







1.时期的频率转换
Period和PeriodIndex对象都可以通过其asfreq方法被转换成别的频率。假设我们有一个年度时期,希望将其转换为当年年初或年末的一个月度时期
p=pd.Period('2007',freq='A-DEC')
print p.asfreq('M',how='start')
print p.asfreq('M',how='end')
结果为:
2007-01
2007-12
你可以将Period('2007',freq='A-DEC')看做一个被划分为多个月度时期的时间段中的游标。对于一个不以12月结束的财政年变,月度子时期的归属情况就不一样了
p=pd.Period('2007',freq='A-JUN')
print p.asfreq('M','start')
print p.asfreq('M','end')
结果为:
2006-07
2007-06
在将高频率转换为低频率时,超时期是由子时期所属的位置决定的。例如,在A-JUN频率中,月份2007年08月实际上是属于周期2008年的
p=pd.Period('2007-08','M')
print p.asfreq('A-JUN')
结果为:
2008
PeriodIndex或TimeSeries的频率转换方式也是如此
rng=pd.period_range('2006','2009',freq='A-DEC')
ts=Series(np.random.randn(len(rng)),index=rng)
print ts
结果为:
2006 0.802142
2007 -0.048446
2008 -1.459365
2009 -0.710186
Freq: A-DEC, dtype: float64
print ts.asfreq('M',how='start')
print ts.asfreq('B',how='end')
结果为:
2006-01 1.385962
2007-01 -0.293633
2008-01 -0.742163
2009-01 0.147614
Freq: M, dtype: float64
2006-12-29 1.385962
2007-12-31 -0.293633
2008-12-31 -0.742163
2009-12-31 0.147614
Freq: B, dtype: float64
2.按季度计算的时期频率
pandas支持12种可能的季度型频率,即Q-JAN到Q-DEC
p=pd.Period('2012Q4',freq='Q-JAN')
print p
结果为:
2012Q4
在以1月结束的财年中,2012Q4是从11月到1月(将其转换为日型频率就明白了),如下图
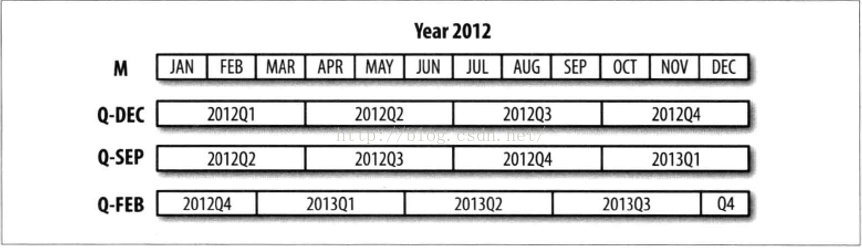
print p.asfreq('D','start')
print p.asfreq('D','end')
结果为:
2011-11-01
2012-01-31
因此,Period之间的算术运算会非常简单。例如,要获取该季度倒数第二个工作日下午4点的时间戳
p4pm=(p.asfreq('B','e')-1).asfreq('T','S')+16*60
print p4pm
print p4pm.to_timestamp()
结果为:
2012-01-30 16:00
2012-01-30 16:00:00
period_range还可用于生产季度型范围。
rng=pd.period_range('2011Q3','2012Q4',freq='Q-JAN')
ts=Series(np.arange(len(rng)),index=rng)
print ts
结果为:
2011Q3 0
2011Q4 1
2012Q1 2
2012Q2 3
2012Q3 4
2012Q4 5
Freq: Q-JAN, dtype: int32
new_rng=(rng.asfreq('B','e')-1).asfreq('T','S')+16*60
ts.index=new_rng.to_timestamp()
print ts
结果为:
2010-10-28 16:00:00 0
2011-01-28 16:00:00 1
2011-04-28 16:00:00 2
2011-07-28 16:00:00 3
2011-10-28 16:00:00 4
2012-01-30 16:00:00 5
dtype: int32
3.将Timestamp转换为Period(及其反向过程)
通过使用to_period方法,可以将由时间戳索引的Series和DataFrame对象转换为以时期索引:
rng=pd.date_range('1/1/2000',periods=3,freq='M')
ts=Series(np.random.randn(3),index=rng)
pts=ts.to_period()
