







我们都知道collect语句,主要用于
报表
数据的合并计算的,简单理解是:如果非数据字段值相等,那么数值字段值相加,其实这种描述不准确。
COLLECT 简单的用法:
其中 t_data和t_test结构相同,那么有以下疑问:
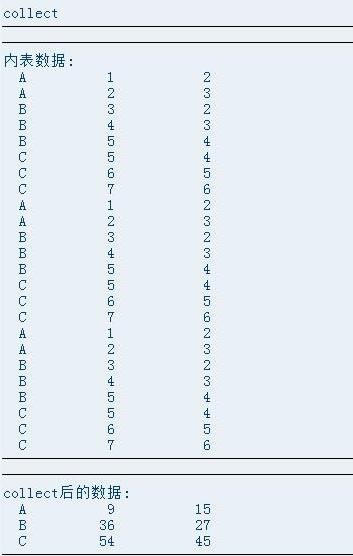
COLLECT 简单的用法:
其中 t_data和t_test结构相同,那么有以下疑问:
- COLLECT实际运用中loop的内表(t_data)需要排序么?
- loop语句中能不能用if或者delete语句,筛选部分数据,然后collect计算呢
1、问题一:
测试结果:
测试结果:
结论:COLLECT实际运用中loop的内表不需要排序,直接loop累加计算。
2、问题二:
以collect代码稍加改变:
测试结果:
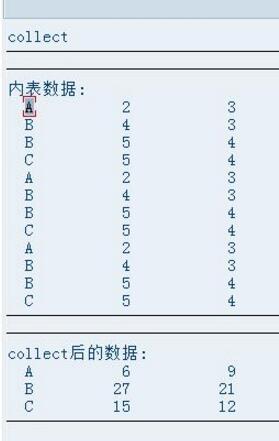
结论:COllECT语句支持这种在loop语句中筛选数据再计算。
由此可见,COLLECT语句还是很强大的,项目中经常会有这种筛选数据在计算,不需要再额外复制内表计算了
你在实际项目中可能使用collect是遇到下面问题:
只有在 COLLECT 命令的所有非关键字段均为数字(类型 I、P 或F)时才可在表中使用该命令。numeric (type I, P, or F)
使用collect就要求所有的非key fields均是I,P或者F数据类型,另外要注意的是对于standard table 而言,如果不指定key fields那么它的key fields就那些非I, P,F数据类型的fields,sorted table 和 hash table均必须指定key fields。
注意:货币类型CURR实际类型是P,所以也可以使用collect累加
2、问题二:
以collect代码稍加改变:
测试结果:
结论:COllECT语句支持这种在loop语句中筛选数据再计算。
由此可见,COLLECT语句还是很强大的,项目中经常会有这种筛选数据在计算,不需要再额外复制内表计算了
你在实际项目中可能使用collect是遇到下面问题:
只有在 COLLECT 命令的所有非关键字段均为数字(类型 I、P 或F)时才可在表中使用该命令。numeric (type I, P, or F)
使用collect就要求所有的非key fields均是I,P或者F数据类型,另外要注意的是对于standard table 而言,如果不指定key fields那么它的key fields就那些非I, P,F数据类型的fields,sorted table 和 hash table均必须指定key fields。
注意:货币类型CURR实际类型是P,所以也可以使用collect累加















 5919
5919











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











