







spark-streaming支持kafka消费,有以下方式:
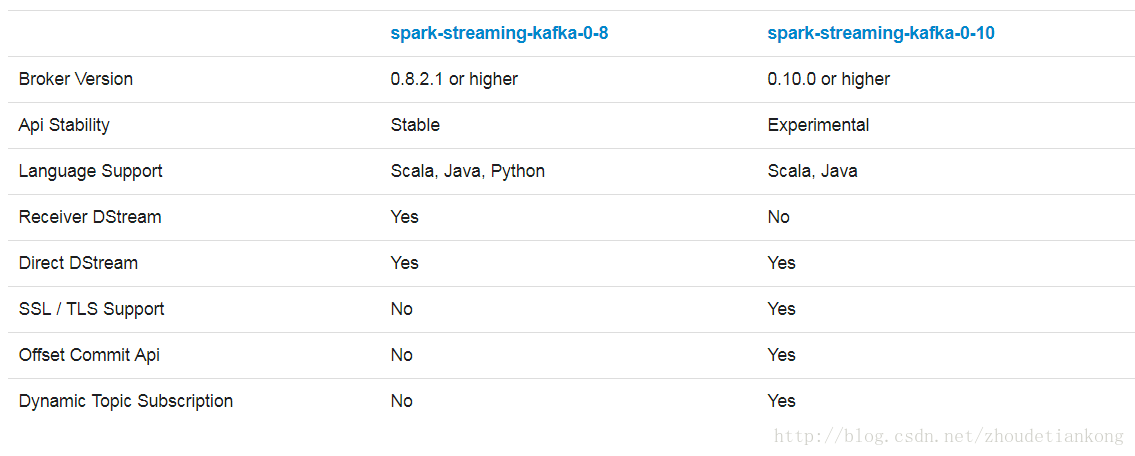
我实验的版本是kafka0.10,试验的是spark-streaming-kafka-0.8的接入方式。另外,spark-streaming-kafka-0.10的分支并没有研究。
spark-streaming-kafka-0.8的方式支持kafka0.8.2.1以及更高的版本。有两种方式:
(1)Receiver Based Approach:基于kafka high-level consumer api,有一个Receiver负责接收数据到执行器
(2)Direct Approcah:基于kafka simple consumer api,没有receiver。
mavne项目需要添加依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-8_2.11</artifactId>
<version>2.1.0</version>
</dependency>Reviced based approach代码:使用方法见注释
package com.lgh.sparkstreaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Minutes, Seconds, StreamingContext}
import org.apache.spark.streaming.kafka.KafkaUtils
/**
* Created by Administrator on 2017/8/23.
*/
object KafkaWordCount {
def main(args: Array[String]): Unit = {
if (args.length < 4) {
System.err.println("Usage: KafkaWordCount <zkQuorum> <group> <topics> <numThreads>")
System.exit(1)
}
//参数分别为 zk地址,消费者group名,topic名 多个的话,分隔 ,线程数
val Array(zkQuorum, group, topics, numThreads) = args
//setmaster,local是调试模式使用
val sparkConf = new SparkConf().setAppName("KafkaWordCount").setMaster("local[2]")
val ssc = new StreamingContext(sparkConf, Seconds(2))
ssc.checkpoint("checkpoint")
//Map类型存储的是 key: topic名字 values: 读取该topic的消费者的分区数
val topicMap = topics.split(",").map((_, numThreads.toInt)).toMap
//参数分别为StreamingContext,kafka的zk地址,消费者group,Map类型
val kafkamessage = KafkaUtils.createStream(ssc, zkQuorum, group, topicMap)
//_._2取出kafka的实际消息流
val lines=kafkamessage.map(_._2)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1L))
.reduceByKeyAndWindow(_ + _, _ - _, Minutes(10), Seconds(2), 2)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}
Direct approach:
package com.lgh.sparkstreaming
import kafka.serializer.StringDecoder
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.kafka.KafkaUtils
/**
* Created by Administrator on 2017/8/23.
*/
object DirectKafkaWordCount {
def main(args: Array[String]) {
if (args.length < 2) {
System.err.println(s"""
|Usage: DirectKafkaWordCount <brokers> <topics>
| <brokers> is a list of one or more Kafka brokers
| <topics> is a list of one or more kafka topics to consume from
|
""".stripMargin)
System.exit(1)
}
//borkers : kafka的broker 列表,多个的话以逗号分隔
//topics: kafka topic,多个的话以逗号分隔
val Array(brokers, topics) = args
// Create context with 2 second batch interval
val sparkConf = new SparkConf().setAppName("DirectKafkaWordCount").setMaster("local[2]")
val ssc = new StreamingContext(sparkConf, Seconds(2))
// Create direct kafka stream with brokers and topics
val topicsSet = topics.split(",").toSet
val kafkaParams = Map[String, String]("metadata.broker.list" -> brokers)
val messages = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](
ssc, kafkaParams, topicsSet)
// Get the lines, split them into words, count the words and print
val lines = messages.map(_._2)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1L)).reduceByKey(_ + _)
wordCounts.print()
// Start the computation
ssc.start()
ssc.awaitTermination()
}
}
关于这两种方式的区别
1.Simplified Parallelism
Direct 方式将会创建跟kafka分区一样多的RDD partiions,并行的读取kafka topic的partition数据。kafka和RDD partition将会有一对一的对应关系。
2.Efficiency
Receiver-based Approach需要启用WAL才能保证消费不丢失数据
,效率比较低
3.Exactly-once semantics
Receiver-based Approach使用kafka high-level consumer api,存储消费者offset在zookeeper中,跟Write Ahead Log配合使用,能够实现至少消费一次语义。
Direct Approach 使用kafka simple consumer api,跟踪offset信息存储在spark checkpoint中。能够实现数据有且只消费一次语义。















 5255
5255

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









