






导语:时下QQ音乐酷狗音乐等APP似乎让用户觉得它比任何人都更懂得自己的音乐口味,会为用户推荐喜欢的歌曲,每一次都充满了surprise。本文作者Sophia Ciocca将通过介绍音乐推荐始祖Spotify的音乐推荐系统及算法,带大家一探其中究竟。
每个周一,数亿的Spotify用户会在Spotify上看到一个全新的音乐推荐列表,这是一个包含了30首歌曲的自定义混音专辑,被称为“Discover Weekly(每周发现)”,这里边的音乐都是你未曾听过的,但基本上都是你喜欢的。
我是Spotify的忠实粉丝,尤其是“每周发现”。 为什么这么说?因为它令我觉得它比任何人都更懂得我的音乐口味,每周都会为我推荐喜欢的歌曲,并且都是我自己从来不会发现的歌曲,每一次都充满了surprise。
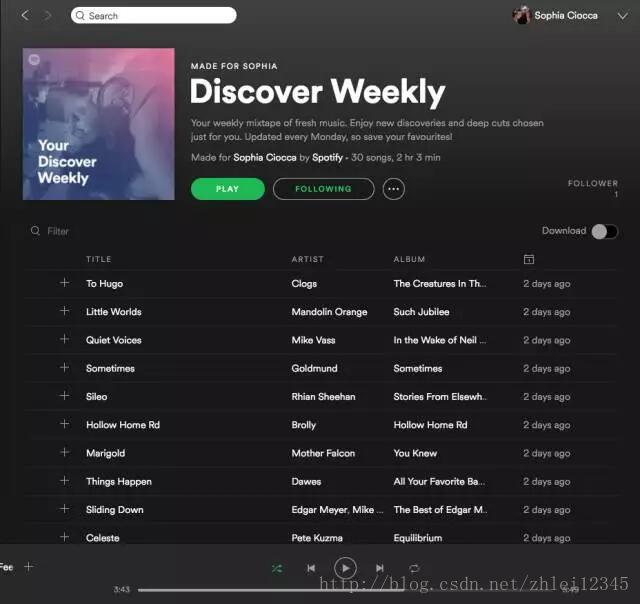
Spotify的“每周发现”播放列表 - 具体来说,是我的播放列表。
事实证明,不仅仅只有我自己中了“每周发现”的毒——很多用户都痴迷于此,这也促使Spotify彻底重新思考他们的产品焦点,将更多的资源投入到基于算法的推荐播放列表中。
下面是Twitter上两位网友的说法:
Dave(A cenobite) @dave_horwitz:
@Spotify Discover Weekly播放列表对我的了解是如此之深。就像一个以前与我一同经历过生死考验的情人一样。
Amanda Whitbred @amandawhitbred:
在这一点上,@ Spotify的“每周发现”非常了解我,以至于它推荐的音乐我都会喜欢。
自从2015年“每周发现”首次上线以来,我一直醉心于研究它是如何向人们推荐音乐的(加上我是Spotify的狂热粉丝,所以有时候我喜欢假装我在那里工作,并且对他们的产品进行研究。)经过三周疯狂的搜索之后,我终于非常幸运地了解到它背后的原理。
那么Spotify是如何每周为数亿用户推荐个性化歌曲的呢?让我们先简单地看下其他音乐服务是如何完成音乐推荐的,然后再了解Spotify如何更好地做到这一点。
在线音乐推荐的简史

