







查找
数据一旦被有规律得组织起来,从中查找出所需元素的效率将会大大提高。
查找算法准确的说,应该是数据的组织方法与查找方法的结合。没有组织规律的数据,我们只能用直观的暴力方法,一个一个拿出来对比,从而筛选出待查找的元素。而一旦数据变得有组织有规律,查找就变得轻而易举了。以下是各种查找算法的效率对比。
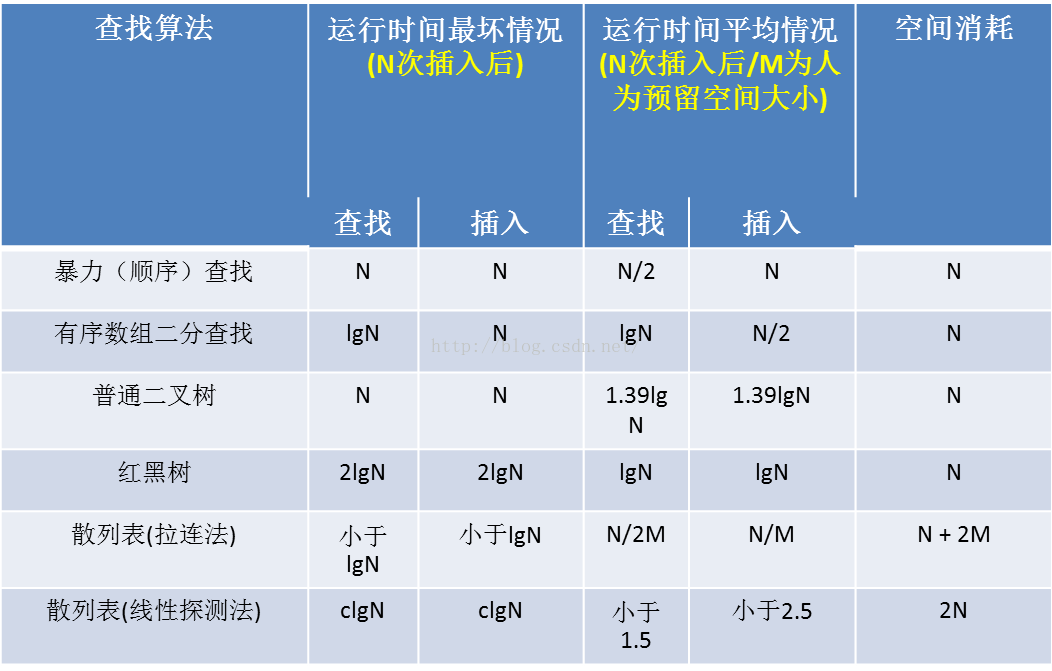
表格 1 各种查找算法性能对比
最直接的方法就是暴力查找,无需对数据做任何预先的组织与处理。其它高效查找算法,都不得不在预先的数据组织和处理上消耗一定功夫。
被查找的基本单元—数据项
数据要有一定的规则,才能够被组织起来。最基本的规则就是有序,比如“4、5、6、7、8”,“A、B、C、D、E”等数字或者字母,天生就就有顺序的规律。而有一些数据,比如中文名字“张三”、“李四”,天生是无规则的。当然我们可以用拼音字母顺序作为“张三”、“李四”排序的规则,也可以用中文笔画数作为排序的规则,这就让天生无规则的数据变得有规则,可排序了。
一般性的通用有规则数据,我们称为数据项。数据项包含两个部分——键(Key)和值(Val)。Key一般都选择天生有序的东西,比如阿拉伯数字”1 、2、3”,而值就是类似“张三”、“李四”这种天生无序的数据。有了一旦“张三”、“李四”作为值,分别有了Key 1和2之后,就好比有了学号或者工号,我们就可以通过学号(key)来对“张三”、“李四”进行组织排序了。
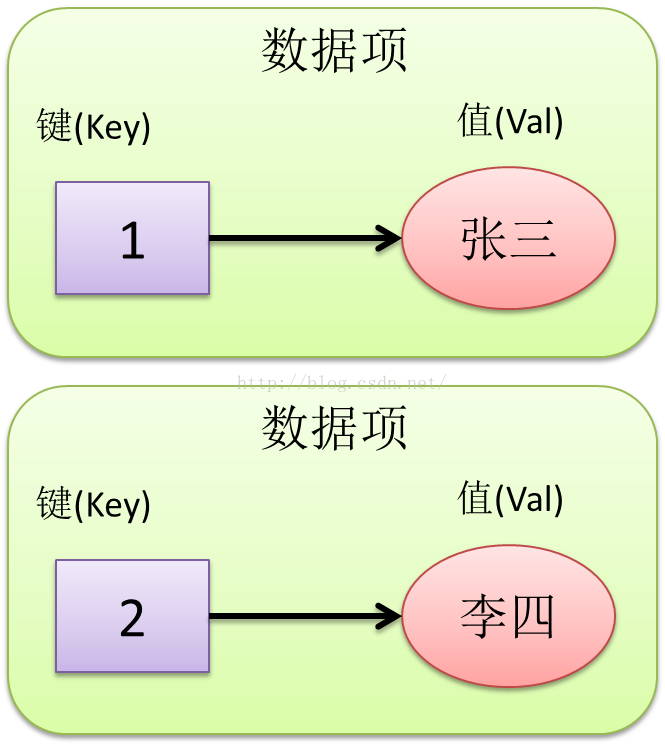
Figure1 符号表的数据项,键,值的关系
所以一般我们说Key 映射(Map)到Val,对于被查找的数据,键一般是人为加上的可排序的属性,而值就是数据真实的值。
当时数据项是类似“4、5、6、7、8”,“A、B、C、D、E”等数字或者字母或者其组合字符串,它们是天生就可排序的,那么Key 和 Val都可以对应可排序数据项本身,因而在讨论类似字符串或者数字查找的问题时,可以省略Key 和 Val的区分,直接对数字或者字符串进行组织排序和查找讨论。
可查找的有序的数据组织
一组数据,如果将基本的数据项,根据其键(Key)先后顺序进行排序组织,那么通过键(Key)大小关系,在组织好的一堆数据中通过类似二叉查找的方法,查找对应的数据项,效率将接近lgN。
