







Joint Face Detection and Alignment Using Multitask Cascaded Convolutional Networks
《IEEE Signal Processing Letters》 , 2016 , 23 (10) :1499-1503
https://kpzhang93.github.io/MTCNN_face_detection_alignment/index.html
https://github.com/kpzhang93/MTCNN_face_detection_alignment
https://github.com/blankWorld/MTCNN-Accelerate-Onet
https://github.com/Seanlinx/mtcnn
本文虽然不是 CVPR 和 ICCV, 但是实用性很强,代码开源
however it is not an end-to-end structure and the model is very complicated to train
人脸检测问题很重要。级联人脸检测器最早由文献【2】 Viola and Jones 提出的 AdaBoost 使用 Haar-Likefeatures 得到实时的人脸检测效果,但是这种类型的检测器在实际应用场景中的性能下降的很快。后来提出了使用 DPM来做人脸检测,效果不错,但是计算量很大。接着就是 CNN网络的崛起。总的来说CNN用于人脸检测效果不错,但是由于网络结构的复杂,计算量较大,检测速度达不到实时。人脸对齐也是一个研究热点,人脸对齐从算法上可以分为两类:基于回归的方法,基于模板拟合的方法。最近文献【22】提出用CNN来做人脸对齐。大部分文献都没有考虑人脸检测和人脸对齐之间内在的关联性。文献【18,20】做了相关的研究,但是性能不是很好。在训练中挖掘 hard samples 对于检测器性能的提升是很重要的,但是传统的 hard sample mining 都是离线的方式,这就显著增加了 manual operations。所以希望可以提出 online hard sample mining 。