print ts
print pts
结果为:
2000-01-31 0.301329
2000-02-29 -0.927125
2000-03-31 0.369884
Freq: M, dtype: float64
2000-01 0.301329
2000-02 -0.927125
2000-03 0.369884
Freq: M, dtype: float64
由于时期指的是非重叠时间区间,因此对于给定的频率,一个时间戳只能属于一个时期。新PeriodIndex的频率默认是从时间戳推断而来的,你也可以指定任何别的频率。结果中允许存在重复时期
rng=pd.date_range('1/29/2000',periods=6,freq='D')
ts2=Series(np.random.randn(6),index=rng)
print ts2.to_period('M')
结果为:
2000-01 0.591006
2000-01 0.326477
2000-01 -2.997369
2000-02 0.140095
2000-02 0.001204
2000-02 -0.276570
Freq: M, dtype: float64
要转换为时间戳,使用to_timestamp即可
pts=ts.to_period()
print pts
print pts.to_timestamp(how='end')
结果为:
2000-01 0.188389
2000-02 -0.967632
2000-03 -0.740213
Freq: M, dtype: float64
2000-01-31 0.188389
2000-02-29 -0.967632
2000-03-31 -0.740213
Freq: M, dtype: float64
4.通过数组创建PeriodIndex
固定频率的数据集通常会将时间信息分开存放在多个列中。如,在下面这个宏观经济数据集中,年度和季度就分别存放在不同的列中
data=pd.read_csv('macrodata.csv')
print data.year
print data.quarter
将这两个数组以及一个频率传入PeriodIndex,就可以将它们合并成DataFrame的一个索引
index=pd.PeriodIndex(year=data.year,quarter=data.quarter,freq='Q-DEC')
print index
data.index=index
print data.infl
结果为:
PeriodIndex(['1959Q1', '1959Q2', '1959Q3', '1959Q4', '1960Q1', '1960Q2',
'1960Q3', '1960Q4', '1961Q1', '1961Q2',
...
'2007Q2', '2007Q3', '2007Q4', '2008Q1', '2008Q2', '2008Q3',
'2008Q4', '2009Q1', '2009Q2', '2009Q3'],
dtype='int64', length=203, freq='Q-DEC')
1959Q1 0.00
1959Q2 2.34
1959Q3 2.74
1959Q4 0.27
1960Q1 2.31
1960Q2 0.14
1960Q3 2.70
1960Q4 1.21
1961Q1 -0.40
1961Q2 1.47
1961Q3 0.80
1961Q4 0.80
1962Q1 2.26
1962Q2 0.13
1962Q3 2.11
1962Q4 0.79
1963Q1 0.53
1963Q2 2.75
1963Q3 0.78
1963Q4 2.46
1964Q1 0.13
1964Q2 0.90
1964Q3 1.29
1964Q4 2.05
1965Q1 1.28
1965Q2 2.54
1965Q3 0.89
1965Q4 2.90
1966Q1 4.99
1966Q2 2.10
2002Q2 1.56
2002Q3 2.66
2002Q4 3.08
2003Q1 1.31
2003Q2 1.09
2003Q3 2.60
2003Q4 3.02
2004Q1 2.35
2004Q2 3.61
2004Q3 3.58
2004Q4 2.09
2005Q1 4.15
2005Q2 1.85
2005Q3 9.14
2005Q4 0.40
2006Q1 2.60
2006Q2 3.97
2006Q3 -1.58
2006Q4 3.30
2007Q1 4.58
2007Q2 2.75
2007Q3 3.45
2007Q4 6.38
2008Q1 2.82
2008Q2 8.53
2008Q3 -3.16
2008Q4 -8.79
2009Q1 0.94
2009Q2 3.37
2009Q3 3.56
Freq: Q-DEC, Name: infl, dtype: float64