早在2000年,Songza就开始使用人工推荐的方式进行在线音乐推荐,并为用户创建播放列表。“人工推荐”意味着一些“音乐专家”或其他推荐人要手动把那些他们认为听起来不错的音乐放到同一个播放列表里(后来,Beats Music也采用了同样的策略)。人工推荐工作是没错的,但它需要手动操作,因此无法考虑每位听众个人音乐品味的细微差别。
像Songza一样,Pandora也是音乐推荐的原始玩家之一。它没有手动标记歌曲的属性,而是采用了更先进一点儿的方法。即先让一群人听音乐,为每个曲目选择一堆描述性的词,并用这些单词把曲目标记起来。然后,Pandora的代码可以简单地筛选某些标签来制作相似音乐的播放列表。
大约在同一时间,来自麻省理工学院媒体实验室的音乐情报机构“Echo Nest”诞生了,并且提出了一种更加先进的方式进行个性化音乐推荐。Echo Nest使用算法分析音乐的音频和文本内容,从而得以进行音乐识别,个性化推荐,播放列表创建和分析。
再往后,Last.fm采用了另一种不同的方法,到今天仍然存在,他们使用了叫做协作过滤的过程来识别用户可能喜欢的音乐。
所以如果上面这些就是其他音乐推荐服务的做法,那Spotify是怎样实现神乎其技的推荐引擎,并且似乎比任何其他服务都更准确地戳中了个人用户的口味的呢?
Spotify的3种推荐模型
Spotify实际上并没有使用一个革命性的推荐模型,而是将其他服务使用的一些最佳策略混合在一起,从而创建自己独特而又强大的发现引擎。
为了创建“每周发现”,Spotify采用以下三种主要类型的推荐模型:
1.协作过滤模型(即Last.fm最初使用的模型),通过分析您的行为和其他人的行为来工作。
2.自然语言处理(NLP)模型,通过分析文本工作。
3.音频模型,通过分析原始音轨本身进行工作。
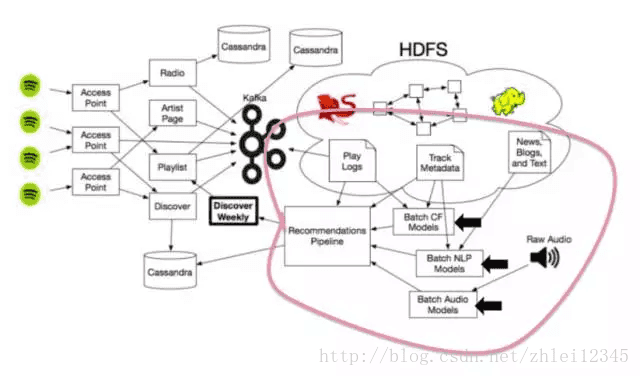
下面,让我们来深入了解这些推荐模式的运作方式!
推荐模型#1:协同过滤
首先需要了解一些背景:当许多人听到“协同过滤”这个词时,他们首先想到的是Netflix,因为他们是首先使用协作过滤来构建推荐模型的公司之一。他们通过使用用户的星级电影评分来了解该把什么电影推荐给其他相似的用户。
在Netflix将“协同过滤”成功应用之后,这个算法的使用速度迅速扩大,现在通常被认为是任何想要构建推荐模型的人的入门算法。
不像Netflix,Spotify没有让用户对音乐进行星级评价。相反,Spotify所用的数据是隐含的反馈 - 具体来说,我们收听的曲目的流数,以及额外的流数据,包括用户是否将曲目保存到自己的播放列表中,或者在收听后访问了歌手页面等等。
但是什么是协同过滤呢,它是如何的发挥作用的呢? 这是一个更高层的抽象,我们现在把它画在下面的这张图里:

Image by Erik Bernhardsson
看懂这张图了吗? 这两个人中的每一位都有一些音乐的偏好 - 左边的人喜欢音乐P,Q,R和S; 右边的人喜欢音乐Q,R,S和T.
通过协同过滤对数据分析后,初步得出这样的结论:
嗯。 你们都喜欢三首相同的音乐——Q,R和S ——所以你们可能是类似的用户。因此,你们每个人都有可能喜欢另一个人听过而你还没听过的其他曲目。
因此,我们建议右边的那个人听一下歌曲P,左边的那个人听一下音乐T。很简单,对吧?
但Spotify是如何在实际操作中使用这一概念来根据数百万其他用户的偏好计算他们的的建议曲目的呢?
…数学矩阵,用Python库就能完成!

实际上,上图的这个矩阵是非常巨大的。 每一行都代表Spotify的1.4亿用户之一(如果您使用Spotify,您可以想象,自己就是此矩阵中的一行),并且每列代表Spotify数据库中的3000万首歌曲之一。
然后,Python库会运行这个漫长而复杂的矩阵分解公式:
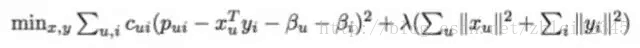
一些复杂的数学
计算完成时,我们就会得到被X和Y表示的两种类型的向量。其中X是用户向量,表示单个用户的口味,Y是表示单个歌曲的资料的歌曲向量。
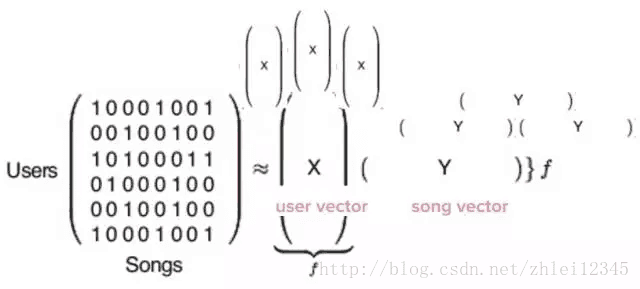
用户/歌曲矩阵产生两种类型的向量:用户向量和歌曲向量。
现在我们有1.4亿个用户向量 - 每个用户就是其中一行 - 以及3000万个歌曲向量。这些向量的实际内容只是一堆数字,它们本身是无意义的,但把它们相互一比较就非常有意义了。
要找到哪些用户的口味和我最相似,协作过滤算法会将我的向量与所有其他用户的向量进行比较,最终揭示与我最相似的用户。Y向量也是一样,歌曲 - 您可以将歌曲的矢量与所有其他歌曲矢量进行比较,并找出哪些歌曲与您正在查看的歌曲最相似。
协同过滤算法的效果其实已经相当不错了,但Spotify为了做得更好还添加了另一个推荐引擎——NLP。
推荐模型#2:自然语言处理(NLP)
Spotify采用的第二种推荐模型是自然语言处理(NLP)模型。这些模型的源数据,顾名思义,是常规的字词 – 歌曲元数据,新闻文章,博客和互联网上的其他文字。

