







排序
排序是为了让查找更有效率。一组无序的数字,字符串等元素,要从中找出某个特殊的元素,是一件很繁琐的事情,我们不得不一个一个列举比较。而面对一组有序的元素,要从中找到某个特殊元素A,或者判断某元素B是否存在,则效率要高很多。
前辈们排序算法研究已久,有些用直觉就能分析出来,即所谓基础排序,有些无法用直觉看出,还需要一些分析研究,即所谓高级排序。以下表格大致罗列一下主流的排序算法的特点。
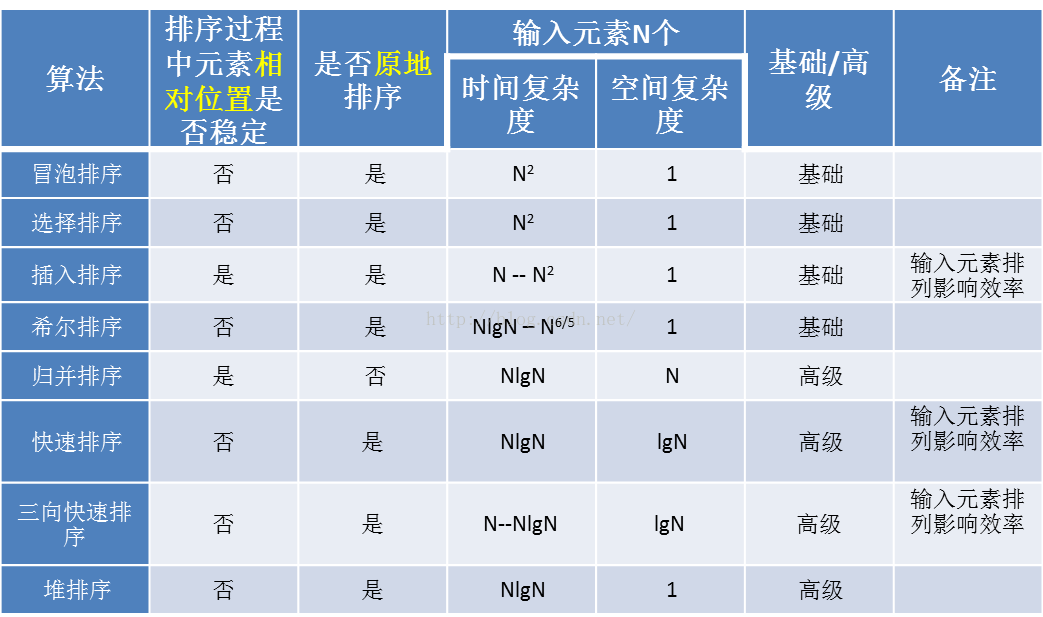
表格 1
排序过程中相对位置是否稳定是指,在输入序列中,已存在的相对有序(不一定是相邻位置,但是相对大小顺序是固定的,比如card、acb、cat之间存在abc, 但是car和cat还是相对有序的。)元素card、cat、control 等,根据首字母排序后,由于排序算法的影响,使得相对有序元素组变得无序,比如相对位置变成 cat、control、card,需要第二轮根据第二个字母排序时,对cat、control、card这个子序列进行重新排序,使其变回card、cat、control这种相对位置。这也就是排序算法带来的副作用。