5.重采样及频率转换
重采样指的是将时间序列从一个频率转换到另一个频率的处理过程。将高频率数据聚合到低频率称为降采样,而将低频率数据转换到高频率则称为升采样。并不是所有的重采样都能被划分到这两个大类中。
pandas对象都带有一个resample方法,它是各种频率转换工作的主力函数
rng=pd.date_range('1/1/2000',periods=100,freq='D')
ts=Series(np.random.randn(len(rng)),index=rng)
print ts.resample('M',how='mean')
print ts.resample('M',how='mean',kind='period')
结果为:
2000-01-31 -0.154671
2000-02-29 0.224220
2000-03-31 -0.242436
2000-04-30 0.291921
Freq: M, dtype: float64
2000-01 -0.154671
2000-02 0.224220
2000-03 -0.242436
2000-04 0.291921
Freq: M, dtype: float64

6.降采样
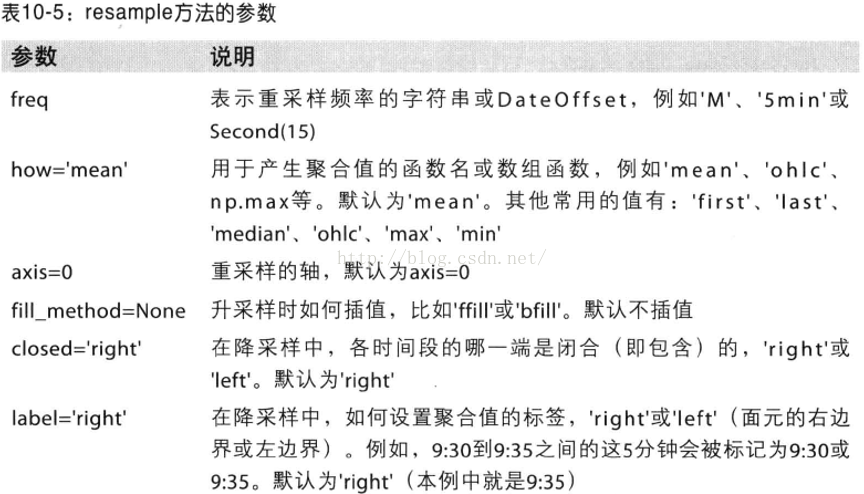
在用resample对数据进行降采样时,需要考虑两样东西:
a.各区间哪边是闭合的
b.如何标记各个聚合面元,用区间的开头还是末尾
首先,来看一些“1分钟”数据:
rng=pd.date_range('1/1/2000',periods=12,freq='T')
ts=Series(np.arange(12),index=rng)
print ts
结果为:
2000-01-01 00:00:00 0
2000-01-01 00:01:00 1
2000-01-01 00:02:00 2
2000-01-01 00:03:00 3
2000-01-01 00:04:00 4
2000-01-01 00:05:00 5
2000-01-01 00:06:00 6
2000-01-01 00:07:00 7
2000-01-01 00:08:00 8
2000-01-01 00:09:00 9
2000-01-01 00:10:00 10
2000-01-01 00:11:00 11
Freq: T, dtype: int32
假设你想通过求和的方式将这些数据聚合到“5分钟”块中
print ts.resample('5min',how='sum')
结果为:
2000-01-01 00:00:00 10
2000-01-01 00:05:00 35
2000-01-01 00:10:00 21
Freq: 5T, dtype: int32
传入的频率将会以“5分钟”的增量定义面元边界。默认情况下,面元的右边界是包含的,传入closed='left'会让区间以左边界闭合
print ts.resample('5min',how='sum',closed='left')
结果为:
2000-01-01 00:00:00 10
2000-01-01 00:05:00 35
2000-01-01 00:10:00 21
Freq: 5T, dtype: int32
传入label='left'即可用面元的左边界对其进行标记
print ts.resample('5min',how='sum',closed='left',label='left')
结果为:
2000-01-01 00:00:00 10
2000-01-01 00:05:00 35
2000-01-01 00:10:00 21
Freq: 5T, dtype: int32
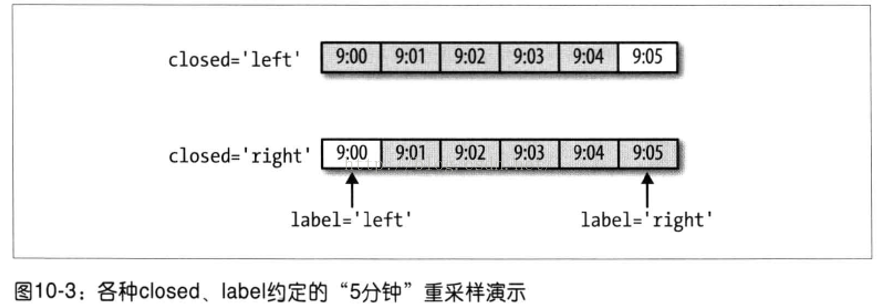
只需要通过loffset设置一个字符串或日期偏移量即可实现对结果索引做一些位移
print ts.resample('5min',how='sum',loffset='-1s')
结果为:
1999-12-31 23:59:59 10
2000-01-01 00:04:59 35
2000-01-01 00:09:59 21
Freq: 5T, dtype: int32
此外,也可以通过调用结果对象的shift方法来实现该目的,这样就不需要设置loffset了。
7.OHLC重采样
金融领域中有一种无所不在的时间序列聚合方式,计算各面元的四个值:第一个值(open,开盘),最后一个值(close,开盘),最大值(high,最高)以及最小值(low,最低)。传入how='ohlc'即可得到一个含有这四种聚合值的DataFrame
print ts.resample('5min',how='ohlc')
结果为:
open high low close
2000-01-01 00:00:00 0 4 0 4
2000-01-01 00:05:00 5 9 5 9