1). 有序数组二分查找
如果输入数据可以组织成数组形式,那么对数组进行由小到大排序后,可以通过二分法对数据项进行查找。二分法一般从有序数组中间开始,判断待查找的数据项是大于还是小于中间项,然后再把查找范围缩小一半,如果小于中间项,则下次查找范围是第1项到中间项,否则就是中间项到最后一项。
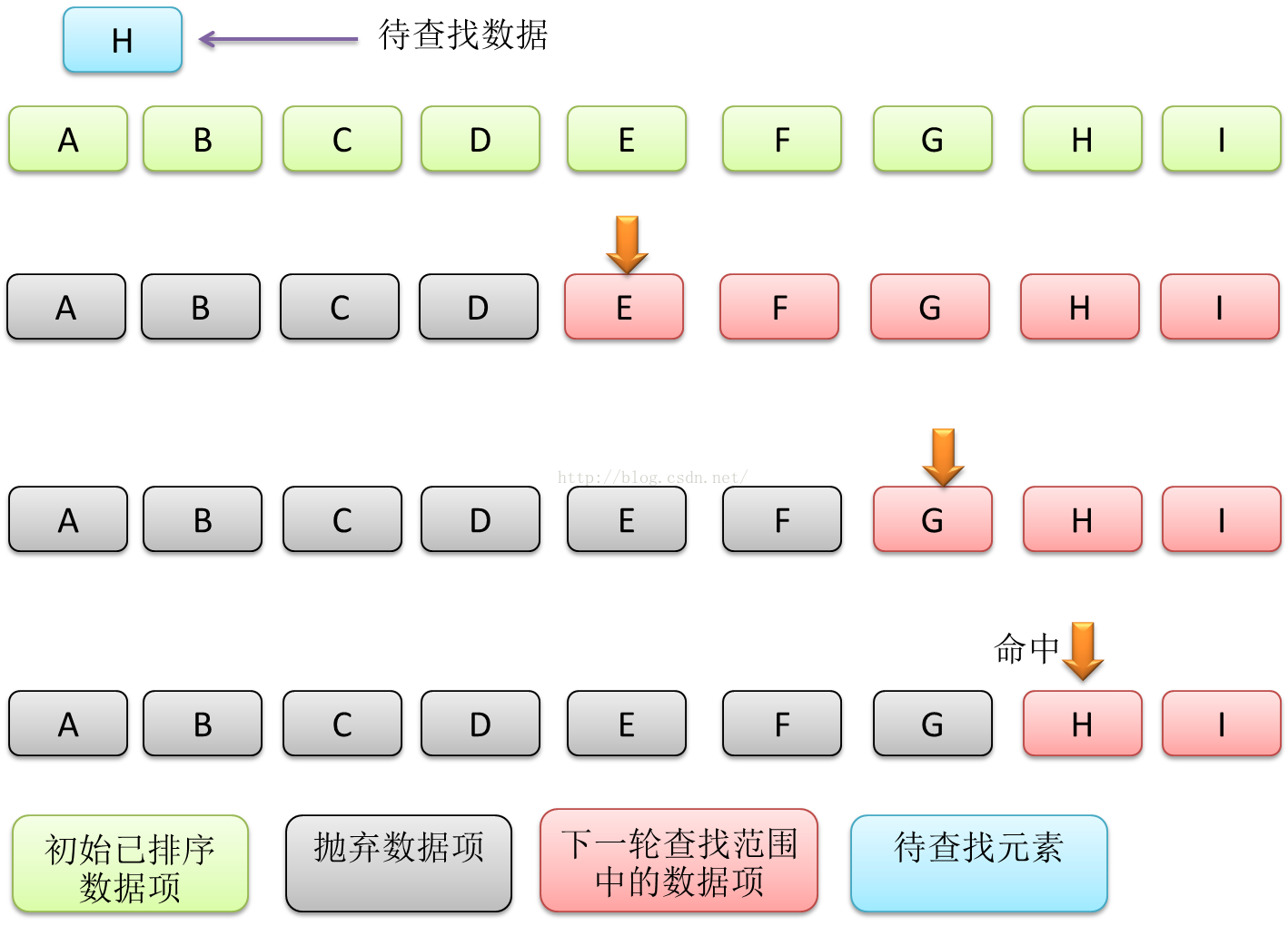
Figure2 一次命中的二分法数据查找过程
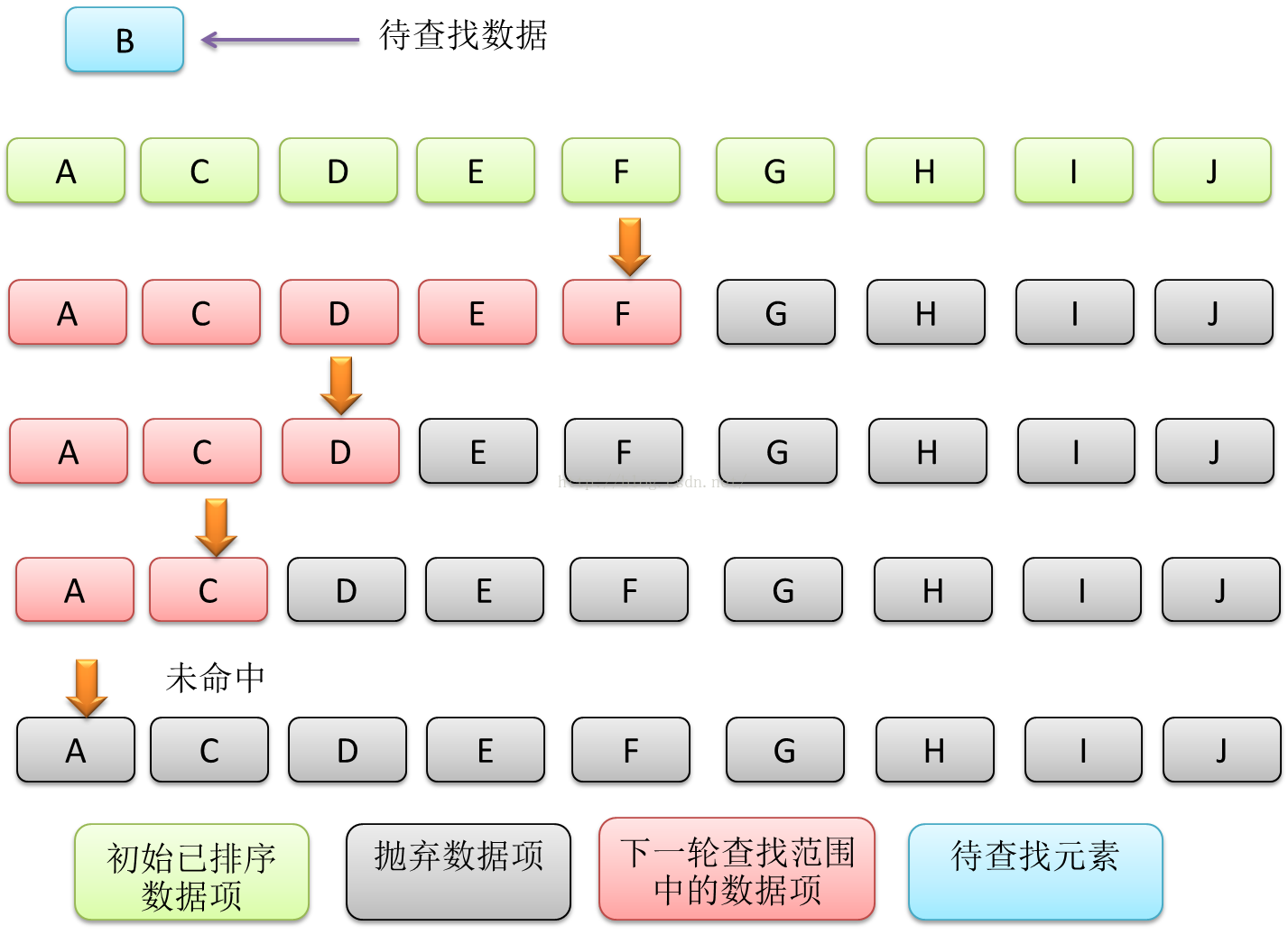
Figure3 一次未命中的二分法数据查找过程
有序数组二分查找比较简单,但是适应的场景有限,尤其是需要面对动态增加或者删除数据项的场景,数组删除和插入都不灵活,需要提前确定数据项的数目量,定义好一块空间,这样将大大降低数据插入和删除的效率。。
2).二叉树
二叉树在高层抽象上,可以看成一种树形结构的数据组织方式。其实现方式可以是某种特殊数组,也可以是链式结构(不同于单双向链表。采用链式结构的二叉树,能够弥补有序数组二分查找的缺点,适应无法提前知道输入数据数量,需要动态插入和删除数据的场景。二叉树的每个二叉节点包含分别指向左右子节点的引用或指针)。二叉树1个节点只有1个键,没用左右子节点(子树)的二叉树节点,称为叶节点。
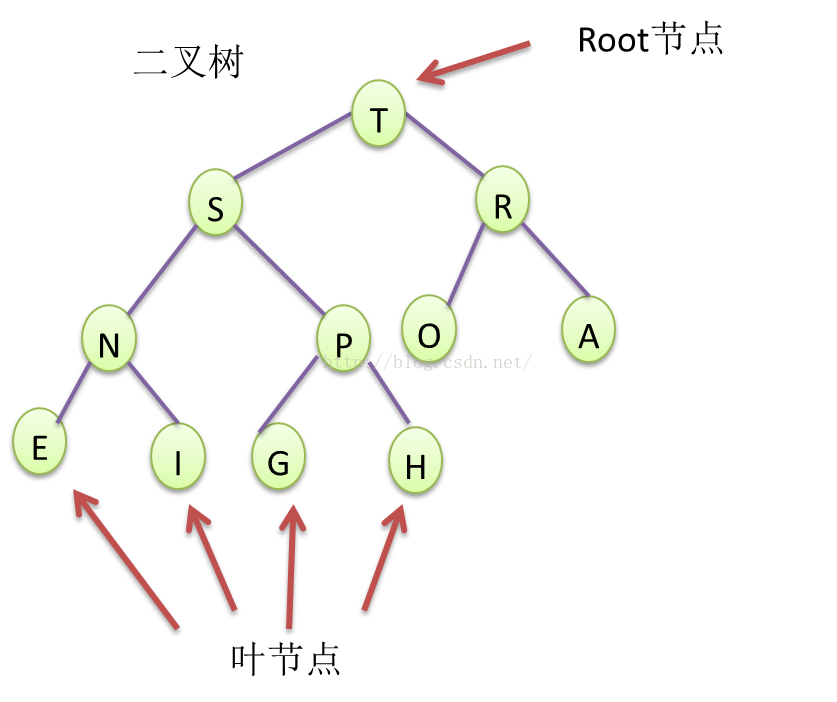
Figure4 典型的二叉树
将数据项(默认不含重复键)插入二叉树时,保证一个节点的键值,大于其左节点键值,小于其右节点键值。这样从根节点(root),一直往左查找,则值越小,一直往右,则值越大。
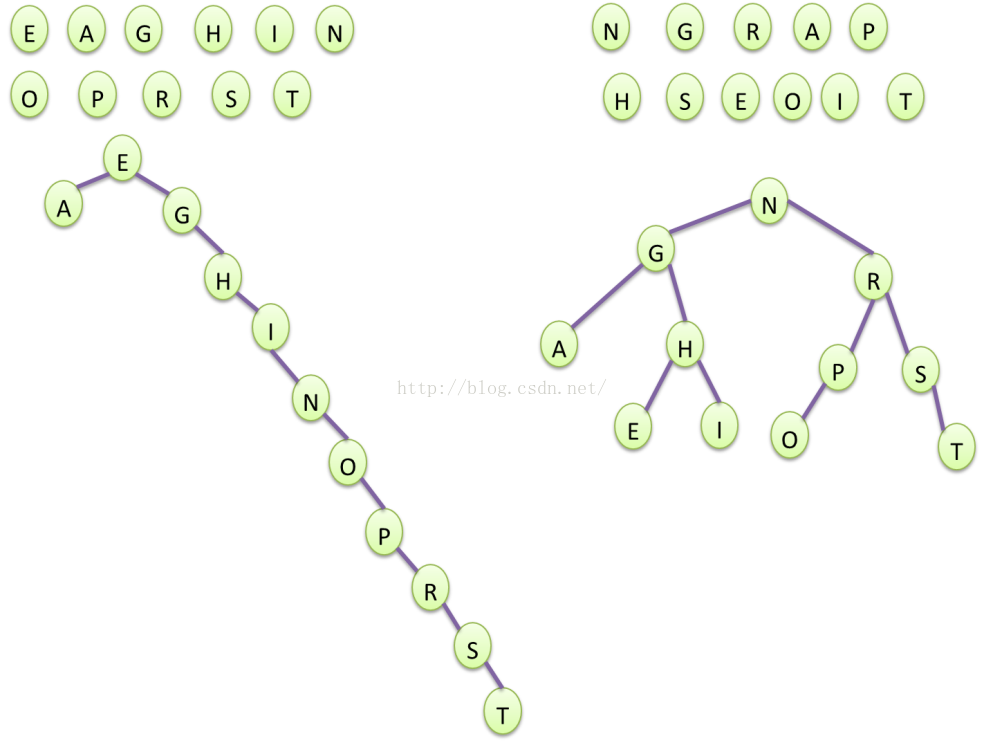
Figure5 同样是数据,不同的插入顺序导致的红黑树结构性差异
一般二叉树的形状,和其数据项的插入顺序有关系,同一组数据项,如果插入顺序不同,那么其二叉树的形状也不同。一个二叉树,root节点的左子树的深度和右子树的深度一样,则二叉树是平衡二叉树。如果一棵二叉树不平衡,由于深度的影响,将使得搜索效率不稳定,平均时间复杂度是lgN,但是搜索不同元素的复杂度和效率差距太大,所以需要找到一种平衡二叉树的结构,使得搜索不同的数据项效率稳定一些,不至于相差数倍。
