







这几天调试一块以OTM4001A作驱动芯片的LCM模组,调试完毕后,终于有结果OK了。之前对这块一直用的不太透彻,恰好趁这次摸清楚了。需要注意的几点记录如下:
(1)关于信号类型的片选。在很多LCD芯片规格书上都有关于信号片选的描述,如M2/M1/M0,典型如下:
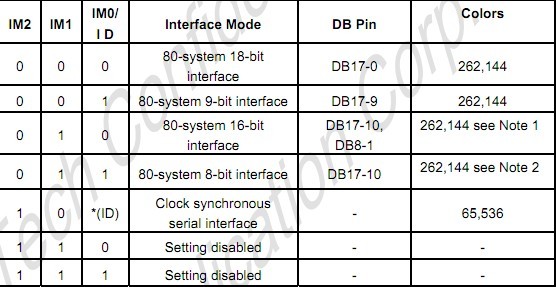
如上图,上面的三个M接口脚是有连接线直接连到主板接口上的,至于是高还是低,可以由主板硬件限定死,另一方面也可以由LCM模组自身做工来限制。具体到我的工作内容上,主板上IM0是不接的,IM2接地,基本上就由IM1来决定是16位是18位,用一个电阻来控制。目前我是用的18位接口,多属于DBI B类型。
关于DBI接口,18位数据线连接和16位连接线要作下说明,针对16位寄存器(8位寄存器不存在这个问题)。
A,18位
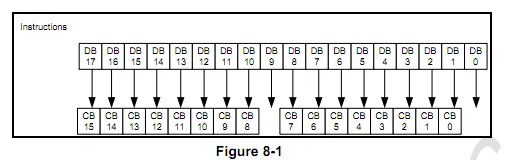
可以看出:18位的数据线传输16位的寄存器参数和命令时,DB0和DB9是跳过去的。这就决定了在写寄存器控制命令时要注意移位(假设32位系统上,怎么样将16位寄存器数据分离,然后放到18位数据线上发送出去),这个在后面会有程序说明。18位的数据传输就是RGB666了,此处不作说明。
B,16位
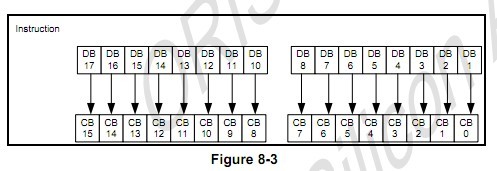
可以看出:16位的数据线,硬件上是直接对应上的,所以写控制命令和参数时,不存在上述移位的问题。16位的数据就是RGB565,这个也不做说明。
从上可以看出,不管是16位还是18位,传输命令的总是那几根线。在硬件接线上注意具体要求。
(2)关于写寄存器的说明。
主芯片自带的读写语句分别是:写寄存器地址SendCtrlComnd(),写寄存器参数SendDataComnd()。两者的形参后来我验证了,应该是32位。硬件采用18位,传输18位数据。那么需要对数据线对应的位进行适当的处理,以在写寄存器命令时跳过DB0和DB9:
#define SendCtrlComndWrapped(value) SendCtrlComnd(((value<<1)&0x1fe)|(((value<<2)&0x3fc00)))
#define SendDataComndWrapped(value) SendDataComnd(((value<<1)&0x1fe)|(((value<<2)&0x3fc00)))
说明:((value<<1)&0x1fe)保证跳过DB0后传输采用的DB8到DB1,恰好在位置上对应。((value<<2)&0x3fc00)保证跳过DB0跟DB9两个位,取得DB17到DB10的数据,从这里可以看出,该寄存器参数类型是32位的,否则无法跟0x3fc00相与。
另外,跳过DB0和DB9还有另一种写法:
#define SendCtrlComndWrapped(value) SendCtrlComnd(((value&0xFF00)<<2) | ((value&0x00FF)<<1) )
#define SendDataComndWrapped(value) SendDataComnd(((value&0xFF00)<<2) | ((value&0x00FF)<<1) )
另补充:以上写控制命令和命令参数都是16位的,所以在18位数据线和16位数据线上要考虑时序。如果控制命令和参数都是8位的,则不需考虑这个过程,也即直接用:
#define SendCtrlComndWrapped(value) SendCtrlComnd(value&0xff)
#define SendDataComndWrapped(value) SendDataComnd(value&0xff)
(3)关于配新屏的过程。
大部分的LCM模组只需要处理好四个函数就可以了。初始化,进入睡眠,唤醒睡眠,写GRAM。都是通过一系列寄存器语句来实现的,比如对于OTM4001A,典型的语句是:
SendCtrlComndWrapped(0x0200);SendDataComndWrapped(0x0000);
其它典型的要补充的是:初始化时要在写GRAM前设置RAM ADDR参数、起始终结的水平垂直位置、Display ON、Write Start;唤醒和睡眠都是有特定的sleep寄存器来控制的,唤醒后可以再把初始化执行一次就可以了。
