






关于Batch Normalization,个人看到的目前最好的两篇博客:
- http://blog.csdn.net/hjimce/article/details/50866313
- https://kratzert.github.io/2016/02/12/understanding-the-gradient-flow-through-the-batch-normalization-layer.html
总结一下Batch Normalization的好处:
- 你可以选择比较大的初始学习率,让你的训练速度飙涨。以前还需要慢慢调整学习率,甚至在网络训练到一半的时候,还需要想着学习率进一步调小的比例选择多少比较合适,现在我们可以采用初始很大的学习率,然后学习率的衰减速度也很大,因为这个算法收敛很快。当然这个算法即使你选择了较小的学习率,也比以前的收敛速度快,因为它具有快速训练收敛的特性;
- 你再也不用去理会过拟合中drop out、L2正则项参数的选择问题,采用BN算法后,你可以移除这两项了参数,或者可以选择更小的L2正则约束参数了,因为BN具有提高网络泛化能力的特性;
- 再也不需要使用使用局部响应归一化层了(局部响应归一化是Alexnet网络用到的方法,搞视觉的估计比较熟悉),因为BN本身就是一个归一化网络层;
- 可以把训练数据彻底打乱(防止每批训练的时候,某一个样本都经常被挑选到,文献说这个可以提高1%的精度,这句话我也是百思不得其解啊)。
Batch Normalization前向传播公式:
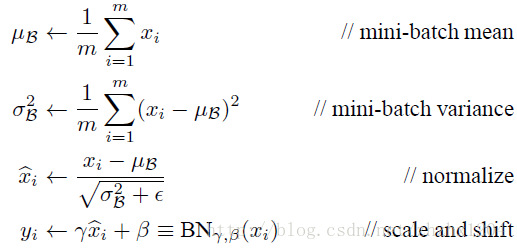
测试阶段的u和σ 计算公式如下:
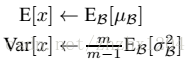
测试阶段,BN的使用公式就是:
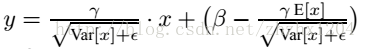
Batch Normalization计算图
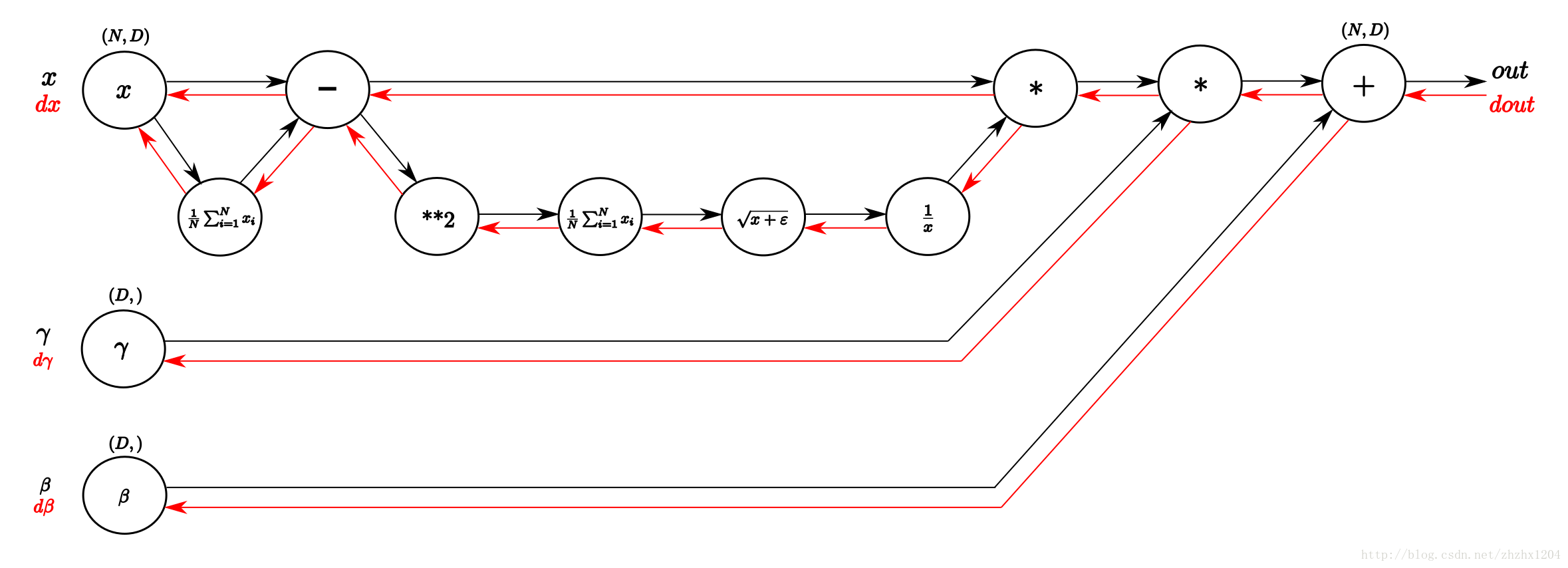
Batch Normalization前向传播
def batchnorm_forward(x, gamma, beta, eps):
N, D = x.shape
#step1: calculate mean
mu = 1./N * np.sum(x, axis = 0)
#step2: subtract mean vector of every trainings example
xmu = x - mu
#step3: following the lower branch - calculation denominator
sq = xmu ** 2
#step4: calculate variance
var = 1./N * np.sum(sq, axis = 0)
#step5: add eps for numerical stability, then sqrt
sqrtvar = np.sqrt(var + eps)
#step6: invert sqrtwar
ivar = 1./sqrtvar
#step7: execute normalization
xhat = xmu * ivar
#step8: Nor the two transformation steps
gammax = gamma * xhat
#step9
out = gammax + beta
#store intermediate
cache = (xhat,gamma,xmu,ivar,sqrtvar,var,eps)
return out, cacheBatch Normalization反向传播
def batchnorm_backward(dout, cache):
#unfold the variables stored in cache
xhat,gamma,xmu,ivar,sqrtvar,var,eps = cache
#get the dimensions of the input/output
N,D = dout.shape
#step9
dbeta = np.sum(dout, axis=0)
dgammax = dout #not necessary, but more understandable
#step8
dgamma = np.sum(dgammax*xhat, axis=0)
dxhat = dgammax * gamma
#step7
divar = np.sum(dxhat*xmu, axis=0)
dxmu1 = dxhat * ivar
#step6
dsqrtvar = -1. /(sqrtvar**2) * divar
#step5
dvar = 0.5 * 1. /np.sqrt(var+eps) * dsqrtvar
#step4
dsq = 1. /N * np.ones((N,D)) * dvar
#step3
dxmu2 = 2 * xmu * dsq
#step2
dx1 = (dxmu1 + dxmu2)
dmu = -1 * np.sum(dxmu1+dxmu2, axis=0)
#step1
dx2 = 1. /N * np.ones((N,D)) * dmu
#step0
dx = dx1 + dx2
return dx, dgamma, dbeta













 1271
1271











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









