







1.1.17 Iterator迭代器模式
Iterator(迭代器)模式又称Cursor(游标)模式,它是运用于聚合对象的一种模式,通过运用该模式,使得我们可以在不知道对象内部表示的情况下,按照一定顺序(由iterator提供的方法)访问聚合对象中的各个元素。
Iterator模式的结构如下:
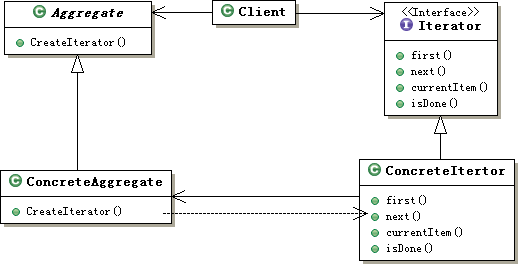
图17-1 Iterator模式类图示意
各角色功能如下:
迭代器接口Iterator:该接口必须定义实现迭代功能的最小定义方法集比如提供hasNext()和next()方法。
迭代器实现类:迭代器接口Iterator的实现类。可以根据具体情况加以实现。
容器接口:也可用抽象类,定义基本功能以及提供类似Iterator iterator()的方法。
容器实现类:容器接口的实现类。必须实现Iterator iterator()方法。
由于Iterator模式的以上特性,即与聚合对象耦合,在一定程度上限制了它的广泛运用,一般仅用于底层聚合支持类,如STL的list、vector、stack等容器类及ostream_iterator等扩展iterator。
根据STL中的分类,iterator包括:
Input Iterator:只能单步向前迭代元素,不允许修改由该类迭代器引用的元素。
Output Iterator:该类迭代器和Input Iterator极其相似,也只能单步向前迭代元素,不同的是该类迭代器对元素只有写的权力。
Forward Iterator:该类迭代器可以在一个正确的区间中进行读写操作,它拥有Input Iterator的所有特性,和Output Iterator的部分特性,以及单步向前迭代元素的能力。
Bidirectional Iterator:该类迭代器是在Forward Iterator的基础上提供了单步向后迭代元素的能力。
Random Access Iterator:该类迭代器能完成上面所有迭代器的工作,它自己独有的特性就是可以像指针那样进行算术计算,而不是仅仅只有单步向前或向后迭代。
这五类迭代器的从属关系,如下图所示,其中箭头A→B表示,A是B的强化类型,这也说明了如果一个算法要求B,那么A也可以应用于其中。
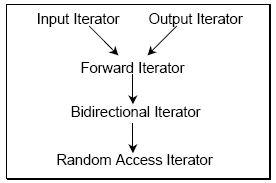
图17-2 Iterator五种迭代器之间的关系
vector和deque提供的是RandomAccessIterator,list提供的是BidirectionalIterator,set和map提供的iterators是ForwardIterator。
下面给出一个比较通用的Iterator模式的Java实现:
import java.util.ArrayList;
interface Iterator<E> { //迭代器接口
public void first();
public void next();
public E currentItem();
public boolean isDone();
}
class ConcreteIterator<E> implements Iterator<E> { //具体迭代器
private ConcreteAggregate<E> agg; //选代器功能是访问聚合对象中的元素,故要引入聚合对象
private int index = 0;
private int size = 0;
public ConcreteIterator(ConcreteAggregate<E> aggregate) { //传入聚合对象
this.agg = aggregate;
this.index = 0;
this.size = aggregate.size();
}
//下面是对聚合对象进行访问的一些方法,可见访问一般会转发给聚合对象本身来完成
@Override
public E currentItem() {
return agg.getElement(index);
}
@Override
public void first() {
index = 0;
}
@Override
public boolean isDone() {
if (index >= size) {
return true;
}
return false;
}
@Override
public void next() {
if (index < size) {
index++;
}
}
}
abstract class Aggregate<E> { //容器接口
protected abstract Iterator createIterator();
}
class ConcreteAggregate<E> extends Aggregate<E> { //具体容器
private ArrayList<E> arrayList = new ArrayList<E>();//聚合对象要维护一个对象列表
//聚合对象要一个创建选代器的方法,并把自己传入,以便选代器能对其进行访问
@Override
public Iterator createIterator() {
return new ConcreteIterator<E>(this);
}
public void add(E o) {
arrayList.add(o);
}
public E getElement(int index) {
