






版权声明:本文为博主原创文章,转载请注明出处。
Redis高级特性及应用场景
redis中键的生存时间(expire)
Redis中可以使用expire命令设置一个键的生存时间,到时间后redis会自动删除它。
- 过期时间可以设置为秒或者毫秒精度。
- 过期时间分辨率总是 1 毫秒。
- 过期信息被复制和持久化到磁盘,当 Redis 停止时时间仍然在计算 (也就是说 Redis 保存了过期时间)。
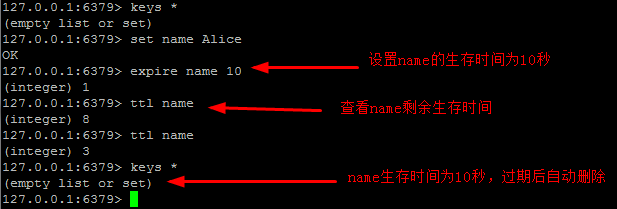
expire 设置生存时间(单位/秒)
ttl 查看键的剩余生存时间
persist 取消生存时间
expireat [key] unix时间戳1351858600
示例:
操作图示:
应用场景:
- 限时的优惠活动信息
- 网站数据缓存(对于一些需要定时更新的数据,例如:积分排行榜)
- 手机验证码
- 限制网站访客访问频率(例如:1分钟最多访问10次)
redis的事务(transaction)
redis中的事务是一组命令的集合。事务同命令一样都是redis的最小执行单元。一组事务中的命令要么都执行,要么都不执行。(例如:转账)
原理:
先将属于一个事务的命令发送给redis进行缓存,最后再让redis依次执行这些命令。
应用场景:
- 一组命令必须同时都执行,或者都不执行。
- 我们想要保证一组命令在执行的过程之中不被其它命令插入。
命令:
错误处理
1:语法错误:致命的错误,事务中的所有命令都不会执行
2:运行错误:不会影响事务中其他命令的执行
Redis 不支持回滚(roll back)
正因为redis不支持回滚功能,才使得redis在事务上可以保持简洁和快速。
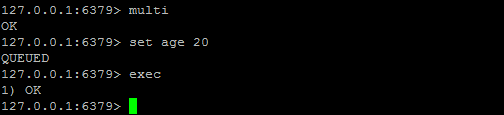
watch命令
作用:监控一个或者多个键,当被监控的键值被修改后阻止之后的一个事务的执行。
但是不能保证其它客户端不修改这一键值,所以我们需要在事务执行失败后重新执行事务中的命令。
注意:执行完事务的exec命令之后,watch就会取消对所有键值的监控
unwatch:取消监控
操作图示:
redis中数据的排序(sort)
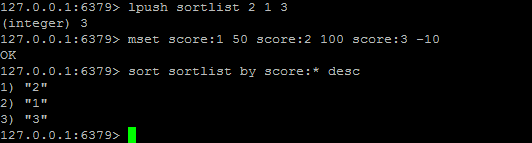
sort命令可以对列表类型,集合类型和有序集合类型进行排序。
by 参考键(参考键可以是字符串类型或者是hash类型的某个字段,hash类型的格式为:键名->字段名)
- 如果参考键中不带*号则不排序
- 如果某个元素的参考键不存在,则默认参考键的值为0
扩展 get参数
- get参数的规则和by参数的规则一样
- get # (返回元素本身的值)
扩展 store参数
使用store 参数可以把sort的排序结果保存到指定的列表中
性能优化
1:尽可能减少待排序键中元素的数量
2:使用limit参数只获取需要的数据
3:如果要排序的数据数量很大,尽可能使用store参数将结果缓存。
操作图示:

“发布/订阅”模式
发布:publish
订阅:subscribe
取消订阅:unsubscribe
按照规则订阅:psubscribe
按照规则取消订阅:punsubscribe
注意:使用punsubscribe命令只能退订通过psubscribe 订阅的频道。
操作图示:(订阅频道后,频道每发布一条消息,都能动态显示出来)
订阅:
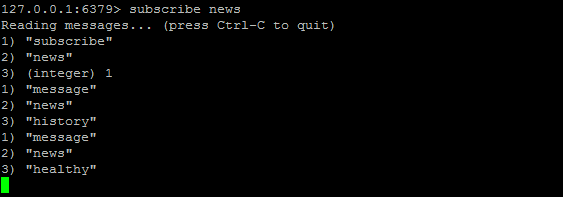
