1. 算子分类
从大方向来说,Spark 算子大致可以分为以下两类
- Transformation:操作是延迟计算的,也就是说从一个RDD 转换生成另一个 RDD 的转换操作不是马上执行,需要等到有 Action 操作的时候才会真正触发运算。
- Action:会触发 Spark 提交作业(Job),并将数据输出 Spark系统。
从小方向来说,Spark 算子大致可以分为以下三类:
- Value数据类型的Transformation算子。
- Key-Value数据类型的Transfromation算子。
- Action算子
| 类型 | 算子 |
|---|
| 输入分区与输出分区一对一型 | map、flatMap、mapPartitions、glom |
| 输入分区与输出分区多对一型 | union、cartesian |
| 输入分区与输出分区多对多型 | groupBy |
| 输出分区为输入分区子集型 | filter、distinct、subtract、sample、takeSample |
| Cache型 | cache、persist |
1.2 Key-Value数据类型的Transfromation算子
| 类型 | 算子 |
|---|
| 输入分区与输出分区一对一 | mapValues |
| 对单个RDD | combineByKey、reduceByKey、partitionBy |
| 两个RDD聚集 | Cogroup |
| 连接 | join、leftOutJoin、rightOutJoin |
1.3 Action算子
| 类型 | 算子 |
|---|
| 无输出 | foreach |
| HDFS | saveAsTextFile、saveAsObjectFile |
| Scala集合和数据类型 | collect、collectAsMap、reduceByKeyLocally、lookup、count、top、reduce、fold、aggregate |
2.1 map
2.1.1 概述
语法(Java):
static <R> JavaRDD<R> map(Function<T,R> f)
说明:
将原来RDD的每个数据项通过map中的用户自定义函数f映射转变为一个新的元素
2.1.2 Java示例
/**
* map算子
* <p>
* map和foreach算子:
* 1. 循环map调用元的每一个元素;
* 2. 执行call函数, 并返回.
* </p>
*/
private static void map() {
SparkConf conf = new SparkConf().setAppName(JavaOperatorDemo.class.getSimpleName())
.setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
List<String> datas = Arrays.asList(
"{'id':1,'name':'xl1','pwd':'xl123','sex':2}",
"{'id':2,'name':'xl2','pwd':'xl123','sex':1}",
"{'id':3,'name':'xl3','pwd':'xl123','sex':2}");
JavaRDD<String> datasRDD = sc.parallelize(datas);
JavaRDD<User> mapRDD = datasRDD.map(
new Function<String, User>() {
public User call(String v) throws Exception {
Gson gson = new Gson();
return gson.fromJson(v, User.class);
}
});
mapRDD.foreach(new VoidFunction<User>() {
public void call(User user) throws Exception {
System.out.println("id: " + user.id
+ " name: " + user.name
+ " pwd: " + user.pwd
+ " sex:" + user.sex);
}
});
sc.close();
}
id: 1 name: xl1 pwd: xl123 sex:2
id: 2 name: xl2 pwd: xl123 sex:1
id: 3 name: xl3 pwd: xl123 sex:2
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
2.1.3 Scala示例
private def map() {
val conf = new SparkConf().setAppName(ScalaOperatorDemo.getClass.getSimpleName).setMaster("local")
val sc = new SparkContext(conf)
val datas: Array[String] = Array(
"{'id':1,'name':'xl1','pwd':'xl123','sex':2}",
"{'id':2,'name':'xl2','pwd':'xl123','sex':1}",
"{'id':3,'name':'xl3','pwd':'xl123','sex':2}")
sc.parallelize(datas)
.map(v => {
new Gson().fromJson(v, classOf[User])
})
.foreach(user => {
println("id: " + user.id
+ " name: " + user.name
+ " pwd: " + user.pwd
+ " sex:" + user.sex)
})
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
2.2 filter
2.2.1 概述
语法(java):
JavaPairRDD<K,V> filter(Function<scala.Tuple2<K,V>,Boolean> f)
说明:
对元素进行过滤,对每个元素应用f函数,返回值为true的元素在RDD中保留,返回为false的将过滤掉
2.2.2 Java示例
static void filter() {
SparkConf conf = new SparkConf().setAppName(JavaOperatorDemo.class.getSimpleName())
.setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
List<Integer> datas = Arrays.asList(1, 2, 3, 7, 4, 5, 8);
JavaRDD<Integer> rddData = sc.parallelize(datas);
JavaRDD<Integer> filterRDD = rddData.filter(
new Function<Integer, Boolean>() {
public Boolean call(Integer v) throws Exception {
return v >= 3;
}
}
);
filterRDD.foreach(
new VoidFunction<Integer>() {
@Override
public void call(Integer integer) throws Exception {
System.out.println(integer);
}
}
);
sc.close();
}
3
7
4
5
8
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
2.2.3 Scala示例
def filter {
val conf = new SparkConf().setAppName(ScalaOperatorDemo.getClass.getSimpleName).setMaster("local")
val sc = new SparkContext(conf)
val datas = Array(1, 2, 3, 7, 4, 5, 8)
sc.parallelize(datas)
.filter(v => v >= 3)
.foreach(println)
}
2.3 flatMap
2.3.1 简述
语法(java):
static <U> JavaRDD<U> flatMap(FlatMapFunction<T,U> f)
说明:
与map类似,但每个输入的RDD成员可以产生0或多个输出成员
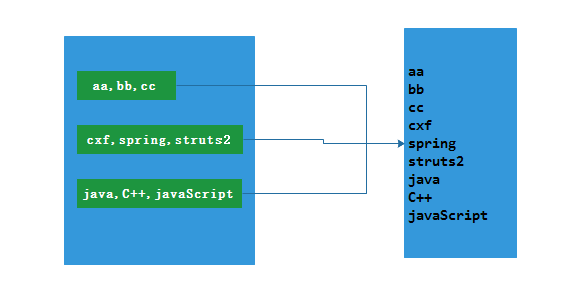
2.3.2 Java示例
static void flatMap() {
SparkConf conf = new SparkConf().setAppName(JavaOperatorDemo.class.getSimpleName())
.setMaster("local")
JavaSparkContext sc = new JavaSparkContext(conf)
List<String> data = Arrays.asList(
"aa,bb,cc",
"cxf,spring,struts2",
"java,C++,javaScript")
JavaRDD<String> rddData = sc.parallelize(data)
JavaRDD<String> flatMapData = rddData.flatMap(
v -> Arrays.asList(v.split(",")).iterator()
// new FlatMapFunction<String, String>() {
// @Override
// public Iterator<String> call(String t) throws Exception {
// List<String> list= Arrays.asList(t.split(","))
// return list.iterator()
// }
// }
)
flatMapData.foreach(v -> System.out.println(v))
sc.close()
}
// 结果
aa
bb
cc
cxf
spring
struts2
java
C++
javaScript
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
2.3.3 Scala示例
sc.parallelize(datas)
.flatMap(line => line.split(","))
.foreach(println)
2.4 mapPartitions
2.4.1 概述
语法(java):
static <U> JavaRDD<U> mapPartitions(
FlatMapFunction<java.util.Iterator<T>,U> f,
boolean preservesPartitioning)
说明:
与Map类似,但map中的func作用的是RDD中的每个元素,而mapPartitions中的func作用的对象是RDD的一整个分区。所以func的类型是Iterator\
2.4.2 Java示例
static void mapPartitions() {
SparkConf conf = new SparkConf().setAppName(JavaOperatorDemo.class.getSimpleName())
.setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
List<String> names = Arrays.asList("张三1", "李四1", "王五1", "张三2", "李四2",
"王五2", "张三3", "李四3", "王五3", "张三4");
JavaRDD<String> namesRDD = sc.parallelize(names, 3);
JavaRDD<String> mapPartitionsRDD = namesRDD.mapPartitions(
new FlatMapFunction<Iterator<String>, String>() {
int count = 0;
@Override
public Iterator<String> call(Iterator<String> stringIterator) throws Exception {
List<String> list = new ArrayList<String>();
while (stringIterator.hasNext()) {
list.add("分区索引:" + count++ + "\t" + stringIterator.next());
}
return list.iterator();
}
}
);
List<String> result = mapPartitionsRDD.collect();
result.forEach(System.out::println);
sc.close();
}
分区索引:0 张三1
分区索引:1 李四1
分区索引:2 王五1
分区索引:0 张三2
分区索引:1 李四2
分区索引:2 王五2
分区索引:0 张三3
分区索引:1 李四3
分区索引:2 王五3
分区索引:3 张三4
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
2.4.3 Scala示例
sc.parallelize(datas, 3)
.mapPartitions(
n => {
val result = ArrayBuffer[String]()
while (n.hasNext) {
result.append(n.next())
}
result.iterator
}
)
.foreach(println)
2.5 mapPartitionsWithIndex
2.5.1 概述
语法(java):
static <R> JavaRDD<R> mapPartitionsWithIndex(
Function2<Integer, java.util.Iterator<T>, java.util.Iterator<R>> f,
boolean preservesPartitioning)
说明:
与mapPartitions类似,但输入会多提供一个整数表示分区的编号,所以func的类型是(Int, Iterator\
2.5.2 Java示例
private static void mapPartitionsWithIndex() {
SparkConf conf = new SparkConf().setAppName(JavaOperatorDemo.class.getSimpleName())
.setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
List<String> names = Arrays.asList("张三1", "李四1", "王五1", "张三2", "李四2",
"王五2", "张三3", "李四3", "王五3", "张三4");
JavaRDD<String> namesRDD = sc.parallelize(names, 3);
JavaRDD<String> mapPartitionsWithIndexRDD = namesRDD.mapPartitionsWithIndex(
new Function2<Integer, Iterator<String>, Iterator<String>>() {
private static final long serialVersionUID = 1L;
public Iterator<String> call(Integer v1, Iterator<String> v2) throws Exception {
List<String> list = new ArrayList<String>();
while (v2.hasNext()) {
list.add("分区索引:" + v1 + "\t" + v2.next());
}
return list.iterator();
}
},
true);
List<String> result = mapPartitionsWithIndexRDD.collect();
result.forEach(System.out::println);
sc.close();
}
分区索引:0 张三1
分区索引:0 李四1
分区索引:0 王五1
分区索引:1 张三2
分区索引:1 李四2
分区索引:1 王五2
分区索引:2 张三3
分区索引:2 李四3
分区索引:2 王五3
分区索引:2 张三4
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
2.5.3 Scala示例
sc.parallelize(datas, 3)
.mapPartitionsWithIndex(
(m, n) => {
