







本讲内容:
a. DStream与RDD关系的彻底的研究
b. Streaming中RDD的生成彻底研究
注:本讲内容基于Spark 1.6.1版本(在2016年5月来说是Spark最新版本)讲解。
上节回顾
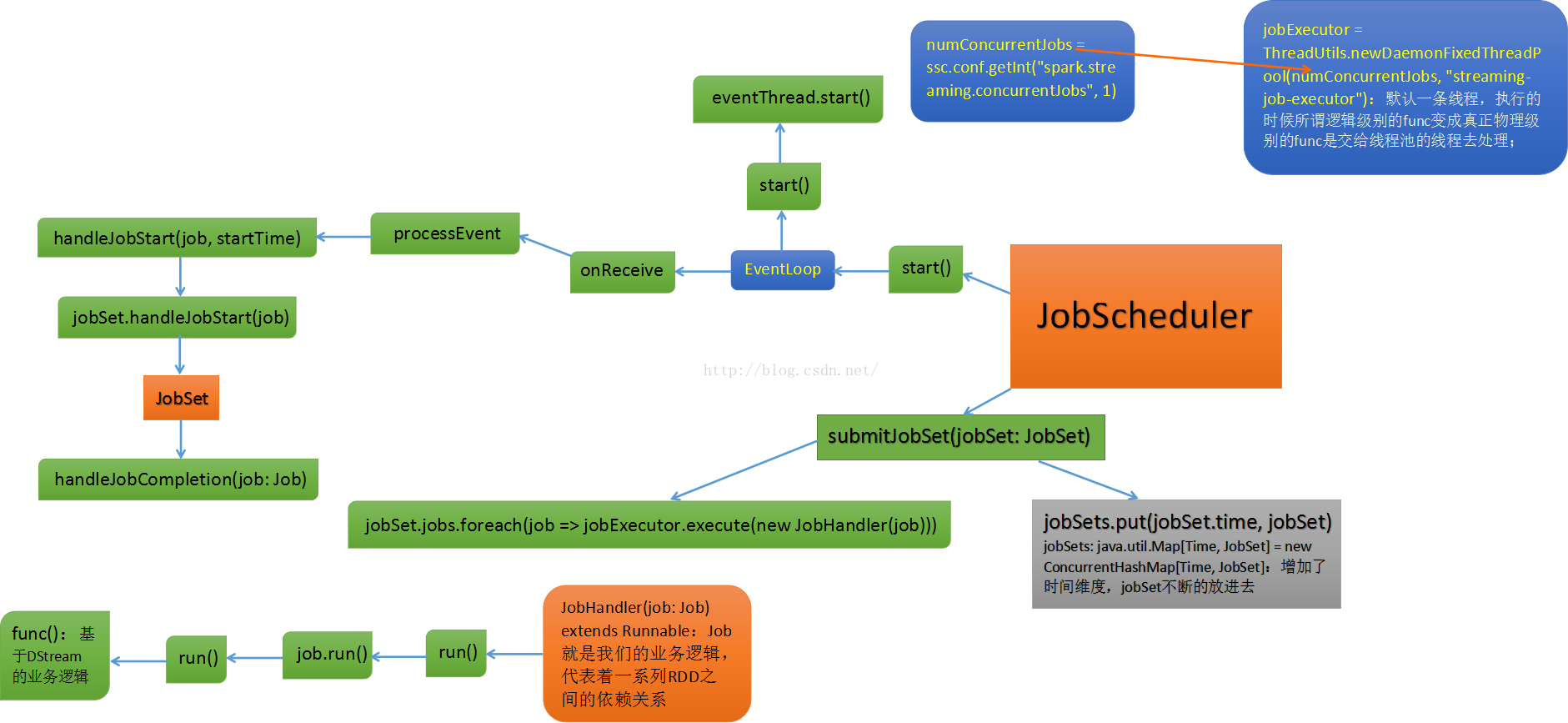
上节课,我们重点给大家揭秘了JobScheduler内幕;可以说JobScheduler是整个Spark Streming的调度的核心,其地位相当于Spark Core中的DAGScheduler。
JobScheduler是SparkStreaming 所有Job调度的中心,内部有两个重要的成员:JobGenerator负责Job的生成,ReceiverTracker负责记录输入的数据源信息。
JobScheduler的启动会导致ReceiverTracker和JobGenerator的启动。ReceiverTracker的启动导致运行在Executor端的Receiver启动并且接收数据,ReceiverTracker会记录Receiver接收到的数据meta信息。
JobGenerator的启动导致每隔BatchDuration,就调用DStreamGraph生成RDD Graph,并生成Job。
JobScheduler中的线程池来提交封装的JobSet对象(时间值,Job,数据源的meta)。Job中封装了业务逻辑,导致最后一个RDD的action被触发,被DAGScheduler真正调度在Spark集群上执行该Job。
最后我们通过JobScheduler重要方法的源码跟踪步骤图给大家揭了整个内幕:
开讲
开讲之前,我们不妨带着问题,去开始:
RDD是怎么生成的?
RDD依靠什么生成?
RDD生成的依据是什么?
Spark Streaming中RDD的执行是否和Spark Core中的RDD执行有所不同?
运行之后我们对RDD怎么处理?
……
带着这些问题,我们从源码中提炼出具体的流程,绘制成下图:
(图来自http://lqding.blog.51cto.com/9123978/1773398 感谢作者!)
