






有一个学员问了一个关于Unicode字符编码的奇怪问题。
问题如下:
String strChina = "中国";
(1)直接把每个字符中的内容对应着的整数打印出来,显示的结果就是这个字符的Unicode码,则下面的代码:
for(int i=0; i<strChina.length(); i++)
{
System.out.println(Integer.toHexString((int)strChina.charAt(i)));
}
打印出的结果是:
4e2d
56fd
(2)下面的代码:
byte [] buf = strChina.getBytes("Unicode");
for(int i=0; i<buf.length; i++)
{
System.out.println(Integer.toHexString(buf[i]));
}
打印出的结果是:
ffffffff
fffffffe
2d
4e
fffffffd
56
打印出的“ffffffff”和“fffffffe”表示什么?“2d”和“4e”为什么和直接打印的结果是相反的?
回答如下:
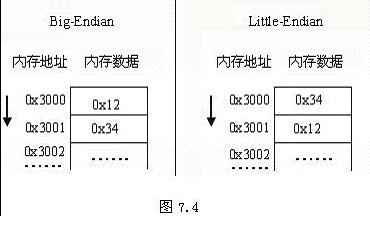
在不同体系结构的计算机系统中,UTF-16编码的Unicode字符在内存中的字节存储顺序是不同的。使用Intel CPU的计算机中,一个多字节数据在内存中的存储形式通常是:低字节在前,高字节在后,这种方式称为Little-Endian(最不重要的字节在先)。但是,在使用其他CPU的一些计算机中,又是以高字节在前,低字节在后的方式存储多字节数据的,这种方式称为Big-Endian(最重要的字节在先)。对于0x1234这样一个双字节数据,使用Little-Endian和Big-Endian两种方式在内存中存储的格式如图7.4所示。
对于采用UTF-16编码的文件,通常都要用字节顺序标记(Byte Order Mark,简称BOM)来说明文件中的字符所使用的字节存储顺序。如果文件以0xFE 0xFF这两个字节开头,则表明文本的其余部分是Big-Endian的 UTF-16编码;如果文件以0xFF 0xFE这两个字节开头,则表明文本的其余部分是Little-Endian的 UTF-16编码;如果文件开头没有使用任何字节顺序标记,则暗指全部文本都是Big-Endian的 UTF-16编码。
“ffffffff”和“fffffffe”实际上是0xff和0xfe的两个字节,把他们当作整数打印时,就成了4个字节, 由于0xfe的最高bit位是1,当它转成4字节的整数时,前面3个字节的所有bit位都补1,结果就成了0xfffffffe。前面打印出:
ffffffff
fffffffe
2d
4e
fffffffd
56
实际上是:
ff
fe
2d
4e
fd
56
前两个字节是在说字节存储顺序!














 1114
1114











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









