







算法原理
决策树(Decision Tree)是一种经典的数据挖掘算法,它的应用很广泛,具体到算法本身也有不同的策略。通过训练数据构建决策树,可以高效的对未知的数据进行分类。决策数有两大优点:1)决策树模型可以读性好,具有描述性,有助于人工分析;2)效率高,决策树只需要一次构建,反复使用,每一次预测的最大计算次数不超过决策树的深度。它是根据特征(feature)的值逐步把数据分类,直到所有的叶子节点属于同一个类型结束。决策树都是贪婪的。
决策树的核心思想是通过不同的特征划分方式将数据逐一通过不同的树枝流向不同的叶子节点,根据不同的策略对同一个数据集可以构成不同的决策树,由于决策树的构建是一个NP问题,很长时间内找不到非常好的决策树构建方式。后来根据信息熵的定义,产生了大名鼎鼎的ID3构建决策树方法,决策树得以流行起来。
信息熵的表达式为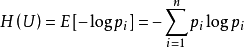
决策树的划分方法有以下几种:
- ID3
选取能够得到最大信息增益(information gain)的特征为数据划分归类,直到全部划分结束而不对树的规模进行任何控制。等树生成之后,执行后剪枝。信息增益的潜在问题是,比如有一个数据集含有一个特征是日期或者ID,则该特征会得到最大的信息增益,但是显然在验证数据中不会得到任何的结果。C45的信息增益比就是解决这个问题的。 - C45
选取能够得到最大信息增益率(information gain ratio)的特征来划分数据,并且像ID3一样执行后剪枝。是ID3的后续版本并扩展了IDC的功能,比如特征数值允许连续,在分类的时候进行离散化。 信息增益率:
“Gain ratio takes number and size of branches into account when choosing an attribute,and corrects the information gain by taking the intrinsic information of a split into account (i.e. how much info do we need to tell which branch an instance belongs to).” - C50
这是最新的一个版本,是有许可的(proprietary license)。比之C45,减少了内存,使用更少的规则集,并且准确率更高。 - CART
CART(Classification and Regression Trees)分类回归树,它使用基尼不纯度(Gini Impurity)来决定划分。它和C45基本上是类似的算法,主要区别:1)它的叶节点不是具体的分类,而是是一个函数f(),该函数定义了在该条件下的回归函数。2)CART是二叉树,而不是多叉树。
虽然ID3有一定的缺陷,但它是学习决策树最经典的入门方法,以ID3方法为例,详解使用python进行决策树工作。
ID3算法能得出结点最少的决策树。
ID3算法步骤:
⒈ 对当前例子集合,计算各属性的信息增益;
⒉ 选择信息增益最大的属性Ak;
⒊ 把在Ak处取值相同的例子归于同一子集,Ak取几个值就得几个子集;
⒋ 对既含正例又含反例的子集,递归调用建树算法;
⒌ 若子集仅含正例或反例,对应分枝标上P或N,返回调用处。
python实例
以《机器学习实战》中的例子为例,根据不浮出水面是否可以生存和是否有脚蹼两个特征划分是否属于鱼类。
样本 不浮出水面可以生存 是否有脚蹼 属于鱼类
0 1 1 1
1 1 1 1
2 1 0 0
3 0 1 0
4 0 1 0
利用ID3算法进行计算的步骤如下:
- 计算整体的信息熵,利用两个特征的类别进行计算
- 划分数据集,将分别根绝两个特征生成两个子数据集
- 计算字数据集的信息增益,挑选出最适合分类的特征,生成 两个树枝,依次类推递归调用
- 根据实际情况定义叶子节点
新建一个tree.py文件,代码如下:
#coding=utf-8
from math import log
import operator
#建立划分决策树的数据集,前两个值为特征是否存在,最后一个为键值,这里表示是否为鱼,相当于一个拥有两个特征的二分类问题
def createDataSet():
dataSet = [[1, 1, 'yes'],
[1, 0, 'no'],
[1, 1, 'yes'],
[0, 1, 'no'],
[0, 1, 'no']]
labels = ['no surfacing','flippers']
#change to discrete values
return dataSet, labels #返回数据集合标签
#计算数据集的信息熵
def calcShannonEnt(dataSet):
numEntries=len(dataSet) #数据集的长度,这里返回的结果是5
labelCounts={} #创立一个数据字典,健为标签值,即yes或者no,键值为统计得到的次 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 3312
3312











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