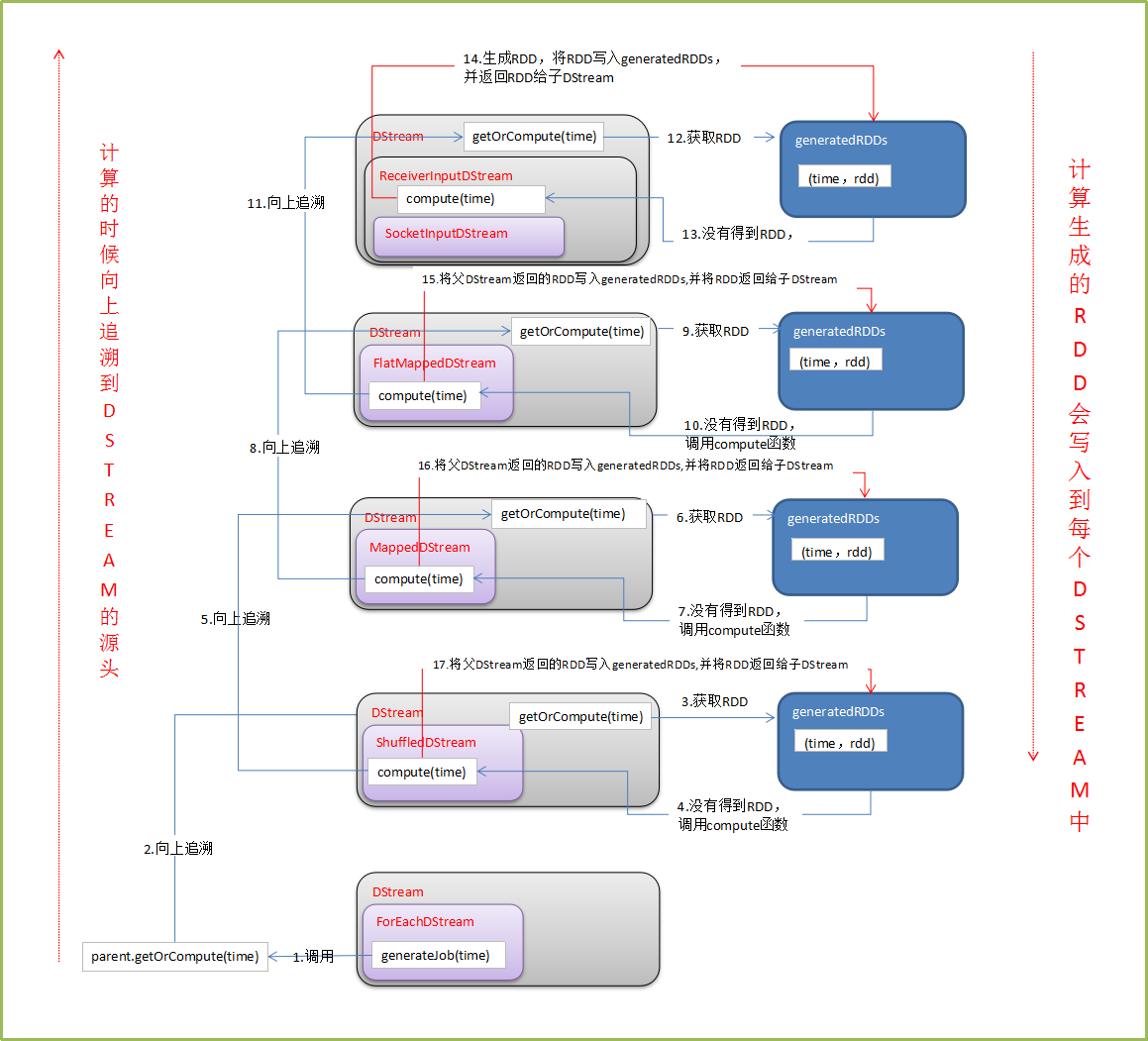
从而我们总结出这样一套说辞:
a. DStream是RDD的模板,其内部generatedRDDs 保存了每个BatchDuration时间生成的RDD对象实例。DStream的依赖构成了RDD依赖关系,即从后往前计算时,只要对最后一个DStream计算即可。
b. JobGenerator每隔BatchDuration调用DStreamGraph的generateJobs方法,调用了ForEachDStream的generateJob方法,其内部先调用父DStream的getOrCompute方法来获取RDD,然后在进行计算,从后往前推,第一个DStream是ReceiverInputDStream,其comput方法中从receiverTracker中获取对应时间段的metadata信息,然后生成BlockRDD对象,并放入到generatedRDDs中
下面以一个基于Spark中的例子(NetworkWordCount)开启解密之旅:
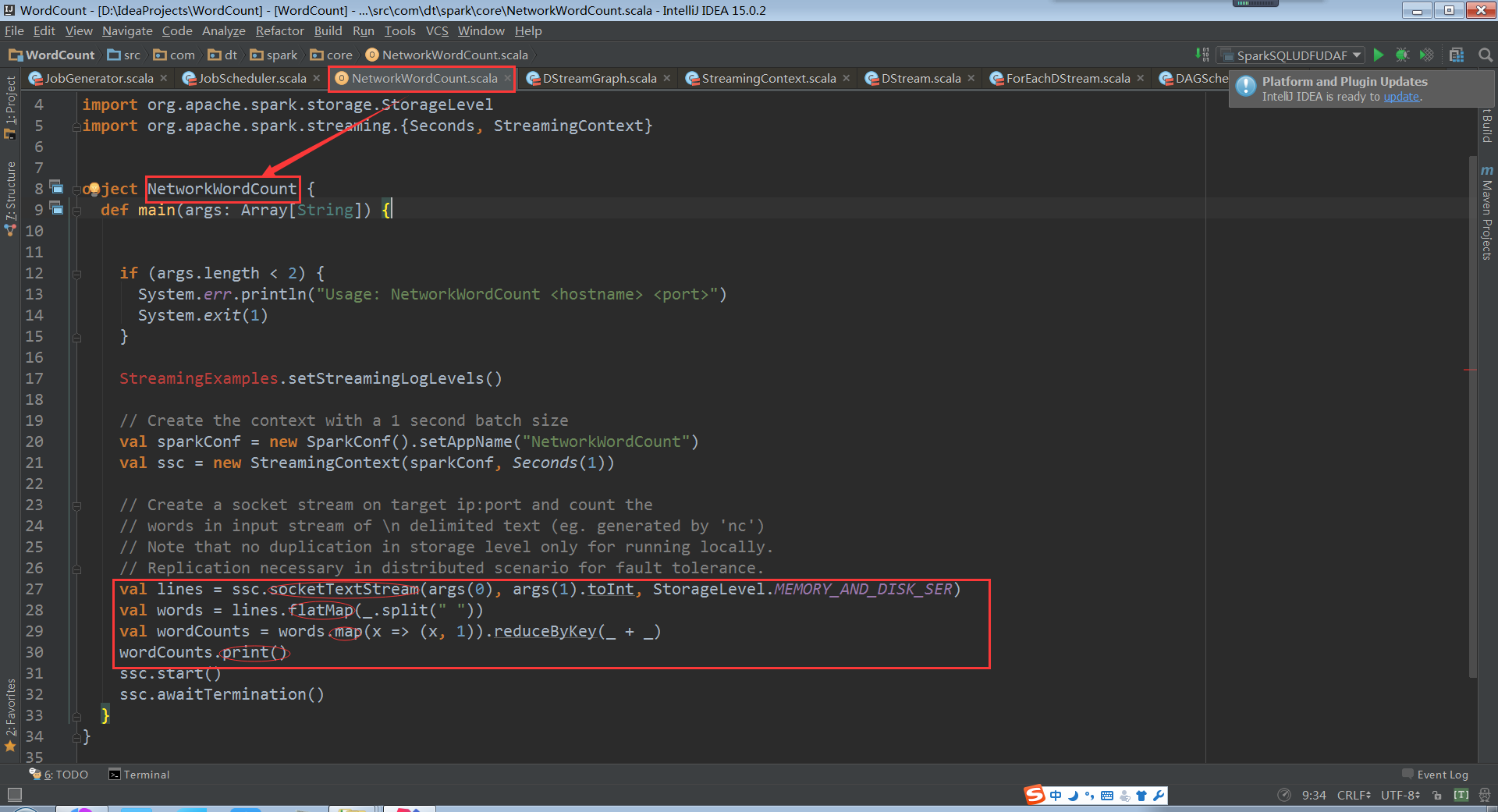
上面代码中四个方法(socketTextStream、flatMap、map、print)实际上都是transform(表面上最后一个是action)。