发布:

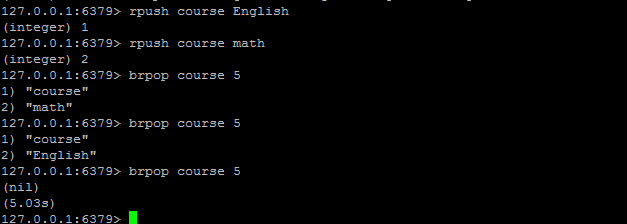
redis任务队列
任务队列:使用lpush和rpop(brpop)可以实现普通的任务队列。
brpop是列表的阻塞式(blocking)弹出原语。
它是 RPOP命令的阻塞版本,当给定列表内没有任何元素可供弹出的时候,连接将被 BRPOP命令阻塞,直到等待超时或发现可弹出元素为止。
当给定多个 key 参数时,按参数 key 的先后顺序依次检查各个列表,弹出第一个非空列表的尾部元素。
优先级队列:
操作图示:
redis管道(pipeline)
redis的pipeline(管道)功能在命令行中没有,但是redis是支持管道的,在Java的客户端(jedis)中是可以使用的。
测试发现:
1:不使用管道方式,插入1000条数据耗时328毫秒
2:使用管道方式,插入1000条数据耗时37毫秒
在插入更多数据的时候,管道的优势更加明显:测试10万条数据的时候,不使用管道要40秒,实用管道378毫秒。
redis持久化(persistence)
redis支持两种方式的持久化,可以单独使用或者结合起来使用。
第一种:RDB方式(redis默认的持久化方式)
第二种:AOF方式
redis持久化之RDB
rdb方式的持久化是通过快照完成的,当符合一定条件时redis会自动将内存中的所有数据执行快照操作并存储到硬盘上。默认存储在dump.rdb文件中。(文件名在配置文件中dbfilename)
redis进行快照的时机(在配置文件redis.conf中)
Redis自动实现快照的过程
1、redis使用fork函数复制一份当前进程的副本(子进程)
2、父进程继续接收并处理客户端发来的命令,而子进程开始将内存中的数据写入硬盘中的临时文件
3、当子进程写入完所有数据后会用该临时文件替换旧的RDB文件,至此,一次快照操作完成。
注意:redis在进行快照的过程中不会修改RDB文件,只有快照结束后才会将旧的文件替换成新的,也就是说任何时候RDB文件都是完整的。
这就使得我们可以通过定时备份RDB文件来实现redis数据库的备份
RDB文件是经过压缩的二进制文件,占用的空间会小于内存中的数据,更加利于传输。
手动执行save或者bgsave命令让redis执行快照。
两个命令的区别在于,save是由主进程进行快照操作,会阻塞其它请求。bgsave是由redis执行fork函数复制出一个子进程来进行快照操作。
文件修复:
rdb的优缺点
优点:由于存储的有数据快照文件,恢复数据很方便。
缺点:会丢失最后一次快照以后更改的所有数据。
redis持久化之AOF
aof方式的持久化是通过日志文件的方式。默认情况下redis没有开启aof,可以通过参数appendonly参数开启。
aof文件的保存位置和rdb文件的位置相同,都是dir参数设置的,默认的文件名是appendonly.aof,可以通过appendfilename参数修改
redis写命令同步的时机
aof日志文件重写
手动执行bgrewriteaof进行重写
重写的过程只和内存中的数据有关,和之前的aof文件无关。
所谓的“重写”其实是一个有歧义的词语, 实际上, AOF 重写并不需要对原有的 AOF 文件进行任何写入和读取, 它针对的是数据库中键的当前值。
文件修复:
动态切换redis持久方式,从 RDB 切换到 AOF(支持Redis 2.2及以上)
注意:
