




 本文详细解析了二叉树的非递归遍历方法,包括中序、前序和后序遍历。通过分析思路和代码示例,阐述了非递归实现的原理,特别是利用栈来辅助遍历。中序遍历最为简单,后序遍历最具挑战性。建议读者对比不同代码,深入理解算法本质,并尝试自己编写实现。
本文详细解析了二叉树的非递归遍历方法,包括中序、前序和后序遍历。通过分析思路和代码示例,阐述了非递归实现的原理,特别是利用栈来辅助遍历。中序遍历最为简单,后序遍历最具挑战性。建议读者对比不同代码,深入理解算法本质,并尝试自己编写实现。
前言
在前两篇文章二叉树和二叉搜索树中已经涉及到了二叉树的三种遍历。递归写法,只要理解思想,几行代码。可是非递归写法却很不容易。这里特地总结下,透彻解析它们的非递归写法。其中,中序遍历的非递归写法最简单,后序遍历最难。我们的讨论基础是这样的:
//Binary Tree Node
typedef struct node
{
int data;
struct node* lchild; //左孩子
struct node* rchild; //右孩子
}BTNode;首先,有一点是明确的:非递归写法一定会用到栈,这个应该不用太多的解释。我们先看中序遍历:
中序遍历
分析
中序遍历的递归定义:先左子树,后根节点,再右子树。如何写非递归代码呢?一句话:让代码跟着思维走。我们的思维是什么?思维就是中序遍历的路径。假设,你面前有一棵二叉树,现要求你写出它的中序遍历序列。如果你对中序遍历理解透彻的话,你肯定先找到左子树的最下边的节点。那么下面的代码就是理所当然的:
中序代码段(i)
BTNode* p = root; //p指向树根
stack<BTNode*> s; //STL中的栈
//一直遍历到左子树最下边,边遍历边保存根节点到栈中
while (p)
{
s.push(p);
p = p->lchild;
}保存一路走过的根节点的理由是:中序遍历的需要,遍历完左子树后,需要借助根节点进入右子树。代码走到这里,指针p为空,此时无非两种情况:
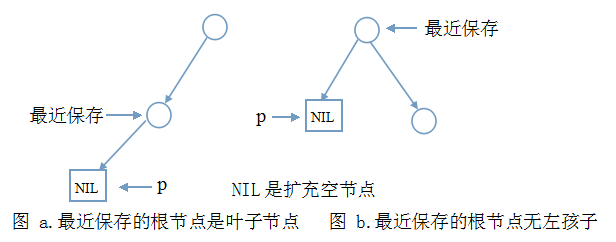
说明:
- 上图中只给出了必要的节点和边,其它的边和节点与讨论无关,不必画出。
- 你可能认为图a中最近保存节点算不得是根节点。如果你看过树、二叉树基础,使用扩充二叉树的概念,就可以解释。总之,不用纠结这个没有意义问题。
- 整个二叉树只有一个根节点的情况可以划到图a。
仔细想想,二叉树的左子树,最下边是不是上图两种情况?不管怎样,此时都要出栈,并访问该节点。这个节点就是中序序列的第一个节点。根据我们的思维,代码应该是这样:
p = s.top();
s.pop();
cout << p->data;我们的思维接着走,两图情形不同得区别对待:
1.图a中访问的是一个左孩子,按中序遍历顺序,接下来应访问它的根节点。也就是图a中的另一个节点,高兴的是它已被保存在栈中。我们只需这样的代码和上一步一样的代码:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2107
2107

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









