







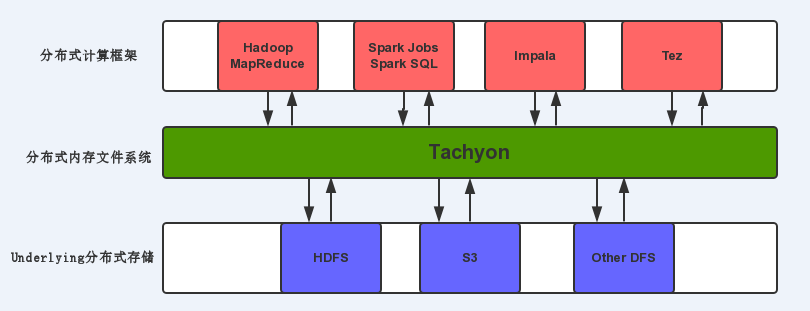
Tachyon架构
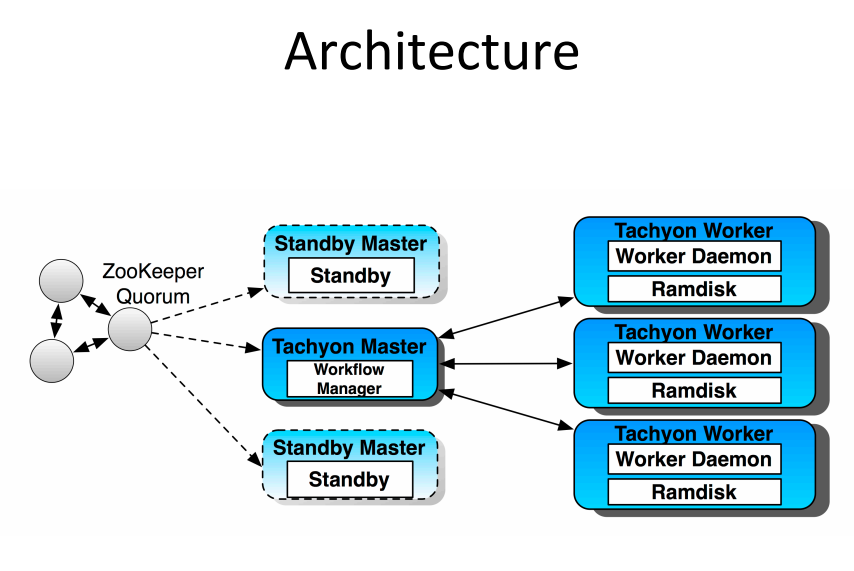
三、Fault Tolerant
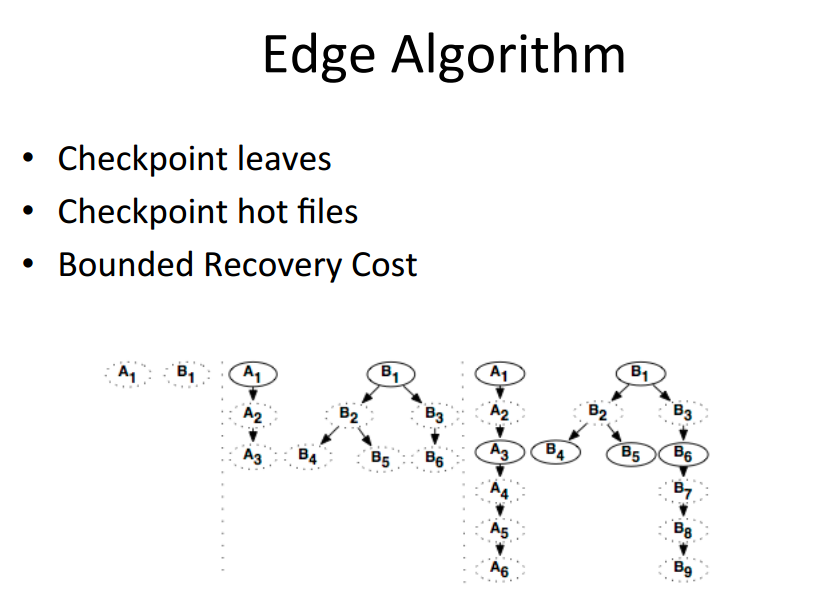
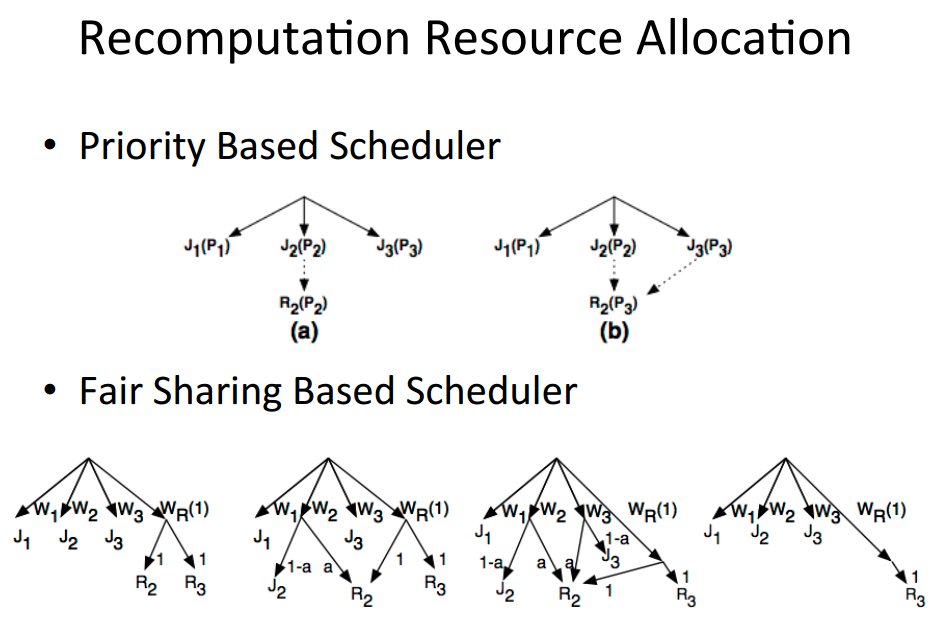
四、总结
Tachyon也有类似RDD的血统概念,input文件和output文件都是会有血统关系,这样来达到容错。并且Tachyon也利用血统关系,异步的做checkpoint,文件丢失情况下,也能利用两种资源分配策略来优先计算丢失掉的资源。
该项目的地址:http://tachyon-project.org/index.html
博文转自:http://www.open-open.com/lib/view/open1409754088791.html
Tachyon架构分析和现存问题讨论
Tachyon是AmpLab的Li Haoyuan所开发的一个基于内存的分布式文件系统,出发点是作为AMPLAB的BDAS的一个组成部分
总体设计思想
从Tachyon的设计目标来看,是要提供一个基于内存的分布式的文件共享框架,需要具备容错的能力,还要体现内存的性能优势
Tachyon以常见的Master/worker的方式组织集群,由Master节点负责管理维护文件系统MetaData,文件数据维护在Worker节点的内存中。
在容错性方面,主要的技术要点包括:
- 底层支持Plugable的文件系统如HDFS用于用户指定文件的持久化
- 使用Journal机制持久化文件系统的Metadata
- 使用Zookeeper构建Master的HA
- 没有使用replica复制内存数据,而是采用和Spark RDD类似的Lineage的思想用于灾难恢复(这一点后面再讨论)
此外为了兼容Hadoop应用,提供了HDFS兼容的API接口
具体实现分析
初始化流程
Tachyon文件系统的初始化,其实就是创建和清空Master/worker所需的工作目录
对Master节点来说这些目录包括底层持久化文件系统上的Data/worker/Journal目录,实际上这里的Worker目录是由Worker节点使用的(用于存放一些零时的持久化文件,丢失Meta信息的数据块等),但是放在Master节点来创建,本质上是为了简化创建逻辑(因为放在HDFS上,只创建一次)
对worker节点来说所需的目录就是本地Ramdisk目录
此外,在master的Journal文件夹中,会创建一个特定前缀的空文件用于标志文件系统格式化完毕
Tachyon Master的启动过程
Tachyon Master的启动过程,首先当然是要读取Master相关配置参数,目前都是通过-D参数传给Java的,理想的是通过配置文件来做。目前这些参数,一部分是在Env文件里设置变量,再通过-D参数设置,也有的直接写死在-D参数中的,也有启动脚本中默认未配置,在MasterConf代码里使用了默认值的