1、当redis启动时,如果rdb持久化和aof持久化都打开了,那么程序会优先使用aof方式来恢复数据集,因为aof方式所保存的数据通常是最完整的。如果aof文件丢失了,则启动之后数据库内容为空。
2、如果想把正在运行的redis数据库,从RDB切换到AOF,建议先使用动态切换方式,再修改配置文件,重启数据库。(不能自己修改配置文件,重启数据库,否则数据库中数据就为空了。)
redis中的config命令
使用config set可以动态设置参数信息,服务器重启之后就失效了。
使用config get可以查看所有可以使用config set命令设置的参数
使用config rewrite命令对启动 Redis 服务器时所指定的 redis.conf 文件进行改写(Redis 2.8 及以上版本才可以使用),主要是把使用config set动态指定的命令保存到配置文件中。
注意:config rewrite命令对 redis.conf 文件的重写是原子性的, 并且是一致的: 如果重写出错或重写期间服务器崩溃, 那么重写失败, 原有 redis.conf 文件不会被修改。 如果重写成功, 那么 redis.conf 文件为重写后的新文件。
redis的安全策略
设置数据库密码
修改配置
验证密码
bind参数(可以让数据库只能在指定IP下访问)
命令重命名
修改命令的名称
禁用命令
redis工具
redis-cli 命令行
Redisclient(redis数据库可视化工具,不怎么实用)
http://www.oschina.NET/news/53391/redisclient-1-0
http://www.oschina.net/news/55634/redisclient-2-0
redis info命令
以一种易于解释(parse)且易于阅读的格式,返回关于 Redis 服务器的各种信息和统计数值。
通过给定可选的参数 section ,可以让命令只返回某一部分的信息:
内容过多,详细参考
http://redisdoc.com/server/info.html
redis内存占用情况
测试情况:
100万个键值对(键是0到999999值是字符串“hello world”)在32位操作系统的笔记本上 用了100MB
使用64位的操作系统的话,相对来说占用的内存会多一点,这是因为64位的系统里指针占用了8个字节,但是64位系统也能支持更大的内存,所以运行大型的redis服务还是建议使用64位服务器
Redis实例最多存keys数
理论上Redis可以处理多达2的32次方的keys,并且在实际中进行了测试,每个实例至少存放了2亿5千万的keys
也可以说Redis的存储极限是系统中的可用内存值。
redis优化1
精简键名和键值
键名:尽量精简,但是也不能单纯为了节约空间而使用不易理解的键名。
键值:对于键值的数量固定的话可以使用0和1这样的数字来表示,(例如:male/female、right/wrong)
当业务场景不需要数据持久化时,关闭所有的持久化方式可以获得最佳的性能
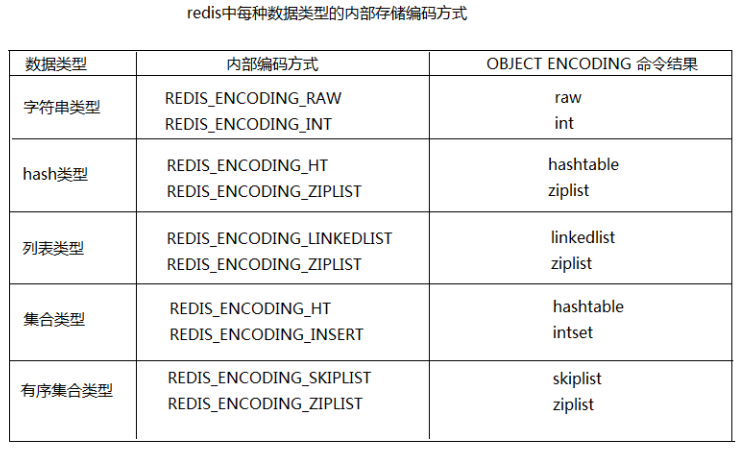
内部编码优化(大家可以自己了解)
redis为每种数据类型都提供了两种内部编码方式,在不同的情况下redis会自动调整合适的编码方式。(如图所示)
SLOWLOG [get/reset/len]
当发现redis性能下降的时候可以查看下是哪些命令导致的
redis优化2