val result = ArrayBuffer[String]()
while (n.hasNext) {
result.append("分区索引:" + m + "\t" + n.next())
}
result.iterator
}
)
.foreach(println)
2.6 sample
2.6.1 概述
语法(java):
JavaPairRDD<K,V> sample(boolean withReplacement,
double fraction)
JavaPairRDD<K,V> sample(boolean withReplacement,
double fraction,
long seed)
说明:
对RDD进行抽样,其中参数withReplacement为true时表示抽样之后还放回,可以被多次抽样,false表示不放回;fraction表示抽样比例;seed为随机数种子,比如当前时间戳
2.6.2 Java示例
static void sample() {
SparkConf conf = new SparkConf().setAppName(JavaOperatorDemo.class.getSimpleName())
.setMaster("local")
JavaSparkContext sc = new JavaSparkContext(conf)
List<Integer> datas = Arrays.asList(1, 2, 3, 7, 4, 5, 8)
JavaRDD<Integer> dataRDD = sc.parallelize(datas)
JavaRDD<Integer> sampleRDD = dataRDD.sample(false, 0.5, System.currentTimeMillis())
sampleRDD.foreach(v -> System.out.println(v))
sc.close()
}
// 结果
7
4
5
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
2.6.3 Scala示例
sc.parallelize(datas)
.sample(withReplacement = false, 0.5, System.currentTimeMillis)
.foreach(println)
2.7 union
2.7.1 概述
语法(java):
JavaPairRDD<K,V> union(JavaPairRDD<K,V> other)
说明:
合并两个RDD,不去重,要求两个RDD中的元素类型一致
2.7.2 Java示例
static void union() {
SparkConf conf = new SparkConf().setAppName(JavaOperatorDemo.class.getSimpleName())
.setMaster("local")
JavaSparkContext sc = new JavaSparkContext(conf)
List<String> datas1 = Arrays.asList("张三", "李四")
List<String> datas2 = Arrays.asList("tom", "gim")
JavaRDD<String> data1RDD = sc.parallelize(datas1)
JavaRDD<String> data2RDD = sc.parallelize(datas2)
JavaRDD<String> unionRDD = data1RDD
.union(data2RDD)
unionRDD.foreach(v -> System.out.println(v))
sc.close()
}
// 结果
张三
李四
tom
gim
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
2.7.3 Scala示例
// sc.parallelize(datas1)
// .union(sc.parallelize(datas2))
// .foreach(println)
// 或
(sc.parallelize(datas1) ++ sc.parallelize(datas2))
.foreach(println)
2.8 intersection
2.8.1 概述
语法(java):
JavaPairRDD<K,V> intersection(JavaPairRDD<K,V> other)
说明:
返回两个RDD的交集
2.8.2 Java示例
static void intersection(JavaSparkContext sc) {
List<String> datas1 = Arrays.asList("张三", "李四", "tom")
List<String> datas2 = Arrays.asList("tom", "gim")
sc.parallelize(datas1)
.intersection(sc.parallelize(datas2))
.foreach(v -> System.out.println(v))
}
// 结果
tom
2.8.3 Scala示例
sc.parallelize(datas1)
.intersection(sc.parallelize(datas2))
.foreach(println)
2.9 distinct
2.9.1 概述
语法(java):
JavaPairRDD<K,V> distinct(int numPartitions)
JavaPairRDD<K,V> distinct()
说明:
对原RDD进行去重操作,返回RDD中没有重复的成员
2.9.2 Java示例
static void distinct(JavaSparkContext sc) {
List<String> datas = Arrays.asList("张三", "李四", "tom", "张三")
sc.parallelize(datas)
.distinct()
.foreach(v -> System.out.println(v))
}
// 结果
张三
tom
李四
2.9.3 Scala示例
sc.parallelize(datas)
.distinct()
.foreach(println)
2.10 groupByKey
2.10.1 概述
语法(java):
JavaPairRDD<U,Iterable<T>> groupBy(Function<T,U> f)
JavaPairRDD<U,Iterable<T>> groupBy(Function<T,U> f, int numPartitions)
JavaPairRDD<K,Iterable<V>> groupByKey()
JavaPairRDD<K,Iterable<V>> groupByKey(int numPartitions)
JavaPairRDD<K,Iterable<V>> groupByKey(Partitioner partitioner)
说明:
对\
2.10.2 Java示例
static void groupBy(JavaSparkContext sc) {
List<Integer> datas = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9)
sc.parallelize(datas)
.groupBy(new Function<Integer, Object>() {
@Override
public Object call(Integer v1) throws Exception {
return (v1 % 2 == 0) ? "偶数" : "奇数"
}
})
.collect()
.forEach(System.out::println)
List<String> datas2 = Arrays.asList("dog", "tiger", "lion", "cat", "spider", "eagle")
sc.parallelize(datas2)
.keyBy(v1 -> v1.length())
.groupByKey()
.collect()
.forEach(System.out::println)
}
// 结果
(奇数,[1, 3, 5, 7, 9])
(偶数,[2, 4, 6, 8])
(4,[lion])
(6,[spider])
(3,[dog, cat])
(5,[tiger, eagle])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
2.10.3 Scala示例