3).平衡二叉树(红黑树)
红黑树是一种平衡二叉树。如何使得二叉树插入的时候变得平衡,不受插入顺序的影响?这是个经典的问题,红黑树是其中最经典的解决方法(平衡二叉树的实现方法不只有红黑树一种)。但是红黑树的旋转平衡过程,可能有违直觉,很多时候只能死记硬背下来,实际上,要理解红黑树的平衡原理,先要从3-B树说起。
3-B树
B树是一种多链接树(二叉树是2链接),根据节点中的键数和链接数可以分为很多变种。这里讨论的3-B树,稳定时,一般包含2-节点(节点有1个键,2个子链接,等同于普通二叉树节点)和3-节点(节点有2个键,3个子链接)。其稳定时,每个节点的键数一定是小于3(4-B树,节点键数小于4,N-B树键树小于N,链接数=键树+1)。
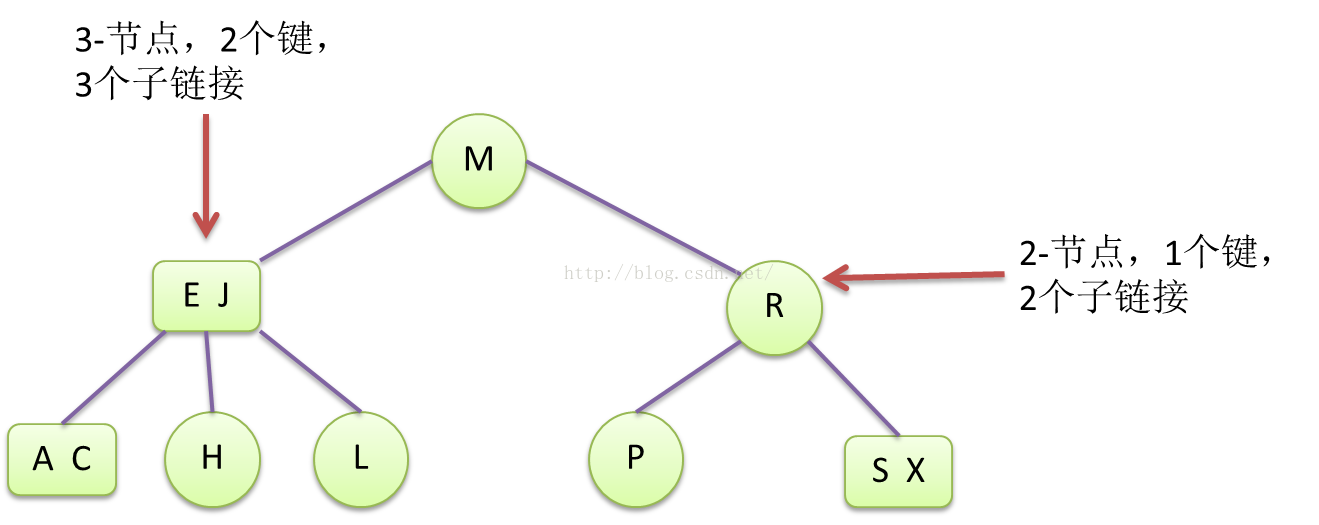
Figure6 3-B树概念图
一棵3-B树,它的2-节点和二叉树一样,其键值大于左子树的键值,小于右子树的键值。但如果是3-节点,有2个键,左子树键值小于2键的最小键,右子树键值大于2键最大键,中间子树的键值,为2键直接的值,即大于2键最小值,小于最大值。
3-B树的键插入,是有别于二叉树的,不是二叉树那种找到键的位置,直接挂上去。3-B树是先与一个存在的2-节点合并成3-节点,当3-节点中还要插入键,形成不稳定的4-节点时,才会分裂向上增长,这种一层一层往上增长,而不是二叉树那种往下增长,挂载节点的方式,能保持全局的平衡性,因而不会出现图5左侧由于输入顺序不同而产生的畸形二叉树的例子。
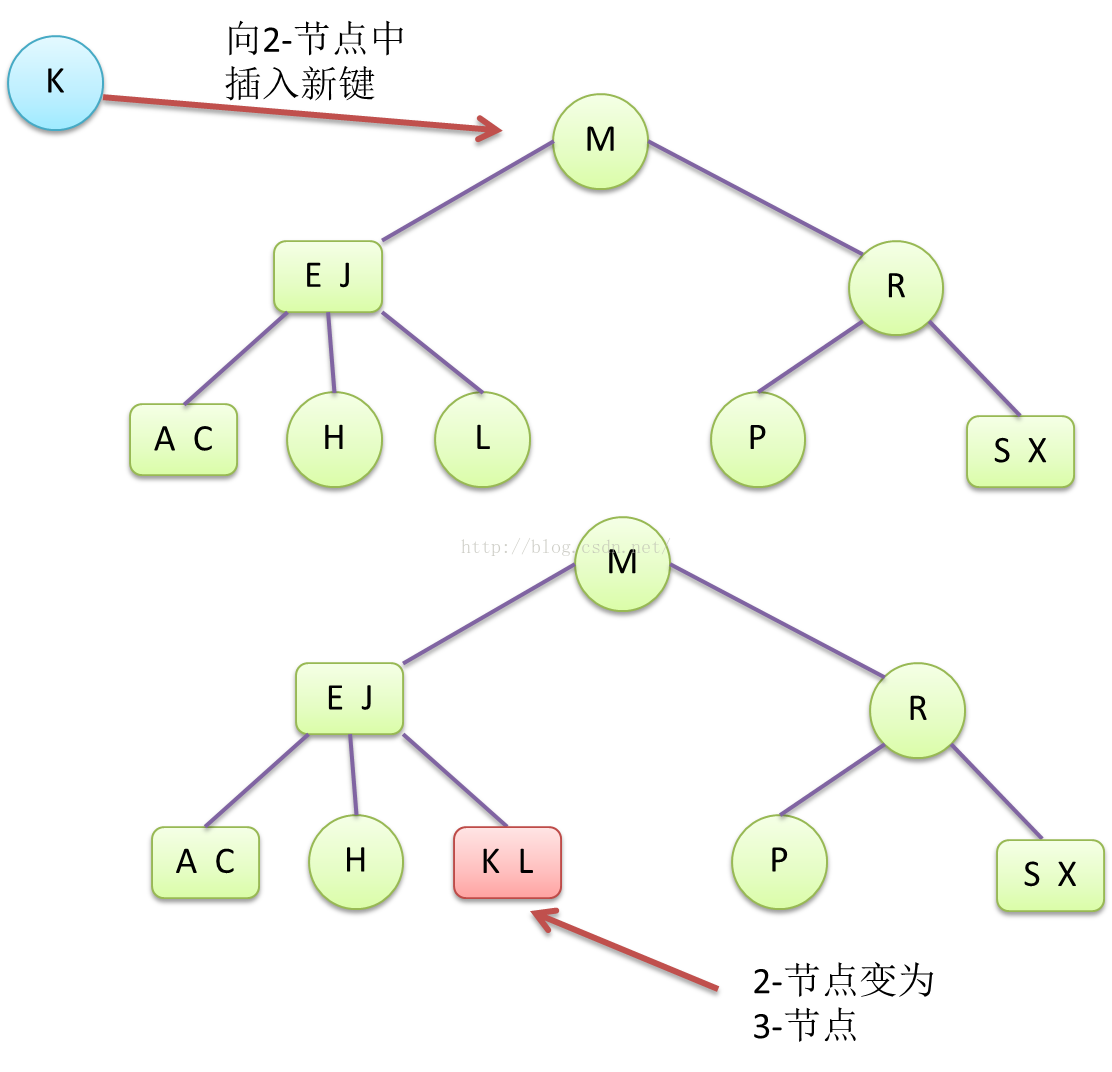
Figure7 向3-B树中的2-节点插入新键,变成3-节点
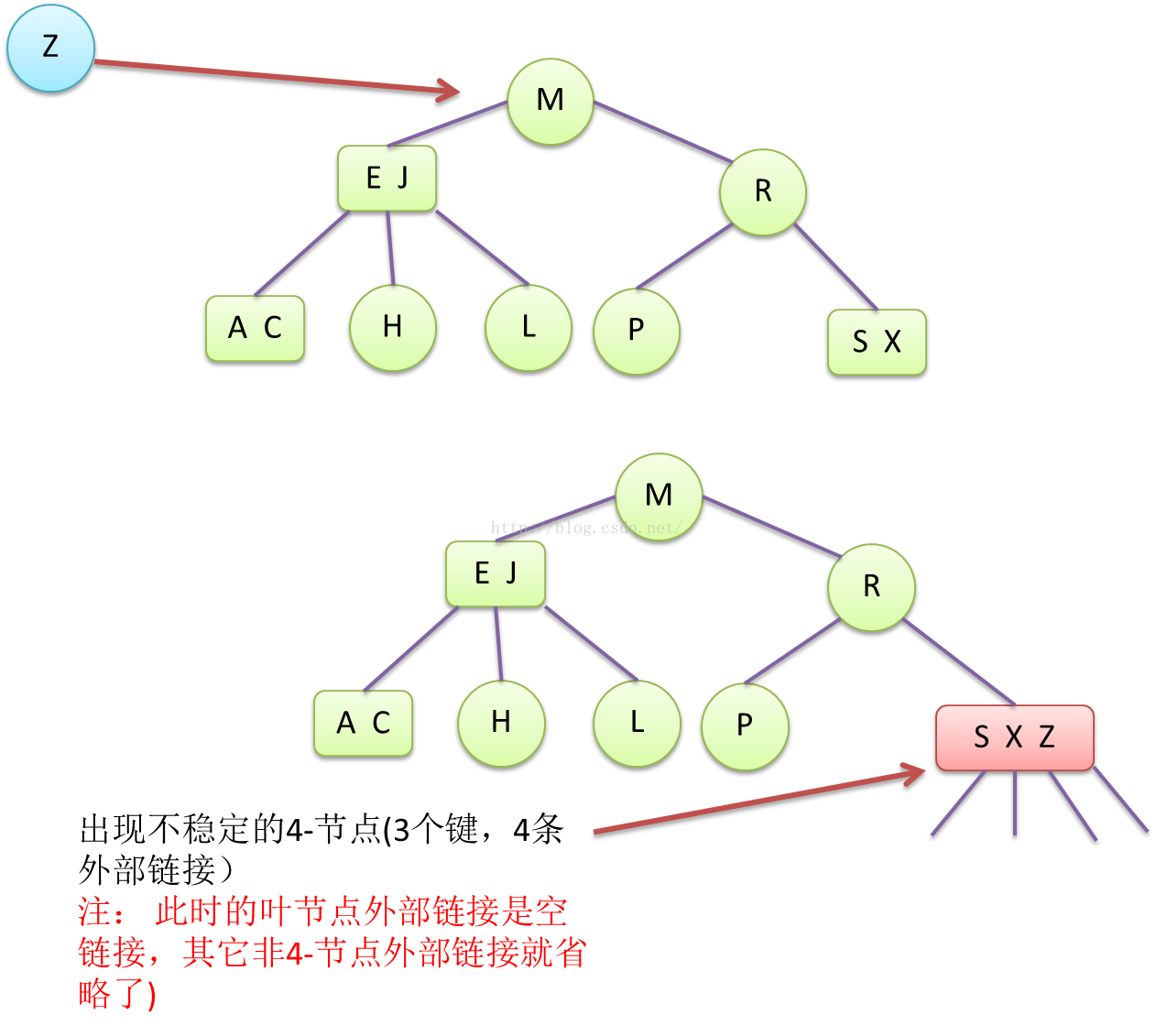
Figure8 向3-B树3-节点插入键,得到不稳定的4-节点的case
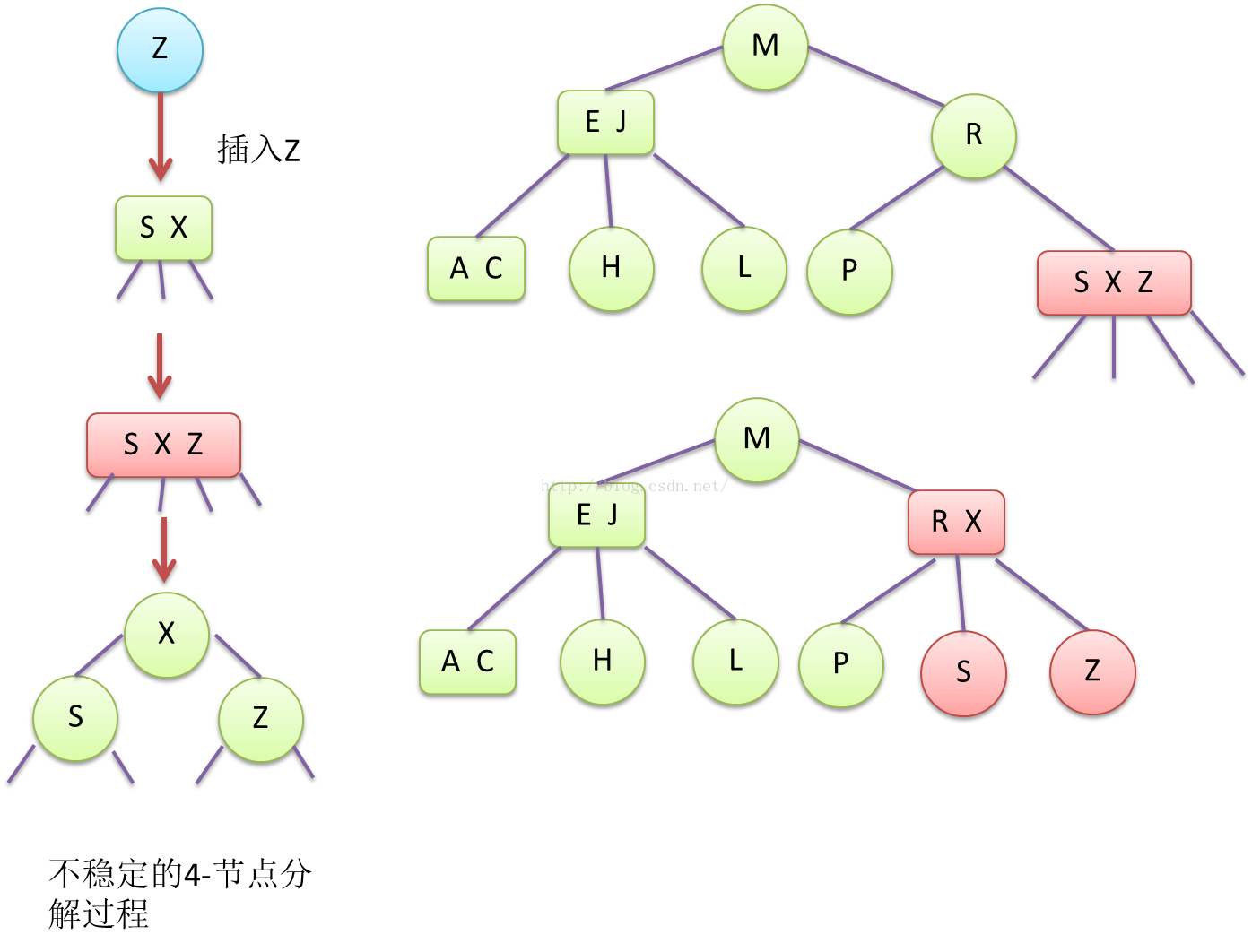
Figure9 含有4-节点的不稳定3-B树恢复稳定平衡的过程
