







原文地址:http://www.ywnds.com/?p=8735
在使用InnoDB存储引擎时,如果没有特别的需要,请永远使用一个与业务无关的自增字段作为主键,除非高并发写入操作可能需要衡量自增主键,后面会讲。
经常看到有帖子或博客讨论主键选择问题,有人建议使用业务无关的自增主键,有人觉得没有必要,完全可以使用如学号或身份证号这种唯一字段作为主键。不论支持哪种论点,大多数论据都是业务层面的。如果从数据库索引优化角度看,使用InnoDB引擎而不使用自增主键绝对是一个糟糕的主意。
下面先简单说说MySQL索引实现
在MySQL中,索引属于存储引擎级别的概念,不同存储引擎对索引的实现方式是不同的,本文主要讨论MyISAM和InnoDB两个存储引擎的索引实现方式。
MyISAM存储引擎
MyISAM引擎使用B+Tree作为索引结构,叶节点的data域存放的是数据记录的地址。下图是MyISAM索引的原理图:
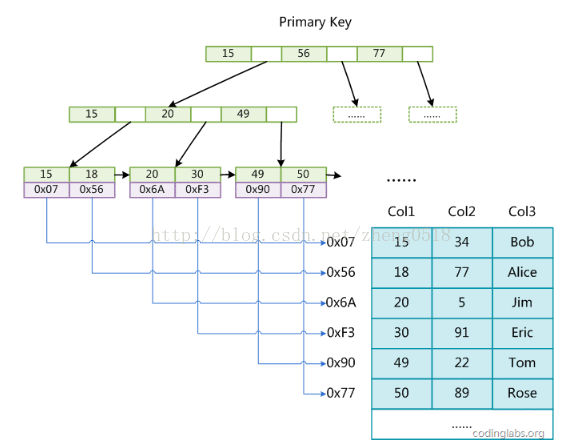
这里设表一共有三列,假设我们以Col1为主键,则上图是一个MyISAM表的主索引(Primary key)示意。可以看出MyISAM的索引文件仅仅保存数据记录的地址。在MyISAM中,主索引和辅助索引(Secondary key)在结构上没有任何区别,只是主索引要求key是唯一的,而辅助索引的key可以重复。如果我们在Col2上建立一个辅助索引,则此索引的结构如下图所示:
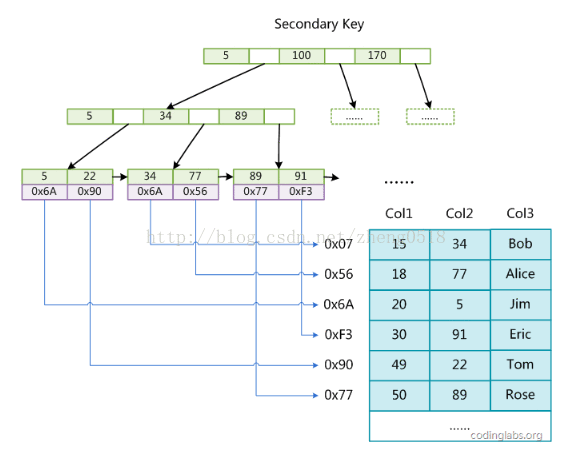
同样也是一颗B+Tree,data域保存数据记录的地址。因此,MyISAM中索引检索的算法为首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其data域的值,然后以data域的值为地址,读取相应数据记录。
MyISAM的索引方式也叫做“非聚集”的,之所以这么称呼是为了与InnoDB的聚集索引区分。
InnoDB存储引擎
虽然InnoDB也使用B+Tree作为索引结构,但具体实现方式却与MyISAM截然不同。
第一个重大区别是InnoDB的数据文件本身就是索引文件。从上文知道,MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。而在InnoDB中,表数据文件本身就是按B+Tree组织的一个索引结构,这棵树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。
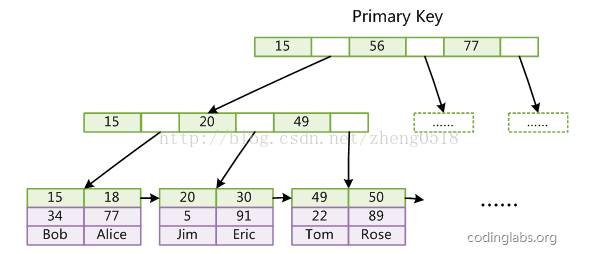