def groupBy(sc: SparkContext): Unit = {
sc.parallelize(1 to 9, 3)
.groupBy(x => {
if (x % 2 == 0) "偶数"
else "奇数"
})
.collect()
.foreach(println)
val datas2 = Array("dog", "tiger", "lion", "cat", "spider", "eagle")
sc.parallelize(datas2)
.keyBy(_.length)
.groupByKey()
.collect()
.foreach(println)
}
2.11 reduceByKey
2.11.1 概述
语法(java):
JavaPairRDD<K,V> reduceByKey(Partitioner partitioner,
Function2<V,V,V> func)
JavaPairRDD<K,V> reduceByKey(Function2<V,V,V> func,
int numPartitions)
JavaPairRDD<K,V> reduceByKey(Function2<V,V,V> func)
说明:
对\
2.11.2 Java示例
static void reduceByKey(JavaSparkContext sc) {
JavaRDD<String> lines = sc.textFile("file:///Users/zhangws/opt/spark-2.0.1-bin-hadoop2.6/README.md");
JavaRDD<String> wordsRDD = lines.flatMap(new FlatMapFunction<String, String>() {
private static final long serialVersionUID = 1L;
public Iterator<String> call(String line) throws Exception {
List<String> words = Arrays.asList(line.split(" "));
return words.iterator();
}
});
JavaPairRDD<String, Integer> wordsCount = wordsRDD.mapToPair(new PairFunction<String, String, Integer>() {
private static final long serialVersionUID = 1L;
public Tuple2<String, Integer> call(String word) throws Exception {
return new Tuple2<String, Integer>(word, 1);
}
});
JavaPairRDD<String, Integer> resultRDD = wordsCount.reduceByKey(new Function2<Integer, Integer, Integer>() {
private static final long serialVersionUID = 1L;
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
resultRDD.foreach(new VoidFunction<Tuple2<String, Integer>>() {
private static final long serialVersionUID = 1L;
public void call(Tuple2<String, Integer> t) throws Exception {
System.out.println(t._1 + "\t" + t._2());
}
});
sc.close();
}
package 1
For 3
Programs 1
(略)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
2.11.3 Scala示例
val textFile = sc.textFile("file:///home/zkpk/spark-2.0.1/README.md")
val words = textFile.flatMap(line => line.split(" "))
val wordPairs = words.map(word => (word, 1))
val wordCounts = wordPairs.reduceByKey((a, b) => a + b)
println("wordCounts: ")
wordCounts.collect().foreach(println)
2.12 aggregateByKey
2.12.1 概述
语法(java):
<U> JavaPairRDD<K,U> aggregateByKey(U zeroValue,
Partitioner partitioner,
Function2<U,V,U> seqFunc,
Function2<U,U,U> combFunc)
<U> JavaPairRDD<K,U> aggregateByKey(U zeroValue,
int numPartitions,
Function2<U,V,U> seqFunc,
Function2<U,U,U> combFunc)
<U> JavaPairRDD<K,U> aggregateByKey(U zeroValue,
Function2<U,V,U> seqFunc,
Function2<U,U,U> combFunc)
说明:
aggregateByKey函数对PairRDD中相同Key的值进行聚合操作,在聚合过程中同样使用了一个中立的初始值。和aggregate函数类似,aggregateByKey返回值得类型不需要和RDD中value的类型一致。因为aggregateByKey是对相同Key中的值进行聚合操作,所以aggregateByKey函数最终返回的类型还是Pair RDD,对应的结果是Key和聚合好的值;而aggregate函数直接返回非RDD的结果。
参数:
- zeroValue:表示在每个分区中第一次拿到key值时,用于创建一个返回类型的函数,这个函数最终会被包装成先生成一个返回类型,然后通过调用seqOp函数,把第一个key对应的value添加到这个类型U的变量中。
- seqOp:这个用于把迭代分区中key对应的值添加到zeroValue创建的U类型实例中。
- combOp:这个用于合并每个分区中聚合过来的两个U类型的值。
2.12.2 Java示例
static void aggregateByKey(JavaSparkContext sc) {
List<Tuple2<Integer, Integer>> datas = new ArrayList<>();
datas.add(new Tuple2<>(1, 3));
datas.add(new Tuple2<>(1, 2));
datas.add(new Tuple2<>(1, 4));
datas.add(new Tuple2<>(2, 3));
sc.parallelizePairs(datas, 2)
.aggregateByKey(
0,
new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
System.out.println("seq: " + v1 + "\t" + v2);
return Math.max(v1, v2);
}
},
new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
System.out.println("comb: " + v1 + "\t" + v2);
return v1 + v2;
}
})
.collect()
.forEach(System.out::println);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
2.12.3 Scala示例
def aggregateByKey(sc: SparkContext): Unit = {
// 合并在同一个partition中的值,a的数据类型为zeroValue的数据类型,b的数据类型为原value的数据类型
def seq(a:Int, b:Int): Int = {
println("seq: " + a + "\t" + b)
math.max(a, b)
}