当一个3-节点插入一个新键时,该节点变成一个临时的4-节点(3个键,4个链接),这时,3-B树处于不稳定状态,4-节点需要分解成2-节点和3-节点。分解的过程就是:4-节点 --> 劈裂成3个2-节点子树 --> 中间键节点上升到上一层,与上一级节点合并 --> 如果合并后,上一级节点是3-节点,则3-B树回到稳定状态,否则变成4-节点,继续分裂并往上层提升,直到根节点,最终会使得3-B树变回稳定状态。
3-B树的插入变化都是局部变换,并不影响树的全局有序性和平衡性,所以这是一种很好的节点插入和维持整棵树平衡的方法。
3-B树保持平衡的原理虽好,但是毕竟它不是以二叉树的形式实现的,结构要复杂一些,管理和查找起来没有二叉树简洁。红黑树则是通过对节点/链接增加颜色属性,来模仿3-B树的特性,使得其具有二叉树的查找搜索特性,又能模仿3-B树局部变换带来的插入后全局有序性和平衡性。
红黑树
红黑树的基本思想是用标准的二叉树和一些额外信息(颜色)来表示3-B树。相应的等价替换如下:
a) 红黑树将二叉树中的链接分为2类——红链接和黑链接
b) 黑链接等价于3-B树中的普通2-B节点之间的链接
c) 如果3-B树中有3-B节点,由于二叉树不能有3-B节点,因而在红黑树中,可以用红链接(内部链接)将两个节点连起来,等价替换3-B树中的3-节点(2个键,3个外部链接)。注意,原本3-B树中的3-节点内部的2个键是没用内部链接的,因为B树不是二叉树,但是由于红黑树是二叉树,每个节点只能有1个键,因而将3-节点内部的2个键劈裂开,独立成节点,再用红链接连起来,所以说,红链接类比于3-B树的3-节点中,2个键之间的内部链接。
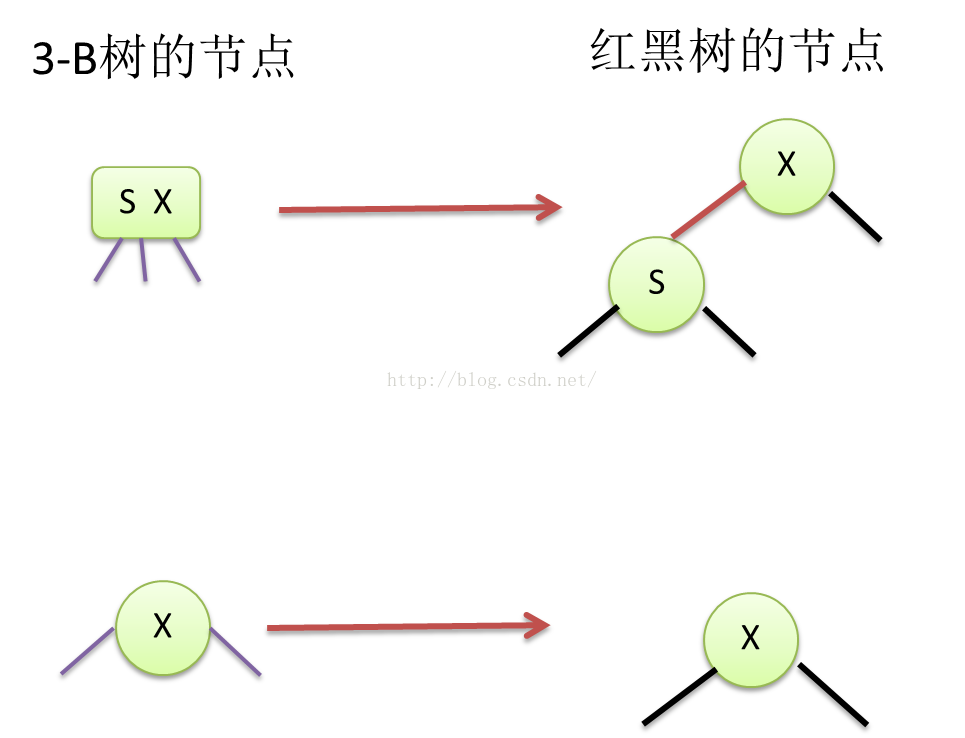
Figure10 3-B树与红黑树的节点替换关系
一棵红黑树,它自身的限制和定义如下:
d) 二叉树的每个节点,分别拥有左右两个链接来连接左右子节点。红链接只能是节点的左链接。
e) 红黑树中,没有任何一个节点,同时和两条红链接相连。
f) 如果任意叶节点到根节点路径上的黑色链接,数量都相同,则该红黑树是完美黑色平衡的。
g) root节点默认是黑色节点
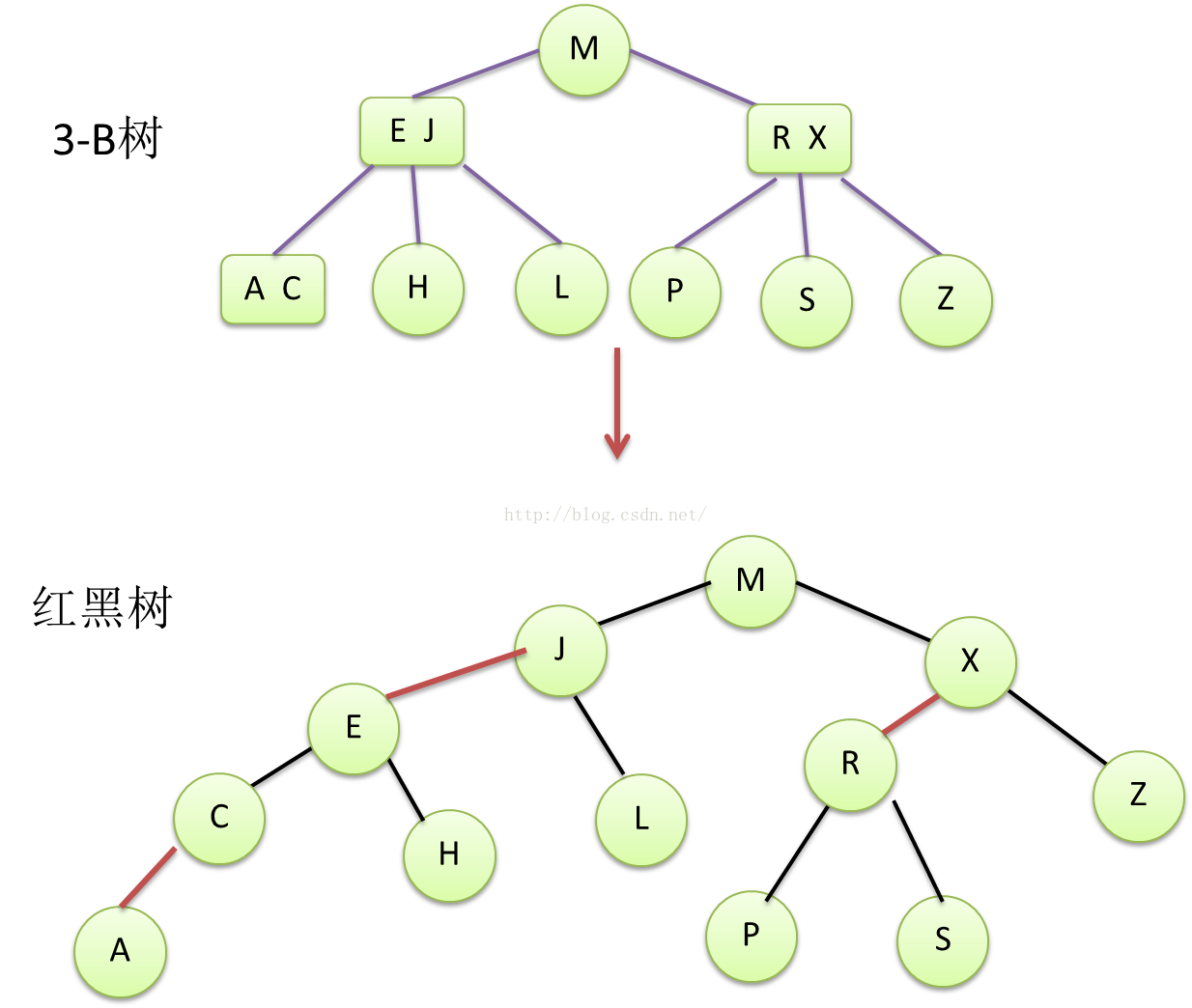
Figure11 符合以上限制条件的3-B树到红黑树的变换
如何理解规则d、e、f呢?
