







计算图模型

1. 下载midi文件
下载midi格式音乐的网站:freemidi.org
2.创建NoteSequences
即创建旋律数据库,将MIDI集合转化为NoteSequences。(NoteSequences是协议缓冲区,它是一种快速有效的数据格式,并且比MIDI文件更易于使用)
INPUT_DIRECTORY=/Users/mac/Desktop/MIDI
SEQUENCES_TFRECORD=/Users/mac/Desktop/train/notesequences.tfrecord
convert_dir_to_note_sequences\
--input_dir=$INPUT_DIRECTORY \
--output_file=$SEQUENCES_TFRECORD \
--recursive注意:路径中不能有空格
显示如下图则操作成功:

(magenta)zhu-Macs-MacBook-Pro:magenta zhujianing$INPUT_DIRECTORY=/Users/mac/Desktop/MIDI
(magenta)zhu-Macs-MacBook-Pro:magenta zhujianing$ # TFRecord file that will containNoteSequence protocol buffers.
(magenta)zhu-Macs-MacBook-Pro:magenta zhujianing$SEQUENCES_TFRECORD=/Users/mac/Desktop/train/notesequences.tfrecord
(magenta)zhu-Macs-MacBook-Pro:magenta zhujianing$
(magenta)zhu-Macs-MacBook-Pro:magenta zhujianing$ convert_dir_to_note_sequences \
> --input_dir=$INPUT_DIRECTORY \
> --output_file=$SEQUENCES_TFRECORD \
> --recursive
INFO:tensorflow:Convertingfiles in '/Users/mac/Desktop/MIDI/'.
/Users/mac/miniconda2/envs/magenta/lib/python2.7/site-packages/pretty_midi/pretty_midi.py:100:RuntimeWarning: Tempo, Key or Time signature change events found on non-zerotracks. This is not a valid type 0 ortype 1 MIDI file. Tempo, Key or TimeSignature may be wrong.
RuntimeWarning)
INFO:tensorflow:Converted70 files in '/Users/mac/Desktop/MIDI/'.
INFO:tensorflow:Could not parse 0 files.
INFO:tensorflow:Wrote70 NoteSequence protos to '/Users/mac/Desktop/train/notesequences.tfrecord'
(magenta)zhu-Macs-MacBook-Pro:magenta zhujianing$3.创建SequenceExamples
SequenceExamples被提供给模型用来训练和评估。每个SequenceExample包含一个输入序列和代表一个旋律的一系列标签。下面的命令是从NoteSequences中提取旋律,并将它们保存为SequenceExamples。将生成两个SequenceExamples集合,一个用于训练,另一个用于评估,其中评估集中SequenceExamples的分数由-eval_ratio确定。评估率为0.10,提取的旋律的10%将保存在评估系统中,90%将被保存在训练集中。
代码:
melody_rnn_create_dataset\
--config=lookback_rnn\
--input=/Users/mac/Desktop/train/notesequences.tfrecord\
--output_dir=/Users/mac/Desktop/train/melody_rnn/sequence_examples\
--eval_ratio=0.10代码运行后生成的文件