通过读取特定的format文件判断文件系统是否格式化
接下来就是在内存中重建文件系统信息
Tachyon的文件系统信息依靠Journal日志保存,Journal包括两部分,一是meta信息在某个时刻的快照Image,二是增量Log。Tachyon Master启动时首先从快照Image文件中读取文件系统meta信息,包括各种数据节点(文件/目录/Raw表/Checkpoint/依赖关系等)信息,而后再从继续EditLog(可能多个)中读取增量操作记录,EditLog的内容基本对应于Tachyon文件系统Client的一些相关操作,包括文件的添加,删除,重命名,数据块的添加等等
需要注意的是,这里的Log记录不包括实际的文件内容数据,只是meta信息,所以如果Cache中的文件内容丢失,如果没有持久化,也没有绑定相关lineage信息,那么对应的文件的具体内容也就丢失了
文件系统信息恢复完毕以后,在Tachyon Master正式启动服务之前,Tachyon Master会先把当前的Meta Data写出为新的快照Image
在启用zookeepeer的情况下,standby的Master会定期将Editlog合并并创建Standby的Image,如果没有Standby的Master则只有在启动过程中,才通过上述步骤合并到新的Image中。这里多个Master并发操作Image的editlog,没有Lock或者互斥的机制,不知道会不会存在竞争冲突,数据stale或丢失的问题
文件的存储
Tachyon存放在RamDisk上的文件以Block(默认为1G)为单位划分,Master为每个Block分配一个BlockID,Worker直接以BlockID作为实际的文件名在Ramdisk上存储对应Block的数据
数据的读写
Tachyon的文件读写,尽可能的通过Java NIO API将文件直接映射到内存中,做为数据流进行读写操作,目的在于避免在Java Heap中使用大量的内存,由此减小GC的开销,提升响应速度
读写过程中,所有涉及到Meta相关信息的,都需要通过调用Tachyon Master经由Thrift暴露的ServerAPI来执行
Tachyon的文件读操作支持本地和远程两种模式,从Client API的角度来说对用户是透明的。读文件的实现,其流程基本就是先从Master处获取对应文件Offset位置对应的Block的ID
而后连接本地Worker取得相应ID对应的文件名,如果文件存在,Client端代码会通知Worker锁定对应的Block,而后Client端代码直接映射相关文件为RandomAccessFile直接进行读操作,并不经由Worker代理读取实际的数据