由NetworkWordCount中的代码,我们进入到源码中绘制出DStream生成RDD的主流程图:
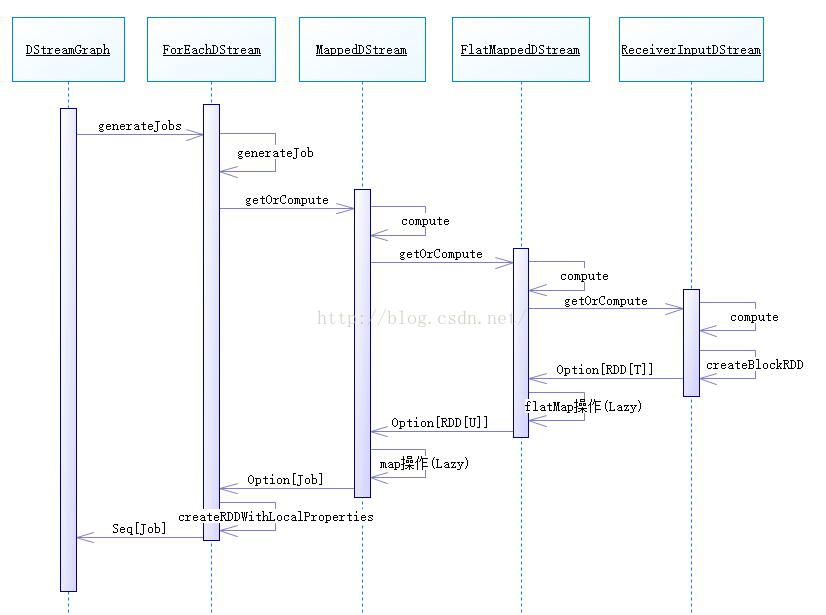
DStreamGraph.generateJobs的代码:
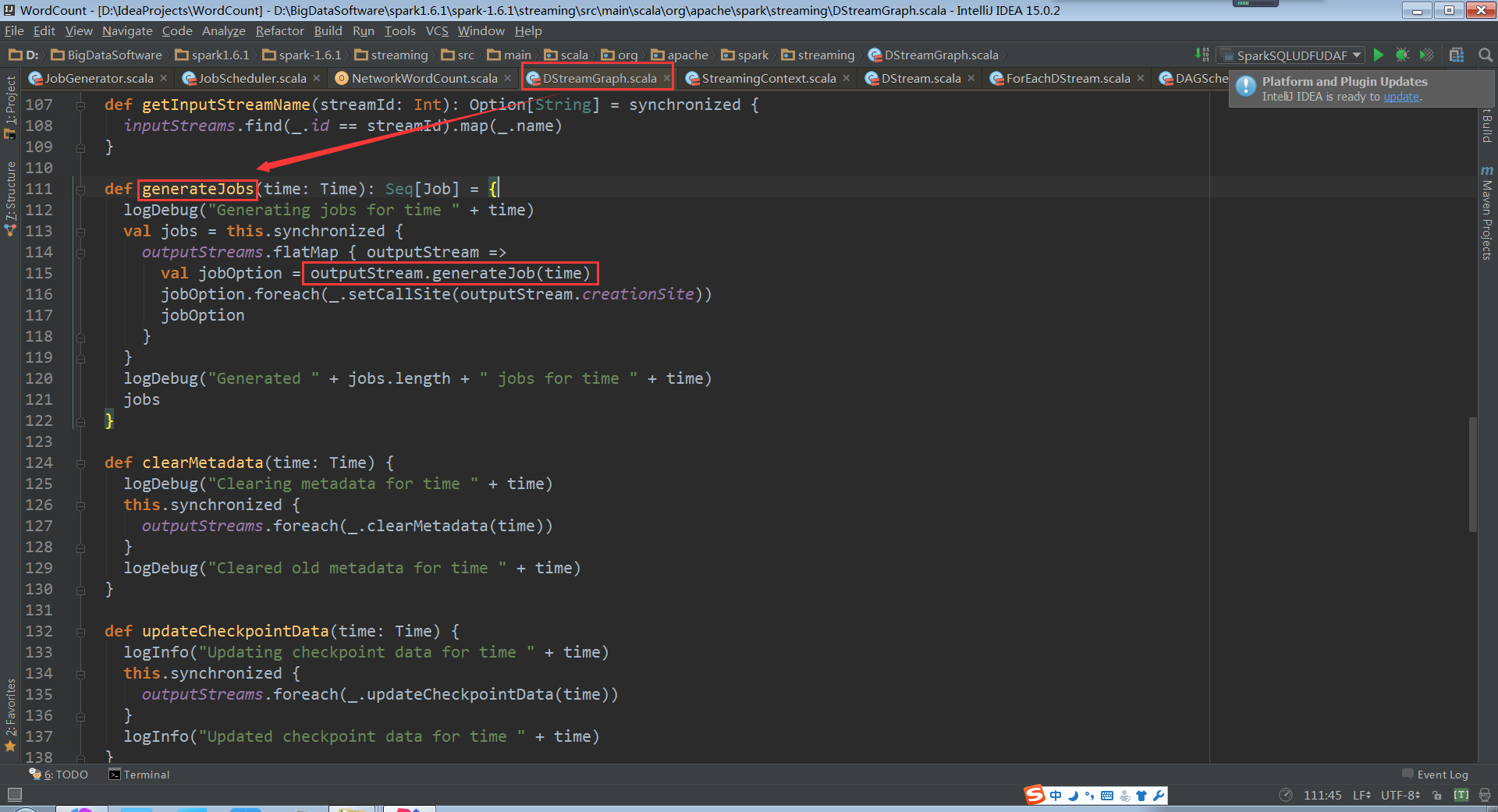
点击进入到outputStream.generateJob(time)中,我们就来到了DStream的 generateJob(time: Time),但这个不是我们所需要的,我们来看看ForEachDStream的genarateJob
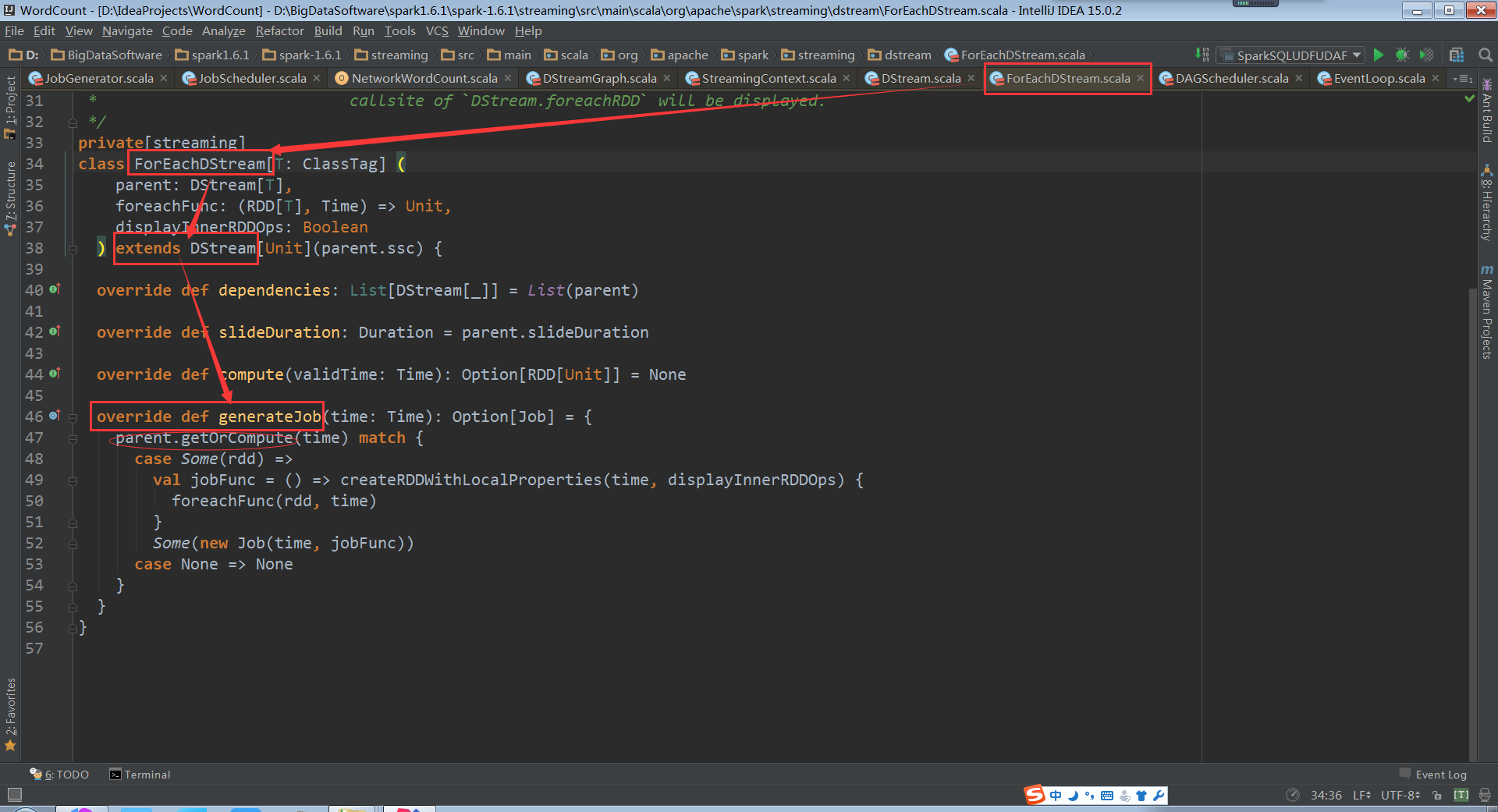
ForEachDStream继承了DStream,并覆写了genarateJob方法。
事实上,genarateJob中通过父类DStream的getOrCompute与案例中各个DStream子类的compute方法组成了职责链模式。
DStream.getOrCompute:
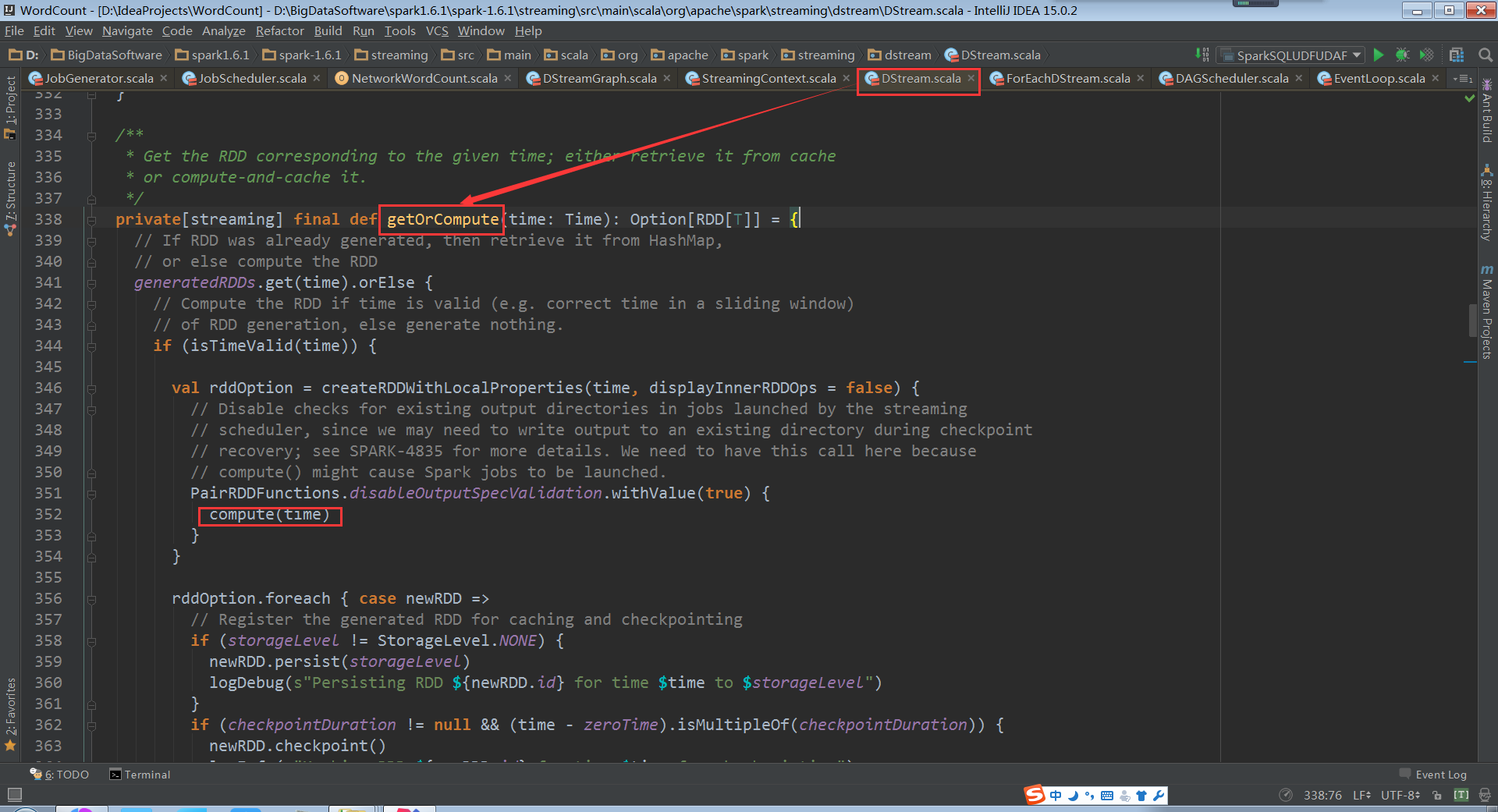