原地排序是指不需要借助辅助缓存,存储输入序列的一个大副本。但是利用一个swap变量进行交换,或者递归使用的栈空间,是不算在辅助缓存大副本里的。
基础排序
冒泡排序
冒泡排序就是对大小为N的元素序列(对数组,链表对象序列的一种高层抽象描述。),进行N轮比较,在第m(0 < m <= N) 轮的比较和交换中,找到剩余未排序元素中最小的元素,将其放置到序列的第m个位置。
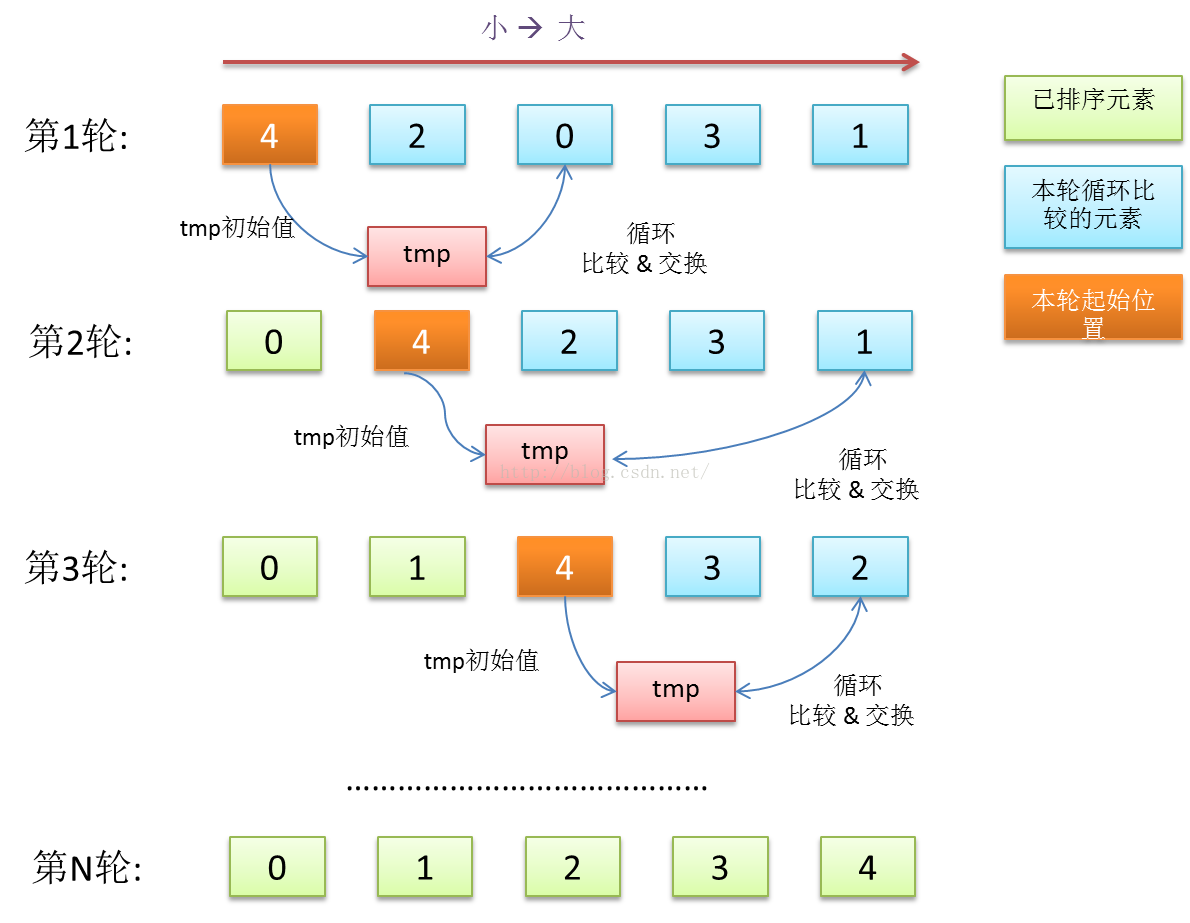
图 1 冒泡排序的flow
元素序列总共要N轮比较和交换,每轮的比较和交换的次数依次为N、N-1、N-2…… 2 、1, 即一个等差数列,那么总次数为等差数列之和 N2 / 2,时间复杂度近似于N2.
选择排序
选择排序本质原理和冒泡排序是一样的,只是冒泡排序太知名了,不得不单独拿出来讲。
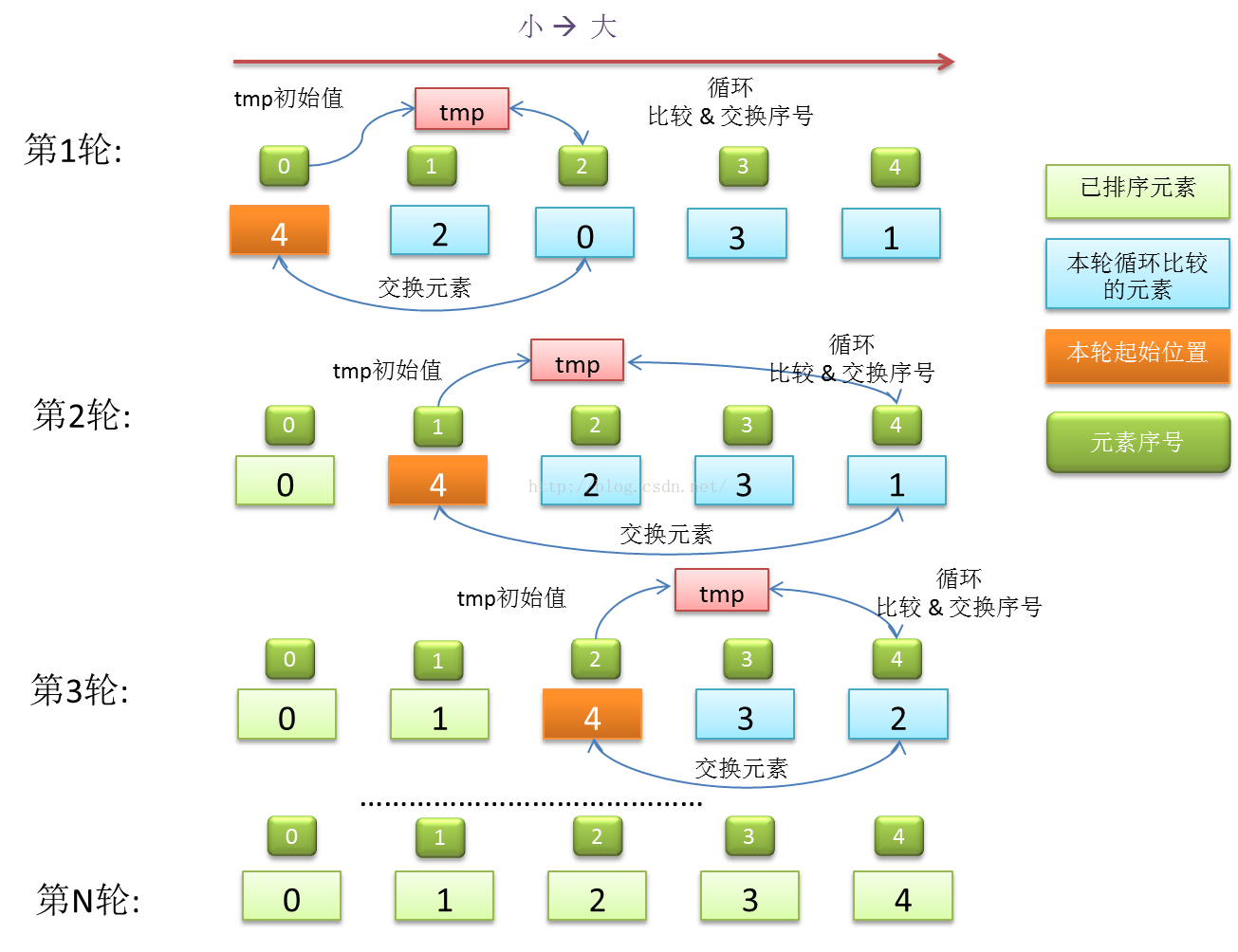
