









LZ4 (Extremely Fast Compression algorithm)
项目:http://code.google.com/p/lz4/
作者:Yann Collet
本文作者:zhangskd @ csdn blog
LZ4格式
The compressed block is composed of sequences.
每个数据块可以压缩成若干个序列,格式如下:
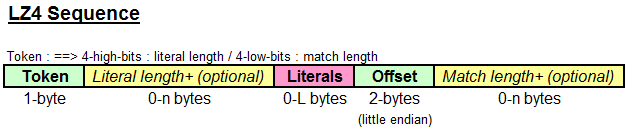
(1) literals
length of literals. If it is 0, then there is no literal. If it is 15, then we need to add some more bytes to indicate the
full length. Each additional byte then represent a value of 0 to 255, which is added to the previous value to produce
a total length. When the byte value is 255, another byte is output.
literals are uncompressed bytes, to be copied as-is.
(2) match
offset. It represents the position of the match to be copied from.
Note that 0 is an invalid value, never used. 1 means "current position - 1 byte".
The maximum offset value is really 65535. The value is stored using "little endian" format.
matchlength. There is an baselength to apply, which is the minimum length of a match called minmatch.
This minimum is 4. As a consequence, a value of 0 means a match length of 4 bytes, and a value of 15 means a
match length of 19+ bytes. (Similar to literal length)
(3) rules
1. The last 5 bytes are always literals.
2. The last match cannot start within the last 12 bytes.
So a file within less than 13 bytes can only be represented as literals.
(4) scan strategy
a single-cell wide hash table.
Each position in the input data block gets "hashed", using the first 4 bytes (minimatch). Then the position is stored
at the hashed position. Obviously, the smaller the table, the more collisions we get, reducing compression
effectiveness. The decoder do not care of the method used to find matches, and requires no addtional memory.
(5) Streaming format

实现
(1) 哈希表
Each position in the input data block gets "hashed", using the first 4 bytes (minimatch). Then the position is stored
at the hashed position. Obviously, the smaller the table, the more collisions we get, reducing compression
effectiveness. The decoder do not care of the method used to find matches, and requires no addtional memory.
LZ4使用哈希表来查找匹配字符串。这个哈希表的映射关系(key, value):
key为4个字节的二进制值。
value为这4个字节在块中的位置。
/* Default value is 14, for 16KB, which nicely fits into Intel x86 L1 cache。
* Increasing memory usage improves compression ratio
* Reduced memory usage can improve speed, due to cache effect
*/
#define MEMORY_USAGE 14
#define LZ4_HASHLOG (MEMORY_USAGE - 2) /* 哈希桶位数12 */
#define HASHTABLESIZE (1 << MEMORY_USAGE) /* 哈希表大小2^14 = 16K */
#define HASHNBCELLS4 (1 << LZ4_HASHLOG) /* 哈希桶个数2^12 = 4K */
选择哈希表的大小时,要做一个权衡:
1. 侧重压缩比,则哈希表可以大一些。
2. 侧重压缩速度,则哈希表应该适中,以便能装入L1 cache。
默认的哈希表使用的内存为16KB,能装进L1 cache,这也是LZ4压缩速度快的一个原因。
当前主流的Intel X86 L1 Data Cache为32KB,所以建议哈希表不要超过此大小。
typedef enum { byPtr, byU32, byU16} tableType_t;
哈希表存储的数据为“位置”,分三种情况:
1. inputSize小于64KB时,使用byU16,表示16位的偏移值即可。
2. inputSize大于64KB时:
2.1 指针大小为8字节,使用byU32,表示32位的偏移值,如果用指针不划算。
2.2 指针大小为4字节,使用byPtr,表示32位的指针。
采用整数哈希算法。
2654435761U是2到2^32的黄金分割素数,2654435761 / 4294967296 = 0.618033987。
计算哈希值,输入为4个字节,输出可分为2字节值、4字节值两种哈希值。
FORCE_INLINE int LZ4_hashSequence(U32 sequence, tableType_t tableType)
{
if (tableType == byU16)
/* 哈希表为16K,如果哈希value为16位 => 哈希key为13位 */
return (((sequence) * 2654435761U) >> ((MINMATCH * 8) - (LZ4_HASHLOG + 1)));
else
/* 哈希表为16K,如果哈希value为32位 => 哈希key为12位 */
return (((sequence) * 2654435761U) >> ((MINMATCH * 8) - LZ4_HASHLOG));
}
FORCE_INLINE int LZ4_hashPosition(const BYTE *p, tableType_t tableType) \
{ return LZ4_hashSequence(A32(p), tableType); }
把地址存入到哈希表中。
FORCE_INLINE void LZ4_putPositionOnHash(const BYTE *p, U32 h, void *tableBase, tableType_t tableType,
const BYTE *srcBase)
{
switch(tableType)
{
case byPtr: { const BYTE **hashTable = (const BYTE **) tableBase; hashTable[h] = p; break; }
case byU32: { U32 *hashTable = (U32 *) tableBase; hashTable[h] = (U32) (p - srcBase); break; }
case byU16: { U16 *hashTable = (U16 *) tableBase; hashTable[h] = (U16) (p - srcBase); break; }
}
}
计算指针p指向的4字节的哈希值,然后把它的位置存入哈希表中。
FORCE_INLINE void LZ4_putPosition(const BYTE *p, void *tableBase, tableType_t tableType, const BYTE *srcBase)
{
U32 h = LZ4_hashPosition(p, tableType); /* 计算哈希值 */
LZ4_putPositionOnHash(p, h, tableBase, tableType, srcBase); /* 把地址存入哈希表 */
}
根据哈希值,获取地址。
FORCE_INLINE const BYTE *LZ4_getPositionOnHash(U32 h, void *tableBase, tableType_t tableType,
const BYTE *srcBase)
{
if (tableType == byPtr) { const BYTE **hashTable = (const BYTE **) tableBase; return hashTable[h]; }
if (tableType == byU32) { U32 *hashTable = (U32 *) tableBase; return hashTable[h] + srcBase; }
{ U16 *hashTable = (U16 *) tableBase; return hashTable[h] + srcBase; } /* default, to ensure a return */
}
根据指针p指向的4字节,计算哈希值,并查找此哈希桶是否已有赋值。
如果此哈希桶已有赋值,则说明此时的4字节和上次的4字节很可能是一样的(如果是冲突,则是不一样的)。
FORCE_INLINE const BYTE *LZ4_getPosition(const BYTE *p, void *tableBase, tableType, const BYTE *srcBase)
{
U32 h = LZ4_hashPosition(p, tableType);
return LZ4_getPositionOnHash(h, tableBase, tableType, srcBase);
}
(2) 压缩
LZ4_compress()是压缩的一个入口函数,先申请哈希表,然后调用LZ4_compress_generic()。
/* LZ4_compress():
* Compress inputSize bytes from source into dest.
* Destination buffer must be already allocated, and must be sized to handle worst cases situations
* (input data not compressible)
* Worst case size evaluation is provided by function LZ4_compressBound()
* inputSize: Max support value is LZ4_MAX_INPUT_VALUE
* return: the number of bytes written in buffer dest or 0 if the compression fails.
*/
int LZ4_compress(const char *source, char *dest, int inputSize)
{
#if (HEAPMODE) /* 在堆中给哈希表分配内存 */
void *ctx = ALLOCATOR(HASHNBCELLS4, 4); /* Aligned on 4-bytes boundaries */
#else /* 在栈中给哈希表分配内存,比较快,默认 */
U32 ctx[1U << (MEMORY_USAGE - 2) ] = {0}; /* Ensure data is aligned on 4-bytes boundaries */
#endif
int result;
/* 输入小于64K+11,则用16位来表示滑动窗口,否则用32位*/
if (inputSize < (int) LZ4_64KLIMIT)
result = LZ4_compress_generic((void *)ctx, source, dest, inputSize, 0, notLimited, byU16, noPrefix);
else
result = LZ4_compress_generic((void *)ctx, source, dest, inputSize, 0, notLimited,
(sizeof(void *) == 8 ? byU32 : byPtr, noPrefix);
#if (HEAPMODE)
FREE(ctx);
#endif
return result;
}#define MINMATCH 4 /* 以4字节为单位查找哈希表 */
#define COPYLENGTH 8
#define LASTLITERALS 5
#define MFLIMIT (COPYLENGTH + MINMATCH) /* 对于最后的12个字节,不进行查找匹配 */
const int LZ4_minLength = (MFLIMIT + 1); /* 一个块要>=13个字符,才会进行查找匹配 */