// 合并在不同partition中的值,a,b的数据类型为zeroValue的数据类型
def comb(a:Int, b:Int): Int = {
println("comb: " + a + "\t" + b)
a + b
}
// 数据拆分成两个分区
// 分区一数据: (1,3) (1,2)
// 分区二数据: (1,4) (2,3)
// zeroValue 中立值,定义返回value的类型,并参与运算
// seqOp 用来在一个partition中合并值的
// 分区一相同key的数据进行合并
// seq: 0 3 (1,3)开始和中位值合并为3
// seq: 3 2 (1,2)再次合并为3
// 分区二相同key的数据进行合并
// seq: 0 4 (1,4)开始和中位值合并为4
// seq: 0 3 (2,3)开始和中位值合并为3
// comb 用来在不同partition中合并值的
// 将两个分区的结果进行合并
// key为1的, 两个分区都有, 合并为(1,7)
// key为2的, 只有一个分区有, 不需要合并(2,3)
sc.parallelize(List((1, 3), (1, 2), (1, 4), (2, 3)), 2)
.aggregateByKey(0)(seq, comb)
.collect()
.foreach(println)
}
// 结果
(2,3)
(1,7)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
2.13 sortByKey
2.13.1 概述
语法(java):
JavaRDD<T> sortBy(Function<T,S> f,
boolean ascending,
int numPartitions)
JavaPairRDD<K,V> sortByKey()
JavaPairRDD<K,V> sortByKey(boolean ascending)
JavaPairRDD<K,V> sortByKey(boolean ascending,
int numPartitions)
JavaPairRDD<K,V> sortByKey(java.util.Comparator<K> comp)
JavaPairRDD<K,V> sortByKey(java.util.Comparator<K> comp,
boolean ascending)
JavaPairRDD<K,V> sortByKey(java.util.Comparator<K> comp,
boolean ascending,
int numPartitions)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
说明:
对\
2.13.2 Java示例
static void sortByKey(JavaSparkContext sc) {
List<Integer> datas = Arrays.asList(60, 70, 80, 55, 45, 75);
// sc.parallelize(datas)
// .sortBy(new Function<Integer, Object>() {
// @Override
// public Object call(Integer v1) throws Exception {
// return v1;
// }
// }, true, 1)
// .foreach(v -> System.out.println(v));
sc.parallelize(datas)
.sortBy((Integer v1) -> v1, false, 1)
.foreach(v -> System.out.println(v));
List<Tuple2<Integer, Integer>> datas2 = new ArrayList<>();
datas2.add(new Tuple2<>(3, 3));
datas2.add(new Tuple2<>(2, 2));
datas2.add(new Tuple2<>(1, 4));
datas2.add(new Tuple2<>(2, 3));
sc.parallelizePairs(datas2)
.sortByKey(false)
.foreach(v -> System.out.println(v));
}
// 结果
80
75
70
60
55
45
(3,3)
(2,2)
(2,3)
(1,4)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
2.13.3 Scala示例
def sortByKey(sc: SparkContext) : Unit = {
sc.parallelize(Array(60, 70, 80, 55, 45, 75))
.sortBy(v => v, false)
.foreach(println)
sc.parallelize(List((3, 3), (2, 2), (1, 4), (2, 3)))
.sortByKey(true)
.foreach(println)
}
2.14 join
2.14.1 概述
语法(java):
JavaPairRDD<K,scala.Tuple2<V,W>> join(JavaPairRDD<K,W> other)
JavaPairRDD<K,scala.Tuple2<V,W>> join(
JavaPairRDD<K,W> other,
int numPartitions)
JavaPairRDD<K,scala.Tuple2<V,W>> join(
JavaPairRDD<K,W> other,
Partitioner partitioner)
说明:
对\
2.14.2 Java示例
static void join(JavaSparkContext sc) {
List<Tuple2<Integer, String>> products = new ArrayList<>();
products.add(new Tuple2<>(1, "苹果"));
products.add(new Tuple2<>(2, "梨"));
products.add(new Tuple2<>(3, "香蕉"));
products.add(new Tuple2<>(4, "石榴"));
List<Tuple2<Integer, Integer>> counts = new ArrayList<>();
counts.add(new Tuple2<>(1, 7));
counts.add(new Tuple2<>(2, 3));
counts.add(new Tuple2<>(3, 8));
counts.add(new Tuple2<>(4, 3));
counts.add(new Tuple2<>(5, 9));
JavaPairRDD<Integer, String> productsRDD = sc.parallelizePairs(products);
JavaPairRDD<Integer, Integer> countsRDD = sc.parallelizePairs(counts);
productsRDD.join(countsRDD)
.foreach(v -> System.out.println(v));
}
(4,(石榴,3))
(1,(苹果,7))
(3,(香蕉,8))
(2,(梨,3))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
2.14.3 Scala示例
sc.parallelize(List((1, "苹果"), (2, "梨"), (3, "香蕉"), (4, "石榴")))
.join(sc.parallelize(List((1, 7), (2, 3), (3, 8), (4, 3), (5, 9))))
.foreach(println)
2.15 cogroup
2.15.1 概述
语法(java):
JavaPairRDD<K,scala.Tuple2<Iterable<V>,Iterable<W>>> cogroup(JavaPairRDD<K,W> other,
Partitioner partitioner)
JavaPairRDD<K,scala.Tuple3<Iterable<V>,Iterable<W1>,Iterable<W2>>> cogroup(JavaPairRDD<K,W1> other1,
JavaPairRDD<K,W2> other2,
Partitioner partitioner)