显示如下图则操作成功:
(magenta)zhu-Macs-MacBook-Pro:magenta zhujianing$ melody_rnn_create_dataset \
>--config=lookback_rnn \
>--input=/Users/mac/Desktop/train/notesequences.tfrecord \
>--output_dir=/Users/mac/Desktop/train/melody_rnn/sequence_examples \
>--eval_ratio=0.10
INFO:tensorflow:
Completed.
INFO:tensorflow:Processed70 inputs total. Produced 264 outputs.
INFO:tensorflow:DAGPipeline_MelodyExtractor_eval_melodies_discarded_too_few_pitches:4
INFO:tensorflow:DAGPipeline_MelodyExtractor_eval_melodies_discarded_too_long:0
INFO:tensorflow:DAGPipeline_MelodyExtractor_eval_melodies_discarded_too_short:40
INFO:tensorflow:DAGPipeline_MelodyExtractor_eval_melodies_truncated:2
INFO:tensorflow:DAGPipeline_MelodyExtractor_eval_melody_lengths_in_bars:
[7,8): 1
[8,10): 1
[10,20): 6
[20,30): 3
[30,40): 1
INFO:tensorflow:DAGPipeline_MelodyExtractor_eval_polyphonic_tracks_discarded:34
INFO:tensorflow:DAGPipeline_MelodyExtractor_training_melodies_discarded_too_few_pitches:87
INFO:tensorflow:DAGPipeline_MelodyExtractor_training_melodies_discarded_too_long:0
INFO:tensorflow:DAGPipeline_MelodyExtractor_training_melodies_discarded_too_short:1001
INFO:tensorflow:DAGPipeline_MelodyExtractor_training_melodies_truncated:54
INFO:tensorflow:DAGPipeline_MelodyExtractor_training_melody_lengths_in_bars:
[7,8): 38
[8,10): 28
[10,20): 92
[20,30): 39
[30,40): 52
[40,50): 3
INFO:tensorflow:DAGPipeline_MelodyExtractor_training_polyphonic_tracks_discarded:744
INFO:tensorflow:DAGPipeline_RandomPartition_eval_melodies_count:4
INFO:tensorflow:DAGPipeline_RandomPartition_training_melodies_count:66
(magenta)zhu-Macs-MacBook-Pro:magenta zhujianing$4.训练并测试模型
melody_rnn_train\
--config=lookback_rnn\
--run_dir=/Users/mac/Desktop/train/melody_rnn/logdir/run1\
--sequence_example_file=/Users/mac/Desktop/train/melody_rnn/sequence_examples/training_melodies.tfrecord\
--hparams="{'batch_size':64,'rnn_layer_sizes':[64,64]}"\
--num_training_steps=200005. 根据开头给定的旋律给出midi格式音乐
melody_rnn_generate\
--config=lookback_rnn\
--run_dir=/Users/mac/Desktop/train/melody_rnn/logdir/run1\
--output_dir=/Users/mac/Desktop/train/melody_rnn/generated\
--num_outputs=10\
--num_steps=512\
--hparams="{'batch_size':64,'rnn_layer_sizes':[64,64]}"\
--primer_midi=/Users/mac/Desktop/MIDI/21Guns.mid播放midi文件方式
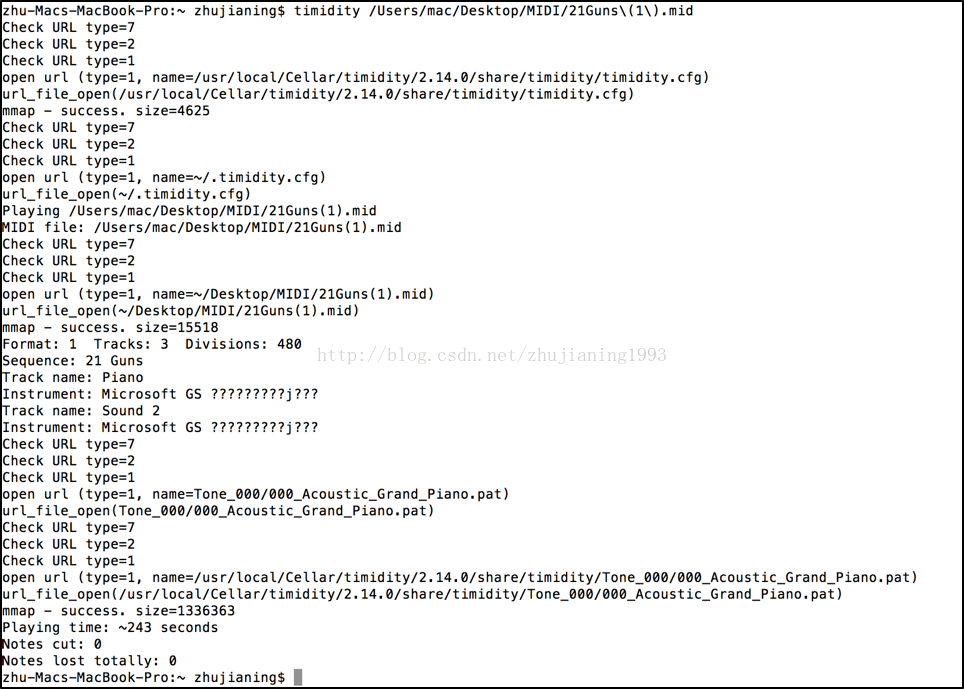
$ brew install timidity
$timidity /Users/mac/Desktop/MIDI/21Guns\(1\).mid结果如下图就可以成功播放mid文件了。














 1981
1981











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