2000-01-01 00:10:00 10 11 10 11
8.通过groupby进行重采样
另一种降采样的办法是使用pandas的groupby功能。如,打算根据月份或星期几进行分组,只需传入一个能够访问时间序列的索引上的这些字段的函数即可
rng=pd.date_range('1/1/2000',periods=100,freq='D')
ts=Series(np.arange(100),index=rng)
print ts
print ts.groupby(lambda x:x.month).mean()
print ts.groupby(lambda x:x.weekday).mean()
结果为:
2000-01-01 0
2000-01-02 1
2000-01-03 2
2000-01-04 3
2000-01-05 4
2000-01-06 5
2000-01-07 6
2000-01-08 7
2000-01-09 8
2000-01-10 9
2000-01-11 10
2000-01-12 11
2000-01-13 12
2000-01-14 13
2000-01-15 14
2000-01-16 15
2000-01-17 16
2000-01-18 17
2000-01-19 18
2000-01-20 19
2000-01-21 20
2000-01-22 21
2000-01-23 22
2000-01-24 23
2000-01-25 24
2000-01-26 25
2000-01-27 26
2000-01-28 27
2000-01-29 28
2000-01-30 29
..
2000-03-11 70
2000-03-12 71
2000-03-13 72
2000-03-14 73
2000-03-15 74
2000-03-16 75
2000-03-17 76
2000-03-18 77
2000-03-19 78
2000-03-20 79
2000-03-21 80
2000-03-22 81
2000-03-23 82
2000-03-24 83
2000-03-25 84
2000-03-26 85
2000-03-27 86
2000-03-28 87
2000-03-29 88
2000-03-30 89
2000-03-31 90
2000-04-01 91
2000-04-02 92
2000-04-03 93
2000-04-04 94
2000-04-05 95
2000-04-06 96
2000-04-07 97
2000-04-08 98
2000-04-09 99
Freq: D, dtype: int32
1 15
2 45
3 75
4 95
dtype: int32
0 47.5
1 48.5
2 49.5
3 50.5
4 51.5
5 49.0
6 50.0
dtype: float64
9.升采样和插值
在将数据从低频率转换到高频率时,就不需要聚合了。
frame=DataFrame(np.random.randn(2,4),
index=pd.date_range('1/1/2000',periods=2,freq='W-WED'),
columns=['Colorado','Texas','New York','Ohio'])
print frame
结果为:
Colorado Texas New York Ohio
2000-01-05 2.168729 0.408150 -1.268413 1.882155
2000-01-12 0.695996 0.981071 0.678594 -0.526727
将其重采样到日频率,默认会引入缺失值
df_daily=frame.resample('D')
print df_daily
结果为:
Colorado Texas New York Ohio
2000-01-05 0.135424 0.551593 -0.777373 -0.233382
2000-01-06 NaN NaN NaN NaN
2000-01-07 NaN NaN NaN NaN
2000-01-08 NaN NaN NaN NaN
2000-01-09 NaN NaN NaN NaN
2000-01-10 NaN NaN NaN NaN
2000-01-11 NaN NaN NaN NaN
2000-01-12 -0.563044 -0.312367 0.601868 1.742242
假设你想要用前面的周型值填充“非星期三”。resampling的值填充和插值方式跟fillna和reindex的一样
print frame.resample('D',fill_method='ffill')
结果为:
Colorado Texas New York Ohio
2000-01-05 0.457819 2.660074 1.196789 -0.582404