MappedDStream.compute:
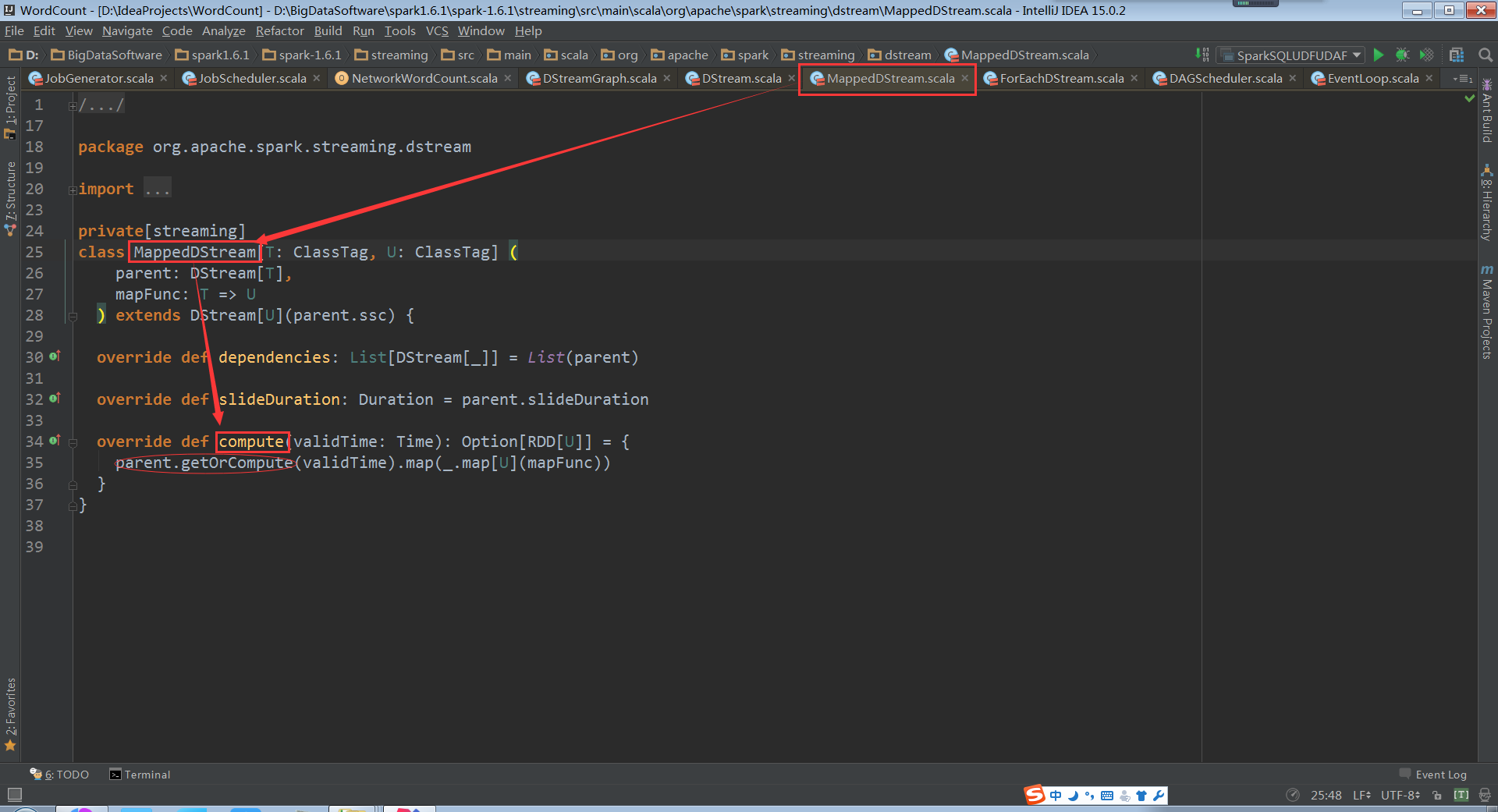
FlatMappedDStream.compute:
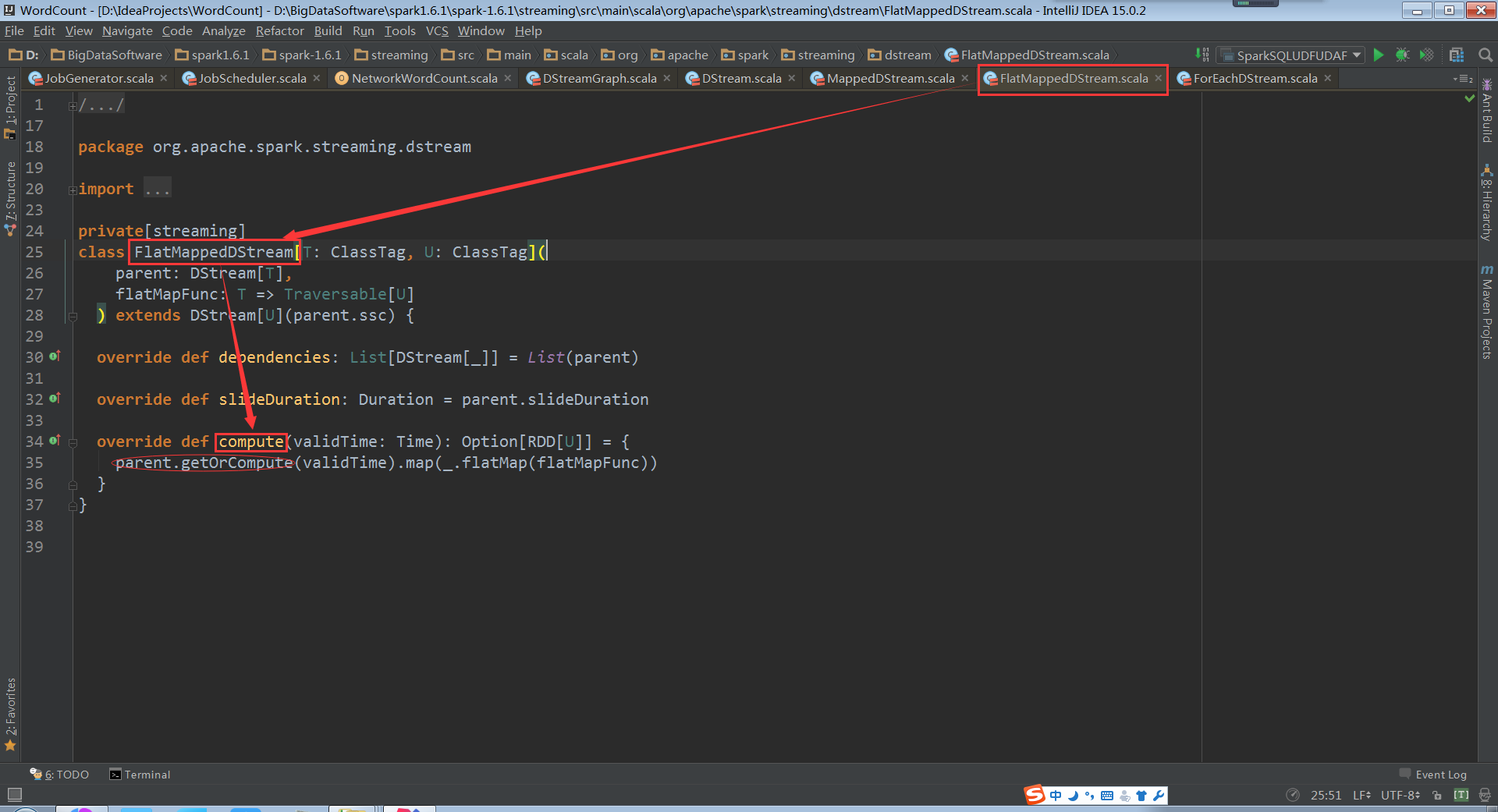
ReceiverInputDStream.compute:
从中我们不难发现:ReceiverInputDStream因为是第一个DStream,不依赖其它DStream,所以必须要自己生成RDD。
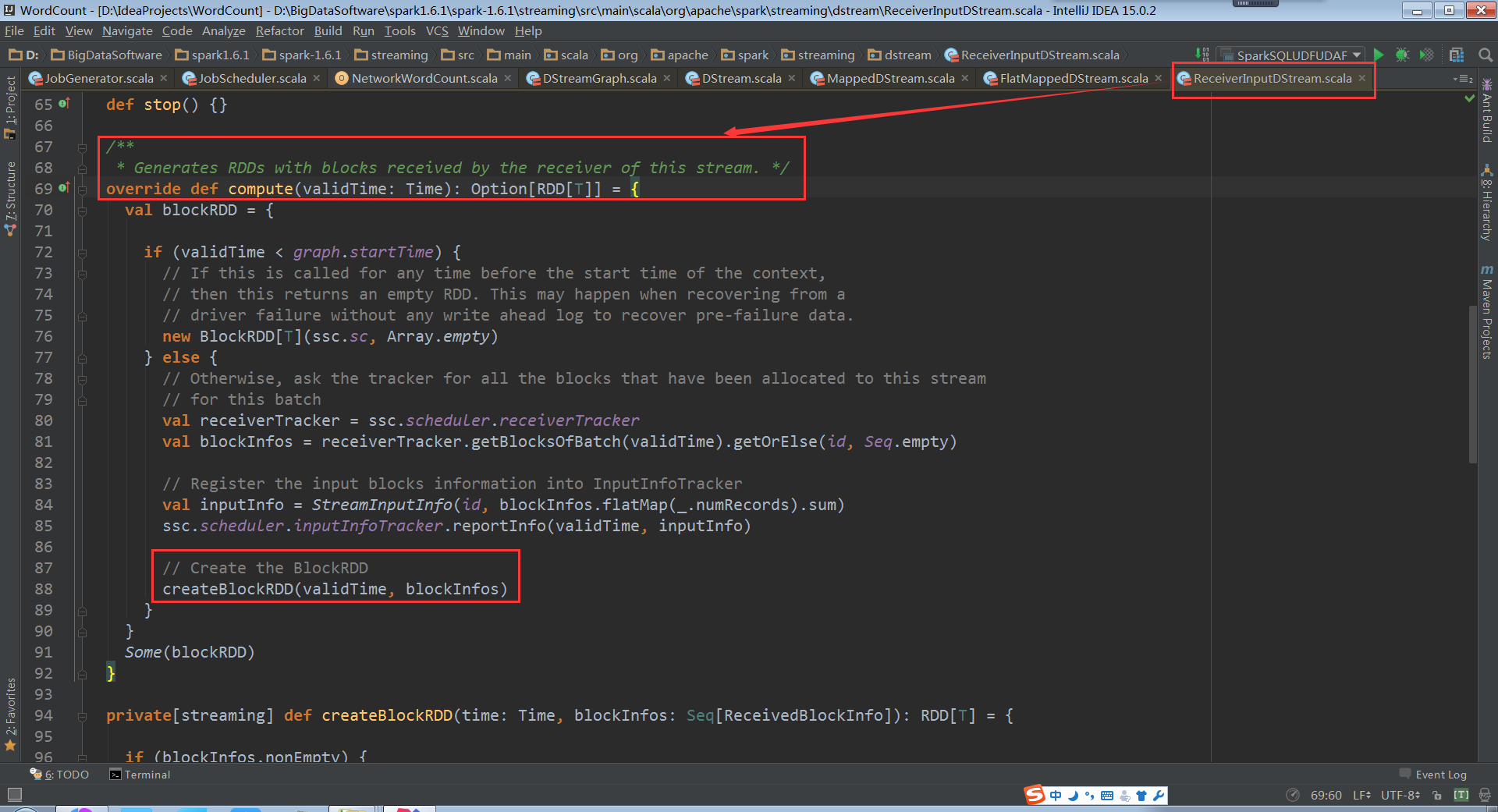