如果本地没有Worker,或者文件在本地worker上不存在,Client代码再进一步通过Master的API获取相关Block所对应的Worker,而后通过Worker暴露的DataServer接口读取对应Block的内容,在DataServer内部,同样延续锁定对应Block,映射文件的流程读取并将数据返回给Client
另外,基于读数据的时候使用的TachyonFile的API接口,如果使用的是FileStream的接口,当远程Worker也没有对应文件Block时,RemoteBlockInStream还会尝试从底层持久化文件系统层(如果存在对应的文件的话)去读取数据,而ReadByteBuffer接口则没有对应的流程(个人感觉,应该做到两种方式的行为匹配才对)。
Tachyon目前只支持本地写操作,写操作按写入位置可以分为
Cache:写到Tachyon内存文件系统中
Through:写到底层持久化文件系统中
具体的类型是以上几种情况的合法的组合,如单cache,cache +through等
还有一个Async模式:异步写到底层持久化文件系统中,这个大概是为了优化那些数据需要持久化,但是又对性能Latency等有要求的场合
读写操作现存问题和并发操作相关
前面提到读取数据时Client端会通知WorkerLock对应的Block。需要注意的是这里的Lock实际上并没有互斥的意思,只是一个标志表示当前还有用户在使用相关文件和数据,这样,在Worker需要分配内存淘汰旧的数据的时候,当前正在使用的文件将不会被删除。
而在写操作过程中,目前的实现看来对并发处理相关的内容基本没有考虑
例如Read操作已经Lock的文件block,依然可以被主动Delete,不考虑lock的状态,当然这一点可能和多数Linux类的Filesystem的设计一致,(但是Windows上显然可能提示无法删除)这个还要再研究一下在大数据分布是环境下其它的设计实现是怎样的
而写操作本身的再入也没有很处理好,不能支持并发是一个问题,单线程重写文件也会造成前面的数据块的丢失或者数据块的混合,当然,这也是因为目前还没有考虑到支持这些情况。
Write目前不支持Append操作,这个和当前的设计也有很大的关系,block尺寸按文件计算,尺寸固定,所以要Append就需要考虑必须在同一节点上写数据,要不然就要支持远程写数据到当前Block所在的节点上,要不然就要支持动态Block大小。然后如果支持异地写,还要考虑并发Append的问题,需要Lock文件,阻止并发写等,这些都是目前Tachyon所无法支持的
Raw Table表单
Tachyon所谓的Raw Table的支持,目前的实现,本质上只是一个分级(column)的文件目录,每个Colum下的一个Partition对应一个Tachyon文件,从用户的角度上来看,相对于直接构建这样的目录结构,仅仅是省去了为每个Partition命名,以及方面统一操作几个文件,实际上并没有提供其它额外的辅助功能,如检索等等