本文的贡献有三点:
1)我们提出了一个级联CNN框架用于人脸检测和对齐,精心设计了一个轻量级的CNN网络结构得到实时性能
2)我们提出了一个有效的方法来进行 online hard sample mining 提升性能
3)做了大量实验,证明了本文的方法性能优异。
II. A PPROACH
A. Overall Framework
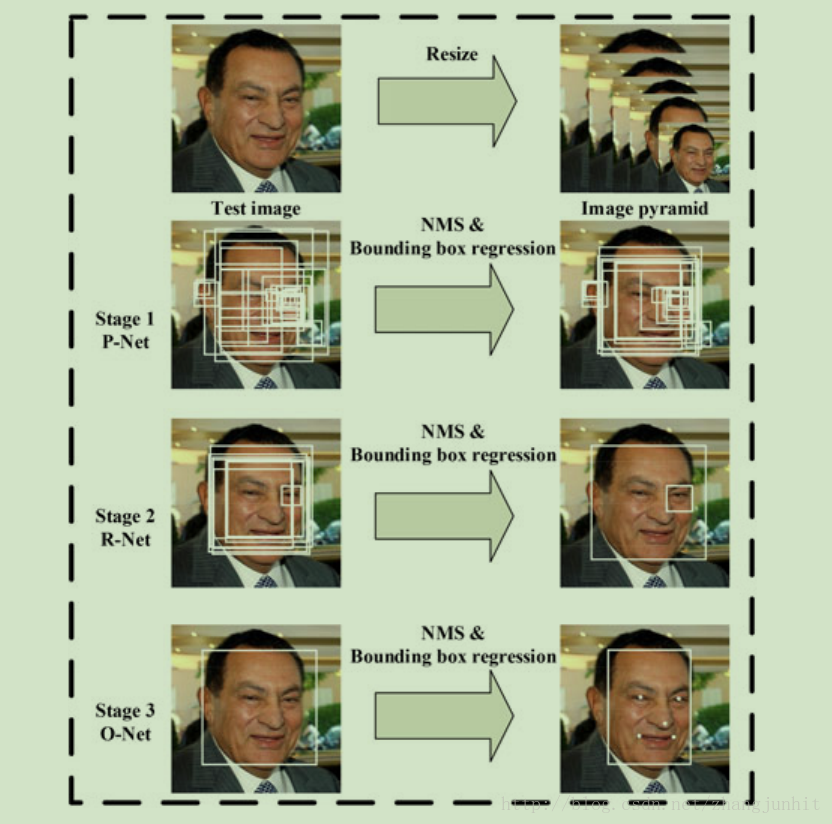

输入一幅图像经过缩放得到图像金字塔,然后将这个图像金字塔输入下面三个级联网络结构得到输出结果。
Stage 1: 我们建立一个全卷积网络,称之为 候选区域提取网络 proposal network (P-Net) 用于得到人脸候选区域及其矩形框回归向量,接着基于矩形框回归向量的估计对人脸候选区域进行校正,接着使用非极大值抑制融合高度重叠的区域。
Stage 2: 所有的候选区域输入到下一个CNN网络,我们称为之 refine network (R-Net),用于进一步去除非人脸候选区域,使用矩形框回归校正人脸区域,进行非极大值抑制。
Stage 3: 这一步和上一步类似,但是我们加入了更多的supervision来确定人脸区域,这里的 O-Net 将会输出五个人脸特征点位置信息
B. CNN Architectures
文献【19】提出使用多个CNN网络用于人脸检测,但是其性能不太好,我们分析原因可能如下:
1)卷积层中一些滤波器可能不够多样化导致其 discriminative ability 有限
2)和其他多类别目标检测和分类任务相比,人脸检测是一个复杂的二分类问题,所以可能每一层需要更少的滤波器。
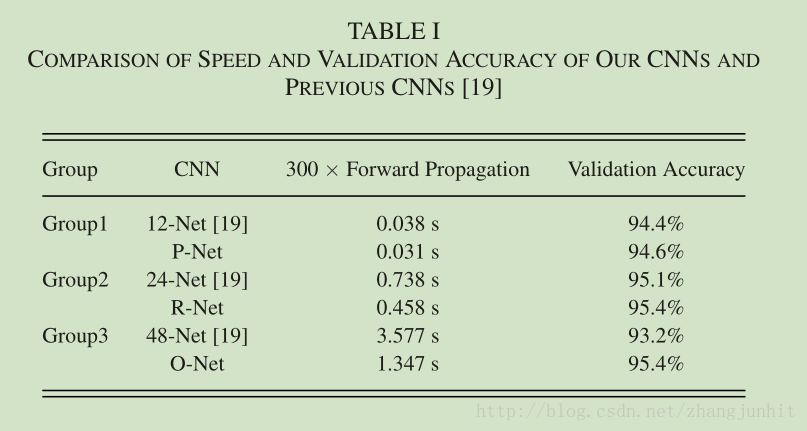