JavaPairRDD<K,scala.Tuple4<Iterable<V>,Iterable<W1>,Iterable<W2>,Iterable<W3>>> cogroup(JavaPairRDD<K,W1> other1,
JavaPairRDD<K,W2> other2,
JavaPairRDD<K,W3> other3,
Partitioner partitioner)
JavaPairRDD<K,scala.Tuple2<Iterable<V>,Iterable<W>>> cogroup(JavaPairRDD<K,W> other)
JavaPairRDD<K,scala.Tuple3<Iterable<V>,Iterable<W1>,Iterable<W2>>> cogroup(JavaPairRDD<K,W1> other1,
JavaPairRDD<K,W2> other2)
JavaPairRDD<K,scala.Tuple4<Iterable<V>,Iterable<W1>,Iterable<W2>,Iterable<W3>>> cogroup(JavaPairRDD<K,W1> other1,
JavaPairRDD<K,W2> other2,
JavaPairRDD<K,W3> other3)
JavaPairRDD<K,scala.Tuple2<Iterable<V>,Iterable<W>>> cogroup(JavaPairRDD<K,W> other,
int numPartitions)
JavaPairRDD<K,scala.Tuple3<Iterable<V>,Iterable<W1>,Iterable<W2>>> cogroup(JavaPairRDD<K,W1> other1,
JavaPairRDD<K,W2> other2,
int numPartitions)
JavaPairRDD<K,scala.Tuple4<Iterable<V>,Iterable<W1>,Iterable<W2>,Iterable<W3>>> cogroup(JavaPairRDD<K,W1> other1,
JavaPairRDD<K,W2> other2,
JavaPairRDD<K,W3> other3,
int numPartitions)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
说明:
cogroup:对多个RDD中的KV元素,每个RDD中相同key中的元素分别聚合成一个集合。与reduceByKey不同的是针对两个RDD中相同的key的元素进行合并。
2.15.2 Java示例
static void cogroup(JavaSparkContext sc) {
List<Tuple2<Integer, String>> datas1 = new ArrayList<>();
datas1.add(new Tuple2<>(1, "苹果"));
datas1.add(new Tuple2<>(2, "梨"));
datas1.add(new Tuple2<>(3, "香蕉"));
datas1.add(new Tuple2<>(4, "石榴"));
List<Tuple2<Integer, Integer>> datas2 = new ArrayList<>();
datas2.add(new Tuple2<>(1, 7));
datas2.add(new Tuple2<>(2, 3));
datas2.add(new Tuple2<>(3, 8));
datas2.add(new Tuple2<>(4, 3));
List<Tuple2<Integer, String>> datas3 = new ArrayList<>();
datas3.add(new Tuple2<>(1, "7"));
datas3.add(new Tuple2<>(2, "3"));
datas3.add(new Tuple2<>(3, "8"));
datas3.add(new Tuple2<>(4, "3"));
datas3.add(new Tuple2<>(4, "4"));
datas3.add(new Tuple2<>(4, "5"));
datas3.add(new Tuple2<>(4, "6"));
sc.parallelizePairs(datas1)
.cogroup(sc.parallelizePairs(datas2),
sc.parallelizePairs(datas3))
.foreach(v -> System.out.println(v));
}
(4,([石榴],[3],[3, 4, 5, 6]))
(1,([苹果],[7],[7]))
(3,([香蕉],[8],[8]))
(2,([梨],[3],[3]))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
2.15.3 Scala示例
def cogroup(sc: SparkContext): Unit = {
val datas1 = List((1, "苹果"),
(2, "梨"),
(3, "香蕉"),
(4, "石榴"))
val datas2 = List((1, 7),
(2, 3),
(3, 8),
(4, 3))
val datas3 = List((1, "7"),
(2, "3"),
(3, "8"),
(4, "3"),
(4, "4"),
(4, "5"),
(4, "6"))
sc.parallelize(datas1)
.cogroup(sc.parallelize(datas2),
sc.parallelize(datas3))
.foreach(println)
}
// 结果
(4,(CompactBuffer(石榴),CompactBuffer(3),CompactBuffer(3, 4, 5, 6)))
(1,(CompactBuffer(苹果),CompactBuffer(7),CompactBuffer(7)))
(3,(CompactBuffer(香蕉),CompactBuffer(8),CompactBuffer(8)))
(2,(CompactBuffer(梨),CompactBuffer(3),CompactBuffer(3)))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
2.16 cartesian
2.16.1 概述
语法(java):
static <U> JavaPairRDD<T,U> cartesian(JavaRDDLike<U,?> other)
说明:
两个RDD进行笛卡尔积合并
2.16.2 Java示例
static void cartesian(JavaSparkContext sc) {
List<String> names = Arrays.asList("张三", "李四", "王五");
List<Integer> scores = Arrays.asList(60, 70, 80);
JavaRDD<String> namesRDD = sc.parallelize(names);
JavaRDD<Integer> scoreRDD = sc.parallelize(scores);
JavaPairRDD<String, Integer> cartesianRDD = namesRDD.cartesian(scoreRDD);
cartesianRDD.foreach(new VoidFunction<Tuple2<String, Integer>>() {
private static final long serialVersionUID = 1L;
public void call(Tuple2<String, Integer> t) throws Exception {
System.out.println(t._1 + "\t" + t._2());
}
});
}
张三 60
张三 70
张三 80
李四 60
李四 70
李四 80
王五 60
王五 70
王五 80
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
2.16.3 Scala示例
namesRDD.cartesian(scoreRDD)
.foreach(println)
2.17 pipe
2.17.1 概述
语法(java):
JavaRDD<String> pipe(String command)
JavaRDD<String> pipe(java.util.List<String> command)