2000-01-06 0.457819 2.660074 1.196789 -0.582404
2000-01-07 0.457819 2.660074 1.196789 -0.582404
2000-01-08 0.457819 2.660074 1.196789 -0.582404
2000-01-09 0.457819 2.660074 1.196789 -0.582404
2000-01-10 0.457819 2.660074 1.196789 -0.582404
2000-01-11 0.457819 2.660074 1.196789 -0.582404
2000-01-12 1.878784 -1.368375 0.484410 -0.698291
同样,这里也可以只填充指定的时期数(目的是限制前面的观测值的持续使用距离)
print frame.resample('D',fill_method='ffill',limit=2)
结果为:
Colorado Texas New York Ohio
2000-01-05 -1.139258 -0.181188 0.669716 1.250018
2000-01-06 -1.139258 -0.181188 0.669716 1.250018
2000-01-07 -1.139258 -0.181188 0.669716 1.250018
2000-01-08 NaN NaN NaN NaN
2000-01-09 NaN NaN NaN NaN
2000-01-10 NaN NaN NaN NaN
2000-01-11 NaN NaN NaN NaN
2000-01-12 -1.318581 0.503518 1.852005 0.378236
新的日期索引完全没必要跟旧的相交
print frame.resample('W-THU',fill_method='ffill')
结果为:
Colorado Texas New York Ohio
2000-01-06 2.113687 0.315481 2.523027 0.609636
2000-01-13 -1.376797 -1.087075 -0.647194 -0.111042
10.通过日期进行重采样
frame=DataFrame(np.random.randn(24,4),
index=pd.period_range('1-2000','12-2001',freq='M'),
columns=['Colorado','Texas','New York','Ohio'])
print frame[:5]
结果为:
Colorado Texas New York Ohio
2000-01 0.119422 0.495024 1.729524 0.633504
2000-02 -1.222105 1.802419 1.167525 1.868474
2000-03 -1.211917 -0.367331 0.834356 -0.984967
2000-04 -0.708925 0.561091 -0.707988 0.809059
2000-05 0.437332 0.315616 0.175065 0.364923
annual_frame=frame.resample('A-DEC',how='mean')
print annual_frame
结果为:
Colorado Texas New York Ohio
2000 -0.326572 0.079417 0.101661 -0.194386
2001 0.228762 -0.290425 -0.674494 0.318449
升样要稍微麻烦一些,因为你必须决定在新频率中各区间的哪端用于放置原来的值,就像asfreq方法那样。convention参数默认为'end',可设置为’start‘
#Q-DEC:季度型(每年以12月结束)
print annual_frame.resample('Q-DEC',fill_method='ffill')
print annual_frame.resample('Q-DEC',fill_method='ffill',convention='start')
结果为:
Colorado Texas New York Ohio
2000Q1 0.055982 0.000586 -0.229527 -0.321558
2000Q2 0.055982 0.000586 -0.229527 -0.321558
2000Q3 0.055982 0.000586 -0.229527 -0.321558
2000Q4 0.055982 0.000586 -0.229527 -0.321558
2001Q1 -0.095915 -0.363507 -0.035557 0.186972
2001Q2 -0.095915 -0.363507 -0.035557 0.186972
