







要了解ES首先就要弄清楚下面的几个概念,这样也不会对ES产生一些误解:
1 近实时
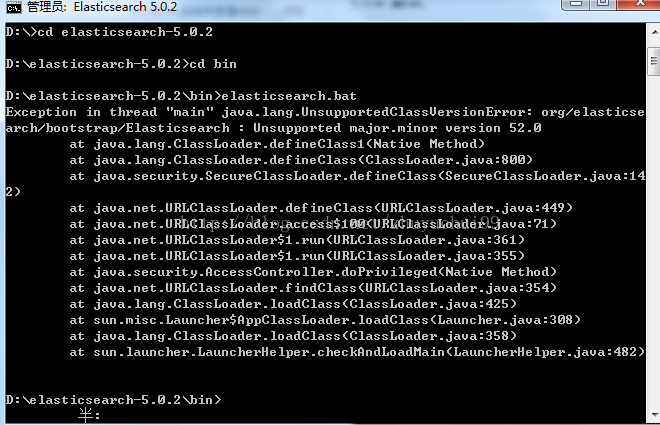
ES并不是一个标准的数据库,它不像MongoDB,它侧重于对存储的数据进行搜索。因此要注意到它 不是 实时读写 的,这也就意味着,刚刚存储的数据,并不能马上查询到。
当然这里还要区分查询的方式,ES也有数据的查询以及搜索,这里的近实时强调的是搜索....
2 集群
在ES中,对用户来说集群是很透明的。你只需要指定一个集群的名字(默认是elasticsearch),启动的时候,凡是集群是这个名字的,都会默认加入到一个集群中。
你不需要做任何操作,选举或者管理都是自动完成的。
对用户来说,仅仅是一个名字而已!
3 节点
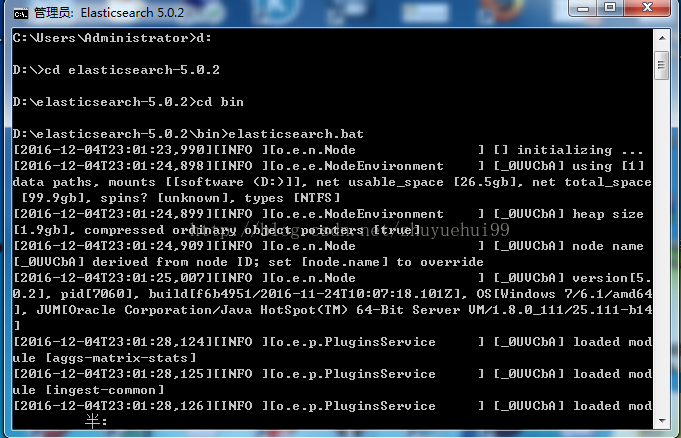
跟集群的概念差不多,ES启动时会设置这个节点的名字,一个节点也就是一个ES得服务器。
默认会自动生成一个名字,这个名字在后续的集群管理中还是很有作用的,因此如果想要手动的管理或者查看一些集群的信息,最好是自定义一下节点的名字。
4 索引
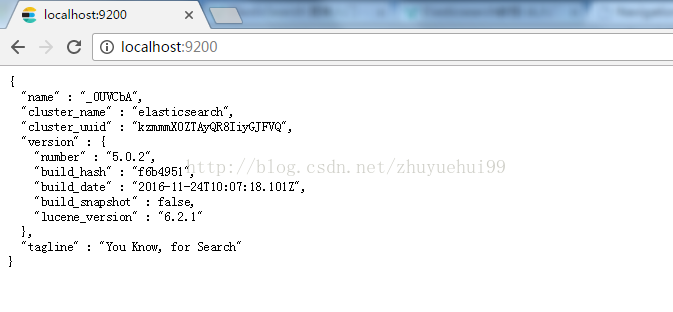
索引是一类文档的集合,所有的操作比如索引(索引数据)、搜索、分析都是基于索引完成的。
在一个集群中,可以定义任意数量的索引。
5 类型
类型可以理解成一个索引的逻辑分区,用于标识不同的文档字段信息的集合。但是由于ES还是以索引为粗粒度的单位,因此一个索引下的所有的类型,都存放在一个索引下。这也就导致不同类型相同字段名字的字段会存在类型定义冲突的问题。
在2.0之前的版本,是可以插入但是不能搜索;在2.0之后的版本直接做了插入检查,禁止字段类型冲突。
6 文档
文档是存储数据信息的基本单元,使用json来表示。
7 分片与备份
在ES中,索引会备份成分片,每个分片是独立的lucene索引,可以完成搜索分析存储等工作。
分片的好处:
1 如果一个索引数据量很大,会造成硬件硬盘和搜索速度的瓶颈。如果分成多个分片,分片可以分摊压力。
2 分片允许用户进行水平的扩展和拆分
3 分片允许分布式的操作,可以提高搜索以及其他操作的效率
拷贝一份分片就完成了分片的备份,那么备份有什么好处呢?
1 当一个分片失败或者下线时,备份的分片可以代替工作,提高了高可用性。
2 备份的分片也可以执行搜索操作,分摊了搜索的压力。
ES默认在创建索引时会创建5个分片,这个数量可以修改。
不过需要注意:
1 分片的数量只能在创建索引的时候指定,不能在后期修改
2 备份的数量可以动态的定义
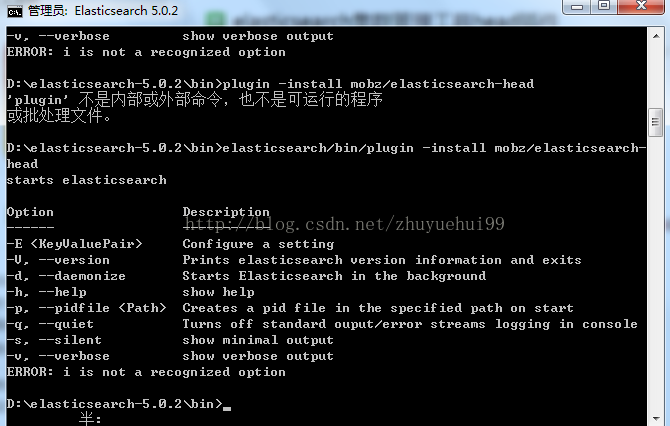
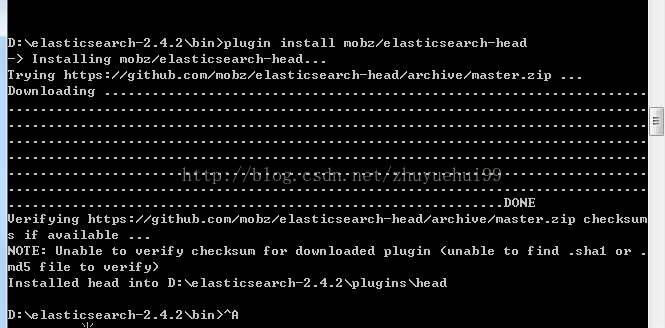
plugin install mobz/elasticsearch-head