图 2 选择排序的flow
选择排序和冒泡排序细节上的差别在于,在N轮比较和交换过程中,每次比较之后,并不直接交换元素,而是保存待交换元素的序号k,直到该轮比较结束后,再根据保存的序号,交换第m轮比较的第m个位置的元素与第k个元素。这样可以减少数组的访问次数,在面对数组类型的可随机访问的序列时,能够起到优化作用,但是面对链表式结构的序列,由于无法随机访问,最后的交换操作,还是需要进行一轮遍历。
选择排序的时间复杂度和冒泡排序是一样的,处理效率和输入序列的分布无关。
插入排序
插入排序,顾名思义,就像玩牌的时候,将一手的牌,一张一张从小到大,按照顺序插入。
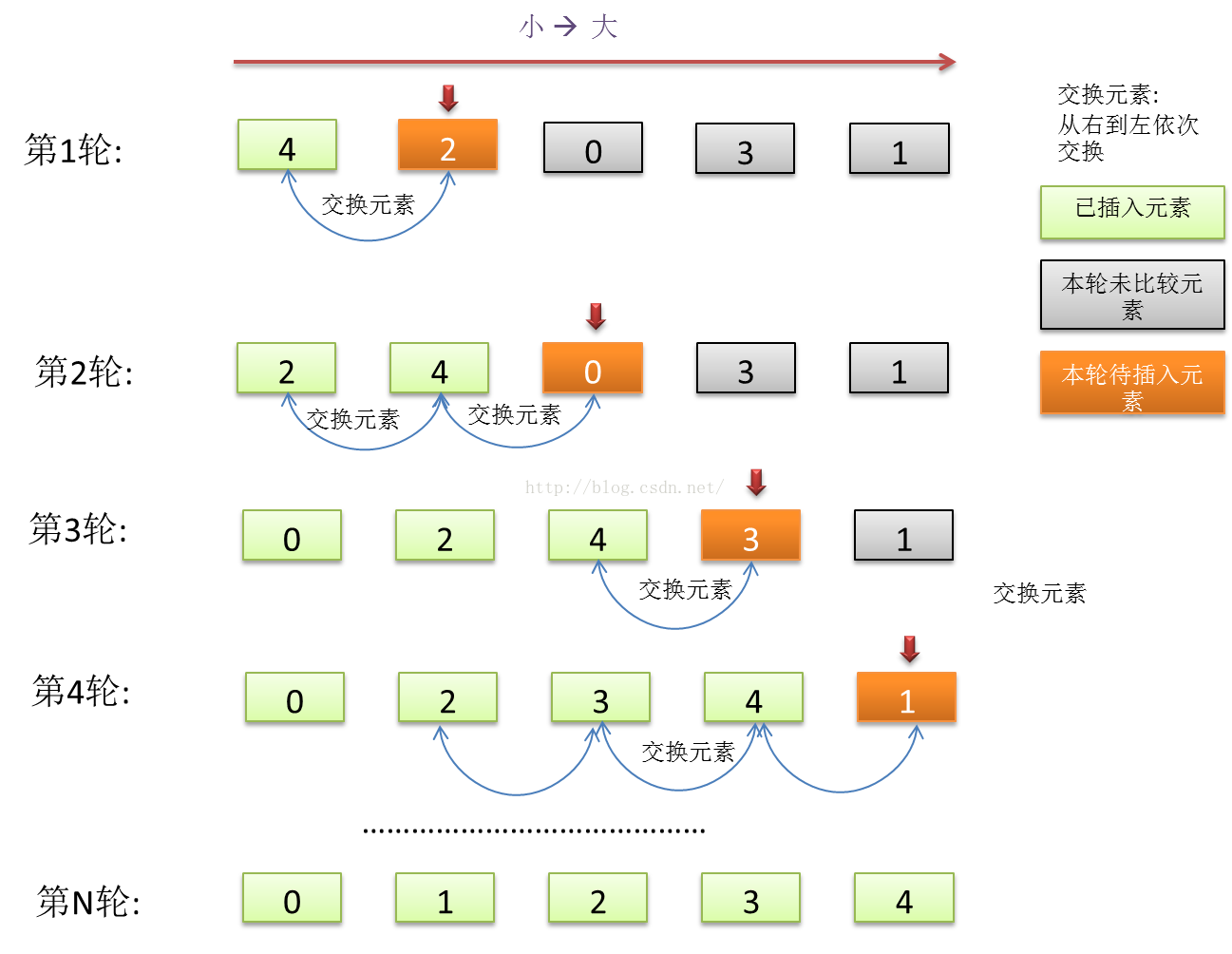
图 3 插入排序flow
插入排序在输入序列接近有序的情况下,相比选择排序有比较明显的优势,时间复杂度可从N2 提升到N。因而插入排序的时间复杂度,随着输入元素序列的结构特性(接近有序、随机)而变化,最差情况是N2, 最好情况是N.