修改Linux内核内存分配策略
原因:
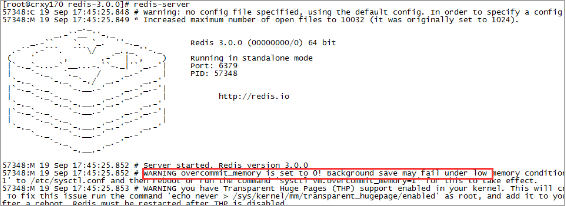
redis在运行过程中可能会出现下面问题
错误日志:
redis在备份数据的时候,会fork出一个子进程,理论上child进程所占用的内存和parent是一样的,比如parent占用的内存为8G,这个时候也要同样分配8G的内存给child,如果内存无法负担,往往会造成redis服务器的down机或者IO负载过高,效率下降。所以内存分配策略应该设置为 1(表示内核允许分配所有的物理内存,而不管当前的内存状态如何)。
内存分配策略有三种
可选值:0、1、2。
0, 表示内核将检查是否有足够的可用内存供应用进程使用;如果有足够的可用内存,内存申请允许;否则,内存申请失败,并把错误返回给应用进程。
1, 不管需要多少内存,都允许申请。
2, 只允许分配物理内存和交换内存的大小。(交换内存一般是物理内存的一半)
向/etc/sysctl.conf添加
或者执行
问题图示:
redis优化3
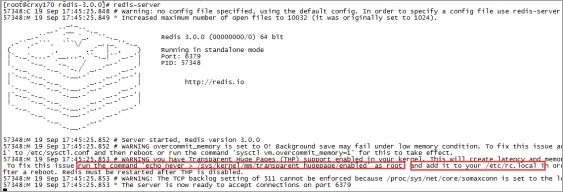
关闭Transparent Huge Pages(THP)
THP会造成内存锁影响redis性能,建议关闭
使用root用户执行下面命令
把这条命令添加到这个文件中/etc/rc.local
redis优化4
修改linux中TCP 监听的最大容纳数量
在高并发环境下你需要一个高backlog值来避免慢客户端连接问题。注意Linux内核默默地将这个值减小到/proc/sys/net/core/somaxconn的值,所以需要确认增大somaxconn和tcp_max_syn_backlog两个值来达到想要的效果。
注意:这个参数并不是限制redis的最大链接数。如果想限制redis的最大连接数需要修改maxclients,默认最大连接数为10000。

redis优化5
限制redis的内存大小
通过redis的info命令查看内存使用情况
如果不设置maxmemory或者设置为0,64位系统不限制内存,32位系统最多使用3GB内存。
修改配置文件中的maxmemory和maxmemory-policy
如果可以确定数据总量不大,并且内存足够的情况下不需要限制redis使用的内存大小。如果数据量不可预估,并且内存也有限的话,尽量限制下redis使用的内存大小,这样可以避免redis使用swap分区或者出现OOM错误。
注意:如果不限制内存,当物理内存使用完之后,会使用swap分区,这样性能较低,如果限制了内存,当到达指定内存之后就不能添加数据了,否则会报OOM错误。可以设置maxmemory-policy,内存不足时删除数据。
拓展
used_memory是Redis使用的内存总量,它包含了实际缓存占用的内存和Redis自身运行所占用的内存(以字节(byte)为单位,其中used_memory_human上的数据和used_memory是一样的值,它以M为单位显示,仅为了方便阅读)。
如果一个Redis实例的内存使用率超过可用最大内存(used_memory >可用最大内存),那么操作系统开始进行内存与swap空间交换,把内存中旧的或不再使用的内容写入硬盘上(硬盘上的这块空间叫Swap分区),以便腾出新的物理内存给新页或活动页(page)使用。