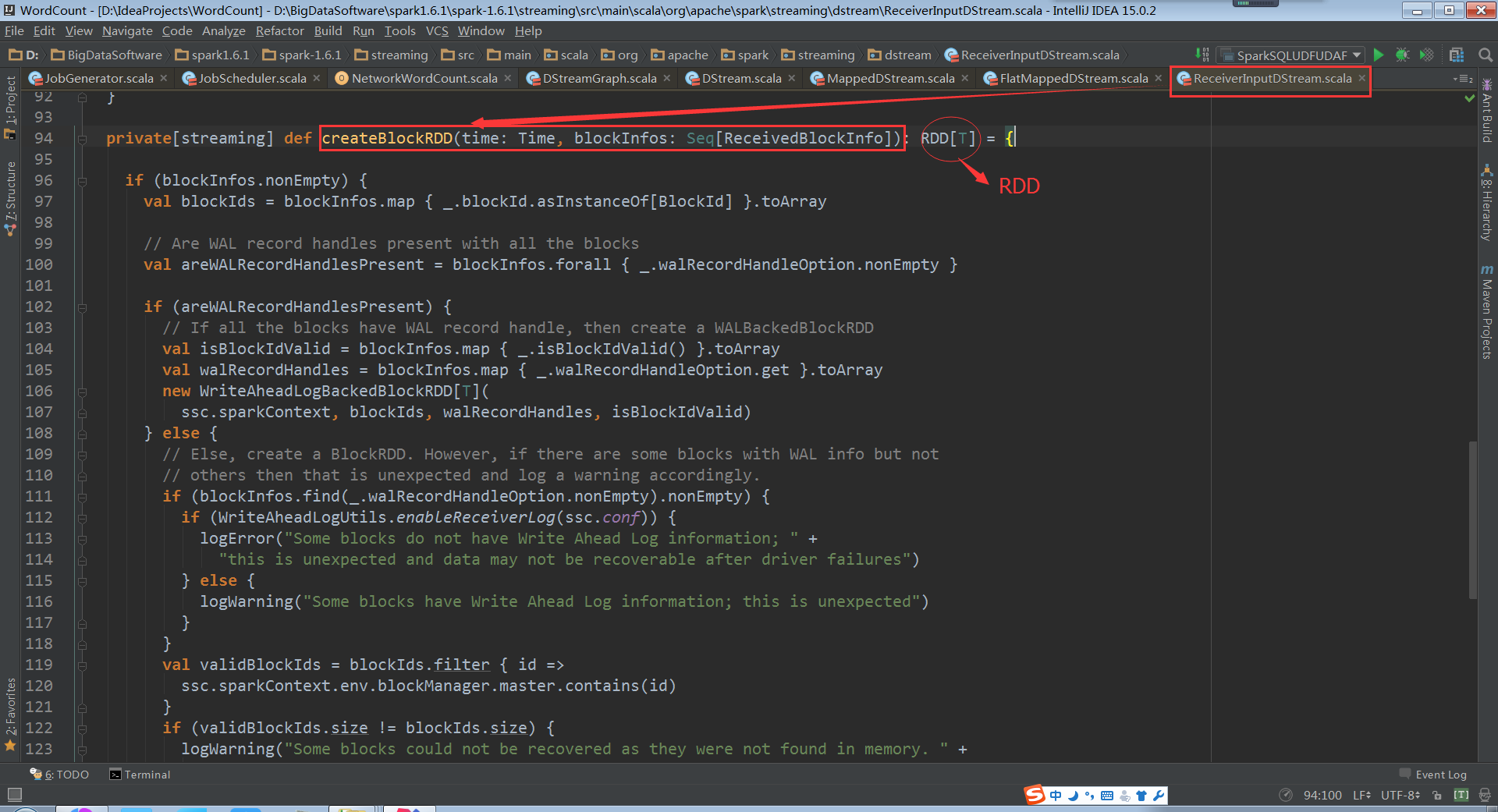
进入到ReceiverInputDStream.createBlockRDD的代码
最后这种职责依赖又回到ForEachDStream.generateJob
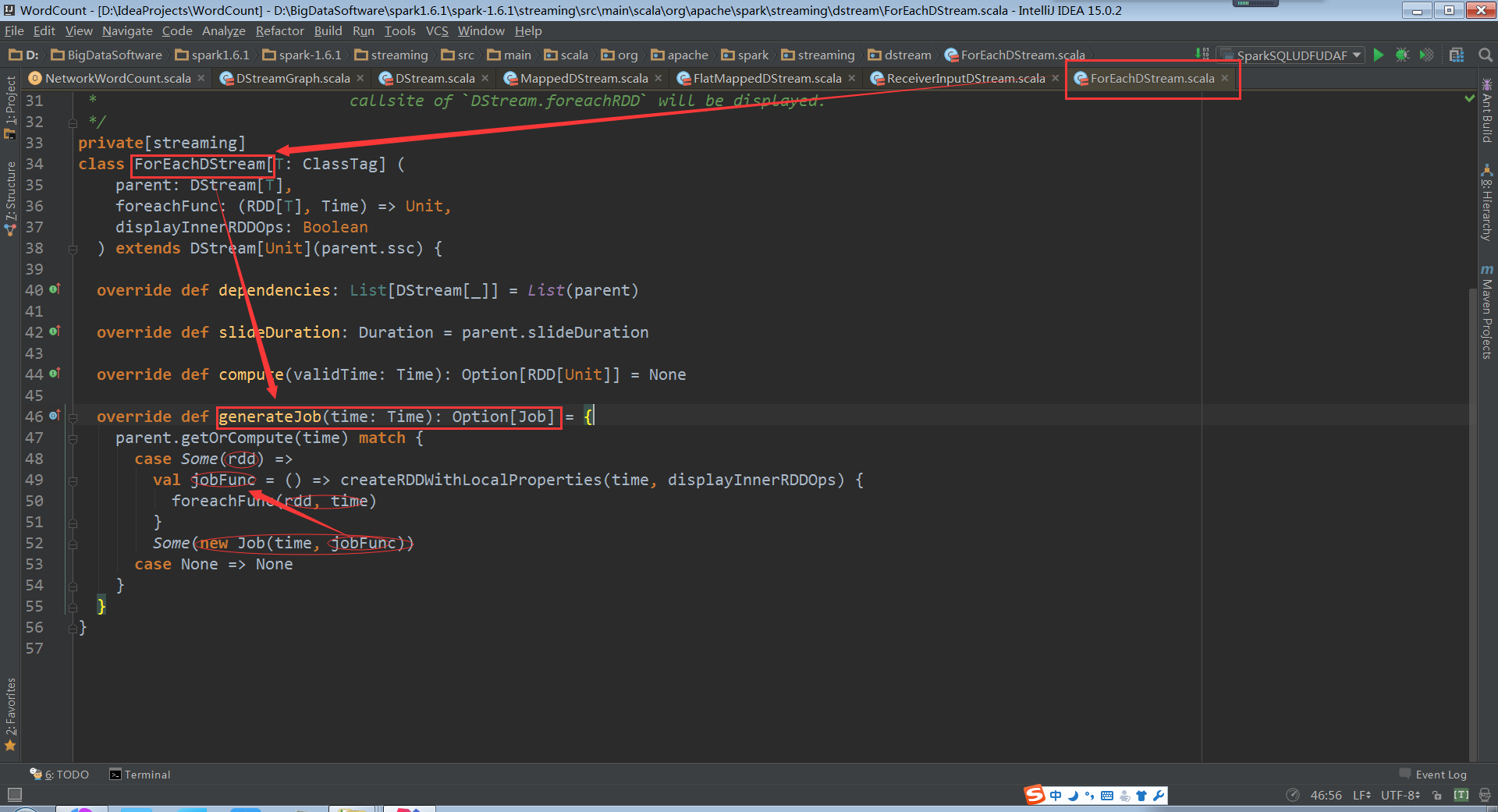
RDD会随jobFunc封装在了新生成的Job中
以上就是物理级别的实际RDD生成过程,下面我们来给大家说说逻辑级别的RDD生成;
我们有必要回到最初的几个问题:
DStream生成RDD的过程,DStream到底是怎么生成RDD的?