d规则实际是为之后红黑树的平衡做简化处理,如果同时允许左右链接都出现红色,则要处理的平衡旋转的case会更多。
e规则是直接从3-B树借鉴来的,一个节点如果同时有两条红链接,它对应的就是3-B树中的4-节点,是不稳定的,必须旋转平衡来消除这种case。
f的话,红黑树无法做到完美平衡的二叉树,只能做到黑链接深度相等,但左右总深度差一般不超过2,这也是实现复杂度与平衡完美性之间的折中。所以红黑树无法实现绝对完美平衡的二叉树。
g节点颜色等价替换链接颜色,root节点已经没有父节点了,所以没有指向它的链接,所以肯定不是红色节点,可以默认是黑色节点。
关于红黑树的定义,讲的都是红链接和黑链接,可是一般二叉树程序实现的都是在操作节点,而并不管链接的,二叉树的节点一般都是这样的结构表示的:
typedef struct node{
int val;
int key;
struct node *left;
struct node *right;
} node;那红黑树的红链接和黑链接在代码中怎么表示呢?
实际上,为了方便起见,一般都是给节点加入颜色属性,通过节点颜色来等价替换红链接和黑链接的。典型的红黑树节点描述如下:
typedef struct rb_node{
enum COLOR color;
int val;
int key;
struct rb_node *left;
struct rb_node *right;
} rb_node;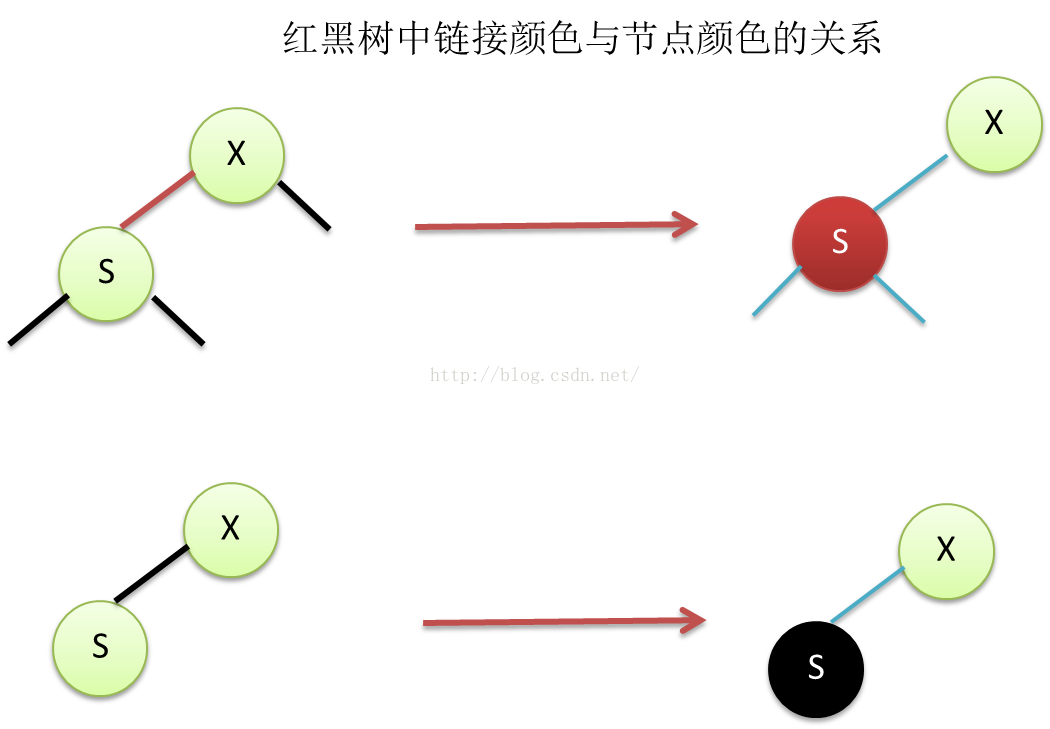
Figure12 编程时,链接颜色变换到节点颜色的简化关系
为什么节点加上颜色属性,就能描述链接颜色了呢?实际上,在二叉树中,除了根节点,其它每个节点A,都会是另一个节点B的子节点。那么必然会有一条链接从节点B指向节点A。因而,每个非根节点A,都会有且只有一条从其父节点B指向自己的链接。那么,如果指向A节点自己的链接是红色的,我们就给A节点的颜色属性标上红色,如果指向A节点自己的链接是黑色,那么就给A节点标上黑色。这样就在代码中出现了红节点和黑节点。根节点默认是黑色节点。我们千万要注意的是,在二叉树的概念中,并没有红节点和黑节点,只有红链接和黑链接,红节点和黑节点的意义是,通过概念与代码等价替换,表示指向自己的链接的颜色。
红黑树的节点插入
把红黑树中,从3-B树 --> 红黑树的限制与定义 --> 红黑树的节点代码这一连串的概念等价替换搞清楚后,剩下就是红黑树的节点插入、删除与旋转了。
