










在上一篇文章中讲了FileInputStream
本文将介绍一个特殊的输入字节流:FilterInputStream,以及与之相随的一个经典的设计模式,装饰者模式。
在之前的文章中提到,InputStream的读取是以byte为单位的,但是我们日常中经常会读写其他类型的数据,当然,我们可以把读取出来的字节进行转码,转成我们需要的数据,那么能不能直接读取字符,int等数据呢?能,只需要利用DataInputStream这个类。
1 FilterInputStream 剖析
FilterInputStream是InputStream一个特殊的子类,关于它和InputStream的关系,可以参照这篇文章java io -- InputStream,它有一个很重要filed:
protected volatile InputStream in;上一张这个类的结构图如下:
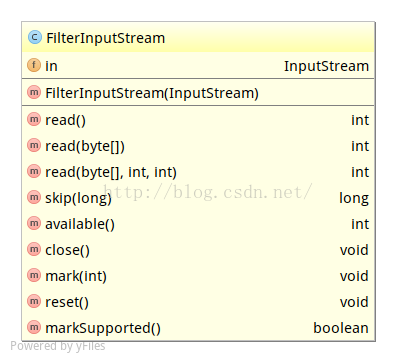
结构图有些说不太清楚,我这里把简略后的源码展示出来:
package java.io;
public class FilterInputStream extends InputStream {
/**
* The input stream to be filtered.
*/
protected volatile InputStream in;
/**
* Creates a <code>FilterInputStream</code>
* by assigning the argument <code>in</code>
* to the field <code>this.in</code> so as
* to remember it for later use.
*
* @param in the underlying input stream, or <code>null</code> if
* this instance is to be created without an underlying stream.
*/
protected FilterInputStream(InputStream in) {
this.in = in;
}
/**
* Reads the next byte of data from this input stream. The value
* byte is returned as an <code>int</code> in the range
* <code>0</code> to <code>255</code>. If no byte is available
* because the end of the stream has been reached, the value
* <code>-1</code> is returned. This method blocks until input data
* is available, the end of the stream is detected, or an exception
* is thrown.
* <p>
* This method
* simply performs <code>in.read()</code> and returns the result.
*
* @return the next byte of data, or <code>-1</code> if the end of the
* stream is reached.
* @exception IOException if an I/O error occurs.
* @see java.io.FilterInputStream#in
*/
public int read() throws IOException {
return in.read();
}
/**
* Reads up to <code>byte.length</code> bytes of data from this
* input stream into an array of bytes. This method blocks until some
* input is available.
* <p>
* This method simply performs the call
* <code>read(b, 0, b.length)</code> and returns
* the result. It is important that it does
* <i>not</i> do <code>in.read(b)</code> instead;
* certain subclasses of <code>FilterInputStream</code>
* depend on the implementation strategy actually
* used.
*
* @param b the buffer into which the data is read.
* @return the total number of bytes read into the buffer, or
* <code>-1</code> if there is no more data because the end of
* the stream has been reached.
* @exception IOException if an I/O error occurs.
* @see java.io.FilterInputStream#read(byte[], int, int)
*/
public int read(byte b[]) throws IOException {
return read(b, 0, b.length);
}
/**
* Reads up to <code>len</code> bytes of data from this input stream
* into an array of bytes. If <code>len</code> is not zero, the method
* blocks until some input is available; otherwise, no
* bytes are read and <code>0</code> is returned.
* <p>
* This method simply performs <code>in.read(b, off, len)</code>
* and returns the result.
*
* @param b the buffer into which the data is read.
* @param off the start offset in the destination array <code>b</code>
* @param len the maximum number of bytes read.
* @return the total number of bytes read into the buffer, or
* <code>-1</code> if there is no more data because the end of
* the stream has been reached.
* @exception NullPointerException If <code>b</code> is <code>null</code>.
* @exception IndexOutOfBoundsException If <code>off</code> is negative,
* <code>len</code> is negative, or <code>len</code> is greater than
* <code>b.length - off</code>
* @exception IOException if an I/O error occurs.
* @see java.io.FilterInputStream#in
*/
public int read(byte b[], int off, int len) throws IOException {
return in.read(b, off, len);
}
/**
* Closes this input stream and releases any system resources
* associated with the stream.
* This
* method simply performs <code>in.close()</code>.
*
* @exception IOException if an I/O error occurs.