#define LZ4_64KLIMIT ((1<<16) + (MFLIMIT - 1)) /* 64K + 11 */
/* Increasing this value will make the compression run slower on incompressible data。
* 用于控制查找匹配时的前进幅度,如果一直没找到匹配,则加大前进幅度。
*/
#define SKIPSTRENGTH 6
LZ4_compress_generic()是主要的压缩函数,根据指定的参数,可以执行多种不同的压缩方案。
匹配算法
1. 当前的地址为ip,它的哈希值为h。
2. 下个地址为forwardIp,它的哈希值为forwardH (下个循环赋值给ip、h)。
3. 按照哈希值h,获取哈希表中的值ref。
3.1 ref为初始值,没有匹配,A32(ip) != A32(ref),继续。
3.2 ref不为初始值,有匹配。
3.2.1 ref不在滑动窗口内,放弃,继续。
3.2.2 ref对应的U32和ip对应的U32不一样,是冲突,继续。
3.3.3 ref在滑动窗口内,且对应的U32一样,找到了match,退出。
4. 保存ip和h的对应关系。
FORCE_INLINE int LZ4_compress_generic(void *ctx, const char *source, char *dest, int inputSize,
int maxOutputSize, limitedOutput_directive limitedOutput, tableType_t tableType,
prefix64k_directive prefix)
{
const BYTE *ip = (const BYTE *) source;
/* 用作哈希表中的srcBase */
const BYTE *const base = (prefix == withPrefix) ? ((LZ4_Data_Structure *)ctx)->base : (const BYTE *)source);
/* 前向窗口的起始地址 */
const BYTE *const lowLimit = ((prefix == withPrefix) ? ((LZ4_Data_Structure *)ctx)->bufferStart : (const BYTE *)source);
const BYTE *anchor = (const BYTE *)source;
const BYTE *const iend = ip + inputSize; /* 输入的结束地址 */
const BYTE *const mflimit = iend - MFLIMIT; /* iend - 12,超过此处不允许再启动一次匹配 */
const BYTE *const matchlimit = iend - LASTLITERALS; /* iend - 5,最后5个字符不允许匹配 */
BYTE *op = (BYTE *) dest; /* 用于操作输出缓存 */
BYTE *const oend = op + maxOutputSize; /* 输出缓存的边界,如果有的话 */
int length;
const int skipStrength = SKIPSTRENGTH; /* 6 */
U32 forwardH;
/* Init conditions */
if ((U32) inputSize > (U32) LZ4_MAX_INPUT_SIZE) return 0; /* 输入长度过大 */
/* must continue from end of previous block */
if ((prefix == withPrefix) && (ip != ((LZ4_Data_Structure *)ctx)->nextBlock)) return 0;
/* do it now, due to potential early exit. 保存下一个块的起始地址 */
if (prefix == withPrefix) ((LZ4_Data_Structure *)ctx)->nextBlock = iend;
if ((tableType == byU16) && (inputSize >= LZ4_64KLIMIT)) return 0; /* Size too large (not within 64K limit) */
if (inputSize < LZ4_minlength) goto _last_literals; /* 如果输入长度小于13,则不查找匹配 */
/* First Byte */
LZ4_putPosition(ip, ctx, tableType, base); /* 计算以第一个字节开头的U32的哈希值,保存其位置 */
ip++; forwardH = LZ4_hashPosition(ip, tableType); /* 计算以第二个字节开头的U32的哈希值 */
/* Main loop,每次循环查找一个匹配,产生一个序列 */
for ( ; ; )
{
int findMatchAttempts = (1U << skipStrength) + 3;
const BYTE *forwardIp = ip;
const BYTE *ref;
BYTE *token;
/* Find a match,查找一个匹配,或者到了尽头mflimit */
do {
U32 h = forwardH; /* 当前ip对应的哈希值 */
int step = findMatchAttempts++ >> skipStrength; /* forwardIp的偏移,一般是1 */
ip = forwardIp;
forwardIp = ip + step; /* 前向缓存中下个将检查的地址 */
if unlikely(forwardIp > mflimit) { goto _last_literals; } /* >=12字节才会去匹配 */
forwardH = LZ4_hashPosition(forwardIp, tableType); /* forwardIp的哈希值 */
/* 这里是查找的关键:按照哈希值h,获取地址ref。
* 1. 没有匹配,ref为srcBase。
* 2. 有匹配。
* 2.1 不在滑动窗口内,继续。
* 2.2 对应的U32不一样,是冲突,继续。
* 2.3 在滑动窗口内,且对应的U32一样,找到了match,退出。
*/
ref = LZ4_getPositionOnHash(h, ctx, tableType, base);
LZ4_putPositionOnHash(ip, h, ctx, tableType, base); /* 保存ip、h这个对应关系 */
} while ((ref + MAX_DISTANCE < ip) || (A32(ref) != A32(ip)));
/* 找到匹配之后,看能否向前扩大匹配 */
while((ip > anchor) && (ref > lowLimit) && unlikely(ip[-1] == ref[-1])) { ip--; ref--; }
/* Encode Literal length,赋值Literal length */