是InnoDB主索引(同时也是数据文件)的示意图,可以看到叶节点包含了完整的数据记录。这种索引叫做聚集索引。因为InnoDB的数据文件本身要按主键聚集,所以InnoDB要求表必须有主键(MyISAM可以没有),如果没有显式指定,则MySQL系统会自动选择一个可以唯一标识数据记录的列作为主键,如果不存在这种列,则MySQL自动为InnoDB表生成一个隐含字段作为主键,这个字段长度为6个字节,类型为长整形。
第二个与MyISAM索引的不同是InnoDB的辅助索引data域存储相应记录主键的值而不是地址。换句话说,InnoDB的所有辅助索引都引用主键作为data域。例如,下图为定义在Col3上的一个辅助索引:
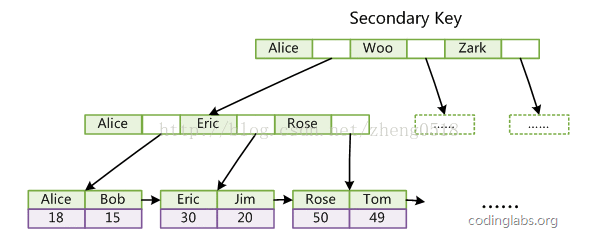
这里以英文字符的ASCII码作为比较准则。聚集索引这种实现方式使得按主键的搜索十分高效,但是辅助索引搜索需要检索两遍索引:首先检索辅助索引获得主键,然后用主键到主索引中检索获得记录。
了解不同存储引擎的索引实现方式对于正确使用和优化索引都非常有帮助,例如知道了InnoDB的索引实现后,就很容易明白为什么不建议使用过长的字段作为主键,因为所有辅助索引都引用主索引,过长的主索引会令辅助索引变得过大。再例如,用非单调的字段作为主键在InnoDB中不是个好主意,因为InnoDB数据文件本身是一颗B+Tree,非单调的主键会造成在插入新记录时数据文件为了维持B+Tree的特性而频繁的分裂调整,十分低效,而使用自增字段作为主键则是一个很好的选择。
InnoDB自增主键
上文讨论过InnoDB的索引实现,InnoDB使用聚集索引,数据记录本身被存于主索引(一颗B+Tree)的叶子节点上。这就要求同一个叶子节点内(大小为一个内存页或磁盘页)的各条数据记录按主键顺序存放,因此每当有一条新的记录插入时,MySQL会根据其主键将其插入适当的节点和位置,如果页面达到装载因子(InnoDB默认为15/16),则开辟一个新的页(节点)。
如果表使用自增主键,那么每次插入新的记录,记录就会顺序添加到当前索引节点的后续位置,当一页写满,就会自动开辟一个新的页。如下图所示:
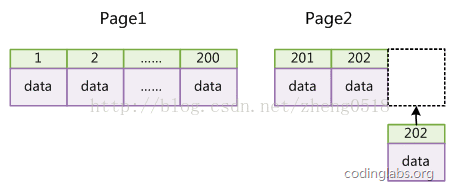
这样就会形成一个紧凑的索引结构,近似顺序填满。由于每次插入时也不需要移动已有数据,因此效率很高,也不会增加很多开销在维护索引上。
如果使用非自增主键(如果身份证号或学号等),由于每次插入主键的值近似于随机,因此每次新纪录都要被插到现有索引页得中间某个位置:
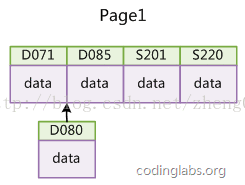
此时MySQL不得不为了将新记录插到合适位置而移动数据,甚至目标页面可能已经被回写到磁盘上而从缓存中清掉,此时又要从磁盘上读回来,这增加了很多开销,同时频繁的移动、分页操作造成了大量的碎片,得到了不够紧凑的索引结构,后续不得不通过OPTIMIZE TABLE来重建表并优化填充页面。
因此,只要可以,请尽量在InnoDB上采用自增字段做主键。
顺序主键什么时候回造成更会坏的结果?
