







1.RBM结构
RBM包括隐层、可见层和偏置层。与前馈神经网络不一样,RBM在可见层和隐层间的链接方向不定的(值可以双向传播,隐层—>可见层和可见层—>隐层)和完全链接的。
Boltzmann分布:描述理想气体在受保守外力作用、或保守外力场的作用不可忽略时,处于热平衡态下的气体分子按能量的分布规律,它能够代表平衡系统中的一切分布。
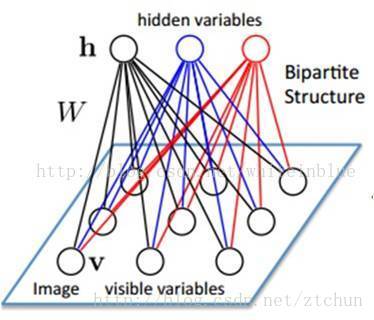
如上二部图所示,每一层的节点之间没有链接,一层是可见层,及输入层(v),一层是隐藏层(h),如果假设所有节点都是随机二进制变量节点(只能取0或1值),同时假设全概率分布p(v,h)满足Boltzmann分布,这个模型就叫RBM。
数学知识:
全概率公式:
贝叶斯公式:
全概率公式结合贝叶斯公式:
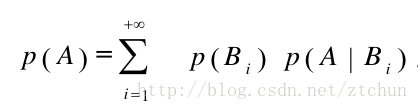
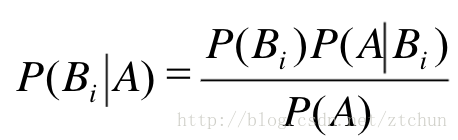
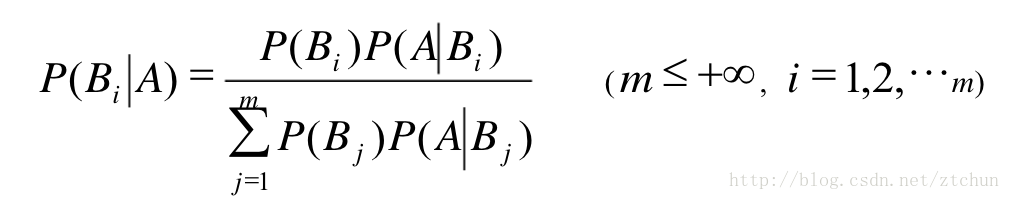
有了先验数学知识就容易了,假设RBM网络结构有n个节点和m个隐藏节点,其中每个可视节点只和m个隐藏节点有关系,其他可视节点是对立的,就是这个可视节点只受m个隐藏节点的影响,对于每个隐藏节点也是,这个特点使得RBM的训练变得容易了。RBM网络有几个参数,一个是可视层与隐藏层之间的权重矩阵Wm x n,一个是可视节点的偏移量b=(b1,b2,…,bn),一个是隐藏节点的偏置值(c1,c2,…,cm),这几个参数决定了RBM网络将一个n维的样本编码成一个什么样的m维样本。
因此,当输入v的时候,通过p(h|v) 可以得到隐藏层h,而得到隐藏层h之后,通过p(v|h)又能得到可视层,通过调整参数,我们就是要使得从隐藏层得到的可视层v1与原来的可视层v如果一样,那么得到的隐藏层就是可视层另外一种表达,因此隐藏层可以作为可视层输入数据的特征,所以它就是一种Deep Learning方法。
2.RBM的用途
(1)对数据进行编码,然后交给监督学习方法进行分类个回归;
这种方法将其当作一个降维的方法使用。这种方式类似于稀疏自动编码器机理。
(2)得到了权重矩阵和偏移量,供BP神经网络初始化训练。
如果直接用BP神经网络,初始值选取不好的话,往往陷入局部极小值,实验结果表明,直接将RBM训练得到的权重矩阵和偏置值作为BP神经网络的初始值,得到效果比较好。
(3)RBM可以估计联合概率p(v,h),如果把v当作训练样本,h当作类别标签(隐藏节点只有一个的情况下,能得到一个隐藏节点为1的概率),就可以用贝叶斯公式求p(h|v),就可以分类,类似朴素贝叶斯、LDA和HMM。RBM可以当作一个生成模型使用。
(4)RBM可以直接计算条件概率p(h|v),如果把v当作训练样本,把h当作类别标签(隐藏节点只有一个的情况下,能得到一个隐藏节点为1的概率),RBM就可以就行分类。RBM可以作为一个判别模型使用。














 7602
7602











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









