








Deep Dual Learning for Semantic Image Segmentation
ICCV2017
针对语义分割问题,本文提出了一个 dual image segmentation (DIS)系统 利用一部分 per-pixel labelmaps的训练样本和 一部分 image-level tags 的样本 进行联合训练,得到较好的分割结果。
本文定义了一些符号: I 输入图像,L 像素标记真值图 labelmap ,T 图像标签 tags, w 弱标记 即只有图像标签, f 全标记即像素级标记

下面给出怎么使用两类样本的方式对比图:
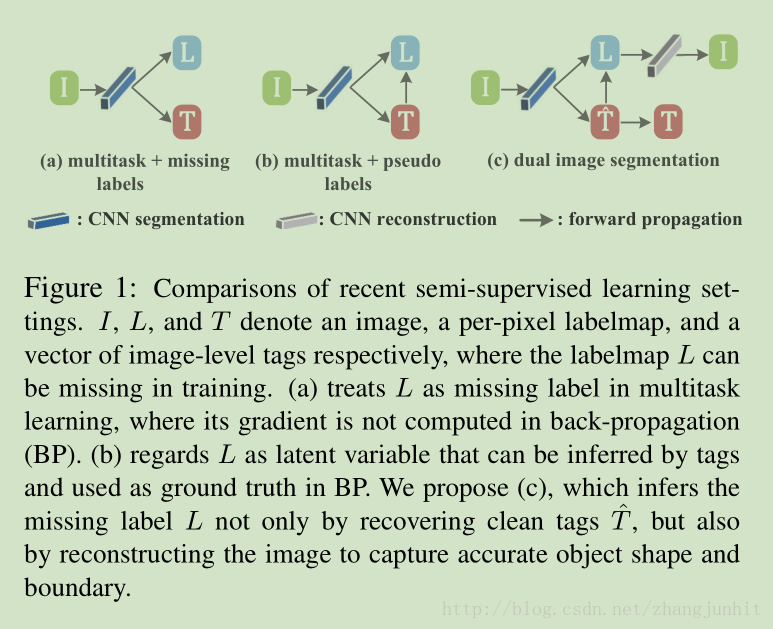
(a)对于弱标记样本,训练时不进行像素级分割结果反向传播计算,
back-propagation of the first task is not performed when a weakly labeled image is presented
(b)对于弱标记样本,使用CNN分割得到分割结果,用图像标签优化分割结果,再用这个分割结果 反向传播计算误差函数,调整网络权值
(c)对于弱标记样本,本文的思路是 通过输入图像和图像的标签来优化样本的分割结果,再用这个分割结果 反向传播计算误差函数,调整网络权值
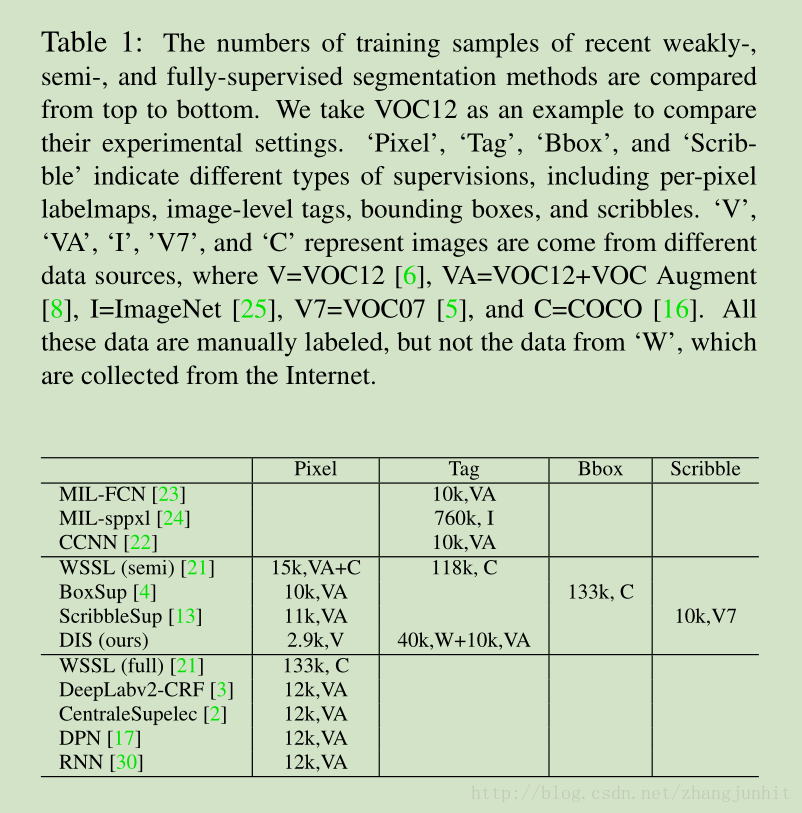
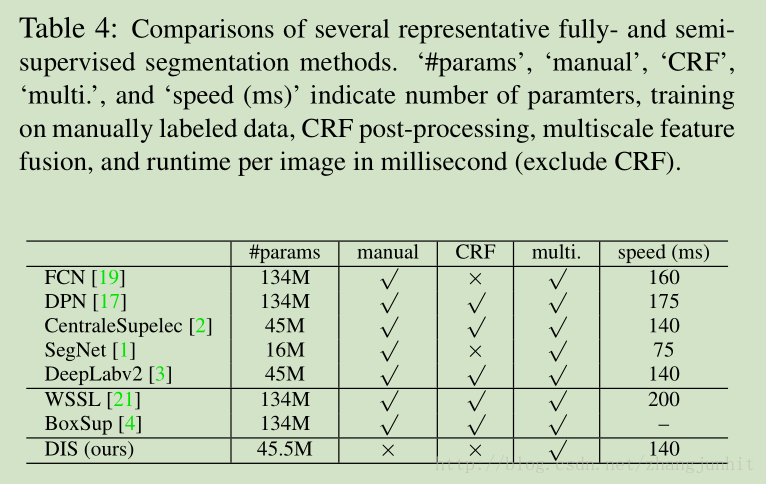
各种方法都用哪些数据,数据量是多少
图像和labelmap 之间的映射途径,我们需要很少的全标记样本