JavaRDD<String> pipe(java.util.List<String> command,
java.util.Map<String,String> env)
JavaRDD<String> pipe(java.util.List<String> command,
java.util.Map<String,String> env,
boolean separateWorkingDir,
int bufferSize)
static JavaRDD<String> pipe(java.util.List<String> command,
java.util.Map<String,String> env,
boolean separateWorkingDir,
int bufferSize,
String encoding)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
说明:
执行cmd命令,创建RDD
2.17.2 Java示例
static void pipe(JavaSparkContext sc) {
List<String> datas = Arrays.asList("hi", "hello", "how", "are", "you")
sc.parallelize(datas)
.pipe("/Users/zhangws/echo.sh")
.collect()
.forEach(System.out::println)
}
2.17.3 Scala示例
echo.sh内容
#!/bin/bash
echo "Running shell script"
RESULT=""
while read LINE; do
RESULT=${RESULT}" "${LINE}
done
echo ${RESULT} > /Users/zhangws/out123.txt
测试代码
def pipe(sc: SparkContext): Unit = {
val data = List("hi", "hello", "how", "are", "you")
sc.makeRDD(data)
.pipe("/Users/zhangws/echo.sh")
.collect()
.foreach(println)
}
结果
# out123.txt
hi hello how are you
# 输出
Running shell script
2.18 coalesce
2.18.1 概述
语法(java):
JavaRDD<T> coalesce(int numPartitions)
JavaRDD<T> coalesce(int numPartitions,
boolean shuffle)
JavaPairRDD<K,V> coalesce(int numPartitions)
JavaPairRDD<K,V> coalesce(int numPartitions,
boolean shuffle)
说明:
用于将RDD进行重分区,使用HashPartitioner。且该RDD的分区个数等于numPartitions个数。如果shuffle设置为true,则会进行shuffle。
2.18.2 Java示例
static void coalesce(JavaSparkContext sc) {
List<String> datas = Arrays.asList("hi", "hello", "how", "are", "you")
JavaRDD<String> datasRDD = sc.parallelize(datas, 4)
System.out.println("RDD的分区数: " + datasRDD.partitions().size())
JavaRDD<String> datasRDD2 = datasRDD.coalesce(2)
System.out.println("RDD的分区数: " + datasRDD2.partitions().size())
}
// 结果
RDD的分区数: 4
RDD的分区数: 2
2.18.3 Scala示例
def coalesce(sc: SparkContext): Unit = {
val datas = List("hi", "hello", "how", "are", "you")
val datasRDD = sc.parallelize(datas, 4)
println("RDD的分区数: " + datasRDD.partitions.length)
val datasRDD2 = datasRDD.coalesce(2)
println("RDD的分区数: " + datasRDD2.partitions.length)
}
2.19 repartition
2.19.1 概述
语法(java):
JavaRDD<T> repartition(int numPartitions)
JavaPairRDD<K,V> repartition(int numPartitions)
说明:
该函数其实就是coalesce函数第二个参数为true的实现
示例略
2.20 repartitionAndSorWithinPartitions
2.20.1 概述
语法(java):
JavaPairRDD<K,V> repartitionAndSortWithinPartitions(Partitioner partitioner)
JavaPairRDD<K,V> repartitionAndSortWithinPartitions(Partitioner partitioner,
java.util.Comparator<K> comp)
说明:
根据给定的Partitioner重新分区,并且每个分区内根据comp实现排序。
2.20.2 Java示例
static void repartitionAndSortWithinPartitions(JavaSparkContext sc) {
List<String> datas = new ArrayList<>();
Random random = new Random(1);
for (int i = 0; i < 10; i++) {
for (int j = 0; j < 100; j++) {
datas.add(String.format("product%02d,url%03d", random.nextInt(10), random.nextInt(100)));
}
}
JavaRDD<String> datasRDD = sc.parallelize(datas);
JavaPairRDD<String, String> pairRDD = datasRDD.mapToPair((String v) -> {
String[] values = v.split(",");
return new Tuple2<>(values[0], values[1]);
});
JavaPairRDD<String, String> partSortRDD = pairRDD.repartitionAndSortWithinPartitions(
new Partitioner() {
@Override
public int numPartitions() {
return 10;
}
@Override
public int getPartition(Object key) {
return Integer.valueOf(((String) key).substring(7));
}
}
);
partSortRDD.collect()
.forEach(System.out::println);
}
// 结果
(product00,url099)
(product00,url006)
(product00,url088)
略
(product09,url004)
(product09,url021)
(product09,url036)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
2.20.3 Scala示例
def repartitionAndSortWithinPartitions(sc: SparkContext): Unit = {
def partitionFunc(key:String): Int = {
key.substring(7).toInt
}
val datas = new Array[String](1000)
val random = new Random(1)
for (i <- 0 until 10; j <- 0 until 100) {
