







图论小结(一)
从一开始搞ACM到现在也有几个年头了,而搞图论的时间可是从一开始搞ACM开始。所以,总是对图论有着一种独有的感情。图论的内容说难不难,但是确实在算法中日常生活中可以经常遇到,且一个很有趣的算法。这也是我当初选择图论的原因,但是图论的代码量一般都比较的大,当初就是看到别人啪啪的一下只就敲出了几百行的图论代码,而自己当时是佩服的不得了啊。可是进入图论后,才发现,一照进图论十年不想敲代码啊。。。。
废话说太多了,其实图论内容很多。今天,最要总结一下最短路和生成树还有拓扑问题。还有一下更高深的网络流啊啥的一堆等下次再说。
一、最小生成树
解决最小生成树的问题,主要有两个算法。
1、Kruscal算法
2、Prime算法
Kruscal算法百度百科的解释及步骤:
求加权连通图的最小生成树的算法。kruskal算法总共选择n- 1条边,所使用的贪婪准则是:从剩下的边中选择一条不会产生环路的具有最小耗费的边加入已选择的边的集合中。注意到所选取的边若产生环路则不可能形成一棵生成树。kruskal算法分e 步,其中e 是网络中边的数目。按耗费递增的顺序来考虑这e 条边,每次考虑一条边。当考虑某条边时,若将其加入到已选边的集合中会出现环路,则将其抛弃,否则,将它选入。
空间复杂度为O(N*N)
时间复杂度为O(N*logN)(根据排序的算法时间决定)
Prim算法百度百科的步骤:
在推荐一个生成树讲的话的博客以供大家参考学习:博客链接
int Prim()
{
int dis[N],ans = 0; //生成树当前的最小花费,最终的最小花费
for(int i = 1;i <= n;++i){ //初始化
dis[i] = graph[1][i];
}
for(int i = 2;i <= n;++i){ //N个顶点要连通只须n-1条边
int x = 1,m = INF;
for(int j = 2;j <= n;++j){ //根据贪心,找出当前最短的一条边
if(dis[j] != -1&&dis[j] < m)
m = dis[x = j];
}
ans += m;
dis[x] = -1; //改点已经使用过,不可能在出现更小的情况
for(int j = 2;j <= n;++j){
/*
这个if就是prim算法和Dijkstra算法的本质不同之处
等提到Dijkstra算法时候,会着重提出。进行比较区分
*/
if((dis[j]!=-1)&&(dis[j] > graph[x][j])) //更新点(当前j点的最短距离,跟从x到j那个更小)
dis[j] = graph[x][j];
}
}
return ans;
}
二、最短路算法
最短路算法最要使用的有三个Dijkstra算法和Bellman-Ford以及Floyd算法。而这三个算法有的都有自己的优化程序,下面会一一讲述。
Dijkstra算法:
这个算法是通过为每个顶点 v 保留目前为止所找到的从s到v的最短路径来工作的。初始时,原点 s 的路径长度值被赋为 0 (d[s] = 0),若存在能直接到达的边(s,m),则把d[m]设为w(s,m),同时把所有其他(s不能直接到达的)顶点的路径长度设为无穷大,即表示我们不知道任何通向这些顶点的路径(对于 V 中所有顶点 v 除 s 和上述 m 外 d[v] = ∞)。当算法退出时,d[v] 中存储的便是从 s 到 v 的最短路径,或者如果路径不存在的话是无穷大。 Dijkstra 算法的基础操作是边的拓展:如果存在一条从 u 到 v 的边,那么从 s 到 v 的最短路径可以通过将边(u, v)添加到尾部来拓展一条从 s 到 v 的路径。这条路径的长度是 d[u] + w(u, v)。如果这个值比目前已知的 d[v] 的值要小,我们可以用新值来替代当前 d[v] 中的值。拓展边的操作一直运行到所有的 d[v] 都代表从 s 到 v 最短路径的花费。这个算法经过组织因而当 d[u] 达到它最终的值的时候每条边(u, v)都只被拓展一次。
时间复杂度我O(|V^2|)
但是可以优化到O(n*logn)优化程序可以看我以前写的文章:文章链接
function Dijkstra(G, w, s)
for each vertex v in V[G] // 初始化
d[v] := infinity // 將各點的已知最短距離先設成無窮大
previous[v] := undefined // 各点的已知最短路径上的前趋都未知
d[s] := 0 // 因为出发点到出发点间不需移动任何距离,所以可以直接将s到s的最小距离设为0
S := empty set
Q := set of all vertices
while Q is not an empty set // Dijkstra演算法主體
u := Extract_Min(Q)
S.append(u)
for each edge outgoing from u as (u,v)
if d[v] > d[u] + w(u,v) // 拓展边(u,v)。w(u,v)为从u到v的路径长度。
d[v] := d[u] + w(u,v) // 更新路径长度到更小的那个和值。
previous[v] := u // 紀錄前趨頂點
现在就说说刚才在Prim算法中提到了但是没有解释的那行程序吧。