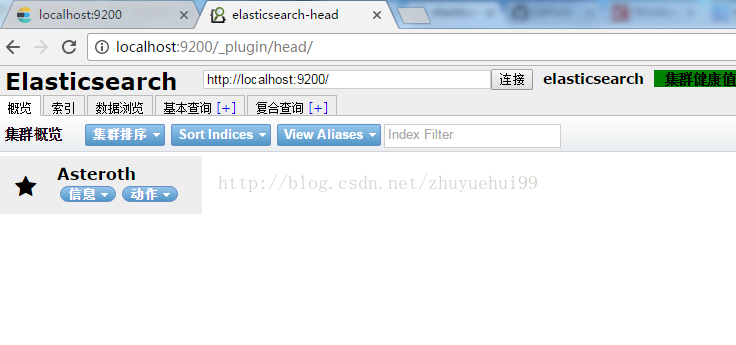
关闭elasticsearch.bat,将下载下来的压缩文件解压,在ES目录中的plugins文件夹里新建名为ik的文件夹,将解压得到的所有文件复制到ik中。
将plugin-descriptor.properties文件中的2.4.1改为2.4.2。这是因为1.10.1版本的ik分词器是为2.4.1版本的ES设计的,如果不改这一项启动elasticsearch.bat的时候会抛出异常。笔者没有测试过5.0版本的ik能否用于2.4版本的ES。
在config文件夹中的elasticsearch.yml文件的最后加上index.analysis.analyzer.ik.type : "ik"














 1801
1801











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