自然语言处理 – 代表了计算机理解人类语言的能力 - 是一个庞大的领域,通过情感分析API来实现。
NLP背后的确切机制超出了本文的范围,并且下面我们介绍的这些场景都是在很高层次上发生的事情:Spotify会不断地浏览网页,不断寻找和音乐有关的博客或其他书面文字,了解人们对特定的艺术家和歌曲谈论的内容——即对这些歌曲经常使用什么形容词和语言,还会讨论哪些其他艺术家和歌曲。
虽然我不知道Spotify如何选择处理其数据的细节,但我可以告诉您Echo Nest如何与之合作。他们会把它们搜集到他们所谓的“文化向量”或“根词汇”中。每个艺术家和歌曲都有数以千计并且每天都在更新的“根词汇”。每个词都有一个权重相关联,它揭示了描述的重要性(粗略地说,权重代表了人们用这个词描述音乐的概率)。
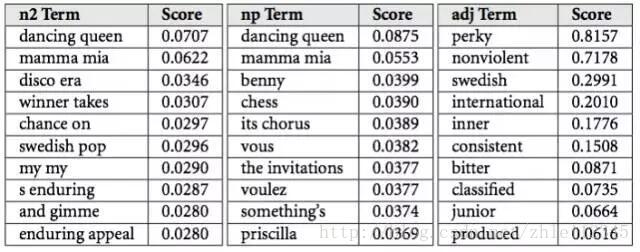
Echo Nest使用的“文化向量”或“根词汇”。表格来自Brian Whitman
然后,就像协同过滤算法一样,NLP模型使用这些词汇和权重来创建歌曲的向量表示,可以用来确定两段音乐是否相似。听起来酷毙了,是不是?
推荐模型#3:原始音频模型
这里有个问题,首先,你可能会在想:但是,亲爱的,我们已经从前两个模型里搜集到了这么多数据!为什么还要在费劲儿分析音频本身呢?
嗯…首先,加上第三个模型可以进一步提高这个推荐服务的准确性。但实际上,使用这种模型还考虑到一个次要目的:与前两种模型类型不同,原始音频模型可以用来发现新歌曲。
例如,你的歌手-作曲家朋友在Spotify上传了一首歌曲,但可能只有50个听众,所以很少有其他听众通过协同过滤算法发现它。它也没有在互联网上的任何地方被提到,所以NLP模型也不会接受它。幸运的是,原始音频模型并不会在意一首歌到底是新的曲目还是流行的曲目,所以在这个算法的帮助下,你朋友的歌曲就可以和其他流行歌曲一起被选择出现在Discover Weekly的播放列表里!
好,解决了为什么的问题,现在我们来探究一下它的原理——我们如何分析原始的音频数据,这似乎听起来很抽象。
方法就是卷积神经网络!
卷积神经网络就是面部识别背后的支撑技术。但在Spotify中,它们被进行了相应的修改,以处理音频数据,而不再是图像数据。下图是一个神经网络架构的例子:
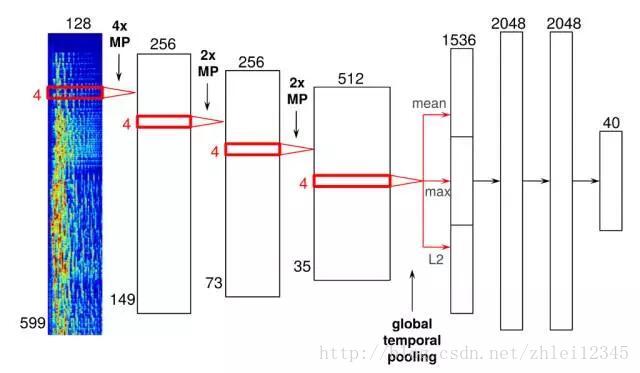
图片来源:Sander Dieleman
这个特定的神经网络有四个卷积层,即左边的四个宽条,和三个全连接层,即右边的三个窄条。输入是音频帧的时间-频率表示,然后将它们进行级联以形成频谱图。
音频帧通过这些卷积层,在最后一个卷积层之后,您可以看到一个“全局时序池化”层,它对整个时间轴进行池化,可以有效地计算歌曲整个时间内学习到的特征的统计。
在处理之后,神经网络会输出对歌曲的分析结果,包括像估计的拍子记号,调,模式,速度和响度等特征。以下是Daft Punk乐队的作品“Around the World”30秒摘录的数据。