希尔(Shell)排序
希尔排序是一种对插入排序的改进。大规模随机输入元素序列的插入排序很慢,尤其是数组类型结构,元素交换是相邻元素一个一个交换。希尔排序
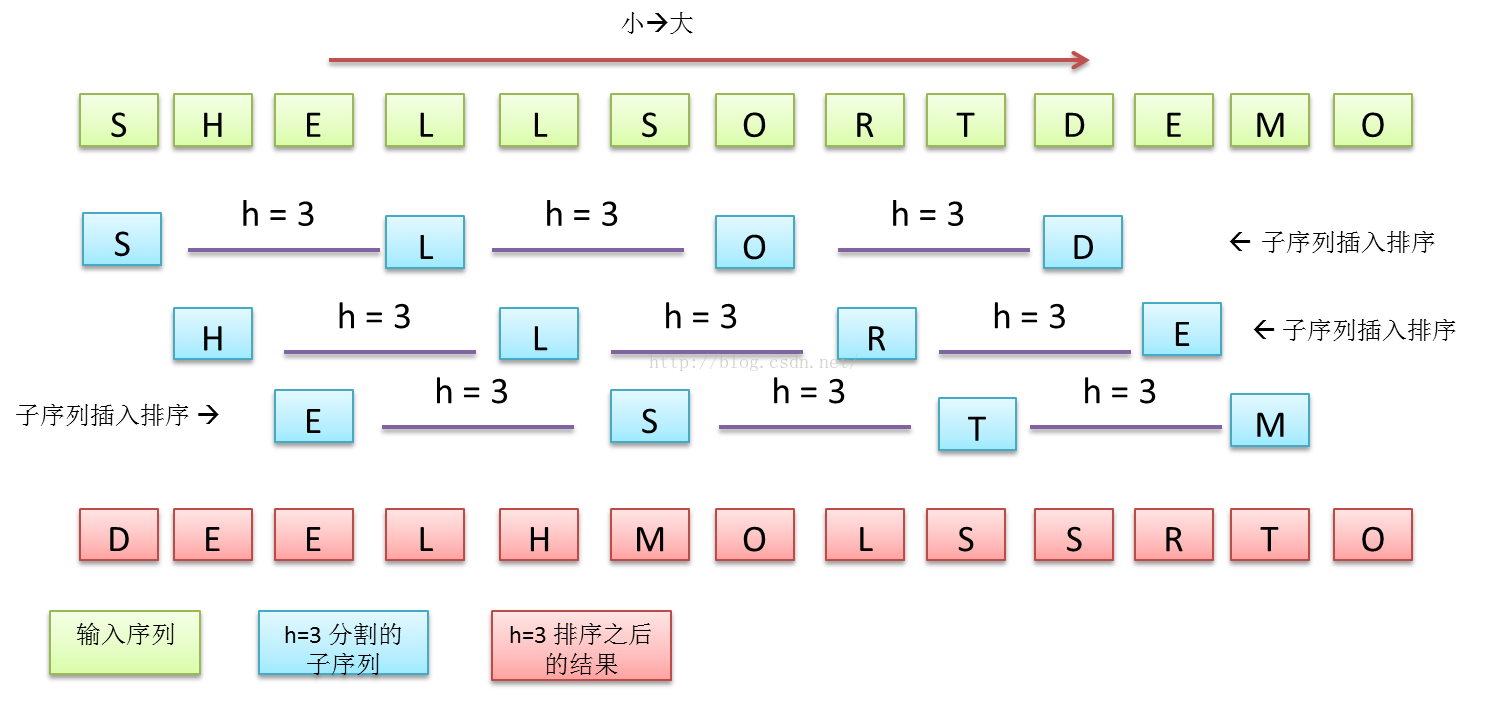
图 4 h=3 分割的希尔排序flow与临时结果
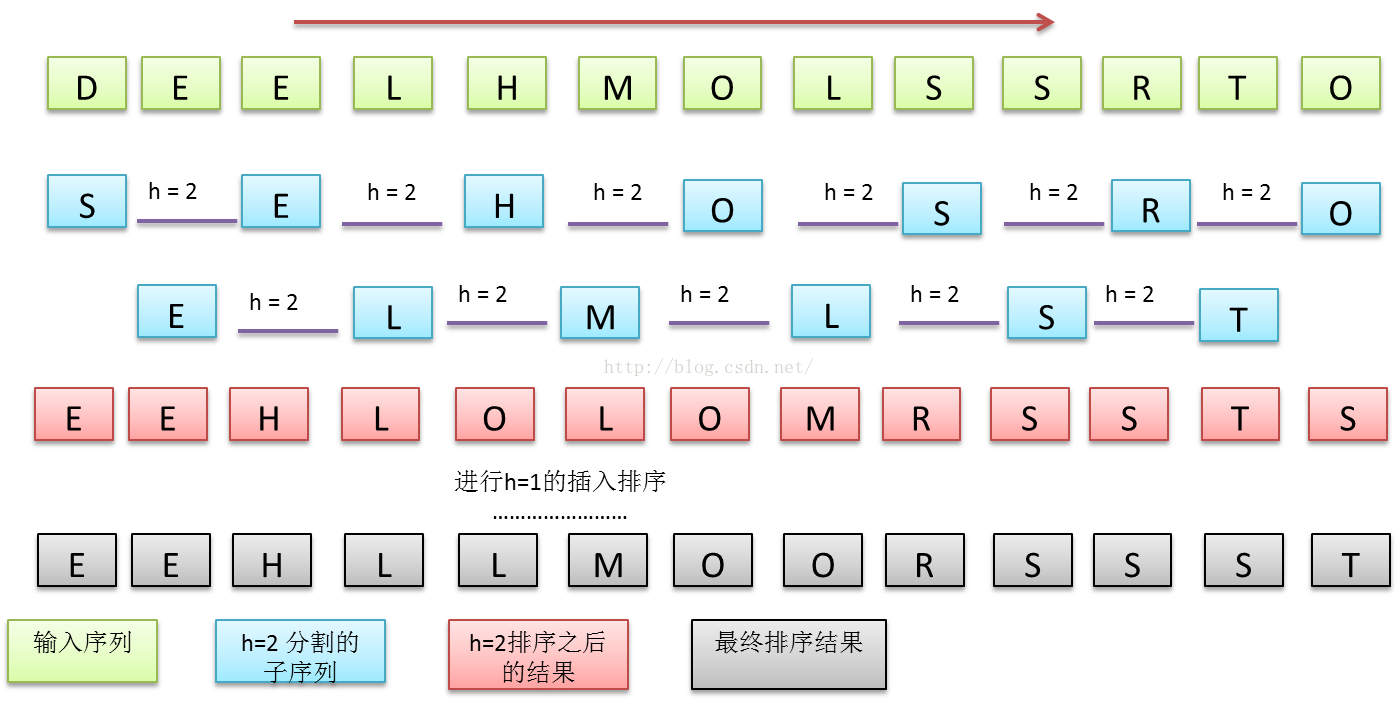
图 5 h=2 分割的希尔排序flow以及最终排序结果
希尔排序定义了h有序数组的概念,即一个数组中,间隔为h的元素之间是有序的。希尔排序先对序列中每个h间隔子序列单独排序,然后使h变小为h/x,再对数组中的h有序子序列进行排序,直到h变为1。间隔为1的子序列就是数组本身,因而排序结束。h分割的值与衰减速度x都可以由算法设计者根据实际情况调节。
希尔排序每轮比较与交换的不是相邻的元素,而是间隔为h的元素,越到后面,h间隔变得越小,数组有序度慢慢提高,因而越到后面排序越快。不过希尔排序的时间复杂度并没有一个绝对的计算公式,一般工程上经验是 NlgN – N6/5.
