






分布式系统总结
我们的系统一直是分布式的。即便在虚拟化、容器技术出现之前,我想他也是一个分布式系统。今天尝试将我对分布式的理解做一些总结。
为什么要分布式?
我想首先是money方面的问题。随着产品支持的容量增加,软件的计算量、存储的数据都变得很大。Grosch定理说CPU的计算能力与它的价格的平方成正比。也就是说如果你付出两倍的价钱,就能获得四倍的性能。这么看其实花钱买高性能的CPU更划算。很遗憾Grosch定理不再适用了。另一方面,随着计算量的增加,没有办法找到这样强大的计算机做到这么大的计算量(比如春晚摇红包的计算量估计不可能由一台计算机搞定)。这要求必须将计算能力一般的计算机组织到一起,完成超级计算。
其次,是部署和运维的考虑。所有计算都在一个计算机上,一个故障就全玩玩了。而多个计算机共同工作时,一个故障不会影响大局。在升级时,也可以先升级试用某一些计算机,效果满意再升级全部。
第三,当业务持续增长时,分布式系统能更好应对 —— 多加入一些计算机就行了。
其实不需要多说,云计算的兴起已经说明了一切。
下面聊一下分布式系统中主要考虑的问题。
总的讲,一个分布式系统必须考虑的几个大块: 接入、计算、存储, 以及这几块之间的数据通信 ——交换。

