







前言
这几晚在看进程相关的内核原理,正好看到了pid这块,看起来不是很复杂,但是引入了pid namespace后增加了一些数据结构,看起来不是那么清晰了,参考了Linux内核架构这本书,看完后感觉还没有理解。所以就在网上找了一些文章参考,其中我发现了一篇质量相当不错的文章,为什么说质量不错呢主要是因为笔者在博文中并没有乱贴代码一桶,也没有按照常规的代码分析,而是以一种追踪溯源的方法还原了整个pid的框架,读了这篇文章后感觉甚好,因此有了本文,本文算不上原创,只是在此基础上将自己的理解重新进行了梳理,相关的图表进行了重绘,加入了一些数据结构的含义表述。关于这篇文章的链接可以参考附录A
PID框架的设计
一个框架的设计会考虑很多因素,相信分析过Linux内核的读者来说会发现,内核的大量数据结构被哈希表和链表链接起来,最最主要的目的就是在于查找。可想而知一个好的框架,应该要考虑到检索速度,还有考虑功能的划分。那么在PID框架中,需要考虑以下几个因素.
- 如何通过task_struct快速找到对应的pid
- 如何通过pid快速找到对应的task_struct
- 如何快速的分配一个唯一的pid
这些都是PID框架设计的时候需要考虑的一些基本的因素。也正是这些因素将PID框架设计的愈加复杂。
原始的PID框架
先考虑的简单一点,一个进程对应一个pid
struct task_struct
{
.....
pid_t pid;
.....
}是不是很easy,回到上文,看看是否符合PID框架的设计原则,通过task_struct找到pid,很方便,但是通过pid找到task_struct怎么办呢?好吧,基于现在的这种结构肯定是无法满足需求的,那就继续改进吧。
注: 以上的这种设计来自与linux 2.4内核的设计
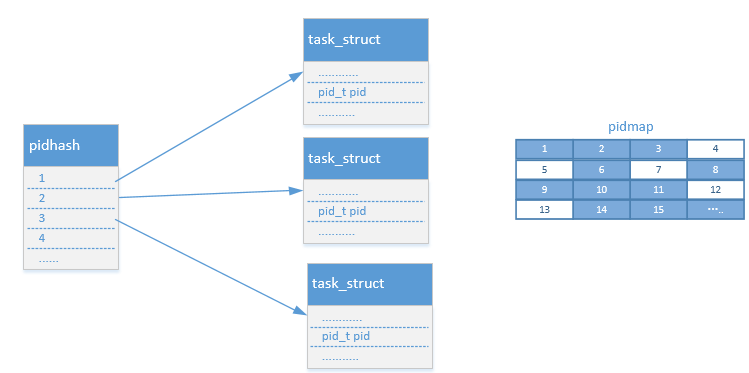
引入hlist和pid位图
struct task_struct *pidhash[PIDHASH_SZ];
struct pidmap {
atomic_t nr_free; //表示当前可用的pid个数
void *page; //用来存放位图
};这样就很方便了,再看看PID框架设计的一些因素是否都满足了,如何分配一个唯一的pid呢,连续递增?,那么前面分配的进程如果结束了,那么分配的pid就需要回收掉,直到分配到PID的最大值,然后从头再继续。好吧,这或许是个办法,但是是不是需要标记一下那些pid可用呢?到此为此这看起来似乎是个解决方案,但是考虑到这个方案是要放进内核,开发linux的那帮家伙肯定会想近一切办法进行优化的,的确如此,他们使用了pid位图,但是基本思想没有变,同样需要标记pid是否可用,只不过使用pid位图的方式更加节约内存.想象一下,通过将每一位设置为0或者是1,可以用来表示是否可用,第1位的0和1用来表示pid为1是否可用,以此类推.到此为此一个看似还不错的pid框架设计完成了,下图是目前整个框架的整体效果.
引入PID类型后的PID框架
熟悉linux的读者应该知道一个进程不光光只有一个进程pid,还会有进程组id,还有会话id,(关于进程组和会话请参考(进程之间的关系)那么引入pid类型后,框架变成了下面这个样子,
struct task_struct
{
....
pid_t pid;
pid_t session;
struct task_struct *group_leader;
....
}
struct signal
{
.... 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 231
231











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