高级排序
所谓高级排序,大部分都使用了递归和分而治之的方法,因而用直觉是很难感受到每一个细节的。
归并排序
归并排序是利用分而治之的方法,通过递归,将元素序列不断地均分,最后变成2个元素的子序列,对这2个最小元素组成的子序列进行比较和交换之后,再与相邻的最小子序列进行比较合并,最终将已经有序的子序列,合并为一个大的有序序列。

图 6 归并排序flow
归并排序通过分而治之的方法,神奇地将时间复杂度减少到NlgN,但是却需要额外的缓存空间,去保存等待归并的子序列,因而增加了空间复杂度,需要一个大小为N的额外辅助 缓存。这是典型的空间换时间的方法。
归并排序一般有自顶向下和自底向上两种实现方法,自顶向下适合数组结构元素序列,自底向上适合链式结构元素序列。
快速排序
快速排序以NlgN的时间复杂度闻名于世界,也是各种语言基础库的sort函数广泛采用的排序方法。
快速排序的核心是思想是利用递归来切分元素序列,选择一个元素作为切分点,使得切分点左边的元素都小于该元素,右边的元素都大于该元素,然后不断地递归切分,最终能够得到有序的数组。并且这种采用切分的地方方法,所消耗的额外空间(主要消耗是递归的函数栈)要小于归并排序,只有lgN。因而这是一种时间和空间达到平衡的一种经典排序算法。
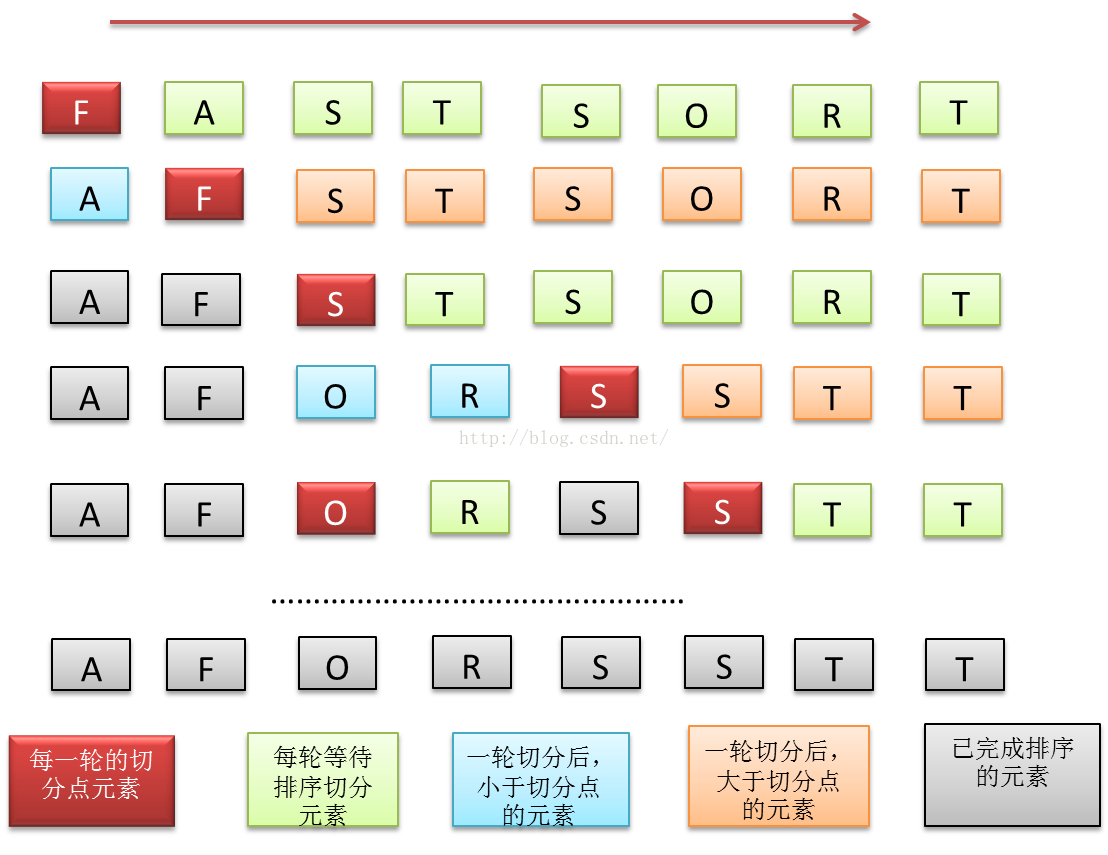
图 7 快速排序flow
三向快速排序
三向快速排序是对快速排序,在切分细节上的改进。其改进后的性能,在处理输入元素序列存在大量重复元素时,特别的明显。
三向快速排序,切分点元素要选择一个合适的中位数,并且该切分元素最好是大量出现的重复元素。然后设置lt, gt 分别作为小于和大于切分元素区域的边界分割标志位置。这样,只交换小于和大于切分点的元素,能够避免对重复元素进行交换。因而该排序方法根据输入元素的特点而变化,在重复元素较多时,时间复杂度能够达到N。最坏情况也能达到快速排序的NlgN。
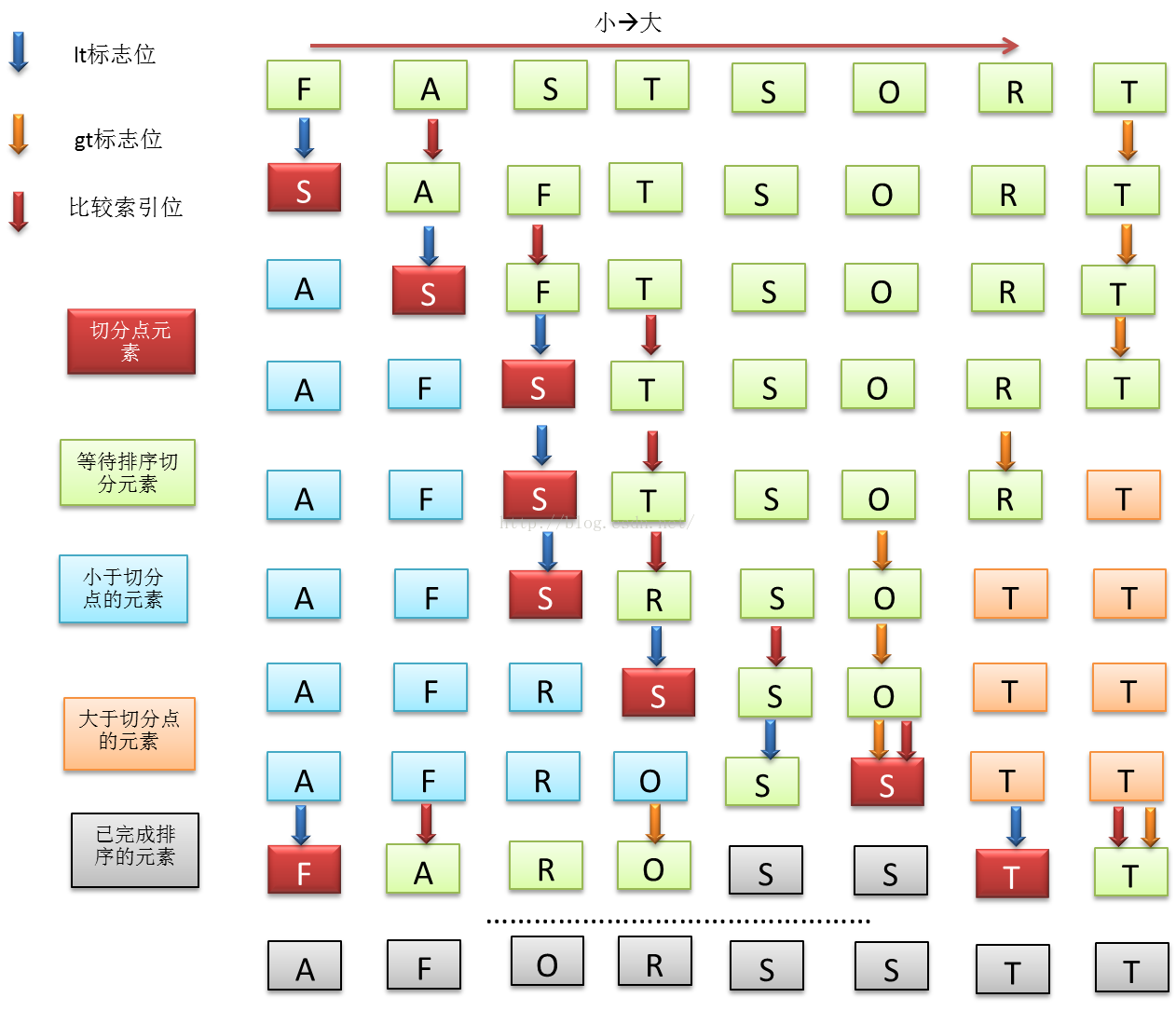