if (index < arrayList.size()) {
return arrayList.get(index);
} else {
return null;
}
}
public int size() {
return arrayList.size();
}
}
public class IteratorClient {
public static void main(String[] args) {
ConcreteAggregate<String> aggregate = new ConcreteAggregate<String>();
aggregate.add("A");
aggregate.add("B");
aggregate.add("C");
aggregate.add("D");
aggregate.add("E");
Iterator iterator = aggregate.createIterator();
for (iterator.first(); !iterator.isDone(); iterator.next()) {
System.out.println(iterator.currentItem());
}
}
} 我们创建的集合ConcreteAggregate可以存放任何类型的数据,然后使用createIterator方法转换成Iterator对象,使用Iterator对象来按顺序显示集合中的内容。
这个模式在java的类库中已经实现了,在java中所有的集合类都实现了Conllection接口,而Conllection接口又继承了Iterable接口,该接口有一个iterator方法,也就是所以的集合类都可以通过这个iterator方法来创建Iterator,用Iterator对象中的hasNext方法来判断是否还有下个元素,next方法来顺序获取集合类中的对象。明白这个原理可以更好的理解Java中的集合类和迭代器,根据这个可以创建功能更加强大的集合类。
在C++中,可以考虑使用两种方式来实现Iterator模式:内嵌类或者友元类。通常迭代类需访问集合类中的内部数据结构,为此,可在集合类中设置迭代类为friend class,但这不利于添加新的迭代类,因为需要修改集合类,添加friend class语句。也可以在抽象迭代类中定义protected型的存取集合类内部数据的函数,这样迭代子类就可以访问集合类数据了,这种方式比较容易添加新的迭代方式,但这种方式也存在明显的缺点:这些函数只能用于特定聚合类,并且,不可避免造成代码更加复杂。
STL的list::iterator、deque::iterator、rbtree::iterator等采用的都是外部Iterator类的形式,虽然STL的集合类的iterator分散在各个集合类中,但由于各Iterator类具有相同的基类,保持了相同的对外的接口(包括一些traits及tags等),从而使得它们看起来仍然像一个整体,同时也使得应用algorithm成为可能。我们如果要扩展STL的iterator,也需要注意这一点,否则,我们扩展的iterator将可能无法应用于各algorithm。
Iterator模式有三个重要的作用:
1)它支持以不同的方式遍历一个聚合。复杂的聚合可用多种方式进行遍历,如二叉树的遍历,可以采用前序、中序或后序遍历。迭代器模式使得改变遍历算法变得很容易: 仅需用一个不同的迭代器的实例代替原先的实例即可,你也可以自己定义迭代器的子类以支持新的遍历,或者可以在遍历中增加一些逻辑,如有条件的遍历等。
2)迭代器简化了聚合的接口。有了迭代器的遍历接口,聚合本身就不再需要类似的遍历接口了,这样就简化了聚合的接口。
3)在同一个聚合上可以有多个遍历。每个迭代器保持它自己的遍历状态,因此你可以同时进行多个遍历。
4)此外,Iterator模式可以为遍历不同的聚合结构(需拥有相同的基类)提供一个统一的接口,即支持多态迭代。
简单说来,迭代器模式也是Delegate原则的一个应用,它将对集合进行遍历的功能封装成独立的Iterator,不但简化了集合的接口,也使得修改、增加遍历方式变得简单。从这一点讲,该模式与Bridge模式、Strategy模式有一定的相似性,但Iterator模式所讨论的问题与集合密切相关,造成在Iterator在实现上具有一定的特殊性。
优缺点:
正如前面所说,与集合密切相关,限制了Iterator模式的广泛使用,就个人而言,我不大认同将Iterator作为模式提出的观点,但它又确实符合模式“经常出现的特定问题的解决方案”的特质,以至于我又不得不承认它是个模式。在一般的底层集合支持类中,我们往往不愿“避轻就重”将集合设计成集合 + Iterator的形式,而是将遍历的功能直接交由集合完成,以免犯了“过度设计”的诟病。最新的Java Collection类库以及.NET Collection类库中就是这么设计的。但是,如果我们的集合类确实需要支持多种遍历方式(仅此一点仍不一定需要考虑Iterator模式,直接交由集合完成往往更方便),或者为了与系统提供或使用的其它机制,如STL算法,保持一致时,Iterator模式才值得考虑。
1.1.18 Mediator中介者模式
模式定义:用一个中介者对象来封装一系列的对象交互。中介者使各对象不需要显式的相互引用,从而使其耦合松散,而且可以独立的改变他们之间的交互。Mediator很象十字路口的红绿灯,每个车辆只需和红绿灯交互,而不是在各车辆之间进行交互。
