







通过之前的配置,已经搭建了包含有三个节点的集群,分别是master、slave1、slave2,并且三个节点能够互联ping通,接下来在master中配置SSH无密钥登陆和安装Hadoop
1、关闭防火墙
对每个虚拟机进行如下操作,完成之后重启三个虚拟机
[zfy@master ~]$ su
Password:
[root@master zfy]# service iptables stop
iptables: Setting chains to policy ACCEPT: filter [ OK ]
iptables: Flushing firewall rules: [ OK ]
iptables: Unloading modules: [ OK ]
[root@master zfy]# setenforce 02、配置SSH
在master中执行以下命令
[zfy@master ~]$ cd
[zfy@master ~]$ ssh-keygen -t rsa
[zfy@master ~]$ cd .ssh
[zfy@master .ssh]$ cat id_rsa.pub >> authorized_keys
[zfy@master .ssh]$ chmod 600 authorized_keys
[zfy@master .ssh]$ scp authorized_keys zfy@slave1:~/.ssh/
[zfy@master .ssh]$ scp authorized_keys zfy@slave2:~/.ssh/执行过程如图
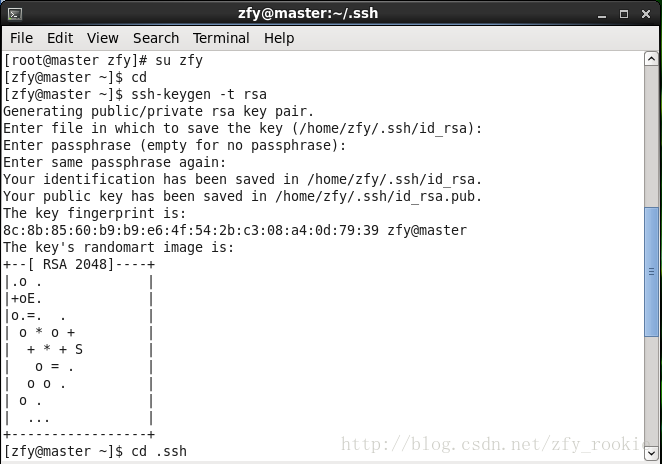
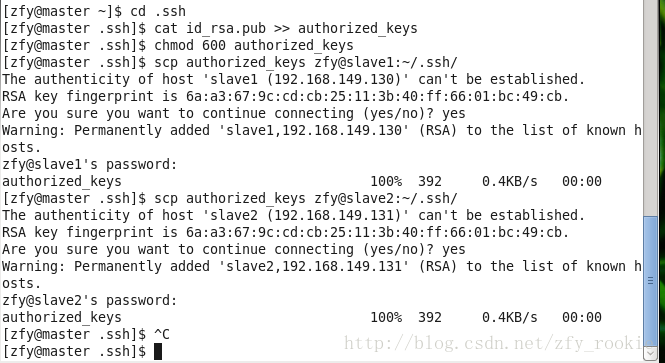
3、检查SSH
在master中执行以下命令,
[zfy@master ~]$ ssh slave1
[zfy@master ~]$ ssh slave2第一次执行需要输入密码,再次执行之后会显示如图所示结果,表明配置ssh成功
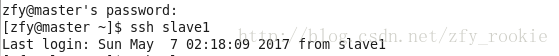
4、安装并配置Hadoop
4.1 下载Hadoop安装文件
网址:https://hadoop.apache.org/
这里使用hadoop-2-7.3版本,下载完成后将安装包复制到/home/zfy/hadoop/目录下
4.2 安装hadoop
执行如下命令,等待解压完成即可
zfy@master ~]$ cd /home/zfy/hadoop/
[zfy@master hadoop]$ ls
hadoop-2.7.3.tar.gz jdk1.8.0_121 jdk-8u121-linux-x64.tar.gz
[zfy@master hadoop]$ tar -zxvf hadoop-2.7.3.tar.gz 4.3 配置hadoop的各项文件
编辑hadoop-env.sh文件
[zfy@master hadoop]$ cd /home/zfy/hadoop/hadoop-2.7.3
[zfy@master hadoop-2.7.3]$ cd etc/hadoop/
[zfy@master hadoop]$ gedit hadoop-env.sh在最后一行添加
export JAVA_HOME=/home/zfy/hadoop/jdk1.8.0_121编辑core-site.xml文件
在标签中添加如下代码
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
<final>true</final>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/zfy/hadoop/tmp</value>
</property>
<property>
<name>ds.default.name</name>
<value>hdfs://master:54310</value>
<final>true</final>
</property>编辑hdfs-site.xml文件
在标签中添加如下代码
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/zfy/hadoop/dfs/name</value>
<final>true</final>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/zfy/hadoop/dfs/data</value>
<final>true</final>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>复制mapred-site.xml.template文件更名为mapred-site.xml,命令:
[zfy@master hadoop]$cp mapred-site.xml.template ./mapred-site.xml编辑mapred-site.xml文件
添加如下代码
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>编辑yarn-site.xml文件
添加如下代码
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>编辑master文件
添加内容
master编辑slaves文件
添加内容
master
slave1
slave25、将配置好的hadoop安装文件复制到slave1、slave2中
执行以下命令:
[zfy@master hadoop]$ cd
[zfy@master ~]$ cd hadoop/
[zfy@master hadoop]$ scp -r hadoop-2.7.3 slave1:~/hadoop
[zfy@master hadoop]$ scp -r hadoop-2.7.3 slave2:~/hadoop6、启动集群
依次执行如下命令
[zfy@master hadoop-2.7.3]$ cd
[zfy@master ~]$ cd hadoop/hadoop-2.7.3
[zfy@master hadoop-2.7.3]$ bin/hdfs namenode -format
[zfy@master hadoop-2.7.3]$ sbin/start-dfs.sh
[zfy@master hadoop-2.7.3]$ sbin/start-yarn.sh
[zfy@master hadoop-2.7.3]$ sbin/hadoop-daemon.sh start secondarynamenode7、检查集群启动情况
在三个虚拟机终端内执行jps,
观察进程情况,若配置正确,在master、slave1、slave2中的进程情况应当依次如下三图所示
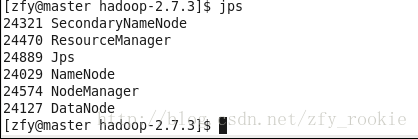
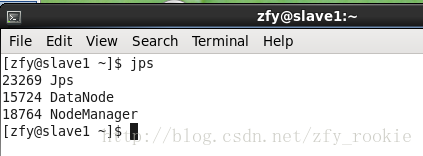
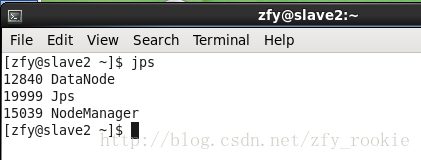
注:关闭集群命令为sbin/stop-all.sh\启动集群命令为sbin/start-all.sh
hadoop配置完成














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









