







传统的关系型数据库很好地满足了以银行交易为代表的事务性业务环境。当人们迈入需要面对非结构化数据构成的数据洪流的全新时代是,传统的关系型数据库已经不能满足需求。在这样的背景下,一HBase为代表的NoSQL数据库成为大数据处理领域的新秀。这里的NoSQL并不是摒弃传统关系型数据库以及SQL,其含义更多是指Not only SQL,即超越传统的关系型数据库。NoSQL的主要思路是在阻碍关系型数据库适应新需求的两个方面做了主要改进:
(1)放松事物一致性的要求。传统的关系型数据库的读写操作都是以事物为基础的,其具有四个典型的特性ACID(Atomicity-原子性,Consistency-一致性,Isolation-隔离性,Durability-持久性)。在这四个特性中,一致性是核心,其他三个特性都是围绕一致性构建的。一致性最典型的表现就是,当完成向一张表写入一条记录后,对该表的查询操作是一定可以获得这条记录的。为了满足这一特性,关系型数据库付出了很大的性能代价。这种一致性在很多要求严格的场景是必须的,但是在NoSQL针对的应用场合中,一致性要求并没有那么高。例如一个用户的动态,被他的好友晚些看到,并不会有什么致命的影响。而放松一些要求,能为NoSQL数据库带来极大的性能提升和构架灵活的好处。
(2)改变固定的表结构。关系型数据库采用了严格的面向行的表结构对数据进行存储,这种方式对以结构化数据为主的情况比较合适,但在业务需求的变化要求数据结构和系统架构发生变化是,就会面临问题。因此NoSQL数据库并没有沿用面向行的表结构,而采用了一些新的形式,例如key-value数据库、列存储数据库等。
HBase架构图:
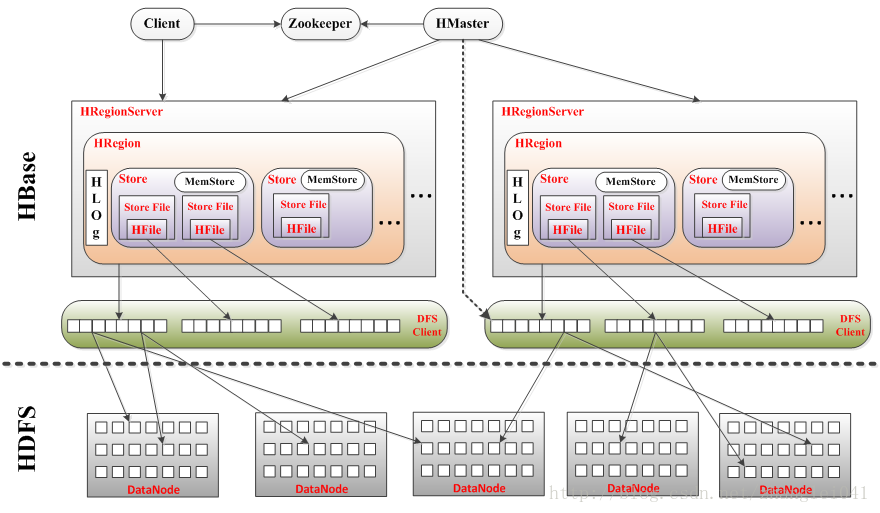
HBase在整个Hadoop体系中位于结构化存储层,其底层存储支撑位HDFS文件系统,使用MapReduce框架对存储在其中的数据进行处理,利用Zookeeper作为协同服务。
HBase Client
Client是HBase功能的使用者,HBase Client使用HBase的RPC机制与HMaster和HRegionServer进行通信,对于管理类操作,Client与HMaster进行RPC;对于数据读写类操作,Client与HRegionServer进行RPC。
Zookeeper
Zookeeper是HBase体系中的协同管理节点,提供分布式协作,分布式同步,配置管理等功能。ZookeeperQuorum中存储的信息包括:
- 存储-ROOT-表的地址:/hbase/root-region-server
- 存储HMaster的地址:/hbase/master
- 存储所有HRegionServer的状态,HRegionServer会把自己以短暂的(Ephemeral)方式注册到 Zookeeper中:/hbase/rs
HMaster
HMaster是整个框架中的控制机节点,他负责管理用户对数据表的增删改和查询操作,调整HRegionServer的负载均衡和Region分布,并确保某个HRegionServer失效后次节点上Region的迁移。HBase中可以启动多个HMaster,通过Zookeeper的Master Election机制保证总有一个HMaster运行,HMaster在功能上主要负责table和region的管理工作:
- 管理用户对table的增、删、改、查操作
- 管理HRegionServer的负载均衡,调整region分布
- 在region split后,负责新region的分配
- 在HRegionServer停机后,负责失效HRegionServer上的region迁移
- HDFS的垃圾文件回收
- 处理schema更新请求
HRegionServer
HRegionServer维护HMaster分配给它的region,并负责响应用户I/O请求,向HDFS文件系统中读写数据,是HBase中最核心的模块。
HRegionServer内部管理了一系列HRegion对象,每个HRegion对应了table中的一个region,HRegion中由多 个HStore组成。每个HStore对应了Table中的一个columnfamily的存储,可以看出每个columnfamily其实就是一个集中的存储单元,因此最好将具备共同IO特性的column放在一个column family中,这样最高效。
HStore存储是HBase存储的核心,由两部分组成,一部分是MemStore,一部分是StoreFile。MemStore是 Sorted Memory Buffer,用户写入的数据首先会放入MemStore,当MemStore满了以后会Flush成一个StoreFile(底层实现是HFile)。
参考文献:
[1]刘军.大数据处理Hadoop.出版社:人民邮电出版社.














 2781
2781











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