一、对外统一接口,内部结点透明,多业务并发
一个系统对外一定是接口固定的,外部用户一定要有一个固定的入口接入系统。比如提供固定的IP地址、偶联地址、或者某协议地址或域名。内部的计算结点不能直接对外可见,否则无法做可靠性、水平扩展等等工作。这就要求有一个接入部分,同时要在接入部分和内部结点之间做一次负载均衡。通常负载均衡策略是根据自己的业务特点决定的。
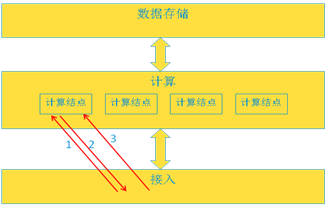
最简单的就是轮选计算结点,当计算结点的个数发生变化(水平扩展或缩容)时需要负载均衡器感知到即可。但往往业务特点决定了不会选择简单轮选策略,比如:一个业务是长连接的,长连接意思是一个业务流程需要和外部多条消息交互。那么在一个业务流程中,必须将消息都发到同一个计算结点,这就需要设计自己特点的转发策略。比如下面消息3必须也发给第一个结点。
再有,还可能和数据存储方式有关系,具体来说:如果计算结点是纯计算(即不保存用户数据),那么每次业务流程的开始都可以随意选择一个计算结点,他从存储部分获取需要的数据,业务完成后再推送回存储部分。但这种方式增加了数据交换的负担。比如下图第一次业务完成后,第二次业务完全可以选择第三个计算结点。
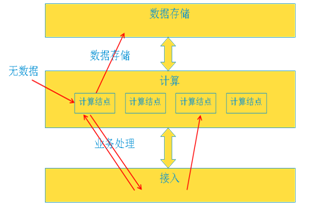
有时产品希望将用户数据cache到计算结点上面,这样就不用每次业务来临都从存储部分拉去数据,这种方式减少了数据交换,但是带来了其他方面的考虑:用户数据和计算结点有强耦合关系,必须通过一定的负载策略将特定的用户发送到特定的计算结点处理。这又对可靠性、水平扩展方面带来了难度:因为必须根据用户和计算结点的关系进行负载策略的调整。
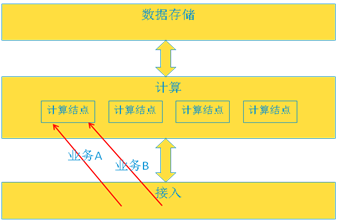
对多业务并发的情况是设计负载均衡策略时要考虑的又一个问题。即对同一个用户同时出现多个业务操作——即流程冲突。比如对一个用户,可以进行业务A,也可以进行业务B。 但是如果在执行业务A的时候,业务B的请求又上来了,系统需要处理这种情况。这里有两个考量:1是需要识别出正在执行A,2是如果处理AB同时进行的业务,还是终止某一个。 其中考量1又会牵扯到负载均衡策略的设计,比如,同一个用户的业务是否都需要转向同一个计算结点?
总的说,我认为应该尽可能的将计算和数据解耦,由此带来的数据交换的问题可以尝试减少数据量(必须仅传输本次业务流程必须的数据)来减少。同时将业务拆分为更小、独立的service,这样也会降低数据交换。 而这样可以带来计算结点管理的简单。
二、高稳定性
稳定性来自两个方面:一个是程序健壮,这反映的是每一个结点都高可靠。 二是系统健壮,即一个结点出问题不影响整个系统运行。我们讨论第二点。
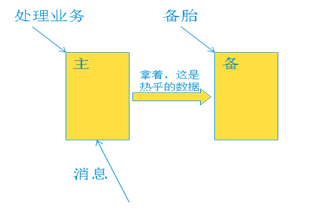
最早期的可靠性保证是简单、粗暴的方式,一般简单粗暴都是最有效的。比如主备热备份的方式。一个单板运行处理业务(主板),另一个单板空转(备板),就等候着处理板出问题时自己顶上。主板实时的将处理的业务数据同步到备板。可以说备板就是主备的克隆。转发系统一旦发现主板出现问题,直接将消息链路切换到备板,备板可以继续运行。这种方式提供了高可靠性,代价是硬件的低效利用。
也许可以在上述方案上优化。比如互备的方式:即两个板子都处理业务,但是互相做备份。即把两块板子配置成好基友,每个上面都有对方的配置和运行数据。当一块板子出现问题时,另一个把他的业务也接管过来,自己干两个人的活。这样似乎弥补了上面备板空跑的情况,有效利用了资源。但相信睿智的您肯定发现:互备的两个基友资源使用率不可以超过50%,一旦超过,也是无法接管对方的业务。 所以本质上并没有改变。
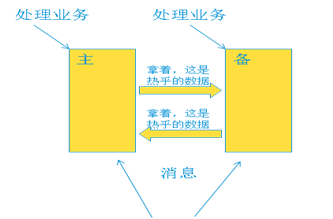
再继续分析,其实系统中计算结点出现故障的概率是不高的,多个结点同时故障的概率更低。所以可以多个业务处理板由一个备板备份(n+1)的方式。这种方式可以提高硬件的使用率。当然还可以做n+m的备份方式。我们不继续做分析了。
总结这些保证可靠性的思路无非两个方面:一是通过系统存在冗余的计算能力,确保计算机出问题时还有计算结点顶上去。二是在保证这种计算能力的同时,还保证了计算结点的数据(参考粗暴方案中的数据同步) 。我们要清晰的分开考虑这两个问题,这也是我上面说的计算和数据解耦。
事实上,虚拟化技术的出现解决了计算能力的保证,无论是openstack,还是容器都可以通过他们的技术使得在一个计算结点故障时,再创建一个相同能力的计算结点出来。而数据,应该放到计算之外的地方去。
三、数据存储
为了讨论方便,我们将数据分为两类:静态数据(配置)和动态数据(用户数据)。这两种数据的对待方式是不同的。
对于静态数据来说,数据必须随时有效,必须做持久化存储。所以必须在硬盘或数据库中有数据。同时,这类数据的特点是读多写少,或几乎没有写,而读取数据的频率非常高,所以应该做一个读缓存层,数据在内存中cache,保证效率。
对于用户数据来说,情况就又不一样。用户一旦接入网络,就需要将数据建立并存储下来,以后用户做业务就要操作这些数据。一种方案是将数据存储在业务处理结点上,这是最容易的方案。但是这种方案使计算和数据产生的绑定,在负载均衡、可靠性、水平伸缩方面都需要考虑很多。 另一种方案是将数据拉远,放到存储服务中。这种方式降低了计算与数据的耦合,但是增加了数据交换,对网络提出了要求,同时数据获取的异步过程对编码也有一些改动。 这方面在前面也讨论了很多,计算与存储绑定的方案, 计算与存储分离的方案我们都经历过。 总的讲我认为应该分离,因为计算结点可靠性的原因、计算结点扩展性的原因等等......当然也是一个权衡,需要根据项目的情况决定。
四、能力水平扩展
这是虚拟化技术带来的功能。在虚拟化出现之前,我们扩容一次都要重新配置负荷分担策略,整个系统重启,那时的符合分担与硬件单元是静态配置的。谈不上能力扩展。虚拟化使得系统和硬件解耦,软件看到的不再是某框某槽某型号的CPU,而是“资源”。在增加、重启一个虚拟机非常容易的情况下,原来的很多问题都不再是问题:比如一个硬件发生故障我想立即启动一个相同的(这在以前是不可能的除非人跑到机房去弄), 再比如业务量增多了我需要加一些资源(以前也要人去启动更多的服务器)。
虚拟化技术带来了这些,那么怎么实现系统的能力扩展:
1. 首先要有一套检测系统来监控系统运行的状态,
2. 还要有一个决策机制来计算和决策弹性动作的执行
3. 还有考虑配套的负载均衡的变化、用户数据的访问、正在进行中的业务如何处理等等。。。
介绍一个集中管理式思路,各个计算结点将资源使用情况上报给总监控结点,再由决策机制计算后决定弹性动作。