图 8 三向快速排序的flow
堆排序
当输入序列元素数量巨大,而运行结果只需要最大的10个元素的情况下,对所有数据进行排序,既要NlgN的时间,又要消耗空间少,这显然是不划算的,而且。这时可以采用一个二叉堆的结构来管理这些数据。
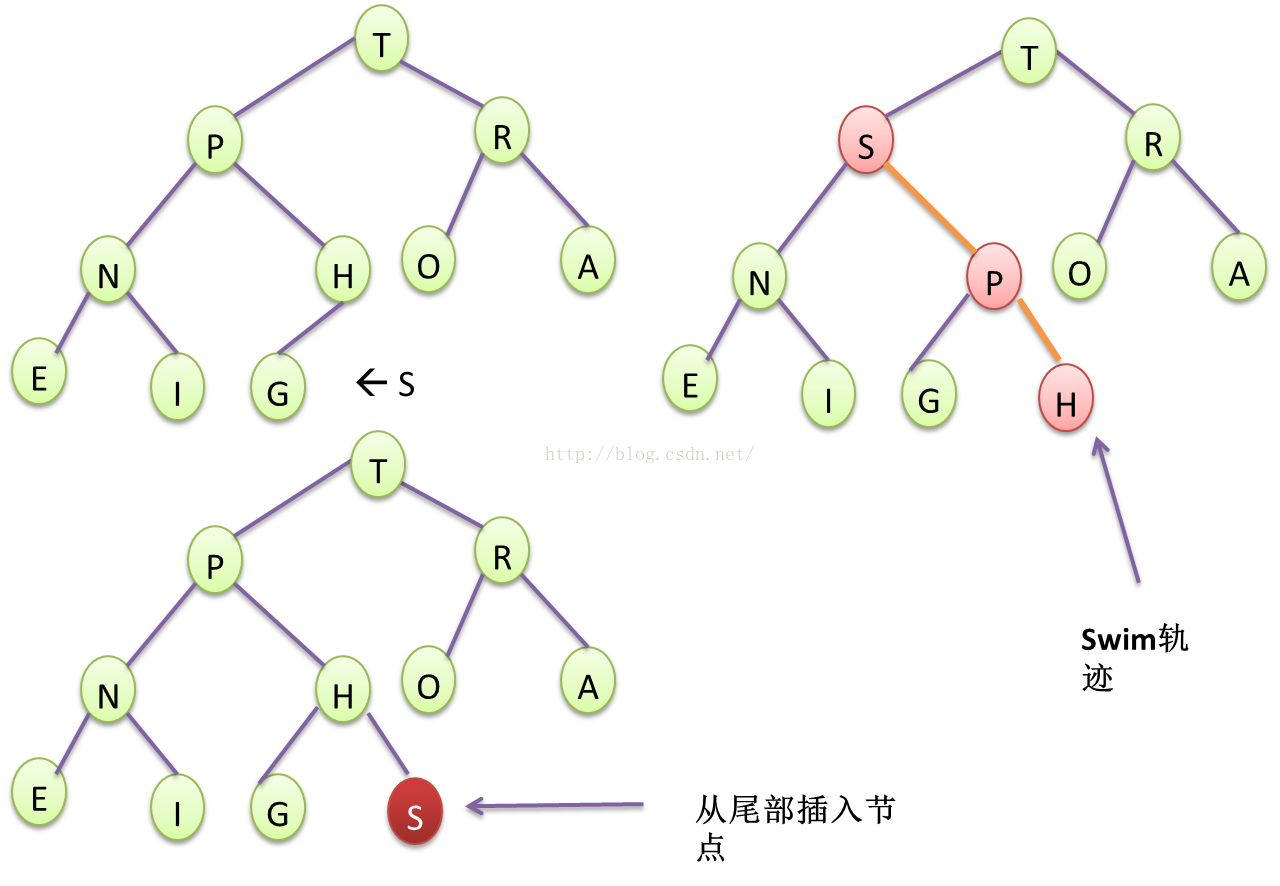
图 9 二叉堆的插入与swim flow
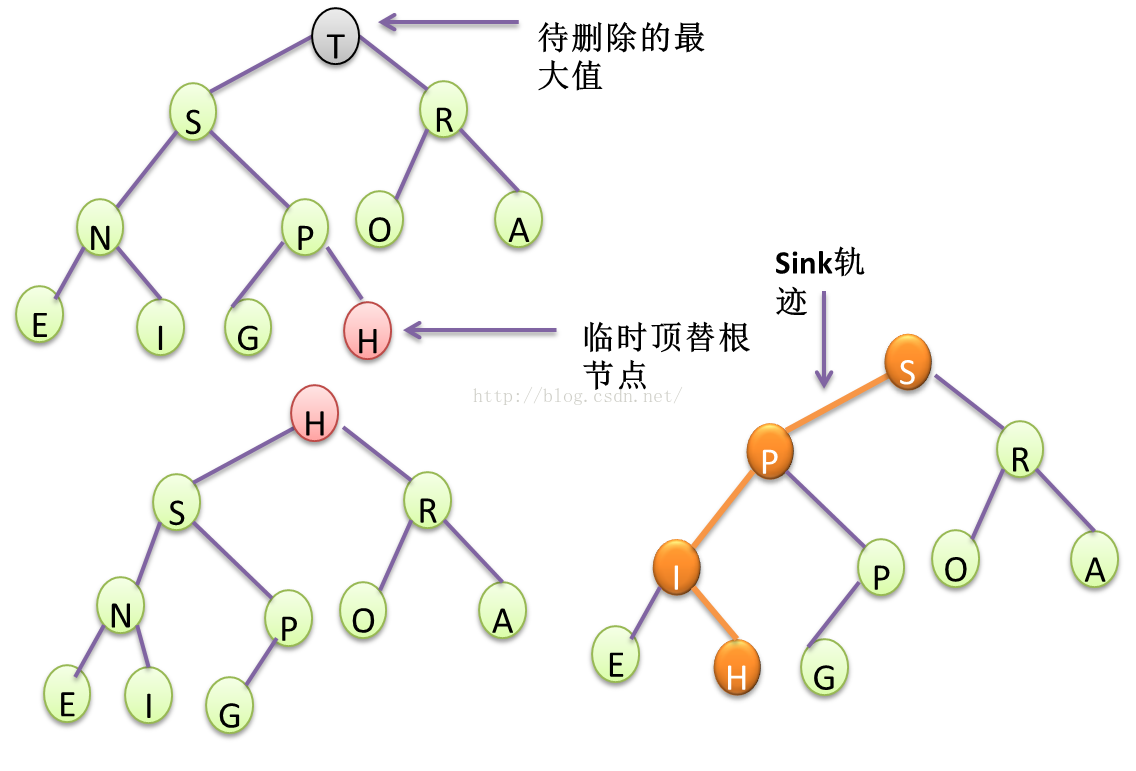
图 10 二叉堆的删除最大元素与sink flow
待排序的输入序列的元素按照二叉堆特殊的插入方法(尾部插入然后swim),插入二叉堆,然后用二叉堆特殊的删除方法(删除堆顶元素,将堆尾元素移至堆顶然后sink)删除顶部最大的元素,使得堆顶部保存的元素一定是最大的。通过不断删除获取堆顶元素M次,即可得到最大的M个元素。
通过二叉堆来组织输入序列的数据,不需要耗费额外空间,时间复杂度为NlgN,但是序列中的元素并不是完全有序的,我们只是为了在大量数据中,获取最大和最小的M个元素而已。