在硬盘上进行读写操作要比在内存上进行读写操作,时间上慢了近5个数量级,内存是0.1us(微秒)、而硬盘是10ms(毫秒)。如果Redis进程上发生内存交换,那么Redis和依赖Redis上数据的应用会受到严重的性能影响。 通过查看used_memory指标可知道Redis正在使用的内存情况,如果used_memory>可用最大内存,那就说明Redis实例正在进行内存交换或者已经内存交换完毕。管理员根据这个情况,执行相对应的应急措施。
排查方案:
若是在使用Redis期间没有开启rdb快照或aof持久化策略,那么缓存数据在Redis崩溃时就有丢失的危险。因为当Redis内存使用率超过可用内存的95%时,部分数据开始在内存与swap空间来回交换,这时就可能有丢失数据的危险。
当开启并触发快照功能时,Redis会fork一个子进程把当前内存中的数据完全复制一份写入到硬盘上。因此若是当前使用内存超过可用内存的45%时触发快照功能,那么此时进行的内存交换会变的非常危险(可能会丢失数据)。 倘若在这个时候实例上有大量频繁的更新操作,问题会变得更加严重。
通过减少Redis的内存占用率,来避免这样的问题,或者使用下面的技巧来避免内存交换发生:
1、尽可能的使用Hash数据结构。因为Redis在储存小于100个字段的Hash结构上,其存储效率是非常高的。所以在不需要集合(set)操作或list的push/pop操作的时候,尽可能的使用Hash结构。比如,在一个web应用程序中,需要存储一个对象表示用户信息,使用单个key表示一个用户,其每个属性存储在Hash的字段里,这样要比给每个属性单独设置一个key-value要高效的多。 通常情况下倘若有数据使用string结构,用多个key存储时,那么应该转换成单key多字段的Hash结构。 如上述例子中介绍的Hash结构应包含,单个对象的属性或者单个用户各种各样的资料。Hash结构的操作命令是HSET(key, fields, value)和HGET(key, field),使用它可以存储或从Hash中取出指定的字段。
2、设置key的过期时间。一个减少内存使用率的简单方法就是,每当存储对象时确保设置key的过期时间。倘若key在明确的时间周期内使用或者旧key不大可能被使用时,就可以用Redis过期时间命令(expire,expireat, pexpire, pexpireat)去设置过期时间,这样Redis会在key过期时自动删除key。 假如你知道每秒钟有多少个新key-value被创建,那可以调整key的存活时间,并指定阀值去限制Redis使用的最大内存。
3、回收key。在Redis配置文件中(一般叫Redis.conf),通过设置“maxmemory”属性的值可以限制Redis最大使用的内存,修改后重启实例生效。也可以使用客户端命令config set maxmemory 去修改值,这个命令是立即生效的,但会在重启后会失效,需要使用config rewrite命令去刷新配置文件。 若是启用了Redis快照功能,应该设置“maxmemory”值为系统可使用内存的45%,因为快照时需要一倍的内存来复制整个数据集,也就是说如果当前已使用45%,在快照期间会变成95%(45%+45%+5%),其中5%是预留给其他的开销。 如果没开启快照功能,maxmemory最高能设置为系统可用内存的95%。