2001Q3 -0.095915 -0.363507 -0.035557 0.186972
2001Q4 -0.095915 -0.363507 -0.035557 0.186972
Colorado Texas New York Ohio
2000Q1 0.055982 0.000586 -0.229527 -0.321558
2000Q2 0.055982 0.000586 -0.229527 -0.321558
2000Q3 0.055982 0.000586 -0.229527 -0.321558
2000Q4 0.055982 0.000586 -0.229527 -0.321558
2001Q1 -0.095915 -0.363507 -0.035557 0.186972
2001Q2 -0.095915 -0.363507 -0.035557 0.186972
2001Q3 -0.095915 -0.363507 -0.035557 0.186972
2001Q4 -0.095915 -0.363507 -0.035557 0.186972
生采样和降采样的规则:
a.在降采样中,目标频率必须是源频率的子时期
b.在升采样中,目标频率必须是源频率的超时期
由Q-MAR定义的时间区间只能生采样为A-MAR,A-JUN,A-SEP,A-DEC等
print annual_frame.resample('Q-MAR',fill_method='ffill')
结果为:
Colorado Texas New York Ohio
2000Q4 -0.288411 -0.340895 0.235046 0.073330
2001Q1 -0.288411 -0.340895 0.235046 0.073330
2001Q2 -0.288411 -0.340895 0.235046 0.073330
2001Q3 -0.288411 -0.340895 0.235046 0.073330
2001Q4 -0.396545 0.510345 0.167587 0.256141
2002Q1 -0.396545 0.510345 0.167587 0.256141
2002Q2 -0.396545 0.510345 0.167587 0.256141
2002Q3 -0.396545 0.510345 0.167587 0.256141
11.时间序列绘图
从Yahoo!Finance下载了几只美国股票的一些价格数据
close_px_all=pd.read_csv('stock_px.csv',parse_dates=True,index_col=0)
close_px=close_px_all[['AAPL','MSFT','XOM']]
close_px=close_px.resample('B',fill_method='ffill')
print close_px
结果为:
AAPL MSFT XOM
2003-01-02 7.40 21.11 29.22
2003-01-03 7.45 21.14 29.24
2003-01-06 7.45 21.52 29.96
2003-01-07 7.43 21.93 28.95
2003-01-08 7.28 21.31 28.83
2003-01-09 7.34 21.93 29.44
2003-01-10 7.36 21.97 29.03
2003-01-13 7.32 22.16 28.91
2003-01-14 7.30 22.39 29.17
2003-01-15 7.22 22.11 28.77
2003-01-16 7.31 21.75 28.90
2003-01-17 7.05 20.22 28.60
2003-01-20 7.05 20.22 28.60
2003-01-21 7.01 20.17 27.94
2003-01-22 6.94 20.04 27.58
2003-01-23 7.09 20.54 27.52
2003-01-24 6.90 19.59 26.93
2003-01-27 7.07 19.32 26.21
2003-01-28 7.29 19.18 26.90
2003-01-29 7.47 19.61 27.88
2003-01-30 7.16 18.95 27.37
2003-01-31 7.18 18.65 28.13
2003-02-03 7.33 19.08 28.52
2003-02-04 7.30 18.59 28.52
2003-02-05 7.22 18.45 28.11
2003-02-06 7.22 18.63 27.87
2003-02-07 7.07 18.30 27.66
2003-02-10 7.18 18.62 27.87
2003-02-11 7.18 18.25 27.67
2003-02-12 7.20 18.25 27.12
... ... ...