排序方法的灵活组合
排序算法在不同的场合各有各的优势,适当组合一番,可以对其进行一些优化,获得性能上进一步提高。
插入排序对其它排序方法的优化
插入排序时间复杂度不稳定,但是工程经验表明,在处理较小序列(例如N <= 8)时,并且输入元素序列有序度较高时,插入排序性能可能要优于快速排序或者归并的方法。那么在快速排序或归并排序递归分治问题的时候,当子序列已经被分治地比较小时,这时可以不再继续分治,而改用插入排序对小序列进行排序,然后再归并,这样能充分利用多种排序方法组合起来的优点,进一步改善算法的性能。
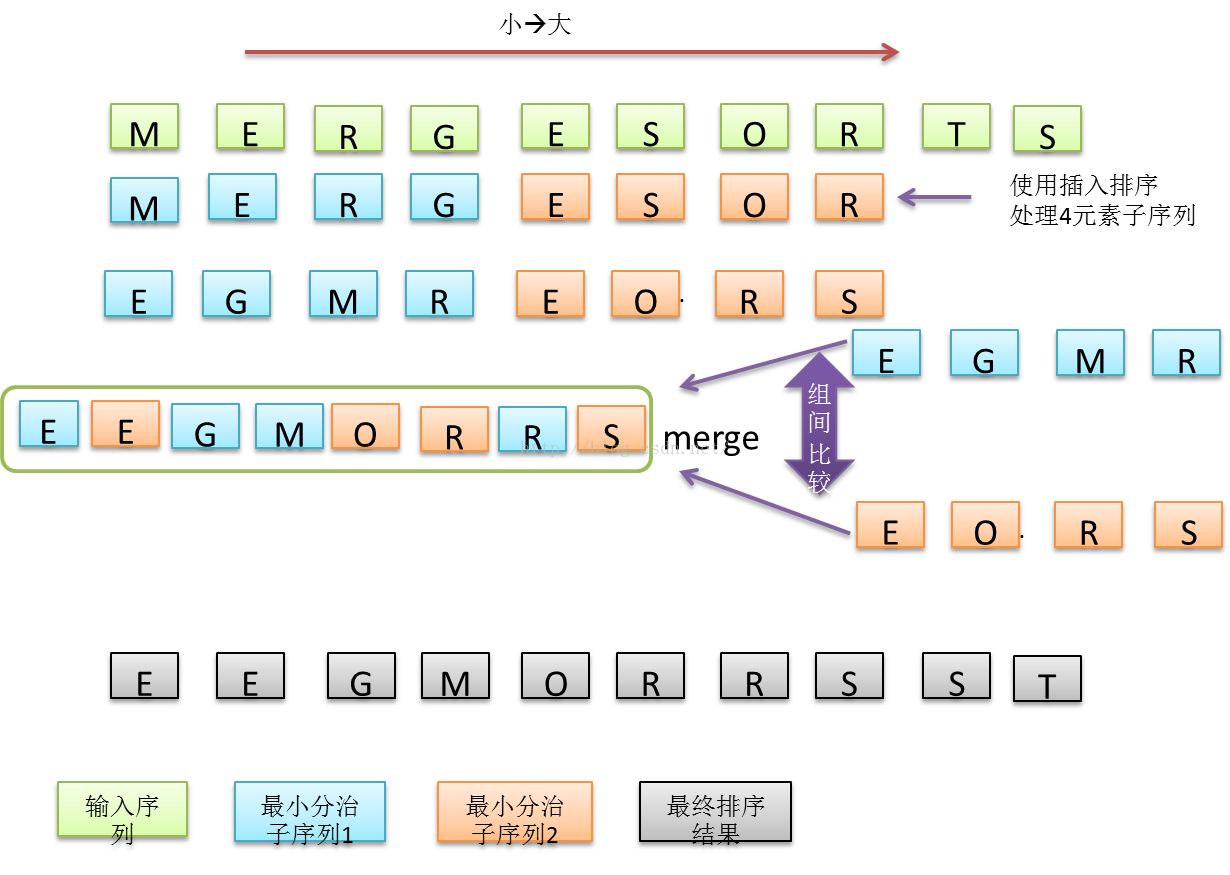
图 11 归并排序时,在子序列元素为4时,不再分治,采用插入排序














 2205
2205











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









