










差值查找
在二分查找中,我们每次比较都可以排除一半的数据量,这个已经是很高效了。如果利用关键字本身的信息,每次排除的数据量充分依赖于关键字的大小,则查找会更高效,这就是差值查找的思想。
下面通过示例代码,比较二分查找和差值查找的不同,在不同中领略差值查找的改良之处。
#include <stdio.h>
#include <stdlib.h>
int InterSearch(int *array, int n, int key)
{
if (array && n > 0)
{
int low, high, mid;
low = 0, high = n - 1;
while (low <= high)
{
//mid = (low + high) / 2; //二分查找
//差值查找
if (array[high] == array[low])
{
if (array[low] == key)
return low;
else
return -1;
}
float rate = (float)(key - array[low]) / (array[high] - array[low]);
if (rate < 0 || rate > 1)
return -1; //比例的值有问题,查找失败
mid = low + (high - low)*rate;
static int i = 1;
printf("查找第 %d 次\n", i++);
if (key < array[mid])
high = mid - 1;
else if (key > array[mid])
low = mid + 1;
else
return mid;
}
return -1;
}
return -1;
}
void main()
{
int array[] = { 1, 3, 5, 6, 7, 8, 9, 11, 13 };
int key = -1;
int sub = InterSearch(array, sizeof(array) / sizeof(int), key);
if (sub != -1)
printf("查找到的下标是 %d , key = %d \n", sub, key);
else
printf("查找失败!\n");
system("pause");
}二分查找
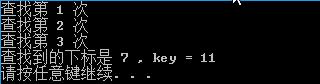
差值查找
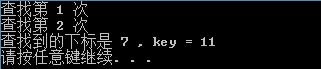
通过打开注释,分别对二分查找和差值查找进行测试。也可以查找一个不存在的关键字,实验发现,差值查找的查找次数明显少于二分查找。
专栏目录















 334
334

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









