






| 1.下面简单介绍一下执行计划结果的读法 |
| ①Explaining → Widths |
| =# EXPLAIN SELECT oid FROM pg_proc; QUERY PLAN ------------------------------------------ Seq Scan on pg_proc (cost=0.00..87.47 rows=1747 width=4) |
| 查询结果的所有字段的总宽度。这个参数并不是关键指标。每个字段的宽度定义如下: text [ n 文字]:n + 4 varchar(n):n+1 char(n):n+1 boolean: 1 bigint :8 integer: 4 |
| ②Explaining → Rows |
| 预测的行数。与实际的行数可能有出入,经常vacuum或者analyze的话,这个值和实际值将更加接近。 |
| ③Explaining → Cost |
| cost是比较重要的指标。例子中的cost=0.00..87.47有两个部分,启动时间(startup)=0.00 和总时间(total)=87.47。单位是毫秒。这个指标也只是预测值。 |
| 启动时间也有解释为找到符合条件的第一行所花的时间。 |
| ④Explaining → Explain Analyze |
| 想知道实际的执行时候的执行计划的话,用这个命令。 =# EXPLAIN ANALYZE SELECT oid FROM pg_proc; QUERY PLAN ------------------------------------------ Seq Scan on pg_proc (cost=0.00..87.47 rows=1747 width=4) (actual time=0.077..17.082 rows=1747 loops=1) Total runtime: 20.125 ms |
| loops:循环的次数。 |
| Total runtime:总的时间 |
| ⑤Explaining → 执行计划运算类型 |
| Seq Scan:扫描表。无启动时间。 |
| Index Scan:索引扫描。无启动时间。 |
| Bitmap Index Scan:索引扫描。有启动时间。 |
| Bitmap Heap Scan:索引扫描。有启动时间。 |
| Subquery Scan:子查询。无启动时间。 |
| Tid Scan:ctid = …条件。无启动时间。 |
| Function Scan:函数扫描。无启动时间。 |
| Nested Loop:循环结合。无启动时间。 |
| Merge Join:合并结合。有启动时间。 |
| Hash Join:哈希结合。有启动时间。 |
| Sort:排序,ORDER BY操作。有启动时间。 |
| Hash:哈希运算。有启动时间。 |
| Result:函数扫描,和具体的表无关。无启动时间。 |
| Unique:DISTINCT,UNION操作。有启动时间。 |
| Limit:LIMIT,OFFSET操作。有启动时间。 |
| Aggregate:count, sum,avg, stddev集约函数。有启动时间。 |
| Group:GROUP BY分组操作。有启动时间。 |
| Append:UNION操作。无启动时间。 |
| Materialize:子查询。有启动时间。 |
| SetOp:INTERCECT,EXCEPT。有启动时间。
|
| 下面是一个hash,hash join例子: =# EXPLAIN SELECT relname, nspname FROM pg_class JOIN pg_namespace ON (pg_class.relnamespace=pg_namespace.oid); QUERY PLAN ------------------------------------------------------------------------ Hash Join (cost=1.06..10.71 rows=186 width=128) Hash Cond: ("outer".relnamespace = "inner".oid) -> Seq Scan on pg_class (cost=0.00..6.86 rows=186 width=68) -> Hash (cost=1.05..1.05 rows=5 width=68) -> Seq Scan on pg_namespace (cost=0.00..1.05 rows=5 width=68) 两个表间 INNER JOIN和LEFT OUTER JOIN 连 接的 时 候, 这 个运算 是 很常用的。 这 个运算是先把外表中关 联条件部分做一个哈希表,然后去和内部表关联。 |