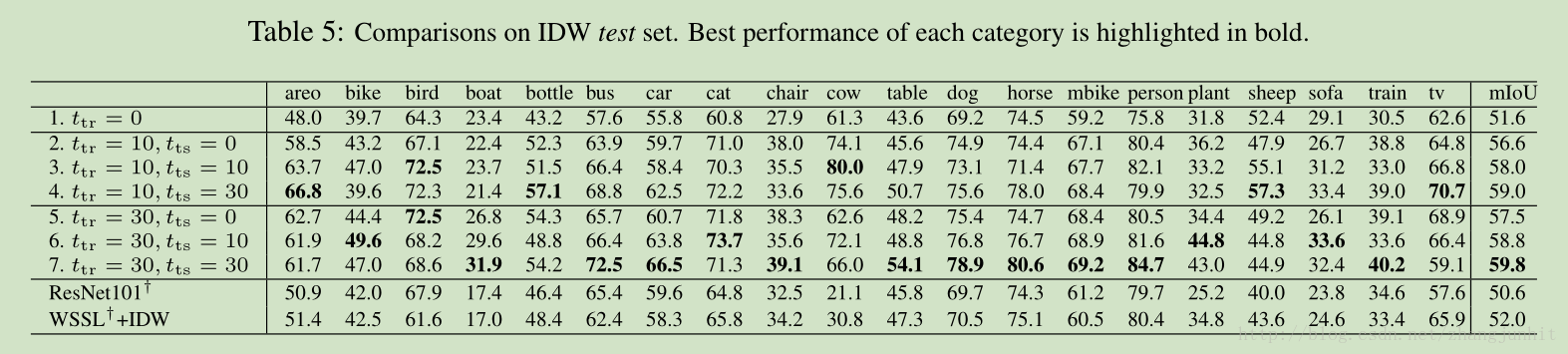
IDW 是什么样子

IDW 的问题是什么?
IDW 是通过一句话来描述图像的,这句话里含有多个标签 tags,其中有一个问题就是这句话有时候不是足够准确,有些重要的标签丢失
A deficiency is that these sentences are not sufficiently accurate, where important tags are missing or not presented in images as highlighted in orange and green in Fig.2
Leveraging them as supervisions may hinder the training procedure. Nevertheless, DIS is able to recover the missing labelmaps and clean tags, to boost the segmentation performance
下面来看看我们的 DIS
2.1. Network Overview
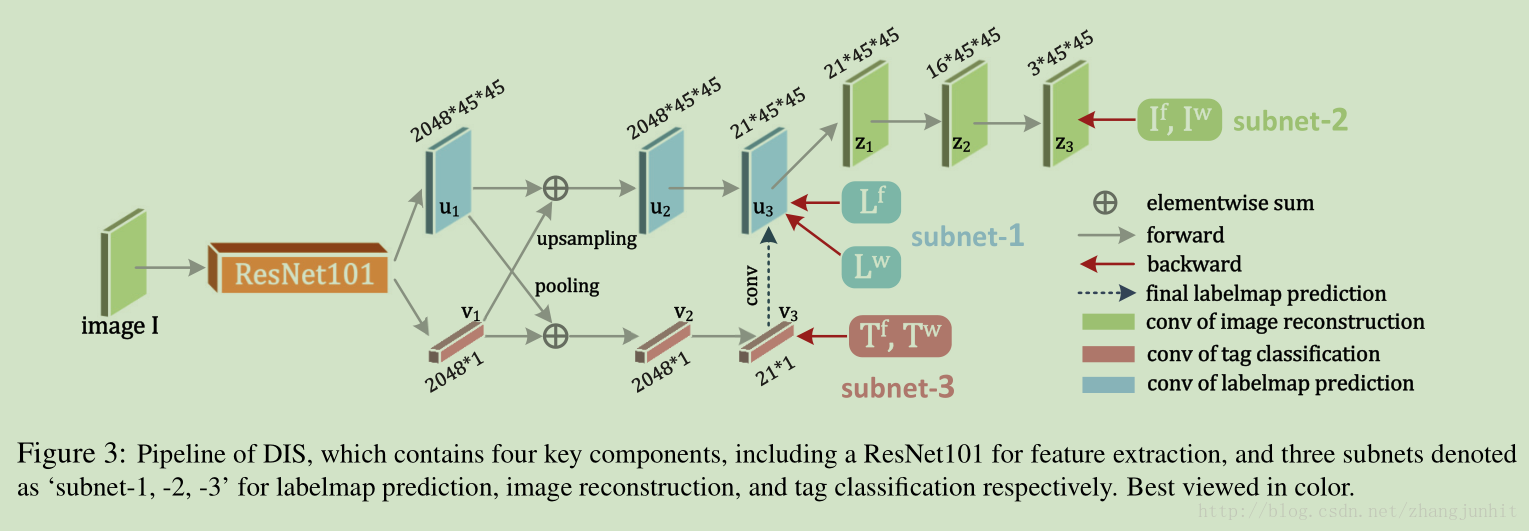
ResNet101 for feature extraction, and three subnets marked as ‘1’, ‘2’, and ‘3’ for labelmap prediction (blue), image
reconstruction (green), and tag classification (pink), respectively.
Baseline. 这里我们使用 ResNet101 网络结构来提取特征,输出一个 2048×45×45 的 feature map 和 2048×1 的 feature vector ,用 u1 v1 表示
Forward Propagation.