Mediator模式的结构如下图所示:
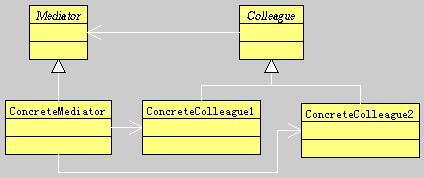
图18-1 Mediator模式类图示意
上面的类图并不能完全反映Mediator模式的全部思想,下面结合GoF的DP一书中的一个对象图对此进行深入说明:
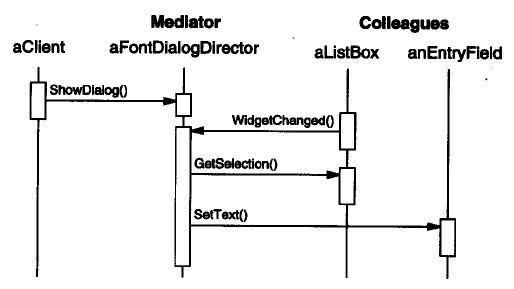
图18-2 一个典型的使用Mediator模式的对象图
在上面的类图中,各角色的分工如下:
1、Mediator(中介者):中介者定义一个接口用于与各Colleague(同事)对象通信。
2、ConcreteMediator(具体中介者):具体中介者通过协调各同事对象实现协作行为,并了解和维护它的各个同事。
3、Colleague class(同事类):每一个同事类都知道它的中介者对象,每一个同事对象在需与其他的同事通信的时候,与它的中介者通信。
Mediator模式是GoF的23种设计模式中较为容易理解的一个,我们在平时的应用中也会经常用到,但可能不会有意去抽象出一个完整的Mediator类,因为要设计一个可复用又可扩展的Mediator是很不容易的。如在MFC的文档/视图程序中,我们可能会在CWinApp派生类中添加一些供所有线程共享的数据成员或方法,这样,各线程即可通过与theApp进行交互即可达到影响其它线程的目的,在这里,CWinApp一定程度上扮演了Mediator的角色。
有人称MFC程序中Dialog在各控件间扮演着Mediator的角色,认为各控件实现时无需知道其它控件,只是将消息发送给父窗口Dialog来处理,而Dialog负责在消息处理函数中完成各控件之间的信息交互,使得控件间复杂的耦合关系变成简单的控件-Mediator(Dialog)关系。我并非十分赞同这种观点,因为我们往往将控件作为整个Dialog的一个组成部分来看待,而有意无意地忽略了它本身也是一个独立对象的事实,造成这种现象的一个关键原因可能在于MFC的消息映射机制屏蔽了控件将消息发送给对话框的过程,使得我们更愿意去认为消息是Dialog(处理)的消息,而不是(来自)控件的消息。
在Java应用中,以上状况依然存在,但是由于没有了直接的消息映射支持,JDialog往往更容易表现得像一个Mediator。
此外,还有一个观点认为,Java的Container通过选择一定的LayoutManager策略(Strategy),在各控件间起到了Mediator的作用,当新的Component被加到Container,如JPanel中时,必然会对其它控件的Layout(布局)造成影响,但各控件间是不知道对方的,他们只需知道自己的Parent Window,然后与之交互即可。这种观点也有欠妥当,但从Mediator作为各object之间的交互的媒介这一实质来看,也无可厚非。
简而言之,Mediator模式的主要作用在于为多个对象之间的交互提供一种媒介,以简化对象之间的耦合关系。
下面给出一个Mediator的Java实现:
import java.util.ArrayList;
abstract class AbstractMediator {
//注册同事
public abstract void register(AbstractColleague ac);
//协调各同事对象实现协作行为
public abstract void ColleagueChanged(AbstractColleague ac);
}
abstract class AbstractColleague {
private AbstractMediator med; //每个同事都知道中介者,故要引入中介者
public AbstractColleague(AbstractMediator mediator) { //通过构造函数传入
this.med = mediator;
}
public abstract void action(); //对象的操作行为
public void changed() { //把交互行为发送给中介者
med.ColleagueChanged(this);
}
}
class ConcreteMediator extends AbstractMediator {
//中介者要维护一个同事列表
private ArrayList<AbstractColleague> colleagueList = new ArrayList<>();
@Override
public void register(AbstractColleague ac) {
colleagueList.add(ac);
}
@Override
public void ColleagueChanged(AbstractColleague ac) {
for (int i = 0; i < colleagueList.size(); i++) {
if (colleagueList.get(i) == ac) {
colleagueList.get(i).action();
}
}
}
}
class ConcreteColleagueA extends AbstractColleague {
public ConcreteColleagueA(AbstractMediator mediator) { //同事要知道中介者