2011-09-05 374.05 25.80 72.14
2011-09-06 379.74 25.51 71.15
2011-09-07 383.93 26.00 73.65
2011-09-08 384.14 26.22 72.82
2011-09-09 377.48 25.74 71.01
2011-09-12 379.94 25.89 71.84
2011-09-13 384.62 26.04 71.65
2011-09-14 389.30 26.50 72.64
2011-09-15 392.96 26.99 74.01
2011-09-16 400.50 27.12 74.55
2011-09-19 411.63 27.21 73.70
2011-09-20 413.45 26.98 74.01
2011-09-21 412.14 25.99 71.97
2011-09-22 401.82 25.06 69.24
2011-09-23 404.30 25.06 69.31
2011-09-26 403.17 25.44 71.72
2011-09-27 399.26 25.67 72.91
2011-09-28 397.01 25.58 72.07
2011-09-29 390.57 25.45 73.88
2011-09-30 381.32 24.89 72.63
2011-10-03 374.60 24.53 71.15
2011-10-04 372.50 25.34 72.83
2011-10-05 378.25 25.89 73.95
2011-10-06 377.37 26.34 73.89
2011-10-07 369.80 26.25 73.56
2011-10-10 388.81 26.94 76.28
2011-10-11 400.29 27.00 76.27
2011-10-12 402.19 26.96 77.16
2011-10-13 408.43 27.18 76.37
2011-10-14 422.00 27.27 78.11
[2292 rows x 3 columns]
runfile('F:/python代码/shuju/date4.py', wdir='F:/python代码/shuju')
AAPL MSFT XOM
2003-01-02 7.40 21.11 29.22
2003-01-03 7.45 21.14 29.24
2003-01-06 7.45 21.52 29.96
2003-01-07 7.43 21.93 28.95
2003-01-08 7.28 21.31 28.83
2003-01-09 7.34 21.93 29.44
2003-01-10 7.36 21.97 29.03
2003-01-13 7.32 22.16 28.91
2003-01-14 7.30 22.39 29.17
2003-01-15 7.22 22.11 28.77
2003-01-16 7.31 21.75 28.90
2003-01-17 7.05 20.22 28.60
2003-01-20 7.05 20.22 28.60
2003-01-21 7.01 20.17 27.94
2003-01-22 6.94 20.04 27.58
2003-01-23 7.09 20.54 27.52
2003-01-24 6.90 19.59 26.93
2003-01-27 7.07 19.32 26.21
2003-01-28 7.29 19.18 26.90
2003-01-29 7.47 19.61 27.88
2003-01-30 7.16 18.95 27.37
2003-01-31 7.18 18.65 28.13
2003-02-03 7.33 19.08 28.52
2003-02-04 7.30 18.59 28.52
2003-02-05 7.22 18.45 28.11
2003-02-06 7.22 18.63 27.87
2003-02-07 7.07 18.30 27.66
2003-02-10 7.18 18.62 27.87
2003-02-11 7.18 18.25 27.67
2003-02-12 7.20 18.25 27.12
... ... ...
2011-09-05 374.05 25.80 72.14
2011-09-06 379.74 25.51 71.15
2011-09-07 383.93 26.00 73.65
2011-09-08 384.14 26.22 72.82
2011-09-09 377.48 25.74 71.01
2011-09-12 379.94 25.89 71.84
2011-09-13 384.62 26.04 71.65
2011-09-14 389.30 26.50 72.64
2011-09-15 392.96 26.99 74.01
2011-09-16 400.50 27.12 74.55
2011-09-19 411.63 27.21 73.70
2011-09-20 413.45 26.98 74.01
2011-09-21 412.14 25.99 71.97
2011-09-22 401.82 25.06 69.24
2011-09-23 404.30 25.06 69.31
2011-09-26 403.17 25.44 71.72
2011-09-27 399.26 25.67 72.91
2011-09-28 397.01 25.58 72.07
2011-09-29 390.57 25.45 73.88
2011-09-30 381.32 24.89 72.63
2011-10-03 374.60 24.53 71.15
2011-10-04 372.50 25.34 72.83
2011-10-05 378.25 25.89 73.95
2011-10-06 377.37 26.34 73.89
2011-10-07 369.80 26.25 73.56