length = (int) (ip - anchor);
token = op++;
/* Check output limit */
if ((limitedOutput) & unlikely(op + length + 2 + (1 + LASTLITERALS) + (length>>8) > oend)) return 0;
if (length >= (int) RUN_MASK) {
int len = length - RUN_MASK;
*token = (RUN_MASK << ML_BITS);
for(; len >= 255; len -= 255) *op++ = 255;
*op++ = (BYTE) len;
} else
*token = (BYTE) (length << ML_BITS);
/* Copy Literals,复制不可编码字符 */
{ BYTE * end = (op) + (length); LZ4_WILDCOPY(op, anchor, end); op = end; }
_next_match: /* 向后扩展匹配 */
/* Encode Offset,赋值offset,op += 2 */
LZ4_WRITE_LITTLEENDIAN_16(op, (U16) (ip - ref));
/* Start Counting */
ip += MINMATCH; ref += MINMATCH; /* MinMatch already verified */
anchor = ip;
while likely(ip < matchlimit - (STEPSIZE - 1)) {
size_t diff = AARCH(ref) ^ AARCH(ip); /* 异或,值为零表示相同 */
if (! diff) { ip += STEPSIZE; ref += STEPSIZE; continue; }
ip += LZ4_NbCommonBytes(diff); /* STEPSIZE不同,看其中有多少个字节是相同的 */
goto _endCount;
}
if (LZ4_ARCH64)
if ((ip < (matchlimit - 3)) && (A32(ref) == A32(ip))) { ip += 4; ref += 4; }
if ((ip < matchlimit - 1)) && (A16(ref) == A16(ip))) { ip += 2; ref += 2; }
if ((ip < matchlimit) && (*ref == *ip)) ip++;
_endCount:
/* Ecode MatchLength,赋值match length */
length = (int) (ip - anchor);
/* Check output limit */
if ((limitedOutput) && unlikely(op + (1 + LASTLITERALS) + (length >> 8) > oend)) return 0;
if (length >= (int) ML_MASK) {
*token += ML_MASK;
length -= ML_MASK;
for (; length > 509; length -= 510) { *op++ = 255; *op++ = 255; }
if (length >= 255) { length -= 255; *op++ = 255; }
*op++ = (BYTE) (length);
} else
*token += (BYTE) (length);
/* Test end of chunk */
if (ip > mflimit) { anchor = ip; break; } /* 不再进行匹配了 */
/* Fill table,顺便保存 */
LZ4_putPosition(ip - 2, ctx, tableType, base);
/* Test next position,尝试着找匹配 */
ref = LZ4_getPosition(ip, ctx, tableType, base);
LZ4_putPosition(ip, ctx, tableType, base);
/* 如果找到匹配,说明没有literals,可以直接跳过查找、赋值literal length */
if ((ref + MAX_DISTANCE >= ip) && (A32(ref) == A32(ip))) { token = op++; *token = 0; goto _next_match; }
/* Prepare next loop,准备进行下个循环 */
anchor = ip++;
forwardH = LZ4_hashPosition(ip, tableType);
}
_last_literals:
/* Encode Last Literals */
{
int lastRun = (int) (iend - anchor); /* 最后原字符串长度 */
if ((limitedOutput) && (((char *)op - dest) + lastRun + 1 + ((lastRun + 255 - RUN_MASK) / 255) >
(U32) maxOutputSize))
return 0; /* check output limit */
if (lastRun >= (int) RUN_MASK) {
*op ++ = (RUN_MASK << ML_BITS);
lastRun -= RUN_MASK;
for (; lastRun >= 255; lastRun -=255) *op++ = 255;
*op++ = (BYTE) lastRun;
} else
*op++ = (BYTE) (lastRun << ML_BITS);
memcpy(op, anchor, iend - anchor); /* 复制literals */
op += iend - anchor;
}
/* End */
return (int) (((char *)op) - dest); /* 返回压缩后的长度 */
}
#define LZ4_MAX_INPUT_SIZE 0x7E000000 /* 2 113 929 216 bytes */
#define ML_BITS 4 /* Token: 4-low-bits, match length */
#define ML_MASK ((1U << ML_BITS) - 1)
#define RUN_BITS (8 - ML_BITS) /* Token: 4-high-bits, literal length */
#define RUN_MASK ((1U << RUN_BITS) - 1)
#define MAXD_LOG 16 /* 滑动窗口的位数 */
#define MAX_DISTANCE ((1 << MAXD_LOG) - 1) /* 滑动窗口的最大值 */














 348
348











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