super(mediator);
mediator.register(this); //把自己注册给中介者
}
@Override
public void action() { //对象的操作行为,由中介者来调用
System.out.println("AAAAAAAAAAAAAAA");
}
}
class ConcreteColleagueC extends AbstractColleague {
public ConcreteColleagueC(AbstractMediator mediator) {
super(mediator);
mediator.register(this);
}
@Override
public void action() {
System.out.println("CCCCCCCCCCCCCCC");
}
}
class ConcreteColleagueB extends AbstractColleague {
public ConcreteColleagueB(AbstractMediator mediator) {
super(mediator);
mediator.register(this);
}
@Override
public void action() {
System.out.println("BBBBBBBBBBBBBBB");
}
}
class MediatorTest {
public static void main(String[] args) {
AbstractMediator mediator = new ConcreteMediator();
AbstractColleague colleagueA = new ConcreteColleagueA(mediator);
AbstractColleague colleagueB = new ConcreteColleagueB(mediator);
AbstractColleague colleagueC = new ConcreteColleagueC(mediator);
colleagueA.changed();
colleagueB.changed();
colleagueC.changed();
}
}Mediator与Observer的比较:
两者发出点根本不同,Mediator是为各对象的操作提供中间代理,Observer是为使操作的结果能够同步。前者侧重操作的进行,后者侧重操作的结果。在实现上,Observer模式中的各个观察者并不主动注册给被观察者,而是由被观察者自己添加,被观察者也可以删除观察者。被观察者的状态改变时,调用各观察者的update(this)方法,把自己传过去,各观察者在update方法中根据传来的状态变化改变自己的状态,这里各观察者本身并不保存被观察者的引用。
Mediator与Proxy的比较:
Proxy模式是简化的Mediator模式?个人认为从功能上讲,Mediator模式与Proxy模式存在一定的相似性,但Proxy主要在于控制对被访问对象的访问,这种访问往往是单向的,而Mediator模式则在于为系统内不同的对象之间的访问提供一种媒介,这种访问往往是多向的。
Mediator与Facade的比较:
很多设计模式的书中都会将Mediator模式与Facade模式进行比较,个人认为二者的区别十分明显:一个是为整个子系统对外提供一个简单化的接口,子系统的内部可能十分复杂,很多类交互作用才形成了最终的简单化的统一接口;而Mediator模式则作为系统内多个对象交互的“媒介”,负责封装对象间的交互,所有对象只需要与Mediator类交互,而不是相互之间直线联系。所以, 也许在实现Facade模式时在子系统的内部采用Mediator模式可能是个不错的选择。
在Observer模式中从Observerable/Observer的角度分析了聊天程序的原理。从Mediator角度看,聊天程序也是Mediator的典型应用,任何人想要发送消息给其他人,只需将消息发送给ChatRoom对象,由ChatRoom负责数据的转发,而不是直接与消息的接收者交互。从Mediator的角度来开发ChatRoom更准确,因为各聊天者都要主动注册给ChatRoom服务器。例如QQ,我要在ChatRoom服务器上注册一个账号,这个账号就标识了我这个对象。服务器必须知道每个客户标识,才能转发消息。
上面例子对象间的交互代码并没有写,只是把对象的空的action()操作代理给了Mediator。以下是一个多线程Producer-Comsumer的例子,在该示例中,由于无法在多个Producer、Cosumer之间建立直接的联系,因此,通过Mediator类来完成这种信息交互,当Producer要Produce时,只需与Mediator进行交互,以查询是否有空的Slot可供存放Product,而Comsumer要Comsume时,也只需与Mediator进行交互,以查询是否有Product可供Comsume。
以下是该示例的Java实现:
import java.util.*;
class Product {
int id; //产品ID
Product(int id) {
this.id = id;
}
}
class Mediator {
private boolean stopFlag = false;