2011-10-10 388.81 26.94 76.28
2011-10-11 400.29 27.00 76.27
2011-10-12 402.19 26.96 77.16
2011-10-13 408.43 27.18 76.37
2011-10-14 422.00 27.27 78.11
[2292 rows x 3 columns]
对其中任意一列调用plot即可生成一张简单的图表
close_px['AAPL'].plot()
当对DataFrame调用plot时,所有时间序列都会被绘制在一个subplot上,并有一个图例说明哪个是哪个,这里只绘制了2009年的数据
close_px.ix['2009'].plot()
展示苹果公司在2011年1月到3月间的每日股价
close_px['AAPL'].ix['01-2011':'03-2011'].plot()
季度型频率的数据会用季度标记进行格式化
appl_q=close_px['AAPL'].resample('Q-DEC',fill_method='ffill')
appl_q.ix['2009':].plot()
12.移动窗口函数
在移动窗口(可以带有指数衰减权数)上计算的各种统计函数也是一类常见于时间序列的数组变换。将它称为移动窗口函数,其中还包括那些窗口不定长的函数(如指数加权移动平均),移动函数会自动排除缺失值。
rolling_mean是其中最简单的一个。它接受一个TimeSeries或DataFrame以及一个window(表示期数)
close_px.AAPL.plot()
pd.rolling_mean(close_px.AAPL,250).plot()
appl_std250=pd.rolling_std(close_px.AAPL,250,min_periods=10)
print appl_std250[5:12]
结果为:
2003-01-09 NaN
2003-01-10 NaN
2003-01-13 NaN
2003-01-14 NaN
2003-01-15 0.077496
2003-01-16 0.074760
2003-01-17 0.112368
Freq: B, Name: AAPL, dtype: float64
appl_std250.plot()
要计算扩展窗口平均,你可以将扩展窗口看做一个特殊的窗口,其长度与实践序列一样,但只需一期(或多期)即可计算一个值
#通过rolling_mean定义扩展平均
expanding_mean=lambda x:rolling_mean(x,len(x),min_periods=1)
对DataFrame调用rolling_mean(以及与之类似的函数)会将转换应用到所有的列上
pd.rolling_mean(close_px,60).plot(logy=True)

13.指数加权函数

下面这个例子对比了苹果公司股价的60日移动平均和span=60的指数加权移动平均
fig,axes=plt.subplots(nrows=2,ncols=1,sharex=True,sharey=True,figsize=(12,7))
aapl_px=close_px.AAPL['2005':'2009']
ma60=pd.rolling_mean(aapl_px,60,min_periods=50)
ewma60=pd.ewma(aapl_px,span=60)
aapl_px.plot(style='k-',ax=axes[0])
ma60.plot(style='k--',ax=axes[0])
aapl_px.plot(style='k-',ax=axes[1])
ewma60.plot(style='k--',ax=axes[1])
axes[0].set_title('Simple MA')
axes[1].set_title('Exponentially-weighted MA')
14.二元移动窗口函数
有些统计计算(如相关系数和协方差)需要在两个时间序列上执行,如果对某只股票对某个参数指数(如标准普尔500指数)的相关系数感兴趣,我们可以通过计算百分数变化并使用rolling_corr的方式得到该结果
spx_px=close_px_all['SPX']
spx_rets=spx_px/spx_px.shift(1)-1
returns=close_px.pct_change()
corr=pd.rolling_corr(returns.AAPL,spx_rets,125,min_periods=100)
corr.plot()
想要一次性计算多只股票与标准普尔500指数的相关系数,只需传入一个TimeSeries和一个DataFrame,rolling_corr就会自动计算TimeSeries(本例中就是spx_rets)与DataFrame各列的相关系数
corr=pd.rolling_corr(returns,spx_rets,125,min_periods=100)
corr.plot()
15.用户定义的移动窗口函数

AAPL2%回报率的百分等级(一年窗口期)
score_at_2percent=lambda x:percentileofscore(x,0.02)
result=pd.rolling_apply(returns.AAPL,250,score_at_2percent)
result.plot()
16.性能和内存使用方面的注意事项

rng=pd.date_range('1/1/2000',periods=10000000,freq='10ms')
ts=Series(np.random.randn(len(rng)),index=rng)
print ts
print ts.resample('15min',how='ohlc')














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