我们采取的措施是减少滤波器的数量,把滤波器的尺寸从 5 × 5 变为 3 × 3 来降低计算量,通过增加网络的深度来提升性能。通过这些措施我们的检测器比文献【19】的性能要更好,速度更快。对比如下图所示:
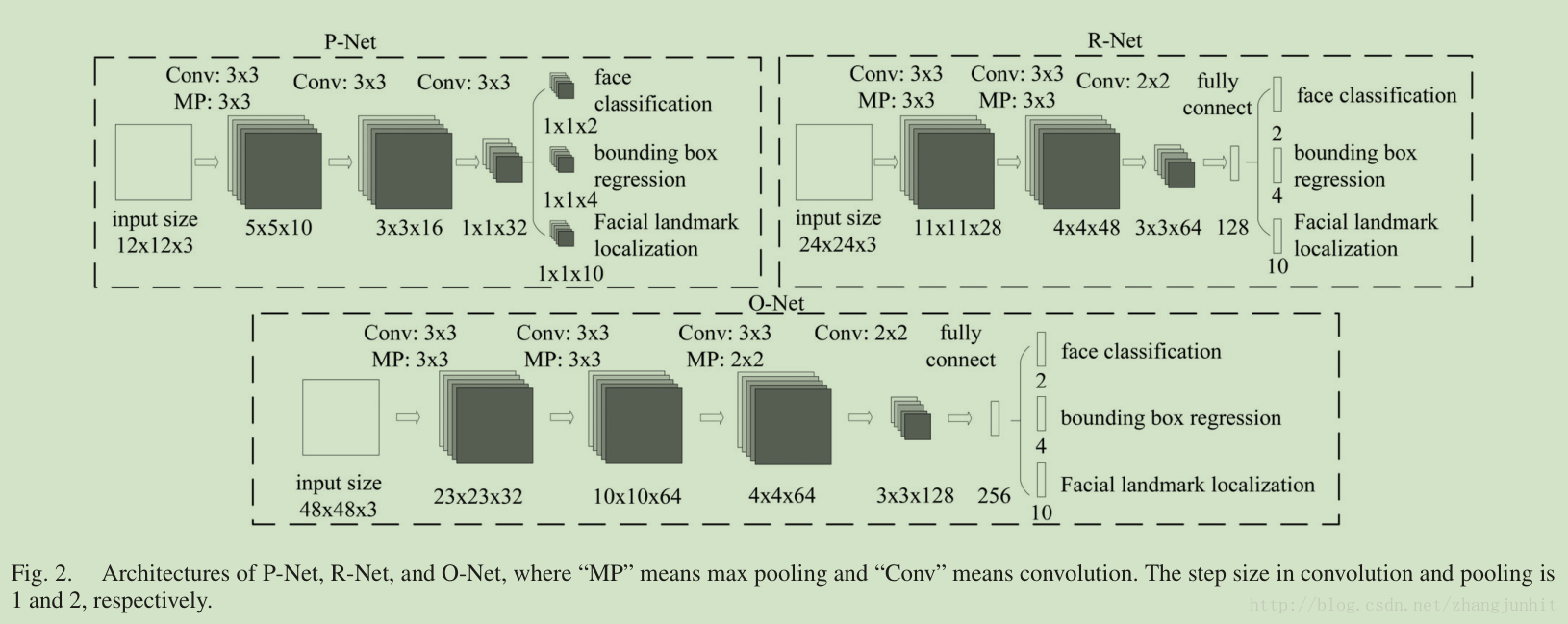
我们的网络结构如下图所示:
C. Training
我们将三个任务嵌入到我们的CNN检测器的训练中:人脸有无,矩形框回归,特征点定位
1) Face Classification: 对于这个任务,我们将学习目标函数看作一个二分类问题,对于每个样本,我们使用 the cross-entropy loss
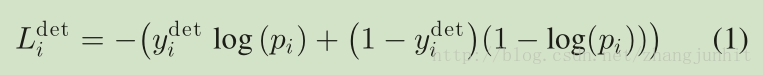
2) Bounding Box Regression: 对于每个候选矩形框,我们预测其和最近的真值矩形框的 偏差 offset,其学习目标函数为一个回归问题,采用 Euclidean loss
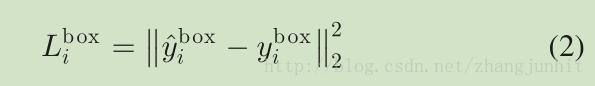
3) Facial Landmark Localization: 和矩形框回归类似,这里的特征点定位看作一个回归问题,采用 Euclidean loss
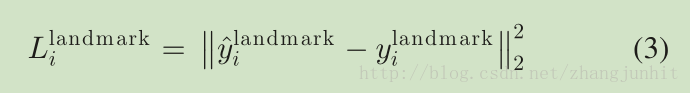
4) Multisource Training: 因为我们的每个 CNN网络需要完成多个不同的任务,在学习过程中存在不同类别的训练图像,如人脸区域,非人脸区域,局部对齐人脸区域。在这种情况下,某些损失函数可能没有使用。例如对于背景区域,我们只计算 L_det 第一个损失函数,其他两个损失函数都是0. 我们可以使用一个 sample type indicator 来实现这个功能, 所以最终的学习目标函数是:
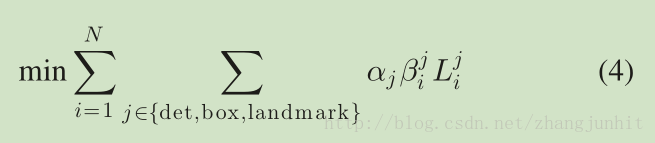