val index: Int = i * 100 + j
datas(index) = "product" + random.nextInt(10) + ",url" + random.nextInt(100)
}
val datasRDD = sc.parallelize(datas)
val pairRDD = datasRDD.map(line => (line, 1))
.reduceByKey((a, b) => a + b)
// .foreach(println)
pairRDD.repartitionAndSortWithinPartitions(new Partitioner() {
override def numPartitions: Int = 10
override def getPartition(key: Any): Int = {
val str = String.valueOf(key)
str.substring(7, str.indexOf(',')).toInt
}
}).foreach(println)
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
3. Action
3.1 reduce
3.1.1 概述
语法(java):
static T reduce(Function2<T,T,T> f)
说明:
对RDD成员使用func进行reduce操作,func接受两个参数,合并之后只返回一个值。reduce操作的返回结果只有一个值。需要注意的是,func会并发执行
3.1.2 Scala示例
def reduce(sc: SparkContext): Unit = {
println(sc.parallelize(1 to 10)
.reduce((x, y) => x + y))
}
// 结果
55
3.2 collect
3.2.1 概述
语法(java):
static java.util.List<T> collect()
说明:
将RDD读取至Driver程序,类型是Array,一般要求RDD不要太大。
示例略
3.3 count
3.3.1 概述
语法(java):
static long count()
说明:
返回RDD的成员数量
3.3.2 Scala示例
def count(sc: SparkContext): Unit = {
println(sc.parallelize(1 to 10)
.count)
}
// 结果
10
3.4 first
3.4.1 概述
语法(java):
static T first()
说明:
返回RDD的第一个成员,等价于take(1)
3.4.2 Scala示例
def first(sc: SparkContext): Unit = {
println(sc.parallelize(1 to 10)
.first())
}
// 结果
1
3.5 take
3.5.1 概述
语法(java):
static java.util.List<T> take(int num)
说明:
返回RDD前n个成员
3.5.2 Scala示例
def take(sc: SparkContext): Unit = {
sc.parallelize(1 to 10)
.take(2).foreach(println)
}
// 结果
1
2
3.6 takeSample
3.6.1 概述
语法(java):
static java.util.List<T> takeSample(boolean withReplacement,
int num,
long seed)
说明:
和sample用法相同,只不第二个参数换成了个数。返回也不是RDD,而是collect。
3.6.2 Scala示例
def takeSample(sc: SparkContext): Unit = {
sc.parallelize(1 to 10)
.takeSample(withReplacement = false, 3, 1)
.foreach(println)
}
// 结果
1
8
10
3.7 takeOrdered
3.7.1 概述
语法(java):
java.util.List<T> takeOrdered(int num)
java.util.List<T> takeOrdered(int num,
java.util.Comparator<T> comp)
说明:
用于从RDD中,按照默认(升序)或指定排序规则,返回前num个元素。
3.7.2 Scala示例
def takeOrdered(sc: SparkContext): Unit = {
sc.parallelize(Array(5,6,2,1,7,8))
.takeOrdered(3)(new Ordering[Int](){
override def compare(x: Int, y: Int): Int = y.compareTo(x)
})
.foreach(println)
}
// 结果
8
7
6
3.8 saveAsTextFile
3.8.1 概述
语法(java):
void saveAsTextFile(String path)
void saveAsTextFile(String path,
Class<? extends org.apache.hadoop.io.compress.CompressionCodec> codec)
说明:
将RDD转换为文本内容并保存至路径path下,可能有多个文件(和partition数有关)。路径path可以是本地路径或HDFS地址,转换方法是对RDD成员调用toString函数
3.8.2 Scala示例
def saveAsTextFile(sc: SparkContext): Unit = {
sc.parallelize(Array(5,6,2,1,7,8))
.saveAsTextFile("/Users/zhangws/Documents/test")
}
// 结果
/Users/zhangws/Documents/test目录下
_SUCCESS
part-00000
// part-00000文件内容
5
6
2
1
7
8
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
3.9 saveAsSequenceFile
3.9.1 概述
语法(java):
def saveAsSequenceFile(path: String, codec: Option[Class[_ <: CompressionCodec]] = None): Unit
说明:
与saveAsTextFile类似,但以SequenceFile格式保存,成员类型必须实现Writeable接口或可以被隐式转换为Writable类型(比如基本Scala类型Int、String等)
示例略
3.10 saveAsObjectFile
3.10.1 概述
语法(java):
static void saveAsObjectFile(String path)
说明:
用于将RDD中的元素序列化成对象,存储到文件中。对于HDFS,默认采用SequenceFile保存。
示例略
3.11 countByKey
3.11.1 概述
语法(java):
java.util.Map<K,Long> countByKey()
说明:
仅适用于(K, V)类型,对key计数,返回(K, Int)
3.11.2 Scala示例
def reduce(sc: SparkContext): Unit = {
println(sc.parallelize(Array(("A", 1), ("B", 6), ("A", 2), ("C", 1), ("A", 7), ("A", 8)))
.countByKey())
}
Map(B -> 1, A -> 4, C -> 1)
3.12 foreach
3.12.1 概述
语法(java):
static void foreach(VoidFunction<T> f)
说明:
对RDD中的每个成员执行func,没有返回值,常用于更新计数器或输出数据至外部存储系统。这里需要注意变量的作用域
3.12.2 Java示例
forEach(System.out::println)
forEach(v -> System.out.println(v))
3.12.3 Scala示例
foreach(println)






















 3759
3759











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