* @see java.io.FilterInputStream#in
*/
public void close() throws IOException {
in.close();
}
}
从源码中可以看出,这个FilterInputStream中有一个域:
protected volatile InputStream in;这个域是在构造方法中传入的:
protected FilterInputStream(InputStream in) {
this.in = in;
}
而且这个类中的read方法并不像FileInputStream进行了实现,而只是一种“伪”实现:
public int read() throws IOException {
return in.read();
}其实只是用了这个构造方法传入的这个InputStream的read方法。
上面只是介绍了一下这个类,那么在java中,这个FilterInputStream有什么作用呢?这就要从它的几个子类说起了,我再上一张FilterInputStream的类图,先看看它的几个子类。

FilterInpustStream子类可以分成两类:
1) DataInputStream能以一种与机器无关的方式,直接从地从字节输入流读取JAVA基本类型和String类型的数据。
2 )其它的子类使得能够对InputStream进行改进,即在原有的InputStream基础上可以提供了新的功能特性。日常中用的最多的就是ButtferInputStream,使得inputStream具有缓冲的功能。
接下来我们就以DataInputStream和BufferInputStream对此进行深入剖析。
DataInputStream
之前的InputStream我们只能读取byte,这个类使得我们可以直接从stream中读取int,String等类型。先把这个类几个方法及说明列出来如下(部分):
Method Summary
| Methods | |
| Modifier and Type | Method and Description |
| int | read(byte[] b) Reads some number of bytes from the contained input stream and stores them into the buffer array b. |
| int | read(byte[] b, int off, int len) Reads up to len bytes of data from the contained input stream into an array of bytes. |
| boolean | See the general contract of the readBoolean method of DataInput. |
| byte | readByte() See the general contract of the readByte method of DataInput. |
| char | readChar() See the general contract of the readChar method of DataInput. |
| void | readFully(byte[] b, int off, int len) See the general contract of the readFully method of DataInput. |
| int | readInt() See the general contract of the readInt method of DataInput. |
| readUTF() See the general contract of the readUTF method of DataInput. | |
| static String | Reads from the stream in a representation of a Unicode character string encoded in modified UTF-8 format; this string of characters is then returned as a String. |
有了DataInputStream后,我们就可以直接读取int,boolean了,下面有一个例子,简单说明DataInputStream的使用。
try {
DataOutputStream out = new DataOutputStream(new FileOutputStream("/home/zhaohui/tmp/readPrim"));
out.writeInt(123);
out.writeUTF("你好");
out.writeBoolean(true);
out.flush();
out.close();
DataInputStream in = new DataInputStream(new FileInputStream("/home/zhaohui/tmp/readPrim"));
int a = in.readInt();
System.out.println("first int is "+a);
String b = in.readUTF();
System.out.println("second string is "+b);
boolean c= in.readBoolean();
System.out.println("third boolean is "+c);
in.close();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}输出:
first int is 123
second string is 你好
third boolean is true
在例子中,我们将一个FileInputStream传入到DataInputStream中,从而使得我们可以直接对文件读取写入int,或者boolean等。
DataInputStream原理
所有的输入流都是对byte的操作,这个类能直接读取int,说明内部一定是对byte进行了处理,我们看一下readInt()方法的源码。
public final int readInt() throws IOException {
int ch1 = in.read();
int ch2 = in.read();
int ch3 = in.read();
int ch4 = in.read();
if ((ch1 | ch2 | ch3 | ch4) < 0)
throw new EOFException();
return ((ch1 << 24) + (ch2 << 16) + (ch3 << 8) + (ch4 << 0));
}正如我在前一篇文章中所说,java每个int是4个字节,而InputStream的read是面向字节的,也就是每次只能读取1个字节,因此在readInt这个方法中,读取出4个字节,再进行处理成一个int,这里我们不对处理过程进行深究。
对于其他的方法思想大致一样,不过由于对于String类型需要对字符进行编码,对字符的长度进行传递,会复杂一点,这里就不多说了,关键是这个类算是对InputStream的一个封装。
BufferedInputStream
我这里再介绍另一个常用的FilterInputStream类,BufferedInputStream类。
这个类提供了一个缓存来加速我们从输入流的读取。
由于我们从InputStream中读取数据时,一般都会用到os的io,或者网络io,这都是会耗费大量时间的操作,比如我们现在从文件读取前20个字节,过一会又从文件读取20个字节,这就是两次io,好的,有了BufferedInputStream,就解决这个两次io的问题,这个类在read时,干脆多读一部分数据进来,放在内存里,等你每次操作流的时候,读取的数据直接从内存中就可以拿到,这就减少了io次数,加快我们的io。
我这里只解析BufferedInputStream中的read()方法,有兴趣的可以在jdk里查看其他部分。
public class BufferedInputStream extends FilterInputStream {
//....省略部分源码
private static int DEFAULT_BUFFER_SIZE = 8192;
private static int MAX_BUFFER_SIZE = Integer.MAX_VALUE - 8;
protected volatile byte buf[];
public synchronized int read() throws IOException {
if (pos >= count) {
fill();
if (pos >= count)
return -1;
}
return getBufIfOpen()[pos++] & 0xff;
}
private void fill() throws IOException {
byte[] buffer = getBufIfOpen();
if (markpos < 0)
pos = 0; /* no mark: throw away the buffer */
else if (pos >= buffer.length) /* no room left in buffer */
if (markpos > 0) { /* can throw away early part of the buffer */
int sz = pos - markpos;
System.arraycopy(buffer, markpos, buffer, 0, sz);
pos = sz;
markpos = 0;
} else if (buffer.length >= marklimit) {
markpos = -1; /* buffer got too big, invalidate mark */
pos = 0; /* drop buffer contents */
} else if (buffer.length >= MAX_BUFFER_SIZE) {
throw new OutOfMemoryError("Required array size too large");
} else { /* grow buffer */
int nsz = (pos <= MAX_BUFFER_SIZE - pos) ?