private Stack slot = new Stack(); //维护一个产品列表,以后进先出方式访问
private int slotCount;
public Mediator(int slotCount) {
this.slotCount = slotCount;
}
public boolean stop() { //是否还可以存放产品
return stopFlag;
}
public void stop(boolean flag) {
stopFlag = true;
}
public boolean put(Product product) { //产品的存与取操作者通过中介者来完成
// or synchronized on Mediator.class, but on slot is better and reasonable
synchronized (slot) {
if (slot.size() >= slotCount) {
return false;
}
slot.push(product);
}
return true;
}
public Product get() {
synchronized (slot) {
if (slot.empty()) {
return null;
}
Product product = (Product) slot.pop();
return product;
}
}
}
class Producer extends Thread {
private Mediator med;
private int id;
private static int num = 1;
public Producer(Mediator m) {
med = m;
id = num++;
}
@Override
public void run() {
Product product;
while (!med.stop()) {
product = new Product((int) (Math.random() * 100)); //生产一个产品
synchronized (System.out) {
System.out.println("Producer[" + id + "] produces Product["
+ product.id + "]");
}
//主动存入中介者的仓库中
// if put failed, try to put again and again.
while (!med.stop() && !med.put(product)) {
try {
sleep(100);
} catch (InterruptedException ie) {
}
}
try {
sleep(100);
} catch (InterruptedException ie) {
}
}
}
}
class Consumer extends Thread {
private Mediator med;
private int id;
private static int num = 1;
public Consumer(Mediator m) {
med = m;
id = num++;
}
public void run() {
Product product;
while (!med.stop()) {
product = med.get(); //取一个产品进行消费
if (product != null) {
synchronized (System.out) {
System.out.println("Consumer[" + id + "] is consuming Product["
+ product.id + "]");
}
}
try {
sleep(100);
} catch (InterruptedException ie) {
}
}
}
}
class MediatorDemo {
public static void main(String[] args) {
Mediator med = new Mediator(2);
Thread thread[] = {new Producer(med), new Producer(med),
new Consumer(med), new Consumer(med), new Consumer(med)};
for (Thread curThread1 : thread) {
curThread1.start();
}
// before stop all threads, sleep 1 second
try {
Thread.sleep(1000);
} catch (InterruptedException ie) {
}
med.stop(true);
// Wait for all threads to return
try {
for (Thread curThread2 : thread) {
curThread2.join();
}
} catch (InterruptedException ie) {
}
}
}在下列情况下使用中介者模式:
1、一组对象以定义良好但是复杂的方式进行通信。产生的相互依赖关系结构混乱且难以理解。
2、一个对象引用其他很多对象并且直接与这些对象通信,导致难以复用该对象。
3、想定制一个分布在多个类中的行为,而又不想生成太多的子类。
Mediator模式有以下优点和缺点:
1、减少了子类生成。Mediator将原本分布于多个对象间的行为集中在一起,改变这些行为只需生成Mediator的子类即可,这样各个Colleague类可被重用。
2、它将各Colleague解耦。Mediator有利于各Colleague间的松耦合,你可以独立的改变和复用各Colleague类和Mediator类。
3、它简化了对象协议。用Mediator和各Colleague间的一对多的交互来代替多对多的交互。一对多的关系更易于理解、维护和扩展。
4、它对对象如何协作进行了抽象。将中介作为一个独立的概念并将其封装在一个对象中,使你将注意力从对象各自本身的行为转移到它们之间的交互上来。这有助于弄清楚一个系统中的对象是如何交互的。
5、它使控制集中化。中介者模式将交互的复杂性变为中介者的复杂性。因为中介者封装了协议,它可能变得比任一个Colleague都复杂。这可能使得中介者自身成为一个难于维护的庞然大物。
1.1.19 Memento备忘录模式
模式定义:在不破坏封装的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态。这样就可以将该对象恢复到原先保存前的状态。
在程序运行过程中,某些对象的状态处在转换过程中,可能由于某种原因需要保存此时对象的状态,以便程序运行到某个特定阶段,需要恢复到对象之前处于某个点时的状态。如果使用一些公有接口让其它对象来得到对象的状态,便会暴露对象的实现细节。 Memento模式的类图结构如下图所示:
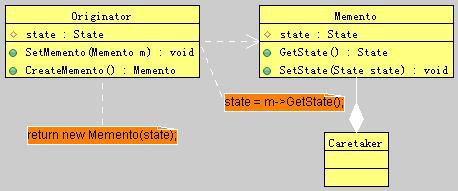
图19-1 Memento模式类图示意
Memento模式所涉及的角色有三个,备忘录角色、发起人角色和负责人角色。其中:
Memento(备忘录):负责存储原发器对象的内部状态,并可防止原发器以外的其他对象访问备忘录。
Originator(原发器):负责创建一个备忘录,用以记录当前时刻它的内部状态,并可使用备忘录恢复内部状态。原发器可根据需要决定备忘录存储原发器的哪些内部状态,因此,当需要保存全部信息时,可以考虑用clone的方式来实现Memento的状态保存方法,但是如果是这样的话,我们有时候可能会考虑不使用Memento,而是直接保存Originator本身,但这样使得我们相当于对上层应用开放了Originator的全部(public)接口,这对于保存备份有时候是不必要的。
Caretaker(负责人):负责保存好备忘录,并且往往不能对备忘录的内容进行操作或检查。
备忘录实际上有两个接口,Caretaker只能看到备忘录的窄接口,即它只能将备忘录传递给其他对象。而原发器能够看到一个宽接口,允许它访问返回到先前状态所需的所有数据。理想的情况是只允许生成本备忘录的那个原发器访问本备忘录的内部状态。
举一个实际的例子,以Windows系统备份为例:备份(Memento)是备忘录角色、Windows系统(WindowsSystem)类是发起人角色、用户(User)类是负责人角色。用户不关心备份的内部细节,而且也无法直接对备份的内容进行直接修改,但Windows系统则可以(在用户指定的情况下)决定备份什么内容,以及如何还原备份。下面的模拟这个过程的代码:
class Memento { //备忘录
private String state;
public Memento(String state) {
this.state = state;
}
public String getState() { //返回备忘录中存储的状态
return state;
}
public void setState(String state) {
this.state = state;
}
}
class WindowsSystem { //原发器
private String state;
public Memento createMemento() { //创建备忘录
return new Memento(state); //备忘录要保存当前系统的状态
}
public void restoreMemento(Memento m) { //用备忘录来恢复系统
this.state = m.getState(); //原发器使用了备忘录的宽接口
}
public String getState() {
return state;
}
public void setState(String state) {
this.state = state;
System.out.println("当前系统处于" + this.state);
}
}
class User { //负责人:备忘录管理者
private Memento memento; //要管理一个备忘录
public Memento retrieveMemento() { //取回备忘录
return this.memento;
}
public void saveMemento(Memento memento) { //保存备忘录
this.memento = memento;
}
}
public class MementoTest {
public static void main(String[] args) {
WindowsSystem Winxp = new WindowsSystem(); //Winxp系统
User user = new User(); //某一用户