Prim更新:if(d[y] != -1&&d[y]>graph[x][y]) d[y] = graph[x][y]; //d[i]==-1表示改点已经更新过
Dijkstra更新:if(d[y]>d[x]+w[x][y]) d[y] = d[x]+w[x][y];
为什么会有这个区别呢?其实,只要你对这两个算法的本质理解了,你就自然会知道了。上面我们已经提到了Prim是求解最小生成树的,其终极目标是使得一个图连通且最终花费最小。而Dijkstra是求单源最短路的。即,给你一个起始点,叫你求出从这个起始点到各点或者给定目标点的最短距离。所以,我们在为Prim更新的时候考虑的是最终总的花费最小,而考虑Dijkstra是考虑起点到当前更新点的花费最小。
所以,最终我得到的d[]也是有区别的。prim的d[]是表示当前连通改点最小的花费d[],而Dijkstra表示的是从起点到当前更新点的最小花费是d[].
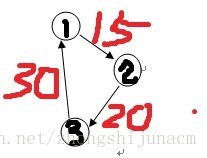
图虽然搓了点,但是却可以很好的解释他们两个的区别。其实,是想画无向图的,就凑合着看吧。
如果,是prim的话是选择(1,2)+(2,3);而Dijkstra的话则是更新(1,3)(假设起点为1).现在应该知道他他们的区别了吧。
Bellman-Ford算法维基百科解释:
它的原理是对图进行V-1次松弛操作,得到所有可能的最短路径。其优于迪科斯彻算法的方面是边的权值可以为负数、实现简单,缺点是时间复杂度过高,高达O(VE)。但算法可以进行若干种优化,提高了效率。
贝尔曼-福特算法与迪科斯彻算法类似,都以松弛操作为基础,即估计的最短路径值渐渐地被更加准确的值替代,直至得到最优解。在两个算法中,计算时每个边之间的估计距离值都比真实值大,并且被新找到路径的最小长度替代。 然而,迪科斯彻算法以贪心法选取未被处理的具有最小权值得节点,然后对其的出边进行松弛操作;而贝尔曼-福特算法简单地对所有边进行松弛操作,共|E | − 1次,其中 |E |是图的边的数量。在重复地计算中,已计算得到正确的距离的边的数量不断增加,直到所有边都计算得到了正确的路径。这样的策略使得贝尔曼-福特算法比迪科斯彻算法适用于更多种类的输入。
贝尔曼-福特算法的最多运行O(|V|·|E|)次,|V|和|E|分别是节点和边的数量)。
procedure BellmanFord(list vertices, list edges, vertex source)
// 该实现读入边和节点的列表,并向两个数组(distance和predecessor)中写入最短路径信息
// 步骤1:初始化图
for each vertex v in vertices:
if v is source then distance[v] := 0
else distance[v] := infinity
predecessor[v] := null
// 步骤2:重复对每一条边进行松弛操作
for i from 1 to size(vertices)-1:
for each edge (u, v) with weight w in edges:
if distance[u] + w < distance[v]:
distance[v] := distance[u] + w
predecessor[v] := u
// 步骤3:检查负权环
for each edge (u, v) with weight w in edges:
if distance[u] + w < distance[v]:
error "图包含了负权环"
改算法同样也有一个很常用的优化算法SPFA算法,就是将检查的时候常常用FIFO来代替了循环检查。
/*
Head[]为邻接表的表头
Key[] 为邻接表的顶点
Next[]为邻接表的下个节点
w[] 为该点的权重
*/
void SPFA(int s) //s 为起点
{
queue<int> q;
int c[MAXV]; //判断是否有负环
bool inq[MAXV]; //在队列中的标记
for(int i = 0;i < n;++i)
d[i] = (i==s?0:INF);
memset(inq,0,sizeof(inq));
q.push(s);
while(!q.empty())
{
int x = q.front();
q.pop();
inq[x] = 0; //清除在队列中的标记
for(int e = Head[x];e != -1;e = Next[e])if(d[Key[e]] > d[x]+w[e]){
d[Key[e]] = d[x] + w[e];
if(!inq[Key[e]]){ //如果已经在队列中,就不要重复加了
inq[Key[e]] = 1;
c[Key[e]]++;
if(c[Key[e]] > MaxVerter)
RETURN "有负环"
q.push(Key[e]);
}
}
}
}
判断有无负环:如果某个点进入队列的次数超过N次则存在负环(SPFA无法处理带负环的图)














 1342
1342











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