根据上面红黑树的d、e、f三条限制和约束,我们将一个节点插入稳定平衡的红黑树时,大概也只有如下图描述的几种case来调整红黑树的局部特性,使得整棵树重回平衡。其中,节点应该插入的位置,是根据二叉树“左-中-右”,“小-中-大”的规则摆放的。
由于d、e、f三点规则的限制,向红黑树插入一个节点后,节点插入后,刚开始,链接一定是红色的,但是这可能是不平衡状态,所以需要做旋转再平衡处理。几种旋转再平衡的case如下所示,该平衡过程会一直往上层散发,直到满足了红黑树3条约束为止。
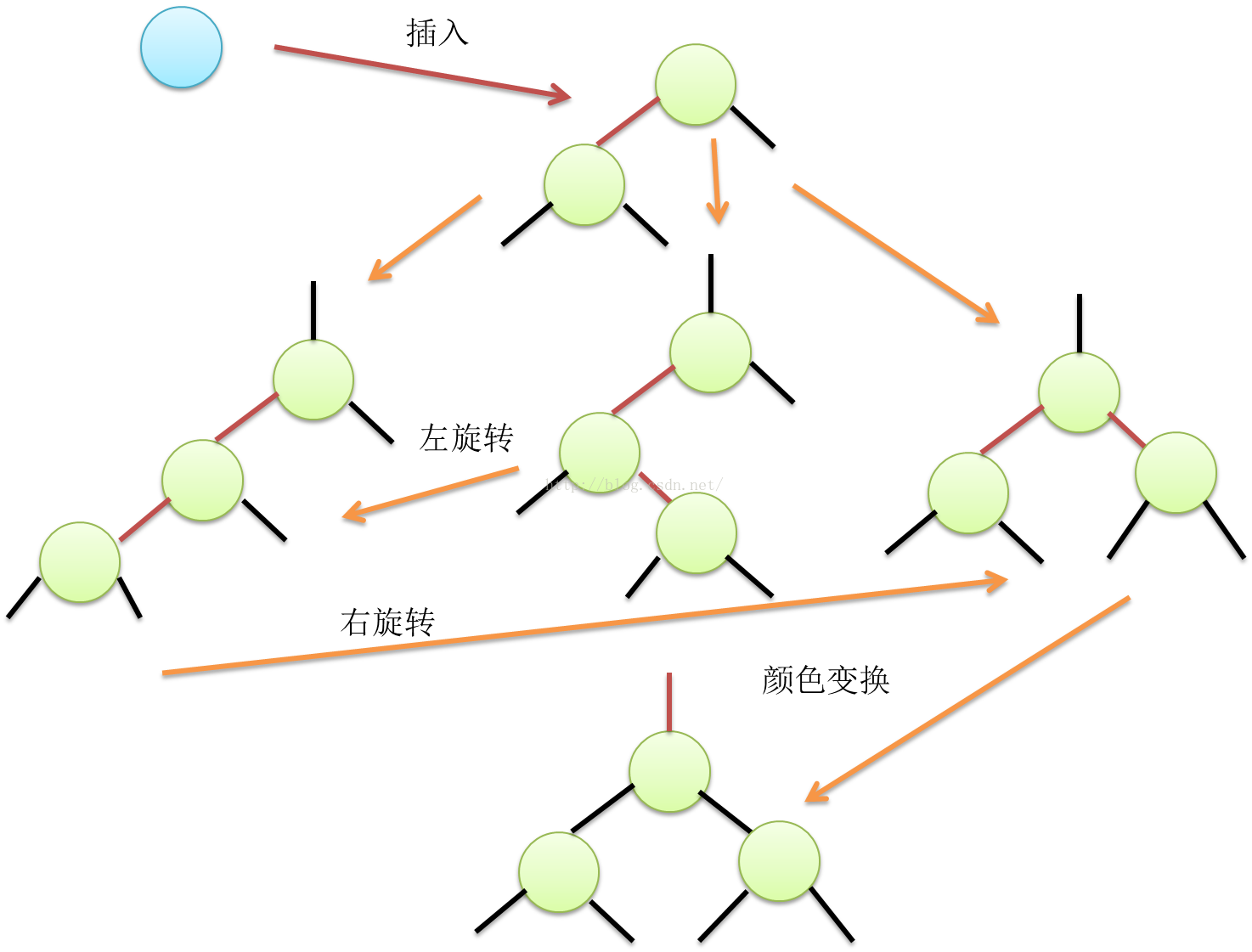
Figure13 红黑树不稳定节点的选择与平衡规则
红黑树的节点删除
红黑树的节点删除要比插入复杂一些。该处一定要用图结合源代码看才能明白,红黑树的实现代码在我的github上有一份,就不直接贴出来了。
要理解红黑树节点的删除,还是先得看看3-B树节点是如何删除的。
从3-B树的3-节点中,删除1个键其实问题不大,因为3-节点有2个键,删除了键,节点还是保留的,因而可以退变成2-节点。但是2-节点的键是不能直接删除的,因为删除2-节点的键,整个节点就不存在了,那么相当于留个一个节点空位,2-B树不像普通二叉树,它的2-节点和3-节点之间要做一些旋转和变换才能连接起来,否则就会破坏树的规则了。
所以一般的3-B树的2-节点删除操作,和插入过程相反,要先和其相邻的节点,合并成不稳定的4-节点或者合并成3-节点,然后再删除对应的键,这样就不会留下空位,能够保持整棵树的平衡,记住,一定不能直接删除2-节点。删除前的变换case大概有这几种。
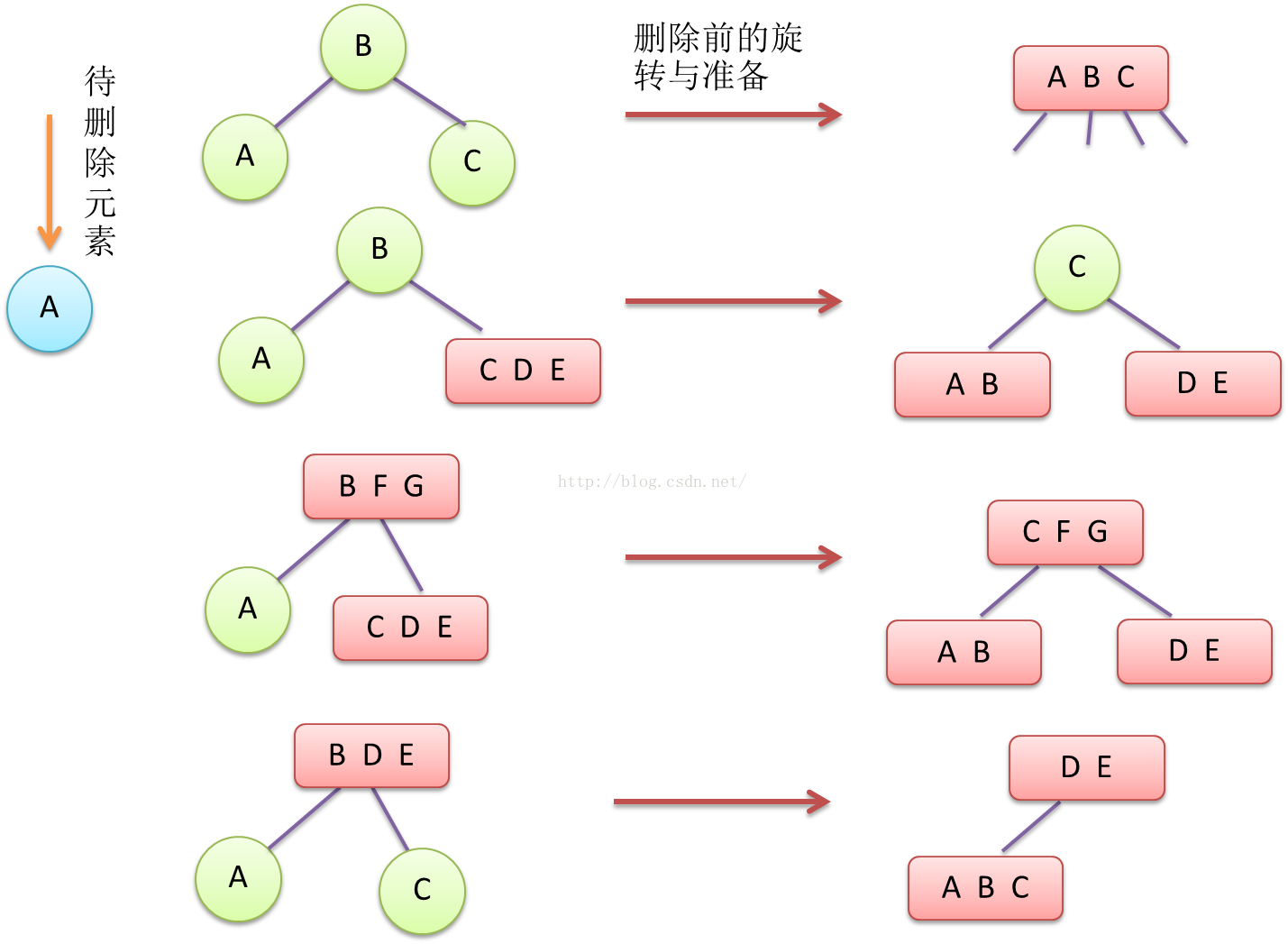
Figure14 3-B树中,删除2-节点,删除前的变换与准备场景
看完3-B树如何删除节点之后,还是用红黑树与3-B树的等价类比的方法将这个过程变换到红黑树这边来,黑色链接的节点不能直接删除,只能删除左边红色链接的节点。于是就有这样的几种case.
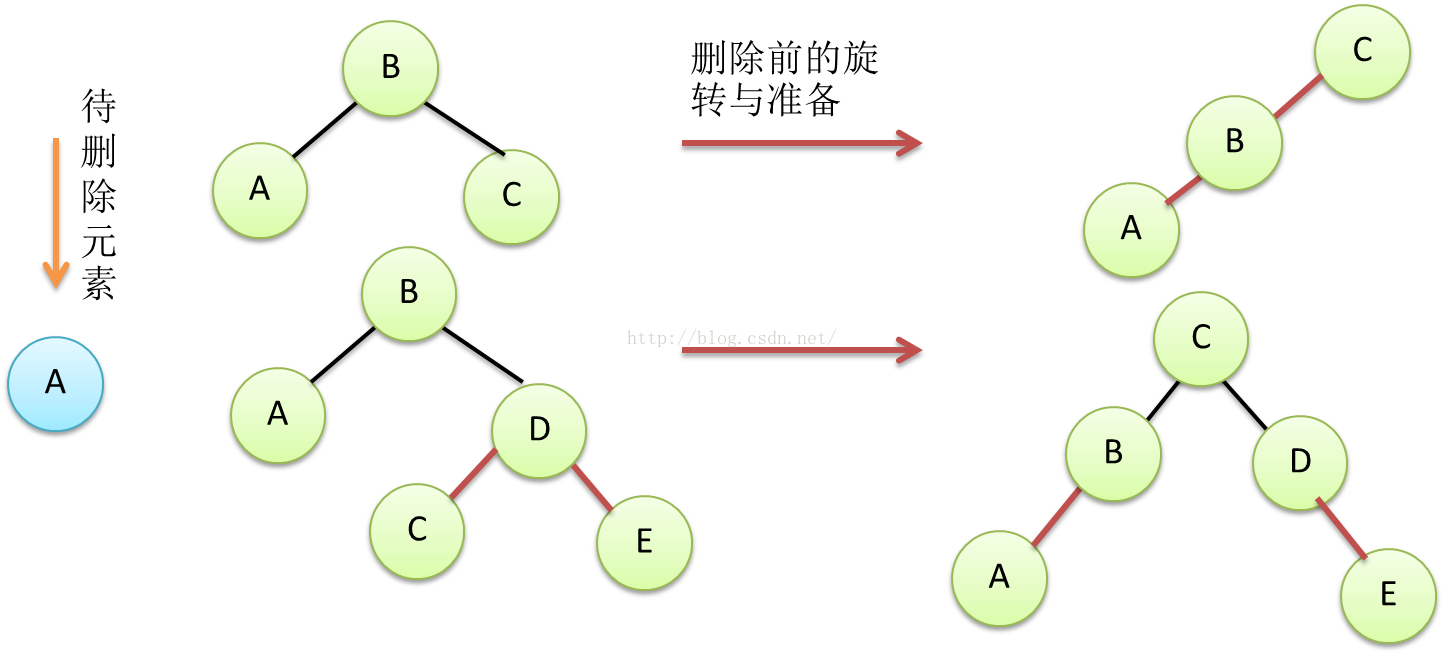
Figure15 红黑树,删除黑色节点前的准备工作case1、2
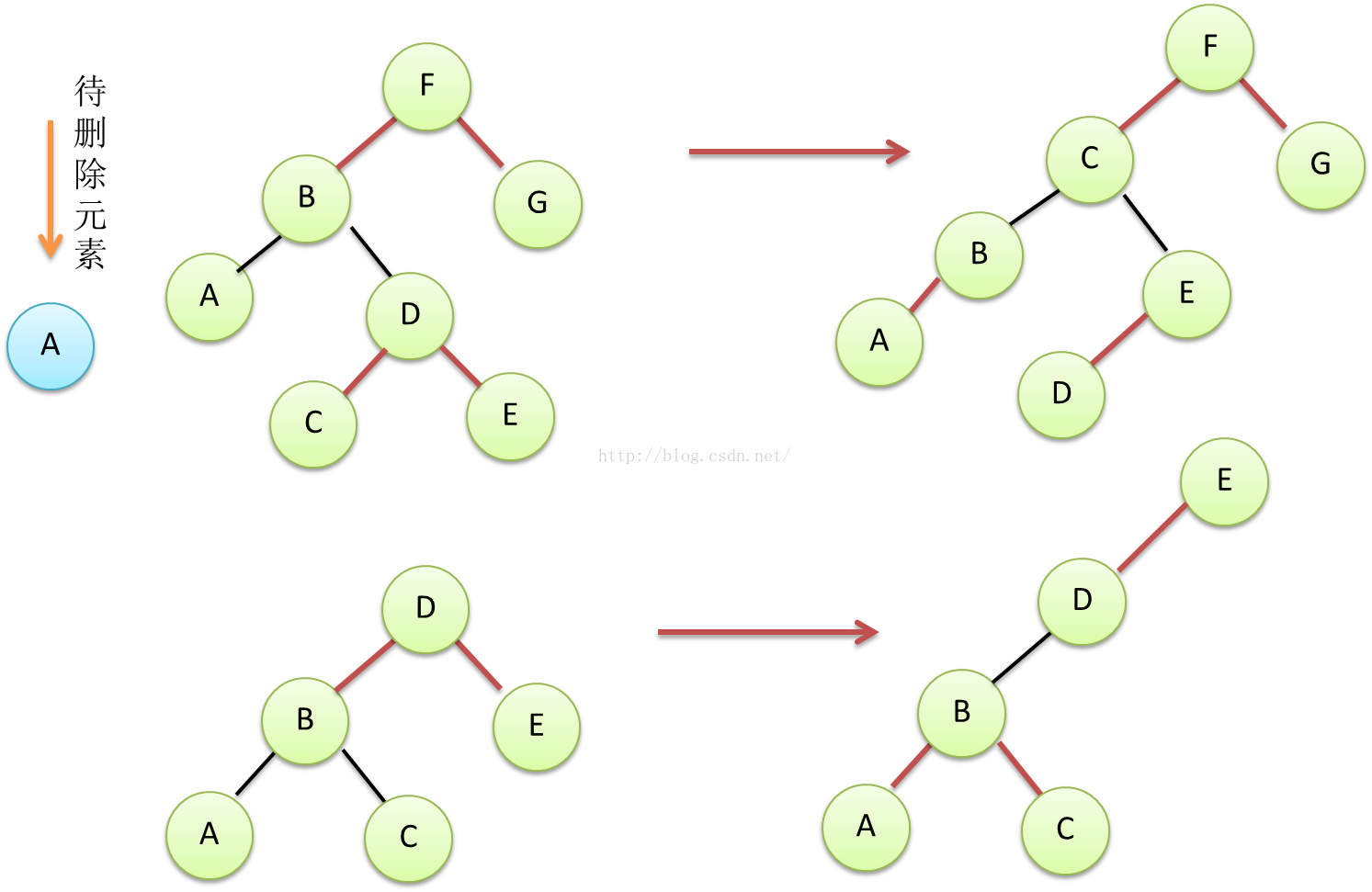
Figure16 红黑树,删除黑色节点前的准备工作case3、4
红黑树的删除代码,删除黑色链接节点前所做得事情,都是在旋转,使得该黑色链接变为红色链接,这时局部可能违反d、e、f等几条规则,变成不稳定状态,但是在这些不稳定状态都可以通过图13的旋转与平衡规则,恢复到平衡的状态。