其中 N 是训练样本个数, α 是每个任务的权重系数,这里我们分别设置为 在 P-Net and R-Net 中为 1, 0.5, 0.5;O-Net 中为 1, 0.5, 1
β 是 0或 1 的 sample type indicator, 这里我们采用 stochastic gradient descent 来训练这些CNN
5) Online Hard Sample Mining: 在每个 minibatch 中 我们通过对所有样本的损失函数的值进行排序,挑选最高的前70% 作为 hard samples 来计算 backward propagation 中的梯度
III. EXPERIMENTS
这一部分首先验证 hard sample mining strategy 的有效性,接着验证算法的整体性能在各大数据库上的检测结果
训练数据:
1) P-Net: 我们从 WIDER FACE 数据库中随机裁出图像块用于收集 positives, negatives, and part face,然后我们从 CelebA 裁出人脸作为 landmark faces
2) R-Net: 我们用第一步骤网络来对 WIDER FACE 进行检测人脸收集 positives, negatives, and part face,landmark faces 从 CelebA 中检测
3) O-Net: 和 R-Net 类似,我们使用前两个步骤的网络检测人脸收集数据
B. Effectiveness of Online Hard Sample Mining
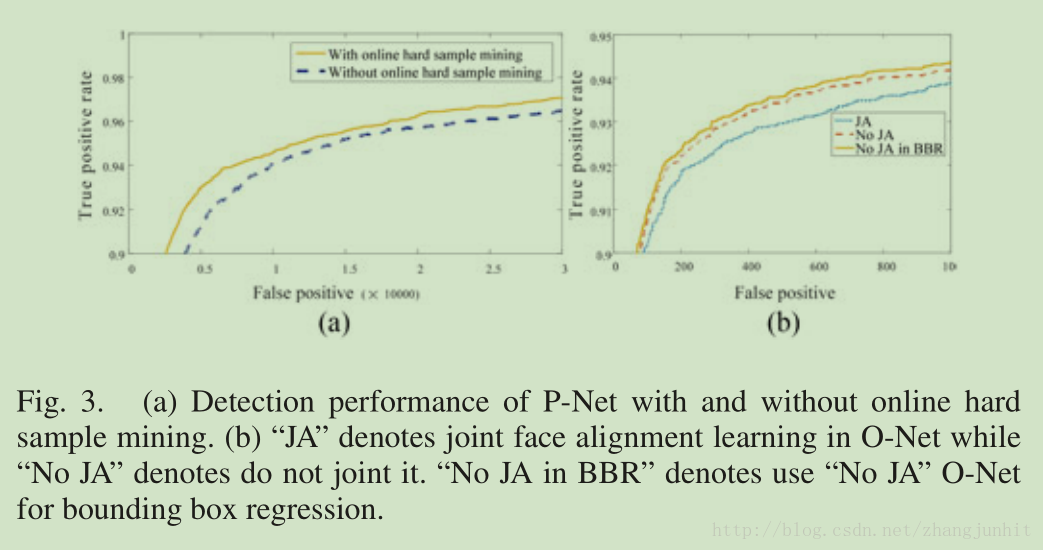
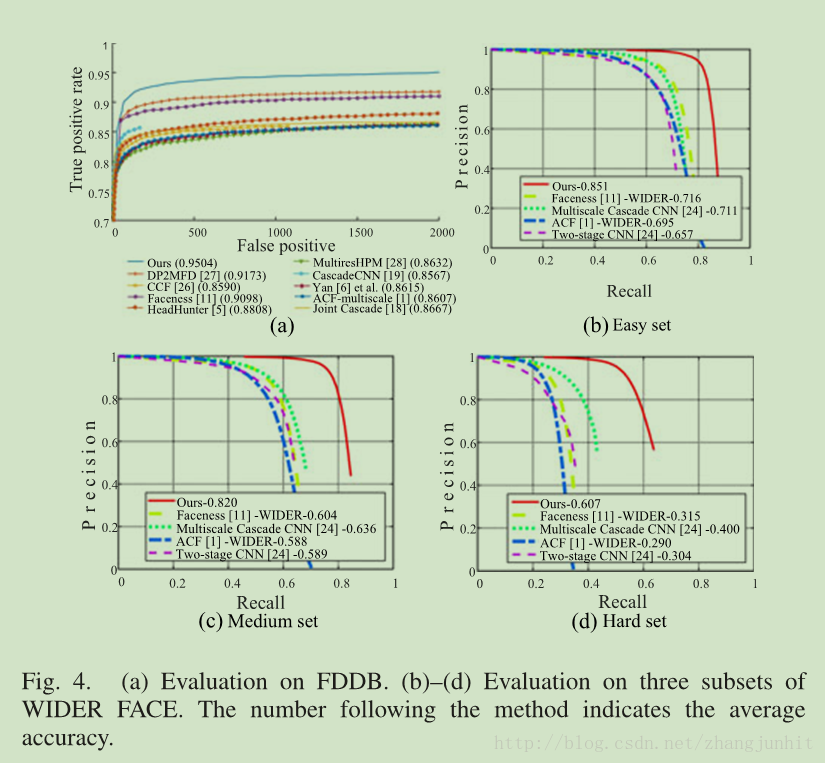
FDDB
AFLW 和 速度















 1184
1184











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