pos * 2 : MAX_BUFFER_SIZE;
if (nsz > marklimit)
nsz = marklimit;
byte nbuf[] = new byte[nsz];
System.arraycopy(buffer, 0, nbuf, 0, pos);
if (!bufUpdater.compareAndSet(this, buffer, nbuf)) {
// Can't replace buf if there was an async close.
// Note: This would need to be changed if fill()
// is ever made accessible to multiple threads.
// But for now, the only way CAS can fail is via close.
// assert buf == null;
throw new IOException("Stream closed");
}
buffer = nbuf;
}
count = pos;
int n = getInIfOpen().read(buffer, pos, buffer.length - pos);
if (n > 0)
count = n + pos;
}
}从上面的代码中看到,这个类有一个buf[],也就是用来当做缓存的字节数组。每次调用read读取数据时,先查看要读取的数据是否在缓存中,如果在缓存中,直接从缓存中读取;如果不在缓存中,则调用fill方法,从InputStream中读取一定的存储到buf中。
因此利用BufferedInputStream读取数据时,在一定的情况下是可以加速的。
装饰者模式
在讲了FilterInputStream之后,就必须要提到一个设计模式:装饰者模式(decorator pattern)。
我这里不是专门讲解装饰者模式的,只是说明装饰者模式在流里的应用。
装饰者模式,顾名思义,是对原有类进行了一定的装饰,装饰后的类必须和原有的类拥有相同的方法,当然,可以在原有类的基础上进行扩展。
这里的装饰者模式通过包含一个原有的Inputstream对象,并且将InputStream原有的方法或直接暴露,或进行装饰后暴露,又或者添加了新的特性,如DataInputStream中的readInt(),BufferedInputStream中的缓存功能。
其实这里还有一个话题,为什么InputStream选择装饰者模式,而非直接继承的方法来扩展,这就是装饰者模式VS继承。
为了回答这个问题,如果我用了继承,看看我们的类图是什么样的。
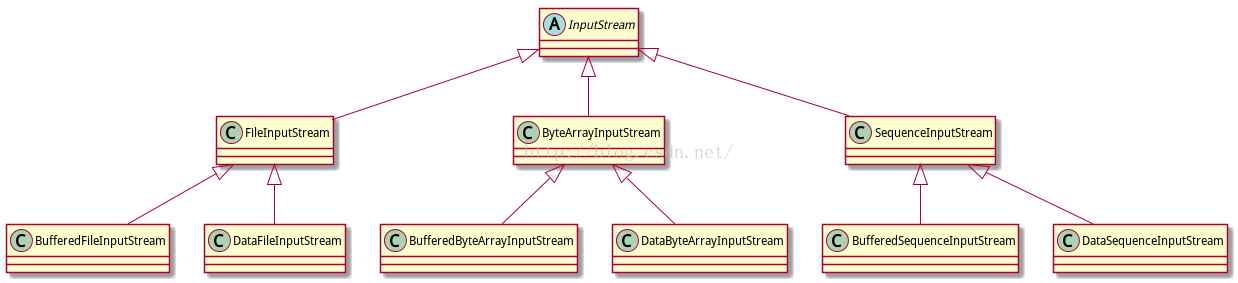
如图所示,我展示的还只是一部分类图,如果单纯的使用继承,就会造成类的“爆炸”式增长。
我在这里做个简单的分析,为什么造成这种爆炸式的增长。
在InputStream的直接子类中,如FileInputStream,都是定义了输入流的<来源>,或者说是介质,通过文件,或者网络。而FilterInputStream的子类并不是增加了流的来源,而只是改善了流读取方法,比如添加了缓存,直接读取int,String等类型。
可以这样简单的认为,InputStream的直接子类是“目的”,而FilterInpustStream的子类是“方法”,我们用一个InputStream就是要用目的和方法。
直接使用继承,可以实现“目的”和“方法”,但是每一种来源的输入流,都需要改善流读取方法,因此在使用继承时,每一个InputStream的子类都需要DataInputStream,BufferedInputStream这几个类提供的“装饰作用”的功能,因此需要的类的数目就是A*B的数目。
而直接使用装饰者模式,将InputStream的几个直接子类进一步抽象,在此基础上提供装饰作用,所需要的类的数目是A+B。使用装饰者模式使得java类的更有层次性,类的数目得到充分控制。这就是装饰者模式相比于继承的优势。

















 2571
2571

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