总之,红黑树插入时,链接是红色,删除时,也是红色。插入和删除的过程中,再平衡的case其实还是比较少,不会超出以上途中的几种组合,这些case也是红黑树比较死的规律,所有的实现代码基本是雷同的,都会相应处理。
红黑树小结
总体来说,要理解红黑树,不能只研究其本身实现,一定要从3-B树出发,一个一个等价变换到红黑树上,才知道红黑树为什么要这么做。就红黑树讲红黑树,还是挺麻烦的。虽然说红黑树对于初学者,是个比较吓人的算法,但是实际上它的代码逻辑还是很简洁,效率也是很高的(时间复杂度接近lgN),因而应用十分广泛,在Linux内核的进程调度的实现中,在CFS调度器中,也是通过这种方法根据进程优先级进程组织和查找,得到优先级最高的进程进行调度的。
可查找的无序的数据组织
所谓可查找的无序数据组织,
1) 顺序遍历
顺序遍历俗称暴力查找法,其实也没啥特别的地方,就是将一堆数据一个一个拿出来比较查找,这也是最符合我们直觉的搜索方法。虽然该方法比较简单粗暴,实际上时间复杂度为N,对现代处理器来说,还是可以接受的一个速度,并且该方法不需要在检索前对数据预先处理。整体上来说,就是简单,简单,简单。可不要小看简单的价值,简单意味着容易实现,调试也简单,不容易出bug,虽然搜索的慢了点,但是可以节约开发和预处理时间。因而在一些小型软件项目,数据量不大时,暴力查找算是一种实用的算法,在此也不多累述。
2).散列表(Hash/哈希表)
在不以顺序方法组织的大量数据中,最经典的组织方法要属散列表和散列查找,当然它的英文名叫Hash(哈希),所以只学过散列的朋友,不要被别人脱口而出的哈希所忽悠了,实际上的一个东西。
哈希表原理不难,分配一个大的数据空间(比如数组),然后通过一个哈希函数,计算一个插入数据项的哈希值(无论插入的是字符串,还是各种奇怪的数据,总可以用特别的哈希函数算法一个整数值作为哈希值),然后根据算出的哈希值n为索引号,将该数据项存放到已分配的数据空间的第n个位置。
当要对一个数据项进行查找时,也是算法待查找数据的哈希值x,然后到分配的数据空间的第x位置去找该数据,找得到就返回数据,找不到就失败。
哈希表的实现和查找,本身不难,难的是如何选择和实现哈希函数,当然哈希函数的研究是属于数学家的范围了,在此也不多讨论数学问题,日常实现哈希函数的方法就是素数取模法。该方法最为简单,比如一个字符串,可以将其每个字符的ascii码值加起来,然后对一个比较大的素数(比如97)取模(%运算),则得到该字符串的哈希值。