弹性过程启动资源申请或释放,同时伴随着负载均衡策略的调整,用户数据的获取等等。这里是比较难的地方,不同的设计差别也比较大。假如有产品对业务成功率要求变态的高(比如我们项目),要求在弹性过程中也要保持业务成功率,而一个业务的流程又很长的时候就很麻烦。具体来说,比如一个业务要执行10条消息交互,而在第5条的时候监控结点决策出应该扩容,又增加了一些计算结点,这必然导致负载均衡策略的调整。如果不幸的将负载均衡策略设计的与用户有关系,这时一个用户的消息将无法决策往那个计算结点转发。因为新增计算结点后,这个用户的分担策略可能调整到了新结点,但是前5条消息已经在老结点上执行了。。。这里需要根据项目自己的特点设计出符合自己的方案。这里我还是再次推荐计算和数据分离,而弹性的过程也要与业务特点解耦,掺杂了过多的业务逻辑的弹性过程,是很痛苦的,也难以维护。
另外,监控决策是需要时间的。如果业务量激增,可能监控来不及反应系统就冲死了。还是应该有一定的提前预判,由人工来提前扩容。同时,系统的业务忙闲一般是呈规律性的,随着系统的进步,决策系统要增加一些自学习的能力。
五、业务链
假设一个业务进入系统先交给A业务单元,执行完再交给B,C,... 姑且把ABC叫这个业务的执行链。业务链不应该长,应该尽量短(当然有时系统成形后就身不由己了)。在业务链的每个环节,都会存在一次负载均衡选择。这都会引起很多思考。应该把业务单元做的内聚。
同时我也不是主张尽量减少业务单元的类型,把ABCD类型的业务单元捏成一个。不同的业务类型单元需要不同的数据,有不同的弹性伸缩需求,应该分开。
业务链上的结点之间应该送耦合,尽量不需要知道上下游的标识。
六、系统运维监控
主要指整个系统业务运行情况的监控。如各种统计,Log日志,信令跟踪,失败信息,告警等等。
从两个层面来讲:
在系统层面,希望将业务统计在各个业务单元之间联系起来。比如一条业务经过的业务单元,从中窥测分发情况、执行情况等等。这些东西在分析系统问题时很重要。
另一个是代码层面,各种统计最好是非入侵性的,散落在代码各处的统计点对维护来说很难。














 936
936











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









