







分片集群是指将数据横向拆分,将一个数据服务器上将数据依据一定的规则分散到多台服务器上。以降低单台服务器的访问压力,提高数据服务的性能。几乎所有的数据库系统都能够手动进行分片,但是这在路由管理上,以及各个分片的管理上都相对困难。MongoDb支持自动分片,就可以摆脱手动分片管理困难的问题。集群自动切分数据,达到负载均衡。下面就详细的做一些介绍。
总结:MongoDb的分片使用配置上因其是内置的不需要手动分片,因此使用上是相对简单的。本篇博客先做一个简要的介绍后续会有具体的搭建实现。
简介
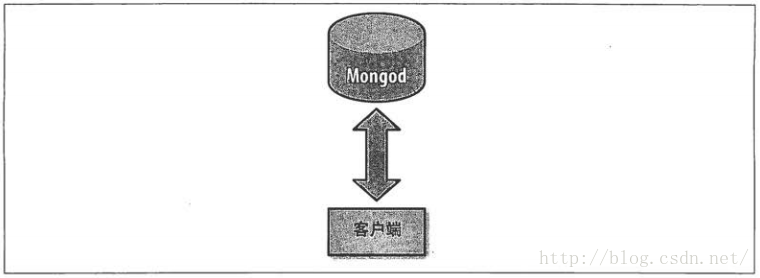
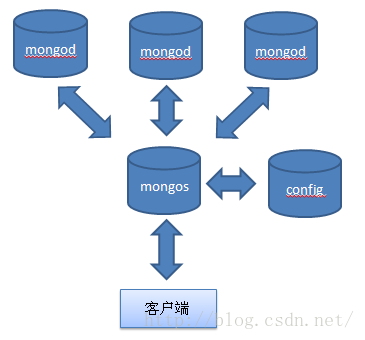
MongoDb分片的基本思想是将集合切分成小块,这些块分散到若干片里面,每个片负责总数居的一部分。这对应用程序来说是透明的,应用程序不必知道数据对应存储的片是哪一个,甚至不需要知道数据已经被拆分了。所以分片集群需要提供一个对分片集群的统一访问入口,即路由进程:mongos。所有分片的信息由该路由来维护。下面是分片和没有分片的结构图(图一:来自《MongoDB权威指南中文版》;图二:来自http://www.cnblogs.com/magialmoon/archive/2013/04/11/3015394.html):- 未分片:
- 分片:
分片原则——片键:
片键的选择在分片的集群上是非常重要的,它是数据切分的依据。也是访问数据库时的路由依据。片键的选择应该考虑分片以后对以下三个方面的影响:1.读和写的分布
其中最重要的一点是读和写的分布。如果你总是朝一台机器写,那么这台机器将会成为写瓶颈,则你的集群的写性能将会降低。这无关乎你的集群有多少个节点,因为所有的写操作都只在一个地方进行。因此,你不应该使用单调递增的id或时间戳作为片键,这样将会导致你一直往最后一个副本集中添加数据。相类似的是如果你的读操作一直都在同一个副本集上,那么你最好祈求你的任务能在机器内存所能承受的范围之内。通过副本集将读请求划分开能够使你的工作数据集大小随着分片数线性扩展。这样的话你能够将负载压力均分到各台机器的内存和磁盘之上。
2.数据块的大小
其次是数据块的大小。MongoDB能够将大的数据块划分成更小的,但这种情况仅仅在片键不同的情况下发生。如果你有巨量的数据文档都使用了同样的片键,那么你相应的会得到巨大的数据块。出现巨大块是非常不好的,不仅仅因为它会导致数据的不平均分布,还因为一旦这个数据块的大小超过某个值,那么你就不能够在分片之间移动它了。3.每个查询命中的分片数目
最后一点,如果能够保证大部分的查询请求都能够命中尽可能少的分片那就最好了。对于一个查询请求来说,其延迟直接取决于最慢的那个命中服务器的延迟;所以你命中的分片越少,那么理论上来说查询将会越快。这一点并不是硬性的规定,不过如果能够做到充分考虑那么应该是很有利的。因为数据块在分片上的分布仅仅是近似的遵循片键的顺序,而并不是严格的强制指定。片的健壮性
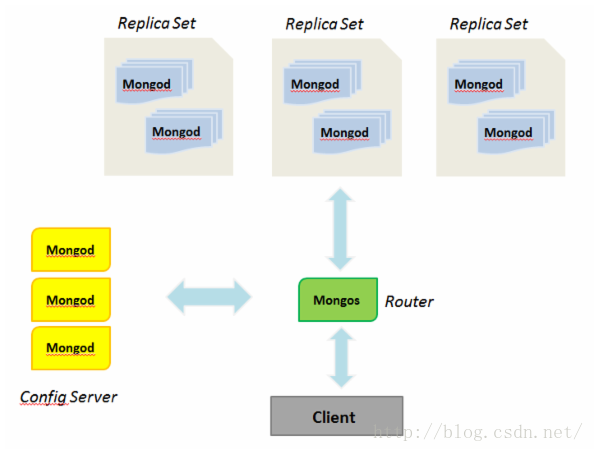
MongoDb做了分片集群以后,每个片存储了一部分数据,即所有的片的数据的集合才是完整的数据。因此,有必要考虑到每个片的健壮性问题,因为,一旦某个片宕机了那就影响数据服务。那么,增加片的健壮性可以通过我们上一篇博客降到的腹直集来做。也就是说每个片都一个复制集,如下图所示(图片:引用自http://www.52ml.net/tags/MongoDB):
总结:MongoDb的分片使用配置上因其是内置的不需要手动分片,因此使用上是相对简单的。本篇博客先做一个简要的介绍后续会有具体的搭建实现。














 178
178











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









