







在模式识别领域中,最近邻居法(KNN算法,又译K-近邻算法)是一种用于分类和回归的非参数统计方法。
PS:k近邻法打算分两篇来写,不然篇幅太长了!,第一篇我们说怎么构建KD-tree,第二篇我们讲怎么去查到最近邻以及怎么推广到K近邻。
训练样本是多维特征空间向量,其中每个训练样本带有一个类别标签。算法的训练阶段只包含存储的特征向量和训练样本的标签。
分类阶段
k是一个用户定义的常数。一个没有类别标签的向量(查询或测试点)将被归类为最接近该点的k个样本点中最频繁使用的一类。
注意:k是我们自己定义的,k定义的过于小,那么选择相邻的极少样本数就会对我们的模型结果产品重大影响,那么模型的稳定性不高,发生过拟合,如果K值较大,那么较远的训练实例也会产生预测作用,这样模型的准确度就很低了。例如k=1,很难保证最近的一个点就是正确的预测,如果选择的k过大,则会忽略掉训练实例中的大量有用信息,例如k=N,那么无论输入实例是什么最终的结果都将是训练实例中最多的类。
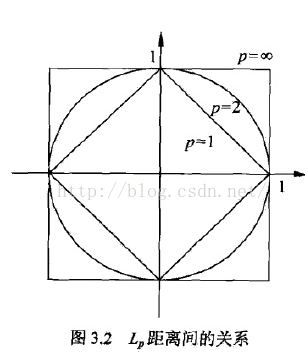
接下来就是要考虑如何度量样本与样本之间的距离了,下面是三种度量方法:

图片直观感觉如下:
和感知机一样,有了距离,那么我们接下来就要选择最优的划分方法了,继续引出损失函数,
k近邻法是多数表决方法,即输入的实例的k个近邻的训练实例中的多数类决定输入实例的类。
这里我使用0-1损失函数衡量,误分类率为:
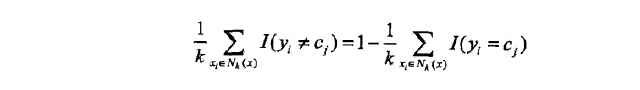
可以看出我们需要努力使样本被正确分类,即最大。
k近邻法最暴力的方法是计算输入实例与每一个训练实例的距离,但如果训练集特别大,那么会非常耗时,为了提高计算效率,下面引出kd树方法。这里我们先谈为什么用KD树,简单来讲就是我们把样本都放在一个空间中,然后根据KD树方法对空间进行划分,就像我们封培住酒店,进去以后大家按男女分房间,男生住1-3楼,女生住4-6楼,这时候如果我们要查找一个女生,我们就可以直接从4-6楼进行查找了,空间划分的方法使我们可以不用搜索某些空间的样本,减少计算量。
注:树是数据结构的一种,长相就是下面这样的
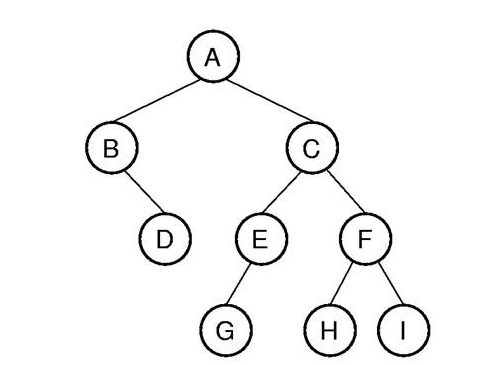
二叉树是每个节点最多有两个子树的树结构。通常子树被称作“左子树”(left subtree)和“右子树”(right subtree)。二叉树常被用于实现二叉查找树和二叉堆。
再多说一个树深度(depth),后面程序中会用到这个概念,比如说A就是第一层,B,C就是第二层,依次类推。
接着我们来说划分方法,下面奉上经典栗子:
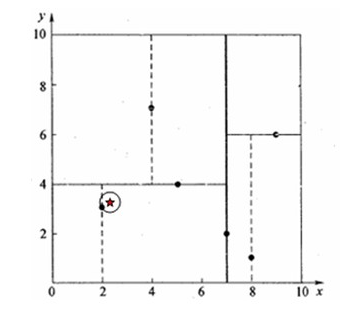
我们的数据集为:(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)共六个二维的数据点。
下图为空间划分的结果:
KD树构建详细步骤:
(1)首先以X作为划分纬度,按照X轴从小到大排列数字:
[2, 3], [4, 7], [5, 4], [7, 2], [8, 1], [9, 6]
X轴的中位数为7,我们就以此作为第一步划分,数据点[7,2]被选作为根节点(看作是其他点的parent),那么数据点[2, 3], [4, 7], [5, 4]被分到左边(成为其左儿子),[8, 1], [9, 6]被分到右边(成为其右儿子)
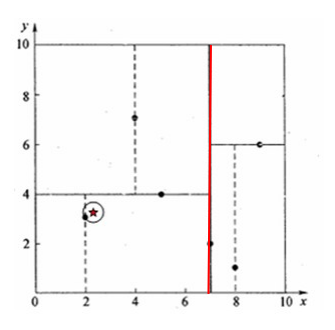
一根红线将我们的空间分为两块,所有数据点分布在两边。
(2)现在我们要进行第二层的划分,按照Y轴进行,左儿子和右儿子都要重新分别排序和划分:
[7,2]的左儿子排序后[[2, 3], [5, 4], [4, 7]]
可以看出中位数为4,于是选出[5, 4]作为根节点,[2,3]作为[5,4]左儿子,[4,7]作为[5,4]右儿子。
[7,2]的右儿子排序后为[[8, 1], [9, 6]]
选出[9,6]为根节点,[8,1]作为其左儿子(要保证左边的y小于的根节点的)
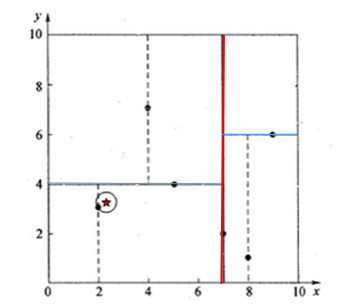
可以看出所有的数据点都找到了自己的空间位置,划分结束,如果还有点没有被划分完全,那么我们继续又从X轴开始交替划分,比如数据特征为(性别、年龄、身高),那么就按性别、年龄、身高为标准交替划分,直到数据划分完毕。
我们将上图转化为二叉树形式的话,就是下图这个东东了:
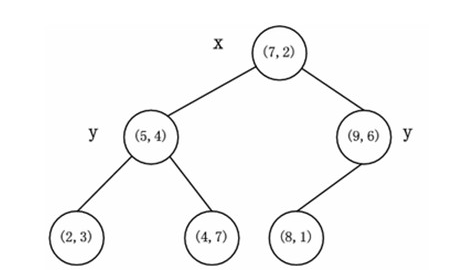
又到了吃瓜群众激动的时候,上代码,意味着这篇终于要结束了。。。。。
import numpy as np
example = [[2,3],[5,4],[9,6],[4,7],[8,1],[7,2]]
L = len(example)
n = len(example[0])
i = 1
class Node(object):
def __init__(self,root,dim):
self.left = None
self.right = None
self.parent = None
self.root = root
self.dim = dim
def insertLeft(self,newNode,depth):
if self.left == None:
self.left = newNode
newNode.parent = self
newNode.dim = depth%n
def insertRight(self,newNode,depth):
if self.right == None:
self.right = newNode
newNode.parent = self
newNode.dim = depth%n
def median(data):
mean = len(data) / 2
return data[mean],mean
def KdTree(exp,depth):
global i
lenth = len(exp)
exp = sorted(exp,key = lambda x:x[depth%n])
t,mean = median(exp)
kdtree = Node(t,depth%n)
print exp,lenth,lenth/2
i = i + 1
if lenth > 1:
kdtree.insertLeft(KdTree(exp[0:lenth/2],depth+1),depth + 1)
if i < L:
kdtree.insertRight(KdTree(exp[lenth/2+1:lenth],depth+1),depth + 1)
return kdtree
kd_tree = KdTree(example,0)
print kd_tree.right.root
PS:换了个编译器配色是不是好看多了? 另外为啥分两部分讲,主要原因还是代码太长了!我本着详细解释代码逻辑的精神,一次解释太多我自己会晕。
(1)首先是引入我们要用的库numpy,然后把我们的数据样本装入example,求出样本量L,样本的特征维度n,i的作用主要是控制程序,后面会用到。
(2)我们要定义一个Node类(就是像人类、动物类、植物类),它的基本属性是有left\right\parent\root\dim(就是上面讲的有左儿子、右儿子、parent、该节点的数据值和划分的维度),它可以有两个方法就是insertLeft\insertRight(对应就是生一个左儿子/右儿子)
(3)然后我们定义了一个median求中位数
(4)然后的然后我们定义了一个构建kd树的函数KdTree,这部分用到了回朔这个古老好用的算法,这个算法是深度优先的,就是先达到树的最后一层,对于第一次接触这个算法的吃瓜群众理解起来可能稍微难,但是跟着我一步步走代码就没问题。
第一层:
lenth = len(exp)
exp = sorted(exp,key = lambda x:x[depth%n])
t,mean = median(exp)
kdtree = Node(t,depth%n)
这时候Lenth = 6 ,对数据点进行按X排序,depth = 0 ,n=2,找到中位数点,将其赋值给kdtree,
第一层:
第一个点[7,2]就被构造出来了,接下来就开始执行:
kdtree.insertLeft(KdTree(exp[0:lenth/2],depth+1),depth + 1)
第二层:
KdTree(exp[0:lenth/2],depth+1)
这个时候Lenth = 3,传入的exp = [[2, 3], [5, 4], [4, 7]],第二个点被[5,4]被选出来了,kdtree = [5,4]这个时候继续执行:
第三层:
kdtree.insertLeft(KdTree(exp[0:lenth/2],depth+1),depth + 1)
Lenth=2,kdtree = [2,3],返回上一层
第二层:
执行插入左子树操作,即[5,4].Left = [2,3],第二层继续往下执行插入右子树操作。
第三层:
此时的数据为[4,7],kdtree=[4,7],不满足lenth > 1,返回上一层
第二层:
执行[5,4].right = [4,7],第二层执行完毕,返回上一层
第一层:
返回的第二层kdtree为[5,4],执行[7,2].left= [5,4],继续往下执行插入右子数操作,数据点为[8,1],[9,6]
第二层:
执行插入左子数操作,第二层kdtree = [9,6],进入第三层
第三层:
数据点为[8,1],回到第二层
第二层:
执行[9,6].left = [8,1],回到第一层
第一层:
执行[7,2].right = [9,6],程序执行完毕,卒。
最后你可以来验证一下程序对不对:比如说print左子树的右子树看是不是[4,7]
更多最新文章:扫码关注风口上的交易狗















 118
118











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