HDFS文件接口
Tachyon提供了兼容HDFS API的文件操作接口,基本上就是提供了一个TFS拓展Hadoop的FileSystem接口,主要就是用Tachyon Client提供的接口实现HDFS对文件相关信息和Metadata的操作
在具体的数据读写上,则是在建立好数据流的基础上,通过Tachyon的FileInStream和FileOutStream来执行
比较奇怪的是FileOutStream是直接传递给了Hadoop FSDataOutputStream,而FileInStream则进一步封装成了HdfsFileInputStream再传递给Hadoop FSDataInputStream使用,理论上难道不是应该只要实现Java InputStream的类就可以了么,其它API接口应该是Hadoop FSDataInputStream实现的
White list/ pin list功能?
White list和 pin list以路径前缀的方式存储一些URLpath用作Filter,用作设置默认需要加载到内存中的文件
White List的设计意图是在读取数据时自动尝试在内存中Cache对应文件,但是具体的实现貌似仅仅设置了标志位,但是没有完成相关功能?实际使用Tachyon API时需要指定Read Cache Type来指定需要Cache对应文件
PinList的目的是保证对应的文件常驻在内存中,目前的实现:在写数据时,强制要求要有足够的内存空间否则出错。在Worker端,当内存空间不足,需要淘汰数据,释放空间时,也会忽略PinList列表中的文件。但是在读数据的路径上,如果由于某种原因,对应文件不在内存上,需要从底层持久化文件系统中获取的话,PinList并不能保证自动Cache这些文件在内存中,依然依赖于Read文件时使用的read Cache type
总结
总体而言,目前Tachyon的功能基本可以看作就是:对外提供了一个以顺序文件流的方式,写本地内存,读本地和远程内存的接口,持久化特定文件,同时兼容HDFS API。其处理内存丢失和替换数据的方式使其更像一个Cache系统而非文件系统。其它的各种额外辅助功能都还不完善。就其实现的部分,各级component包括IPCProtocol,配置,Image,Data API设计,各种异常处理乃至并发处理架构等方面,个人感觉实现方式略显简单粗暴,可以理解为以实现快速原型为思想设计的,存在一定的改进的空间,或者需要考虑优化设计方案。
而前面提到的做为容错设计上,最重要的Lineage的设定,(这也是作者的论文的核心内容所在,毕竟其它部分如果从学术的角度上来说并没有太大创新,而只是具体的工程实现)目前看来,似乎并没有很理想的实现,或者说在实际应用场合中有比较多的局限性?大概需要一个说服力比较强的Case来证明其实用性和适用性(当然,或者是我没有看到更多的这方面的代码,据说有更多的相关实现还没有public?)