Winxp.setState("好的状态"); //Winxp处于好的运行状态
user.saveMemento(Winxp.createMemento()); //用户对系统进行备份,Winxp系统要产生备份文件
Winxp.setState("坏的状态"); //Winxp处于不好的运行状态
Winxp.restoreMemento(user.retrieveMemento()); //用户找回备忘录,系统进行恢复
System.out.println("当前系统处于" + Winxp.getState());
}
}正如结构部分所说,我们有时候也可能会考虑直接保存Originator本身,而不是另外抽象出一个Memento类,就好像在Command模式中举的AdjustUndoableEdit的例子一样,保存的是实际的ModelObject的clone,而不是另外写一个Memento类来。
因此,Memento模式往往被我们忽略,但Memento模式的主要作用在于职责的分离,同时隐藏Originator的实现细节,并在有些情况下起到简化Originator的作用。
因为Memento模式具有的优点在很多情况下并不为我们所关系,同时,还会由此引入更复杂的类结构及可能引入更大的管理开销,因此,是否需要引入Memento模式及何时引入Memento模式是一个需要认真考虑的问题,个人认为,Memento模式比较适用于功能比较复杂的,但需要维护或记录属性历史的类,对于这样的类,对Caretaker公开Originator的接口显得有点多余,或者需要保存的属性只是众多属性中的一小部分时(或者根本就不是Originator的属性,但是由Originator引起,并且Originator可以根据保存的Memento信息还原到前一状态,如GoF的DP一书中提到的增量约束解释工具QOCA),为了节约存储空间,也可以考虑使用Memento模式,这种情况下,clone就太奢侈,也太不负责任了。
以下情况下可考虑使用Memento模式:
1、必须保存一个对象在某一个时刻的(部分)状态,这样以后需要时它才能恢复到先前的状态;
2、如果一个用接口来让其它对象直接得到这些状态,将会暴露对象的实现细节并破坏对象的封装性。
Memento模式有以下这些优缺点:
1、保持封装边界。使用备忘录可以避免暴露一些只应由原发器管理却又必须存储在原发器之外的信息。该模式把可能很复杂的Originator内部信息对其他对象屏蔽起来,从而保持了封装边界。
2、它简化了原发器。在其他的保持封装性的设计中,Originator负责保持客户请求过的内部状态版本。这就把所有存储管理的重任交给了Originator。让客户管理它们请求的状态将会简化Originator,并且使得客户工作结束时无需通知原发器。
3、使用备忘录可能代价很高。如果原发器在生成备忘录时必须拷贝并存储大量的信息,或者客户非常频繁地创建备忘录和恢复原发器状态,可能会导致非常大的开销。除非封装和恢复Originator状态的开销不大,否则该模式可能并不合适。
4、维护备忘录的潜在代价。管理器负责删除它所维护的备忘录。然而,管理器不知道备忘录中有多少个状态。因此当存储备忘录时,一个本来很小的管理器,可能会产生大量的存储开销。
1.1.20 State模式
State模式定义:允许一个对象在其状态改变时,改变它的行为。看起来对象似乎修改了它的类。
一个对象可能处在这样或者那样的状态,并且在不同的状态下会表现出不同的行为,这是很平常的事情。State模式主要解决的就是在开发中时常遇到的根据不同的状态需要进行不同的处理操作的问题,而这样的问题大部分人是采用switch-case语句进行处理的,这样会造成一个问题:分支过多。而且如果加入一个新的状态就需要对原来的代码进行编译。例如,我们制作一个定点报时程序,当时间是0:00-12:00时,问候语是:“Good Morning! 现在是...AM.”;当时间是12:00-18:00时,问候语是:“Good Afternoon! 现在是...PM.”,其它时段,问候语是:“Good Evening! 现在是...PM.”,这要遇到很多的分支。State(状态)模式则把一个对象的这些内部状态从对象中分离出来,形成单独的状态对象,所有与该状态相关的行为都放入该状态对象中。当状态改变的时候进行处理,然后再切换到另一种状态,也就是说把状态的切换责任交给了具体的状态类去负责。
State模式和Strategy模式有很多相似的地方。需要说明的是两者的思想都是一致的,只不过封装的东西不同:State模式封装的是不同的状态,而Stategy模式封装的是不同的算法。
State模式结构图如下:
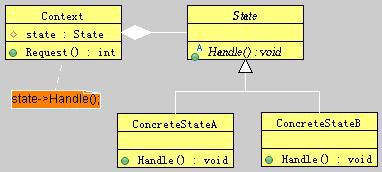
图20-1 State模式类图
上述类图中包括如下角色:
Context(环境):负责定义客户感兴趣的接口,并维护一个ConcreteState的实例,以及维护状态转换或为这种转换提供支持(因为状态转换有时候可能是由上层应用发起的)。
State(状态):定义一个接口以封装与Context的一个特定状态相关的行为。
ConcreteState(具体状态):每一子类实现一个与Context的一个状态相关的行为。