| 下面是一个Nested Loop例子: =# SELECT * FROM pg_foo JOIN pg_namespace ON (pg_foo.pronamespace=pg_namespace.oid); QUERY PLAN ---------------------------------------------------------------------- Nested Loop (cost=1.05..39920.17 rows=5867 width=68) Join Filter: ("outer".pronamespace = "inner".oid) -> Seq Scan on pg_foo (cost=0.00..13520.54 rows=234654 width=68) -> Materialize (cost=1.05..1.10 rows=5 width=4) -> Seq Scan on pg_namespace (cost=0.00..1.05 rows=5 width=4) 两个表间 INNER JOIN和LEFT OUTER JOIN 连接的时候,这个运算是很常用的。这个运算是扫描外表,然后去内部找所符合条件的记录。 |
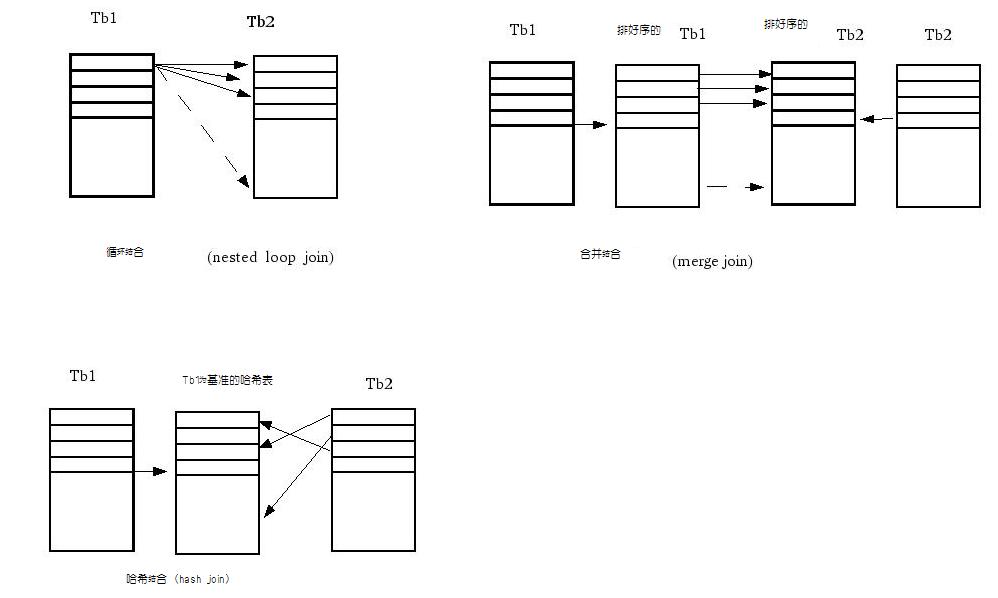
| 下面是对表关联的3种结合运算的概念图。 |
| 哈希运算要做一张哈希表,如果外部的tb1的数据不是特别多的时候是比较快的。如果tb1相当大,这时候做一张可能话时候反而更多。 因为做的哈希表内存装不下,需要输出到硬盘,这样IO读取多了,速度就低下了。 合并查询对外部和内部表都要用两个表的关联字段各自做一张,并且还要排序。如果是已经拍好序的,速度是很快。这中运算有数据特大的时候 还有可能不如循环结合快。 因此我们有个别地方可能直接用系统默认的执行计划的话反而很慢。如果是那样的话,可以尝试强制改变执行计划。禁止使用hash结合或合并结合。 这个要具体问题具体分析。 |
|
2. 强制改 变执行计划 |
| 有时候我们不想用系统默认的执行计划。这时候就需要自己 强制控制 执行计划。 |
| 禁止某种运算的SQL语法: SET enable_运算 类型 = off; //或者=false |
| 开启某种运算的SQL语 法:SET enable_运算 = on; //或者=true |
| 执行 计 划可以改 变 的运算方法如下: – enable_bitmapscan – enable_hashagg – enable_hashjoin – enable_indexscan – enable_mergejoin – enable_nestloop – enable_seqscan – enable_sort – enable_tidscan |
| 如果我们只想改变当前要执行的 SQL的 执行计划,而不想影响其他的 SQL的 话。在设置 SQL里面加一个关 键字 session即可。 |
| 例子: set session enable_hashjoin=false //禁止使用哈希结合算法 |
| 通过 查看 执行计划,我们就能够找到SQL中的哪部分比较慢,或者说花费时间多。然后重点分析哪部分的逻辑,比如减少循环 查 询,或者 强制改 变执行计划。 |
PostgreSQL SQL的性能调试方法 查看执行计划
最新推荐文章于 2024-03-20 16:26:43 发布















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