当内存使用达到设置的最大阀值时,需要选择一种key的回收策略,可在Redis.conf配置文件中修改“maxmemory-policy”属性值。 若是Redis数据集中的key都设置了过期时间,那么“volatile-ttl”策略是比较好的选择。但如果key在达到最大内存限制时没能够迅速过期,或者根本没有设置过期时间。那么设置为“allkeys-lru”值比较合适,它允许Redis从整个数据集中挑选最近最少使用的key进行删除(LRU淘汰算法)。Redis还提供了一些其他淘汰策略,如下:
通过设置maxmemory为系统可用内存的45%或95%(取决于持久化策略)和设置“maxmemory-policy”为“volatile-ttl”或“allkeys-lru”(取决于过期设置),可以比较准确的限制Redis最大内存使用率,在绝大多数场景下使用这2种方式可确保Redis不会进行内存交换。倘若你担心由于限制了内存使用率导致丢失数据的话,可以设置noneviction值禁止淘汰数据。
redis优化6
Redis是个单线程模型,客户端过来的命令是按照顺序执行的,所以想要一次添加多条数据的时候可以使用管道,或者使用一次可以添加多条数据的命令,例如:
Redis应用场景
发布与订阅
在更新中保持用户对数据的映射是系统中的一个普遍任务。Redis的pub/sub功能使用了SUBSCRIBE、UNSUBSCRIBE和PUBLISH命令,让这个变得更加容易。
代码示例:
打印结果:

限制网站访客访问频率
进行各种数据统计的用途是非常广泛的,比如想知道什么时候封锁一个IP地址。INCRBY命令让这些变得很容易,通过原子递增保持计数;GETSET用来重置计数器;过期属性expire用来确认一个关键字什么时候应该删除。
代码示例:
打印结果:

监控变量在事务执行时是否被修改
代码示例:
打印结果:
变量a没有被修改时:

变量a被修改时:

各种计数
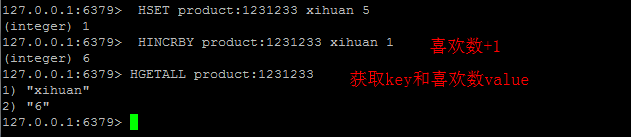
商品维度计数(喜欢数,评论数,鉴定数,浏览数,etc)
采用Redis 的类型: Hash. 如果你对redis数据类型不太熟悉,可以参考 http://redis.io/topics/data-types-intro
为product定义个key product:,为每种数值定义hashkey, 譬如喜欢数xihuan
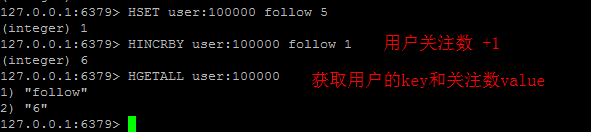
用户维度计数(动态数、关注数、粉丝数、喜欢商品数、发帖数 等)
用户维度计数同商品维度计数都采用 Hash. 为User定义个key user:,为每种数值定义hashkey, 譬如关注数follow
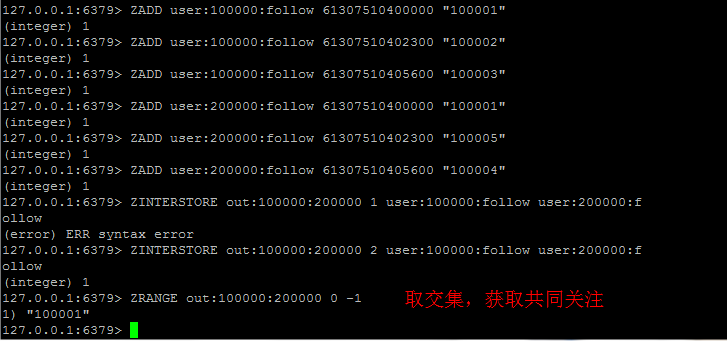
存储社交关系
譬如将用戶的好友/粉丝/关注,可以存在一个sorted set中,score可以是timestamp,这样求两个人的共同好友的操作,可能就只需要用求交集命令即可。
用作缓存代替memcached
缓存内容示例:(商品列表,评论列表,@提示列表,etc)
相对memcached 简单的key-value存储来说,redis众多的数据结构(list,set,sorted set,hash, etc)可以更方便cache各种业务数据,性能也不亚于memcached。
例如:
反spam系统
例如:(评论,发布商品,论坛发贴,etc)