博文转自:http://blog.csdn.net/colorant/article/details/22385763
Spark & Shark & Tachyon 简介
Spark是一个高效的分布式计算系统,相比Hadoop,它在性能上比Hadoop要高100倍。Spark提供比Hadoop更上层的API,同样的算法在Spark中实现往往只有Hadoop的1/10或者1/100的长度。
Shark类似“SQL on Spark”,是一个在Spark上数据仓库的实现,在兼容Hive的情况下,性能最高可以达到Hive的一百倍。
Tachyon是一个高效的分布式存储系统。目前发布的为整体项目的部分功能(缓存部分),此部分功能在一次写、多次读的环境下为系统的性能带来最大的提升。
博文转自:http://blog.csdn.net/lijiajia81/article/details/17080715
Tachyon:吞吐量超过HDFS 300多倍 来自伯克利的分布式文件系统
Hadoop里的HDFS已经成为大数据的核心基础设施,觉得它还不够快?近日,美国加州大学伯克利分校的AMPLab开发的分布式文件系统Tachyon受到了广泛关注。
Tachyon(英文超光子的意思,指假想的比光还快的粒子)的特点是充分使用内存和文件对象之间的世代(lineage)信息,因此速度很快,项目自己号称最高比HDFS吞吐量高300倍。

实际上,不仅仅是要用Tachyon试图取代HDFS,AMPLab已经完全重建了一套类似Hadoop的大数据平台,“没有最快,只有更快”。AMPLab在大数据领域最知名的产品是Spark,它是一个内存中并行处理的框架,Spark的创造者声称:使用Shark运行并行处理Job速度要比MapReduce快100倍。又因为Spark是在内存运行,所以Shark可与Druid或者SAP's HANA系统一较高下。Spark也为ClearStory下一代分析和可视化服务提供处理引擎。如果你喜欢用Hive作为Hadoop的数据仓库,那么你一定会喜欢Shark,因为它代表了“Hive on Spark”。
AMPLab的最新目标就是Hadoop分布式文件系统(HDFS),不过HDFS在可用性和速度方面一直受人诟病,所以AMPLab创建了Tachyon( 在High Scalability上非常夺目,引起了Derrick Harris的注意),“Tachyon是一个高容错的分布式文件系统,允许文件以内存的速度在集群框架中进行可靠的共享,类似Spark和 MapReduce。通过利用lineage信息,积极地使用内存,Tachyon的吞吐量要比HDFS高300多倍。Tachyon都是在内存中处理缓存文件,并且让不同的 Jobs/Queries以及框架都能内存的速度来访问缓存文件”。
当然,AMPLab并不是第一个对HDFS提出质疑的组织,同时也有很多商业版本可供选择,像Quantcast就自己开发了开源文件系统,声称其在运行大规模文件系统时速度更快、更高效。
诚然,AMPLab所做的工作就是打破现有商业软件的瓶颈限制。如果碰巧破坏了现状,那么就顺其自然吧!不过,对于用户来说,AMPLab只是为那些寻找合适工具的人员提供了一种新的选择,AMPLab的合作伙伴和赞助商包括谷歌,Facebook,微软和亚马逊网络服务,它们当然非常乐意看到这些新技术,如果很有必要的话。

AMPLab的其他项目包括PIQL,类似于一种基于键/值存储的SQL查询语言;MLBase,基于分布式系统的机器学习系统;Akaros,一个多核和大型SMP系统的操作系统;Sparrow,一个低延迟计算集群调度系统。(文/王鹏,审校/仲浩,文章2014年4月19日由刘江更新)
原文链接:GigaOM,HighScalability
AMPLab开发的类Hadoop项目Tachyon介绍
在2013年4月,AMPLab共享了其Tachyon 0.2.0 Alpha版本的Tachyon,其宣称性能为HDFS的300倍,受到了极大的关注。截至目前(2013.7.22),其最新版本为0.3.0-SNAPSHOT,项目地址为:
https://github.com/amplab/tachyon/wiki
下面是官方对Tachyon的一个介绍:
Tachyon是一个高容错的分布式文件系统,允许文件以内存的速度在集群框架中进行可靠的共享,就像Spark和 MapReduce那样。通过利用信息继承,内存侵入,Tachyon获得了高性能。Tachyon工作集文件缓存在内存中,并且让不同的 Jobs/Queries以及框架都能内存的速度来访问缓存文件”。因此,Tachyon可以减少那些需要经常使用的数据集通过访问磁盘来获得的次数。
1. 特性:
- Java-like File API: Tachyon的原生API和java的文件系统非常相似,提供InputStream, OutputStream 接口, 和高效的 memory mapped I/O,用这些API能够获得最好的性能