对于高并发工作负载,在InnoDB中按主键顺序插入可能会造成明显的争用。主键上界会成为”热点”,因为所有的插入都发生在这里,所以并发插入可能导致间隙锁竞争。另一个热点可能是AUTO_INCREMENT锁机制:如果遇到这个问题,则可能需要考虑重新设计表或者应用,或者更改innodb_autoinc_lock_mode配置。
自增长在数据库中是非常常见的一种属性,也是很多DBA或开发人员首选的主键方式。在InnoDB存储引擎的内存结构中,对每个含有自增长值的表都有一个自增长计数器。当对含有自增长的计数器的表进行插入操作时,这个计数器会被初始化,执行如下的语句来得到计数器的值:
|
1
|
select
max
(
auto_inc_col
)
from
t
for
update
;
|
插入操作会依据这个自增长的计数器值加1赋予自增长列。这个实现方式称为AUTO-INC Locking。这种锁其实是采用一种特殊的表锁机制,为了提高插入的性能,锁不是在一个事务完成后才释放,而是在完成对自增长值插入的SQL语句后立即释放。
虽然AUTO-INC Locking从一定程度上提高了并发插入的效率,但还是存在一些性能上的问题。首先,对于有自增长值的列的并发插入性能较差,事务必须等待前一个插入的完成,虽然不用等待事务的完成。其次,对于INSERT….SELECT的大数据的插入会影响插入的性能,因为另一个事务中的插入会被阻塞。
从MySQL 5.1.22版本开始,InnoDB存储引擎中提供了一种轻量级互斥量的自增长实现机制,这种机制大大提高了自增长值插入的性能。并且从该版本开始,InnoDB存储引擎提供了一个参数innodb_autoinc_lock_mode来控制自增长的模式,该参数的默认值为1。在继续讨论新的自增长实现方式之前,需要对自增长的插入进行分类。如下说明:
- insert-like:指所有的插入语句,如INSERT、REPLACE、INSERT…SELECT,REPLACE…SELECT、LOAD DATA等。
- simple inserts:指能在插入前就确定插入行数的语句,这些语句包括INSERT、REPLACE等。需要注意的是:simple inserts不包含INSERT…ON DUPLICATE KEY UPDATE这类SQL语句。
- bulk inserts:指在插入前不能确定得到插入行数的语句,如INSERT…SELECT,REPLACE…SELECT,LOAD DATA。
- mixed-mode inserts:指插入中有一部分的值是自增长的,有一部分是确定的。入INSERT INTO t1(c1,c2) VALUES(1,’a’),(2,’a’),(3,’a’);也可以是指INSERT…ON DUPLICATE KEY UPDATE这类SQL语句。
接下来分析参数innodb_autoinc_lock_mode以及各个设置下对自增长的影响,其总共有三个有效值可供设定,即0、1、2,具体说明如下:
- 0:这是MySQL 5.1.22版本之前自增长的实现方式,即通过表锁的AUTO-INC Locking方式,因为有了新的自增长实现方式,0这个选项不应该是新版用户的首选了。
- 1:这是该参数的默认值,对于”simple inserts”,该值会用互斥量(mutex)去对内存中的计数器进行累加的操作。对于”bulk inserts”,还是使用传统表锁的AUTO-INC Locking方式。在这种配置下,如果不考虑回滚操作,对于自增值列的增长还是连续的。并且在这种方式下,statement-based方式的replication还是能很好地工作。需要注意的是,如果已经使用AUTO-INC Locing方式去产生自增长的值,而这时需要再进行”simple inserts”的操作时,还是需要等待AUTO-INC Locking的释放。
- 2:在这个模式下,对于所有”INSERT-LIKE”自增长值的产生都是通过互斥量,而不是AUTO-INC Locking的方式。显然,这是性能最高的方式。然而,这会带来一定的问题,因为并发插入的存在,在每次插入时,自增长的值可能不是连续的。此外,最重要的是,基于Statement-Base Replication会出现问题。因此,使用这个模式,任何时候都应该使用row-base replication。这样才能保证最大的并发性能及replication主从数据的一致。
这里需要特别注意,InnoDB跟MyISAM不同,MyISAM存储引擎是表锁设计,自增长不用考虑并发插入的问题。因此在master上用InnoDB存储引擎,在slave上用MyISAM存储引擎的replication架构下,用户可以考虑这种情况。
另外,InnoDB存储引擎,自增持列必须是索引,同时必须是索引的第一个列,如果不是第一个列,会抛出异常,而MyiSAM不会有这个问题。
|
1
2
|
mysql
>
create
table
test
(
id
int
primary
key
not
null
,
count
int
auto_increment
not
null
)
;
ERROR
1075
(
42000
)
:
Incorrect
table
definition
;
there
can
be
only
one
auto
column
and
it
must
be
defined
as
a
key
|














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