(4)关于RGB565向RGB666转化
写GRAM的本质就是向不同地址写入对应的点阵颜色的数据,而每个颜色点的格式可能有16位或者18位。如果是单点16位的点阵格式,采用在地址自加的同时,执行WriteHwDataAddrWrapped( color );如果是18位的格式,除了在配置时要改成18位和RGB666格式外,在循环写入颜色数据时需要一个转换:
UINT16 color; //16位颜色值存储单元
UINT32 rgb666; //18位颜色值存储单元
UINT32 panelX, panelY;
UINT16 x0, y0, x1, y1;
x0 = (UINT16)rc.left;
y0 = (UINT16)rc.top;
x1 = (UINT16)rc.right-1;
y1 = (UINT16)rc.bottom-1; //起始终结坐标
for (panelY = y0; panelY <= y1; panelY++)
{
for (panelX = x0; panelX <= x1; panelX++)
{
color = pFB[pixelIndex++];
rColor = ((color & 0xF800) >> 10);
gColor = ((color & 0x07E0) >> 5);
bColor = ((color & 0x001F) << 1);
rgb666 = ((rColor << 12) | (gColor << 6) | (bColor)); //RGB565转成RGB666
WriteHwDataAddrWrapped( rgb666 );
}
}
(5)关于图像倾斜。如果一个图像出现一个对角线,整体倾斜,那么可以考虑是多写了数据或是少些了数据。我的改动方法是一定要注意矩形窗口坐标是0到WIDTH-1,和0到HEIGHT-1。如果没有减去1,则会出现此问题。
(6)关于读芯片的ID号
很多芯片的ID都是0X0000寄存器的值,不需要发读出命令。所以只要在读数据前把寄存器的地址0X0000写进去,就可以读到正确的ID。6516提供的命令如下:
VOID LCDReadDataCommand(void )
{
UINT32 data;
LCD_OUTREG32(PARALLEL[s_pLCDParams->m_ifIndex].CONTROL, 0x0000); //写索引地址0X0000
data = LCD_INREG32(PARALLEL[s_pLCDParams->m_ifIndex].DATA);
SHIPMSG(2,(L"Read lcd id is : 0x%x /r /n",data));
}
直接把该函数放到初始化开始就可以了。
实际调试R61509V的代码时,读得的ID号是0x2d412。而芯片规格书上的0XB509,不一致。后来想了一下,由于是18位的接口,对于命令来说,读和写都要跳过第零位和第九位。所以把0x2d412处理一下后就是0XB509。
(7)关于TE(tearing effect)现象
TE现象的表现在于刷屏时有拖尾残留,起因在于主控发送GRAM的速率与LCM刷屏的速率不一致。主要是刷屏速率太快而主控送GRAM数据太慢,导致刷屏刷新的数据时,GRAM的数据还没有送到,所以刷的还是老旧的数据。用FMARK可以解决此问题,否则就要手动调节两边一致才行。一般也可以降低屏的刷新速度来解决,但是降低太多容易出现FLICKER现象。
关于TE,还做过如下实验:
A,在屏初始化加TE和使能AP的TE情况下,片选信号CS跟FMARK信号都有波形,图像刷新;
B,在屏初始化屏蔽TE和使能AP的TE情况下,FMARK信号是没有,因为屏没有发出,CS是没有的,因为AP没有TE收到不工作,图像静止;
C,在屏初始化屏蔽TE和屏蔽AP的TE情况下,FMARK信号是没有,因为屏没有发出,CS是有的,AP不需要TE也能工作,图像刷新;
综上,屏和AP端的TE功能,要么都开,要么都关。在上述B情况中,碰到过手机开机UB阶段无图像但是进入内核后又有图像,原因不明。
(8)关于开机雪花屏或者闪白屏的解决
在开机的时候,有时会出现雪花样的彩点或者闪白屏,造成这种原因的可能性有两点。一是芯片初始化的时间慢于背光上电的时间,在LCD还没有正常工作的时候,背光已经亮了就会造成这种现象,解决方法是调整两者之间的延时关系(唤醒屏幕时有延迟也是类似原因,缩短延时让芯片尽快工作就行);二是LCD初始化完毕后,AP送数据的速度太慢了,导致空的FrameBuffer映射到LCD上也会出现这种彩点画面,解决方法是在LCD初始化之后加上刷黑屏的函数,就可以掩盖此现象。举个刷黑屏的例子:
sw_clear_panel(0x00000);
原型是
static void sw_clear_panel(unsigned int color)
{
unsigned int x0 = 0;
unsigned int y0 = 0;
unsigned int x1 = x0 + FRAME_WIDTH - 1;
unsigned int y1 = y0 + FRAME_HEIGHT - 1;
unsigned int x, y;
send_ctrl_cmd(0x2A); //X座标域
send_data_cmd(HIGH_BYTE(x0));
send_data_cmd(LOW_BYTE(x0));
send_data_cmd(HIGH_BYTE(x1));
send_data_cmd(LOW_BYTE(x1));
send_ctrl_cmd(0x2B); //Y座标域
send_data_cmd(HIGH_BYTE(y0));
send_data_cmd(LOW_BYTE(y0));
send_data_cmd(HIGH_BYTE(y1));
send_data_cmd(LOW_BYTE(y1));
send_ctrl_cmd(0x2C); // send DDRAM set
for (y = y0; y <= y1; ++ y)
{
for (x = x0; x <= x1; ++ x)
{
lcm_util.send_data(color); //刷色
}
}
}
还碰到另一种开机有干扰纹现象:开机时屏幕有横的闪烁干扰线,过了UBOOT阶段之后就没有了。后来经过示波器测试发现,是屏的VCC供电存在电压不稳的干扰所导致的,到内核后就稳定了。同样碰到过接上UART口后电流会回灌到CPU芯片上,导致手机开机异常的现象。
另一种出现开机雪花屏的原因是:18位的LCM,如果初始化序列用的16位就会出现花屏。如果丢的2位是低两位,一般还是会有图像的;如果丢掉的是高两位的数据,那么会出现花屏。
开机白屏有个情况是:轻按下电源键不开机,LCD就会闪烁一个轻微的白屏,这是硬件电路中导致的,因为这个时候程序是还没有运行的,无法从开机初始化来解决这个问题。其实这个问题的根本原因如下:
轻触POWER键时BL_PWM会有一个脉冲,直接给到背光IC,导致屏闪。通过测试时序发现LPSTB这个复位脚和屏供电是一起上电的,在LPSTB为高又不处于复位(低复位)的情况下,BL_PWM是有可能会输出某些波形的。所以解决这个问题的方法是:一可以通过软件使LPSTB在轻触这个时间内不变高,始终为低,使LCD驱动处于复位的可控状态;二是可以硬件方式使LPSTB在轻触时上电缓慢甚至不上电。
背光由MTK系统的PWM控制,碰到开机会闪白屏,但是系统睡眠后唤醒和开机执行的是一模一样的内容,唤醒却不会白屏。说明问题不在屏参的初始化中,做个实验在开机初始化中加延时,无论延时多久,等到出LOGO时都会闪白屏。最后发现问题出来LK中,在LK的platform中将开背光的位置往后放就解决问题了。为什么有的屏有这个问题有的屏没有?答案是跟屏的特殊性有关,有些屏在buffer 没有内容时显示的是白屏,有些屏在buffer 没有内容时显示的是黑屏;在platform init 的函数里,开背光的时间点过早,在show logo 之前就会导致开背光时无内容可显示,如果恰好是默认白屏的这种屏,就会闪一下白屏。
(9)图像反转
平时调LCD驱动时,有时需要对图像反转处理。一个思路在刷新函数中缓存颜色数据,将像素逆序后再输出。更简单的做法是直接用寄存器设置。参数如下图:

图像的具体旋转可以根据行列的扫描方向及像素的起始设置地址来实现。
(10)关于刷屏,开屏,开背光三者的关系
为了保证液晶显示器件在开机和关机时有正常的无瑕疵的显示,一般要遵循严格的信号顺序。对于刷屏数据、开屏电压、开屏背光三者的关系,开机时要做到刷屏数据-》开屏电压-》开背光,这样是保证数据准备好之后再显示背光,避免画面有瑕疵;关机时则要做到相反,即关背光-》关屏电压-》关屏数据,做到数据撤出是在背光灭掉之后。
对于手机充电画面这种动态的刷屏显示。目前我见到的有两种做法:
A,始终处在一个循环中,每个循环只刷一幅图。这样的话,需要一直有个刷图-》开屏电压-》开背光的流程。如以下:
#define BATTERY_BAR 25
while(1)
{
g_prog_temp = (g_bat_volt_check_point/BATTERY_BAR) * BATTERY_BAR; //从电压百分比获取电压显示档位,注意只有四档,处于五个图片间隔中
mt65xx_disp_show_battery_capacity(g_prog); //刷屏数据
g_prog += BATTERY_BAR;
if (g_prog > 100)
g_prog = g_prog_temp; //如满,则再从当前电压档开始
mt65xx_disp_power(KAL_TRUE); //开屏
g_bl_switch_timer++; //超时计数器
mt6573_sleep(100, KAL_TRUE);
mt65xx_backlight_on(); //开背光
if (g_bl_switch_timer > BL_SWITCH_TIMEOUT) //如果超时则熄灭显示
{
g_bl_switch_timer = 0; //计数器清零
mt65xx_backlight_off(); //关背光
mt65xx_disp_power(KAL_FALSE); //关屏
}
}
B,在一个函数段中就完成显示多幅图片,不需要循环。如下:
mt65xx_disp_show_low_batteryThunderYes(); //显示第一幅图
mt6573_sleep(100, KAL_TRUE);
mt65xx_disp_power(KAL_TRUE); //开屏
mt6573_sleep(100, KAL_TRUE);
mt65xx_leds_brightness_set(6, 10); //开背光,之后就不需要再开屏开背光了
mt65xx_disp_wait_idle();
mt6573_sleep(1000, KAL_TRUE);
mt65xx_disp_show_low_batteryThunderNo();
mt65xx_disp_wait_idle();
mt6573_sleep(1000, KAL_TRUE);
mt65xx_disp_show_low_batteryThunderYes();
mt65xx_disp_wait_idle();
mt6573_sleep(1000, KAL_TRUE);
mt65xx_disp_show_low_batteryThunderNo();
mt65xx_disp_wait_idle();
mt6573_sleep(1000, KAL_TRUE);
mt65xx_disp_show_low_batteryThunderYes();
mt65xx_disp_wait_idle();
mt6573_sleep(1000, KAL_TRUE);
mt65xx_disp_power(KAL_FALSE); //关屏
mt65xx_backlight_off(); //关背光
如上,仅在显示第一幅图后开屏开背光,之后就不需要控制。需要注意的是该操作不能放后面,不然会出现后来的画面覆盖前面的画面,待背光亮时已经看不到前面的图片。
(11)adb reboot会闪白屏的问题
碰到一种现象:开机不会闪白屏,用CMD执行adb reboot时则会闪白屏。两者的区别是前者有掉电,后者没有掉电。解决这个问题的方法是:在帧缓冲驱动的关闭函数内关FB的语句前,加上关背光的语句,这样即可保证FB在背光灭之后无论什么图像都对用户不可见。
(12)关机充电时画面灭时有白屏
一般要遵守先关背光再关屏电源这个顺序,如果已经是这个顺序但是会出现白屏现象,就在这两者之间加个延时就行了。出现这种现象的原因是:虽然关背光放在关屏电源前面,但是硬件上的动作前者要慢于后者,所以才会出现白屏。
(13)由于clock的极性问题而导致的画面异常
一款LCD调好之后,颜色错误。如果在试过修改RGB位数、RGB顺序,mapping之后仍然都无效果,可以试下修改clock的极性。因为影响到采样的数据点,最终影响到综合颜色的效果。















 627
627











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