我们现在用State的观点来考虑上面时钟的问题,假定报时由Alarm类完成,Alarm对象在不同的时段处于不同的状态(Morning/Afternoon/Evening),为此,我们添加一个State基类,它的子类负责实现相应的报时动作。以上解决方案使得我们在整个系统运行的过程中,只需要维护状态的变化,而不是像前面采用if...else语句一样将所有的状态下的需要执行的行为混杂在一起,单纯依靠属性判断来决定执行何种动作。
State模式是OOD中用于替代if...else/switch的一种方式(当然不仅限于此,应用部分对此有进一步讨论),State模式的应用使得对象被划分成对象 + 状态对象两部分,一定程度上体现了Delegate的设计原则。
在此需要注意的是,这里的State(状态)并非仅仅指对象当前所具有的属性,还包括对对象在拥有当前属性时行为的封装,这从类设计的角度讲是很自然的,因为类除了应该包括一定的属性信息,还应该包含操作这些属性的方法,及这些属性对应的行为。
下面是一个实现的例子:
class Context { //环境
private State _state; //维护一个当前的状态实例
public Context(State state) {
_state = state;
}
public void request() { //状态执行请求操作,由客户调用
if (_state != null) {
_state.handle(this);
}
}
public void changeState(State s) { //切换到下一状态
if (_state != null) {
_state = null;
}
_state = s;
}
}
interface State { //状态接口
public void handle(Context ctx);
}
class ConcreteStateA implements State { //具体状态类
@Override
public void handle(Context ctx) { //完成本状态的行为,然后切换到下一状态
System.out.println("handle by ConcreteStateA");
if (ctx != null) { //切换到下一状态:切换工作转发给上下文Context来完成
ctx.changeState(new ConcreteStateB());
}
}
}
class ConcreteStateB implements State {
@Override
public void handle(Context ctx) {
System.out.println("handle by ConcreteStateB");
if (ctx != null) {
ctx.changeState(new ConcreteStateA());
}
}
}
public class StateClient {
public static void main(String[] args) {
State state = new ConcreteStateA();
Context context = new Context(state);
context.request(); //内部会把状态转发给具体状态类,它完成状态的行为后,
//又会返回到Context,以进行状态切换
context.request();
context.request();
context.request();
}
}思想:Context维护一个当前状态,完成状态执行请求和状态切换,具体状态类完成状态行为,然后把状态切换转发给Context来完成,以便切换到下一状态。
在C++中,运用State模式时存在一些细节问题需要进一步深入考虑,如:State类可能需要操作Context类的某些保护/私有成员以完成相应动作的执行,那么State类应该设置成Context类的friend类?或者内嵌类?或者其他形式?这里考虑到State扩展的需要,一般不会将State类设置成Context类的友元类(由于友元特性无法继承,主要是将State类的各子类设置成Context类的友元类),因为,不但所有State类都必须设置成Context的友元类,当需求发生变更,State发生增减时,都需要维护友元类信息。鉴于此,内嵌类是个不错的选择,但也并非唯一选择。
此外,State类是否需要维护一个Context类的指针等问题,也需要在具体实现时根据需要来确定。
State模式适用于解决以下的问题:
1、一个对象的行为取决于它的状态,并且它必须在运行时刻根据状态改变它的行为。
2、一个操作中含有庞大的多分支的条件语句,且这些分支依赖于该对象的状态。这个状态通常用一个或多个枚举常量表示。通常, 有多个操作包含这一相同的条件结构。State模式将每一个条件分支放入一个独立的类中。这使得你可以根据对象自身的情况将对象的状态作为一个对象,这一对象可以不依赖于其他对象而独立变化。
State模式具有以下优点:
避免了为判断状态而产生的巨大的if或case语句。
将对象行为交给状态类维护后,对于上层程序而言,仅需要维护状态之间的转换规则。
并且,当状态信息发生增减时,维护成本比较低,仅需根据增减情况调整State子类的数目,并对状态转换逻辑进行简单调整,而不是陷入维护众多if...else逻辑判断的危险境地。














 1436
1436











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









