







概述
为了实现搭建一套初步学习大数据实时分析的平台,用了5台linux虚拟机(Centos 7),安装 的组件包括:
- FlumeNG:数据采集
- kafka集群:数据统一接入
- Storm集群:数据实时处理
- hadoop集群:这里只是用了其中HDFS组件来做数据存储
整个实时处理框架如下:
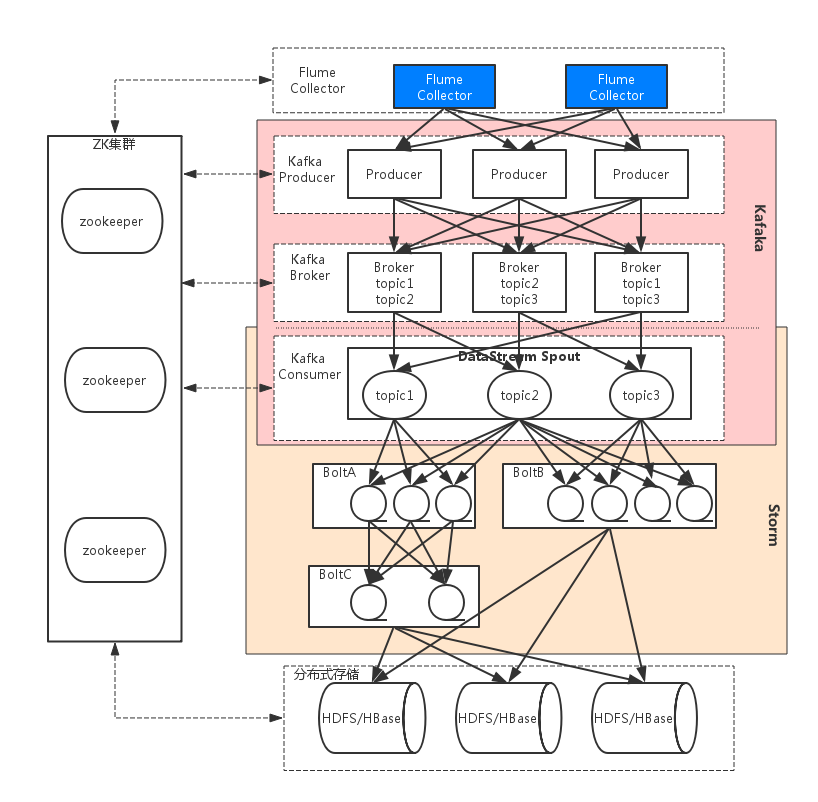
本人自己搭建环境的节点分布如下:
| 服务 | 节点 |
| Hadoop集群 | 172.16.100.78(NameNode),172.16.100.79(DataNode),172.16.100.12(DataNode) |
| Zookeeper集群 | 172.16.100.12 172.16.100.13, 172.16.100.14 |
| Kafka集群 | 172.16.100.12, 172.16.100.13, 172.16.100.14 |
| Storm集群 | 172.16.100.12(nimbus), 172.16.100.13(supervisor), 172.16.100.14(supervisor) |
| FlumeNG | 根据需要装在需要采集日志的应用服务器节点(172.16.100.12) |
本文就主要组件的配置进行详细说明:
zookeeper集群安装:
关于zk的分布式部署网上有很多参考资料这里不
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1886
1886

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