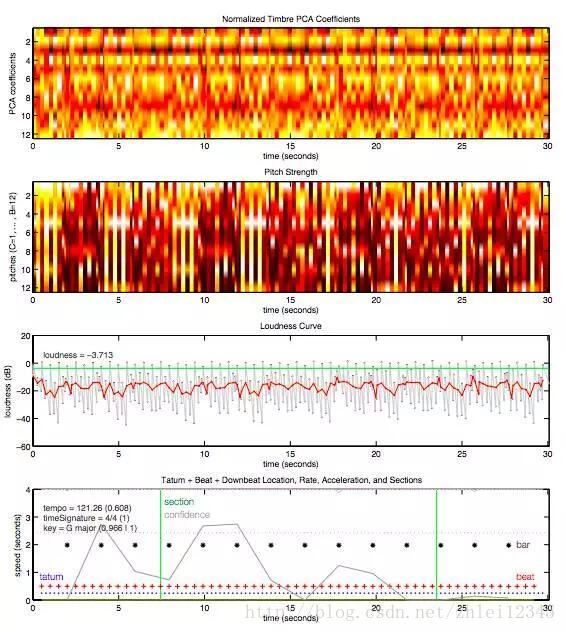
图片来源:Tristan Jehan和David DesRoches(The Echo Nest)
最终,对这首歌曲的主要特征的分析使得Spotify能够了解歌曲之间的基本相似之处,从而使得用户可以基于自己的播放历史欣赏相似的歌曲。
下面这张图涵盖了为推荐管道提供的三种主要类型的推荐模型的基础知识,并最终为“每周发现”播放列表提供建议!
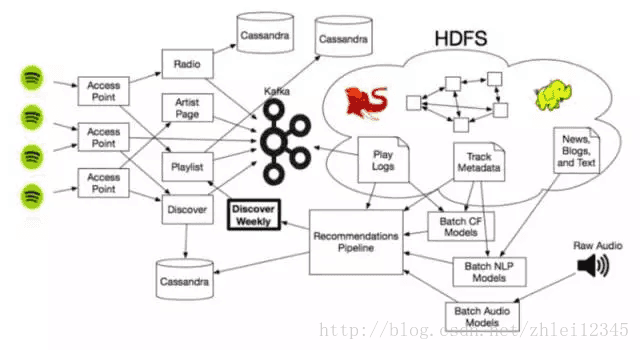
当然,这些推荐模型最终都要连接到Spotify的更大的生态系统中,其中包括大量的数据存储,使用大量的Hadoop集群来扩展建议,并使这些算法引擎对巨型矩阵,无尽的互联网音乐文章和大量的音频文件进行计算。
我希望这篇文章提供的信息量可以足够丰富,并且我的介绍可以激起你的好奇心。现在,我要去看自己的“每周发现”啦~,找到我最喜爱的音乐,了解并体会这些场景下用到的所有和机器学习有关的知识。
另外,推荐我的GitHub,包括相关代码和我的一些其他文章和项目
https://github.com/sophiaciocca
参考资料:
从想法到执行:Spotify的每周发现(Chris Johnson,ex-Spotify)
http://s.ai100.com.cn/8w
Spotify的协同过滤(Erik Bernhardsson,ex-Spotify)
http://s.ai100.com.cn/8x
通过深度学习推荐Spotify音乐(Sander Dieleman)
http://s.ai100.com.cn/8y
音乐推荐何时起效 – 何时失效(“回声巢”联合创始人布莱恩·惠特曼(Brian Whitman))
http://s.ai100.com.cn/8z
Spotify每周发现如何实现?数据科学(镀锌)
http://s.ai100.com.cn/90
Spotify每周发现播放列表如何创造奇迹(Quartz)
http://s.ai100.com.cn/91
Echo Nest’s分析文档
http://s.ai100.com.cn/92
作者:Sophia Ciocca,软件工程师,作家。
个人主页 http://sophiaciocca.com
原文地址:https://hackernoon.com/spotifys-discover-weekly-how-machine-learning-finds-your-new-music-19a41ab76efe
文章来源: AI科技大本营(微信号:rgznai100)














 3112
3112











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