作为一个电商网站被各种spam攻击是少不免(垃圾评论、发布垃圾商品、广告、刷自家商品排名等),针对这些spam制定一系列anti-spam规则,其中有些规则可以利用redis做实时分析,譬如:1分钟评论不得超过2次、5分钟评论少于5次等(更多机制/规则需要结合drools )。 采用sorted set将最近一天用户操作记录起来(为什么不全部记录?节省memory,全部操作会记录到log,后续利用Hadoop进行更全面分析统计),通过
打印结果:
用户Timeline/Feeds
在逛有个类似微博的栏目我关注,里面包括关注的人、主题、品牌的动态。redis在这边主要当作cache使用。
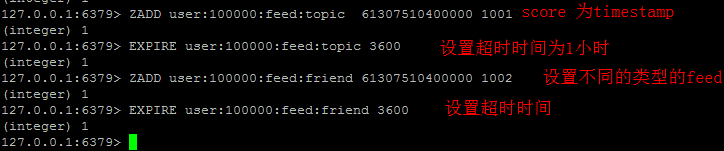
最新列表&排行榜
这里采用Redis的List数据结构或sorted set 结构, 方便实现最新列表or排行榜 等业务场景。
消息通知
其实这业务场景也可以算在计数上,也是采用Hash。如下:
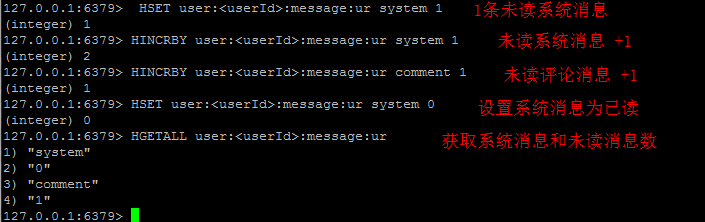
消息队列
当在集群环境时候,Java ConcurrentLinkedQueue 就无法满足我们需求,此时可以采用Redis的List数据结构实现分布式的消息队列。
显示最新的项目列表
Redis使用的是常驻内存的缓存,速度非常快。LPUSH用来插入一个内容ID,作为关键字存储在列表头部。LTRIM用来限制列表中的项目数最多为5000。如果用户需要的检索的数据量超越这个缓存容量,这时才需要把请求发送到数据库。
删除和过滤。
如果一篇文章被删除,可以使用LREM从缓存中彻底清除掉。
排行榜及相关问题
排行榜(leader board)按照得分进行排序。ZADD命令可以直接实现这个功能,而ZREVRANGE命令可以用来按照得分来获取前100名的用户,ZRANK可以用来获取用户排名,非常直接而且操作容易。
按照用户投票和时间排序
这就像Reddit的排行榜,得分会随着时间变化。LPUSH和LTRIM命令结合运用,把文章添加到一个列表中。一项后台任务用来获取列表,并重新计算列表的排序,ZADD命令用来按照新的顺序填充生成列表。列表可以实现非常快速的检索,即使是负载很重的站点。
过期项目处理
使用unix时间作为关键字,用来保持列表能够按时间排序。对current_time和time_to_live进行检索,完成查找过期项目的艰巨任务。另一项后台任务使用ZRANGE...WITHSCORES进行查询,删除过期的条目。
特定时间内的特定项目
这是特定访问者的问题,可以通过给每次页面浏览使用SADD命令来解决。SADD不会将已经存在的成员添加到一个集合。
实时分析
使用Redis原语命令,更容易实施垃圾邮件过滤系统或其他实时跟踪系统。
队列
在当前的编程中队列随处可见。除了push和pop类型的命令之外,Redis还有阻塞队列的命令,能够让一个程序在执行时被另一个程序添加到队列。你也可以做些更有趣的事情,比如一个旋转更新的RSS feed队列。
缓存
Redis缓存使用的方式与memcache相同。
网络应用不能无休止地进行模型的战争,看看这些Redis的原语命令,尽管简单但功能强大,把它们加以组合,所能完成的就更无法想象。当然,你可以专门编写代码来完成所有这些操作,但Redis实现起来显然更为轻松。
手机验证码
使用expire设置验证码失效时间
redis既可以作为数据库来用,也可以作为缓存系统来用














 1055
1055











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