- Compatibility: Tachyon 实现了Hadoop FileSystem 接口, 因此,Hadoop MapReduce和Spark可以不经过任何修改就能在Tachyon上运行。
- Native support for raw tables: Tachyon对列存储结构的数据提供了原生的支持,用户可以将某些访问量高的列选择性地放到内存中。
- Pluggable underlayer file system: Tachyon 提供memory data到底层文件系统的方法。目前支持HDFS和单点的本地文件系统。
- Web UI: 用户可以通过浏览器浏览文件系统,在debug模式下,管理员可以查看文件的位置等详细信息。
- Command line interaction: 用户可以使用 ./bin/tachyon tfs和 Tachyon交互,例如将文件在Tachyon和本地文件系统中拷贝。
2. 项目依赖
Maven
<dependency>
<groupId>org.tachyonproject</groupId>
<artifactId>tachyon</artifactId>
<version>0.2.1</version>
</dependency>Ant
<dependency org="org.tachyonproject" name="tachyon" rev="0.2.1">
<artifact name="tachyon" type="jar" />
</dependency>3. 教程
Running Tachyon Locally: Get Tachyon up and running on a single node for a quick spin in ~ 5 mins.
Running Tachyon on a Cluster: Get Tachyon up and running on your own cluster.
Running Spark on Tachyon: Get Spark running on Tachyon
Running Shark on Tachyon: Get Shark running on Tachyon
Running Hadoop MapReduce on Tachyon: Get Hadoop MapReduce running on Tachyon
Configuration-Settings: How to configure Tachyon.
Command-Line-Interface: Interact with Tachyon through command line.
Tachyon Developer Preview presentation at Spark User Meetup (May, 2013)
4. 总结
本文对Tachyon的来源和特性进行了介绍。
博文转自:http://ju.outofmemory.cn/entry/50616
该项目的另一个测试项目:
Tachyon-Perf
A general performance test framework for Tachyon.The master branch is in version 0.2.0-SNAPSHOT.
Prerequisites
As this project is a test framework for Tachyon, you need to get the Tachyon installed first. If you are not clear how to setup Tachyon, please refer to the guidelines here.
Currently the master branch of Tachyon-Perf supports testing tachyon-0.5.0 (the lastest released version). We also provide a special branch supports a version of Tachyon-0.6.0-Snapshot (Commit NO. 1f512044b939b9b0a2c58f64bca4516642daf8a8). Please see this page to find out how to use Tachyon-Perf against the Tachyon-0.6.0-Snapshot.
The following shows how to run tachyon-perf, and you can add a new benchmark to tachyon-perf if needed. See more in How to add a new benchmark
参考网址(开源代码可下载):https://github.com/PasaLab/tachyon-perf














 8447
8447











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