对于 Subnet-1 ,它包括一个 elementwise-sum layer 和 一个 convolutional layer. elementwise-sum layer 的输入时u1、v1。它俩的尺寸不一样,通过对v1进行 upsampling 得到2048 × 45 × 45, 然后再元素相加 : u 2 = u 1 ⊕ up(v1 ),the pixel-level features u 1 can borrow information
from the image-level features v 1 to improve segmentation。 a convolutional layer applies a 2048×3×3×21 kernel on u 2 to produce u 3 ,对应 VOC12 中 21类别的响应图
对于 Subnet-2, 表示有u3 重建出输入图像,用z3表示,使用了三个卷积层, the sizes of the kernels from u 3 to z 3 are 21 × 5 × 5 × 21, 21 × 3 × 3 × 16, and 16 × 3 × 3 × 3
对于 Subnet-3,它包括一个 elementwise-sum layer 和 一个 convolutional layer,和Subnet-1类似,通过 average pooling 将u1 归一化到 v1 尺寸,再进行元素相加: v 2 = avgpool(u 1 )⊕v 1,通过卷积层 , v 2 is projected into a response vector v 3 of 21 × 1
Inference in Test
DIS 在测试阶段可以通过迭代来提升分割结果
DIS enables iterative inference in the testing stage to gradually improve accuracy of the predicted labelmap. This is an important contribution of DIS
在保持网络参数固定的情况下,通过 u1,v1 来最小化重建误差 不断提升分割结果
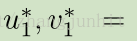
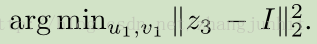

