







整个MapReduce Job运行流程的最初几步是Client向JobTracker提交Job,如下图所示,图中第三步是将Job运行相关资源提交到JobTracker可见的文件系统上。本文将讨论Client需要提交的几个主要文件。
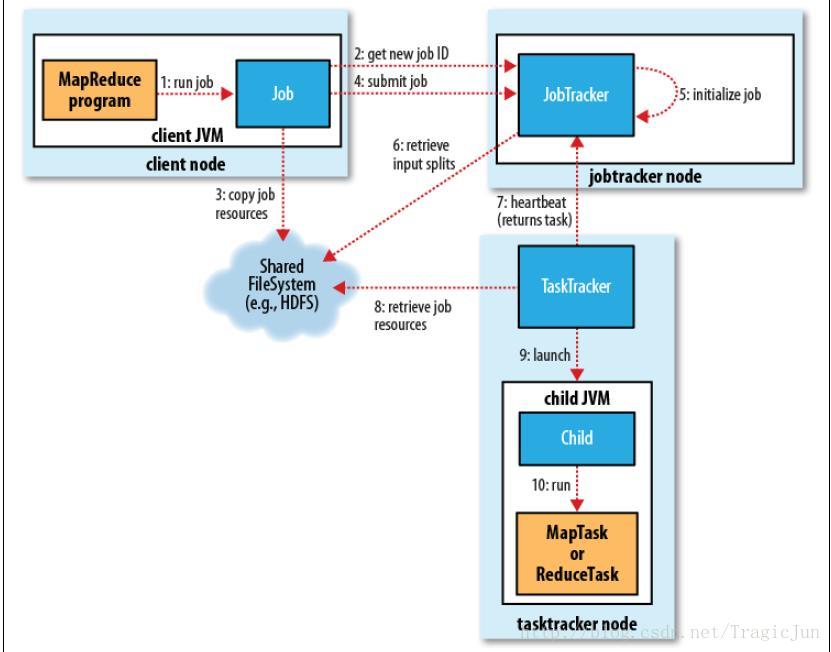
下图列出了提交到staging dir上的几个文件:首先,显而易见的是,job.jar包含Job要执行的程序(jar文件是从Client local复制到staging dir,其他文件是直接在staging dir上生成);job.xml包含所有配置信息(所有可配置的properties)。下面将讨论余下的两个文件。
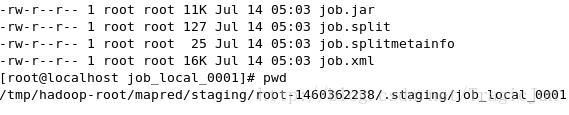
job.split和job.splitmetainfo两个文件存储了有关InputSplit的信息。我们知道,Hadoop MapReduce将所有的输入文件划分成一个一个的InputSplit(划分规则由InputFormat的实现类定义),且为每一个InputSplit,JobTracker将分配一个task交给TaskTracker去执行map。那么,在启动Job之前,首先需要完成文件划分,这个实际上是由Client端来执行。Client完成文件划分后,将划分信息写入job.split和job.splitmetainfo,然后写这两个文件到staging dir。
接下来的问题是,为什么需要有两个文件,它们分别存储了什么样的信息?如下图所示,job.split存储了所有划分出来的InputSplit,而每个InputSplit记录如下信息:
- 该Split的类型(ClassName, mostly org.apache.hadoop.mapreduce.lib.input.FileSplit)
- 该Split所属文件的路径(FilePath)
- 该Split在所属文件中的起始位置(FileOffset)
- 该Split的字节长度(Length)
- 该Split在哪些Node上是local data(Location)
- 该Split对应的InputSplit在job.split文件中的位置(SplitFileOffset)
- 该Split的字节长度(Length, the same as that in job.split)
- job.splitmetainfo提供给JobTracker读取。比如,根据# Split,JobTracker能知道该分配多少个Task;根据Location,JobTracker能决定将该Split对应的Task分配给哪个Node去执行(优先分配到拥有该Split local data的Node)
- job.split提供给TaskTracker读取。根据FilePath, FileOffset, Length,TaskTracker知道从哪个文件的哪个位置开始读取要处理的Split data。
最后来看看job.split和job.splitmetainfo实际的内容,分别如下两图所示(该MapReduce Job运行在Local Mode)。
job.split:

job.splitmetainfo:















 2909
2909











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