哈希表最容易遇到的问题就是哈希值碰撞问题,即两个不同的数据,算出同样的哈希值。所以哈希函数真正的难点,是根据输入数据的特点找到一种合适的算法,使得其计算出来的哈希值,在概率上服从高斯分布,以降低哈希冲突的可能性。如果实在是遇到了冲突的哈希值,我们就可以用以下的方法来解决:
拉链法
拉链法就是在哈希表的每一个索引值对应的位置,通过链表的形式,把相同哈希值的数据项链起来。进行查找时,先算出哈希值,找到对应的项,如果之前有哈希值碰撞的情况,那么找到的应该是数据项链,那么就在该数据项链上再进行暴力查找。如果在等哈希值的数据链上找不到数据项,则返回失败。
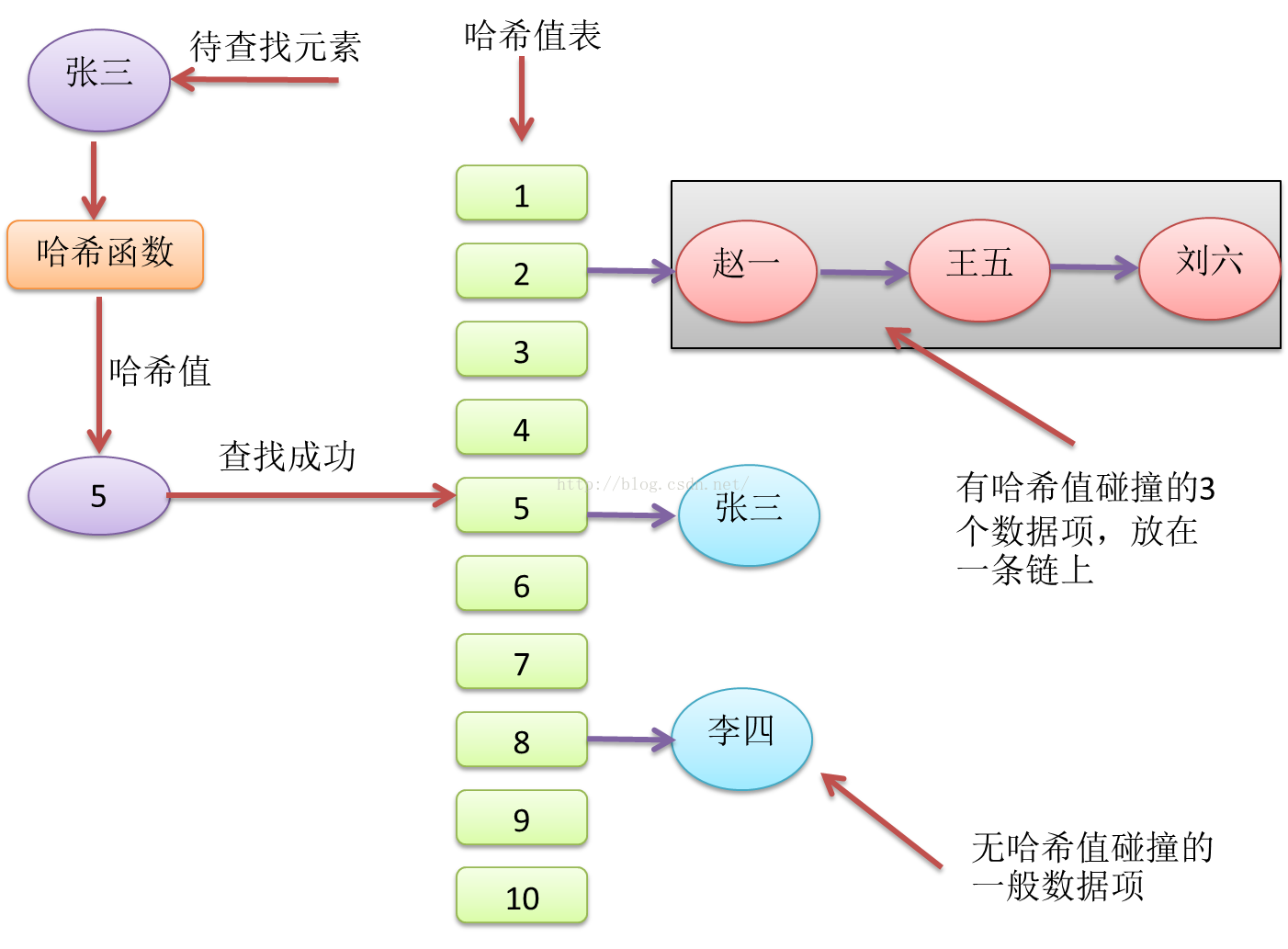
Figure17 拉链法实现的哈希表与哈希查找
拉链法是解决哈希值碰撞问题比较简单的做法,缺点就是哈希表本身会比较稀疏,浪费的空间比较多,空间利用率较低(低于50%),而且在数据链上暴力查找会降低查找效率。
线性探测法
线性探测法是在遇到哈希值碰撞时,直接查找下一个哈希值,直到找到可以存放的空位,然后存放数据。这样做,对空间利用率更高,当然,同时也会降低哈希查找的效率,插入和查找效率会被数据项插入顺序影响,原本应该属于A数据项的哈希表索引位置,可能由于插入时间较晚,已经被B提前占据了,而该位置的哈希值与B的哈希值并不相等。这就是所谓时间换空间。
线性探测法相比于拉链法,在查找失败上,遇到空位才会停止,当哈希表密度很高时,查找失败的情况下,会比拉链法消耗更多的查找时间。
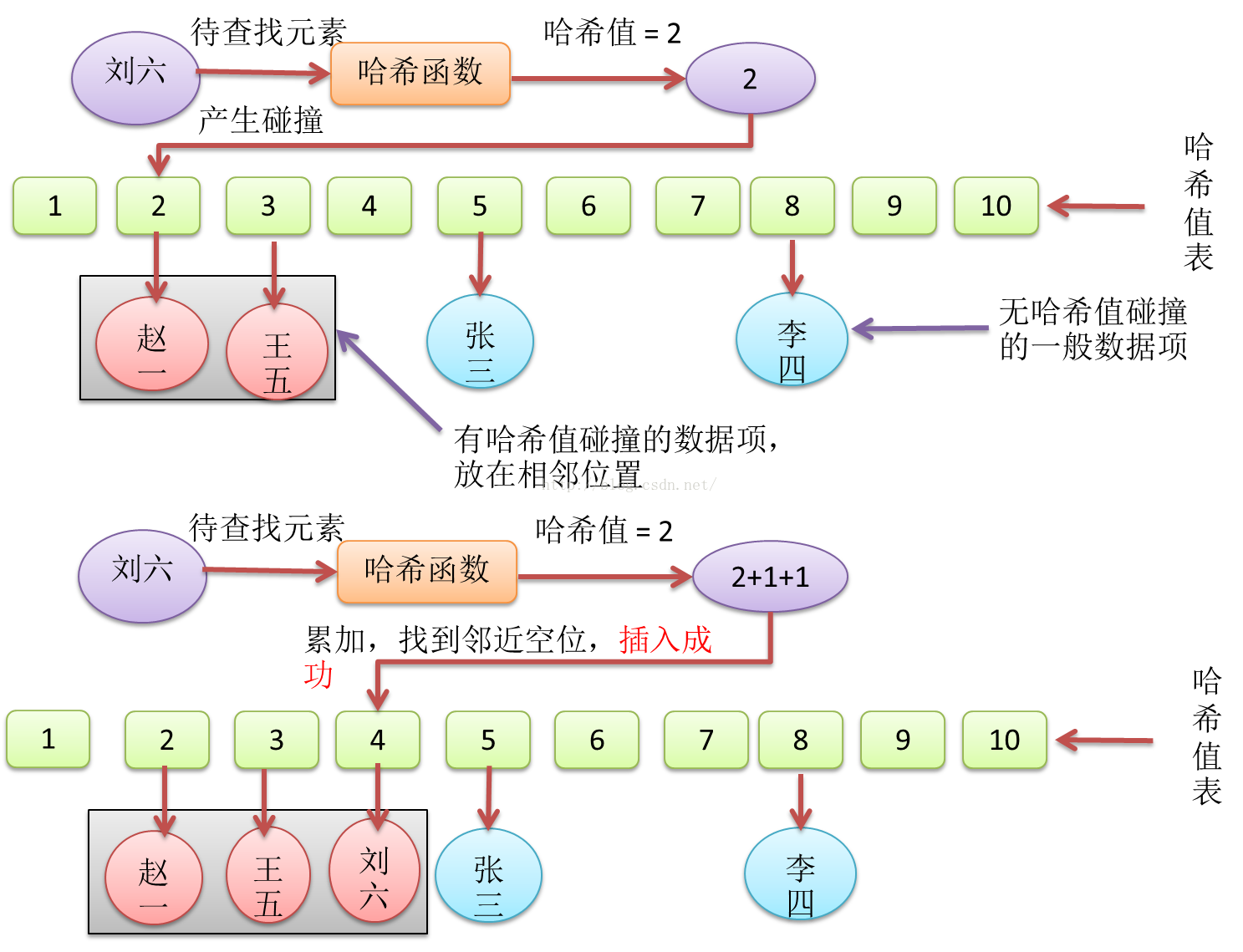
Figure18 哈希查找线性探测法,元素插入与碰撞
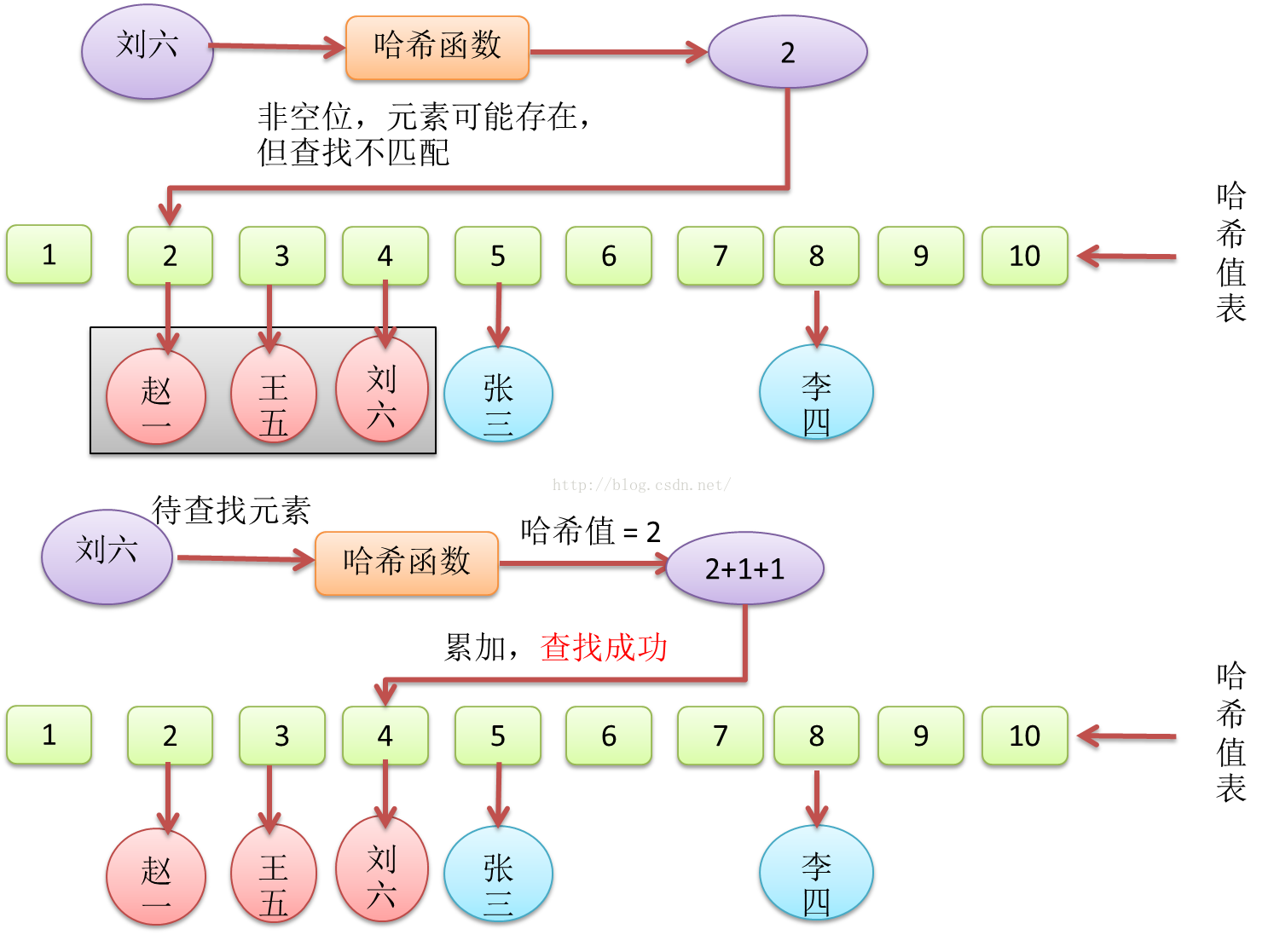
Figure19 基于线性探测法的哈希表,一次有哈希值碰撞的成功查找
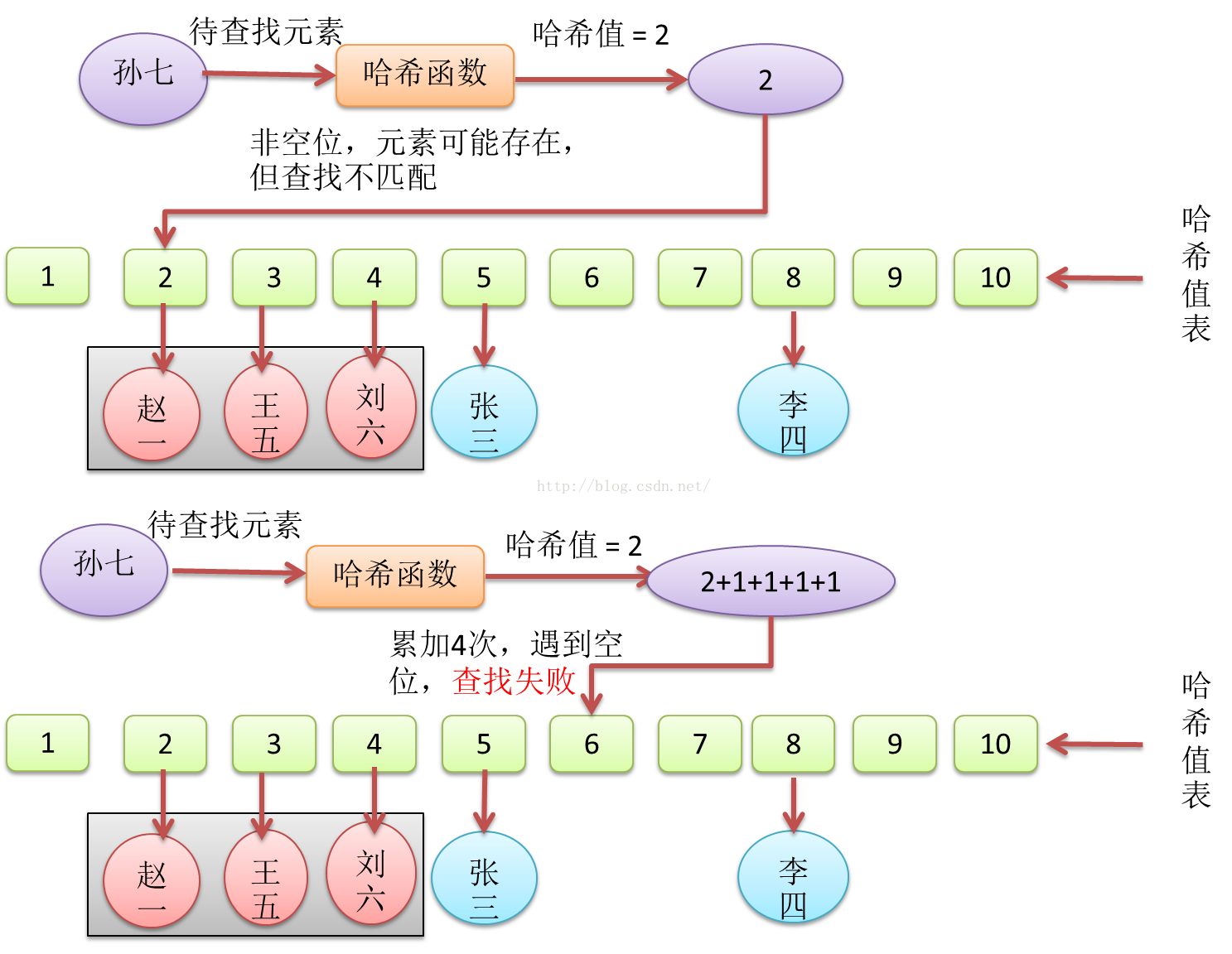
Figure20 基于线性探测法的哈希表,一次有哈希值碰撞的失败查找
散列表小结
整体来说,用散列表来组织和查找数据,效率上提高很明显,时间复杂度低于lgN,可以逼近1(理论上是1,实际上还有其它损耗)。但是缺点就是对空间有较大的消耗,所谓空间换时间,鱼和熊掌不可兼得,需要空间和时间需求达到平衡。哈希表适合于空间限制较小的场合的应用。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