Final Prediction 由最优的 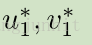
3 Training Algorithms
包括两个阶段: The first stage pretrains the network using the fully annotated images only. In the second stage, the network is finetuned using both the fully and weakly annotated images
An Interesting Finding:可以在训练阶段多迭代几次,测试阶段少迭代几次来提速
The number of iteration t in inference of training and test can be different
computation time in test can be simply reduced by increasing inference iterations in training. On the contrary, training time can be reduced by growing number of iterations in test.
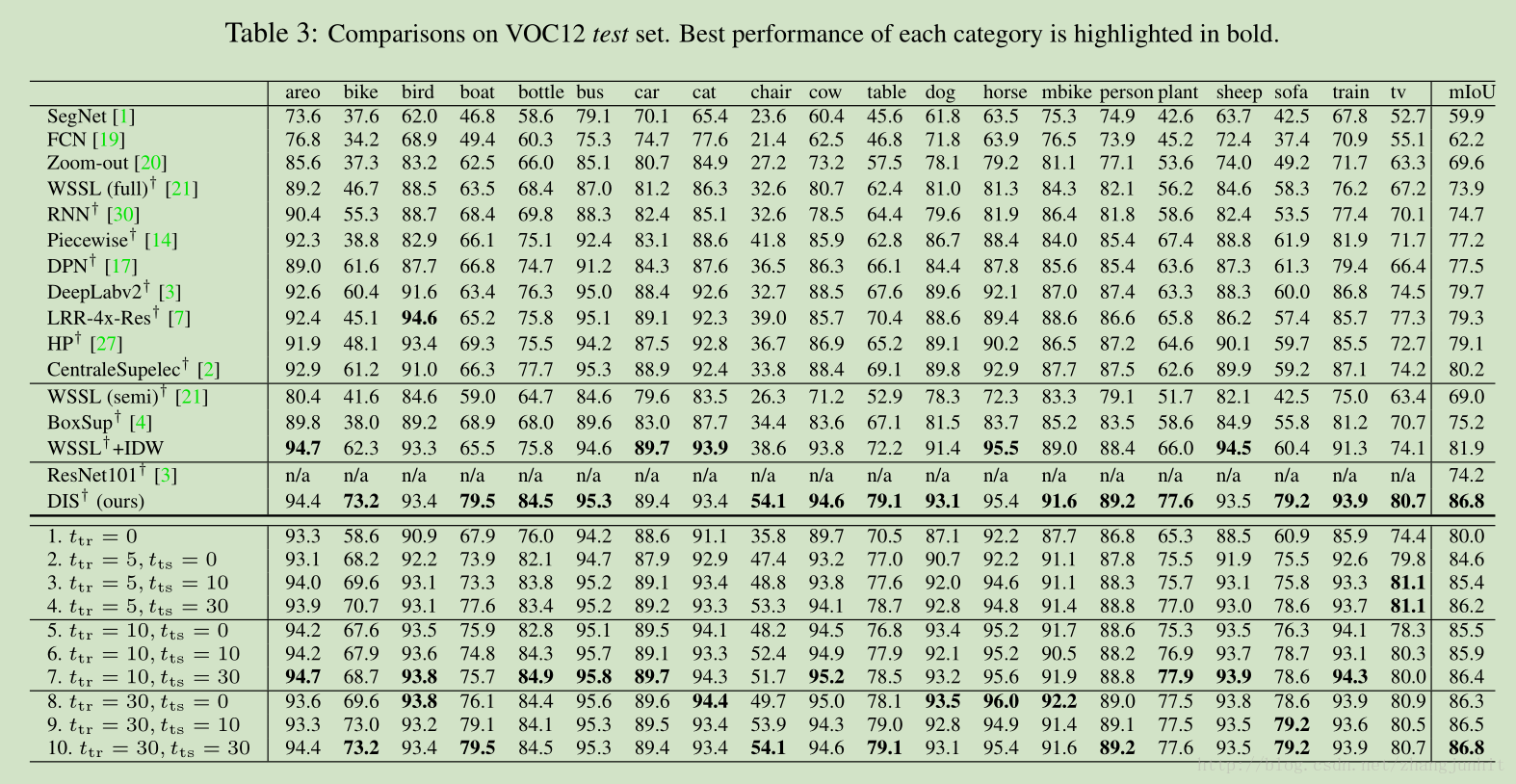
VOC12 test set
IDW test set
网络参数量和速度对比
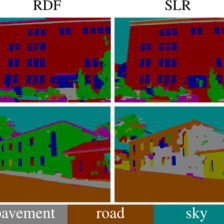
图示分割效果















 946
946











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