DStream和RDD到底什么关系?
RDD生成后是怎么管理的?
我们首先进入到DStream.print()中,开始为大家解答这些问题:
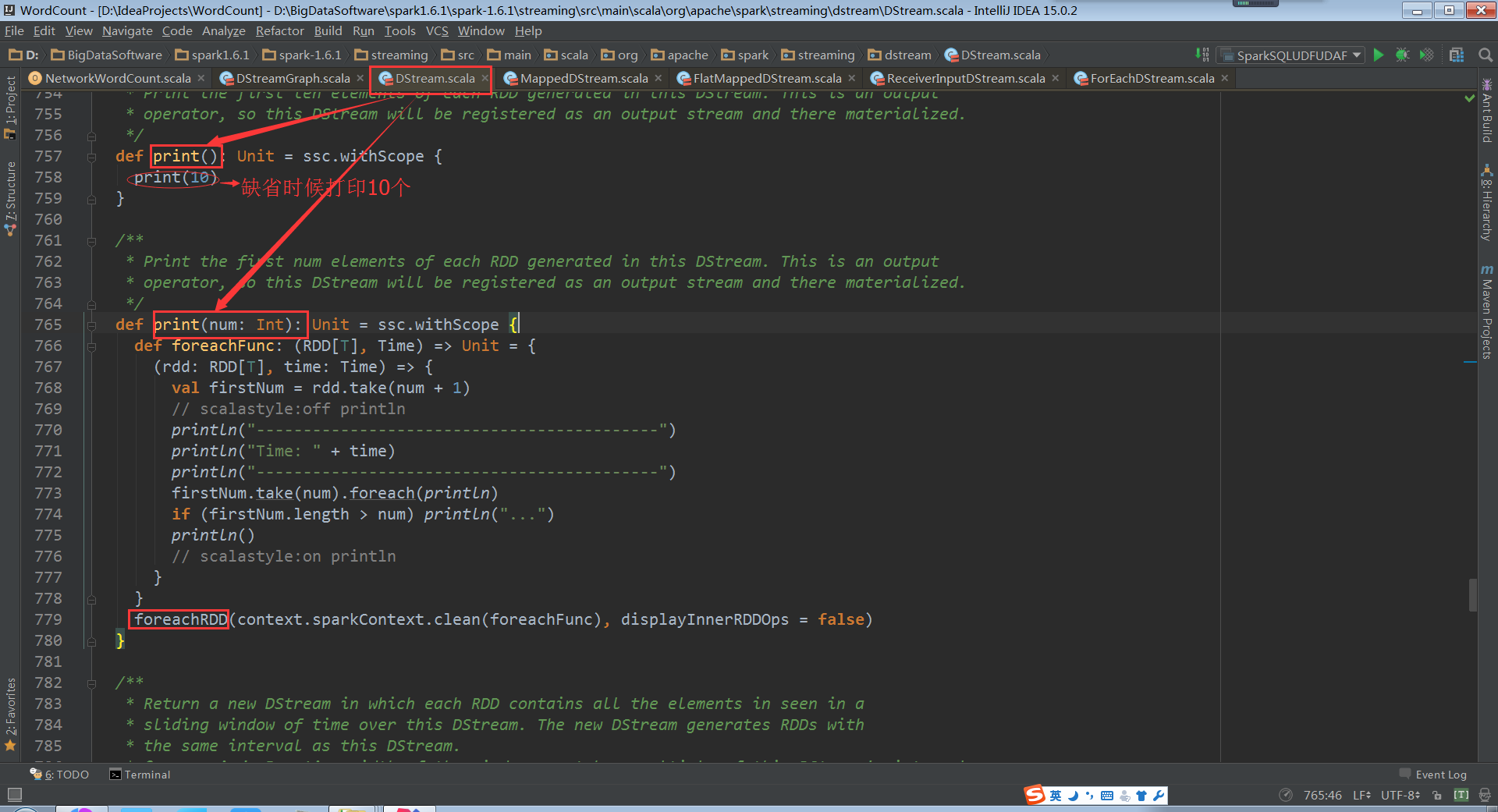
这里的print源码内部用foreachRDD将通过foreachFunc构建的(RDD,Time)遍历操作。
foreachRDD其实也是要产生ForEachDStream,对DStream遍历操作,ForEachDStream不会产生action操作,所以ForEachDStream操作是transform级别操作。所以我们得出一个结论:ForEachDStream并不一定会触发job的执行,但是会产生Job,(不会触发执行)(真正的job触发是Timer定时产生的额)
ForEachDStream会产生Job其实也是假象,因为没有ForEachDStream,也会产生Job,定时器Timer时间到了,管你有没有ForEachDStream,还是会产生Job并执行。
我们再来看一下foreachRDD。
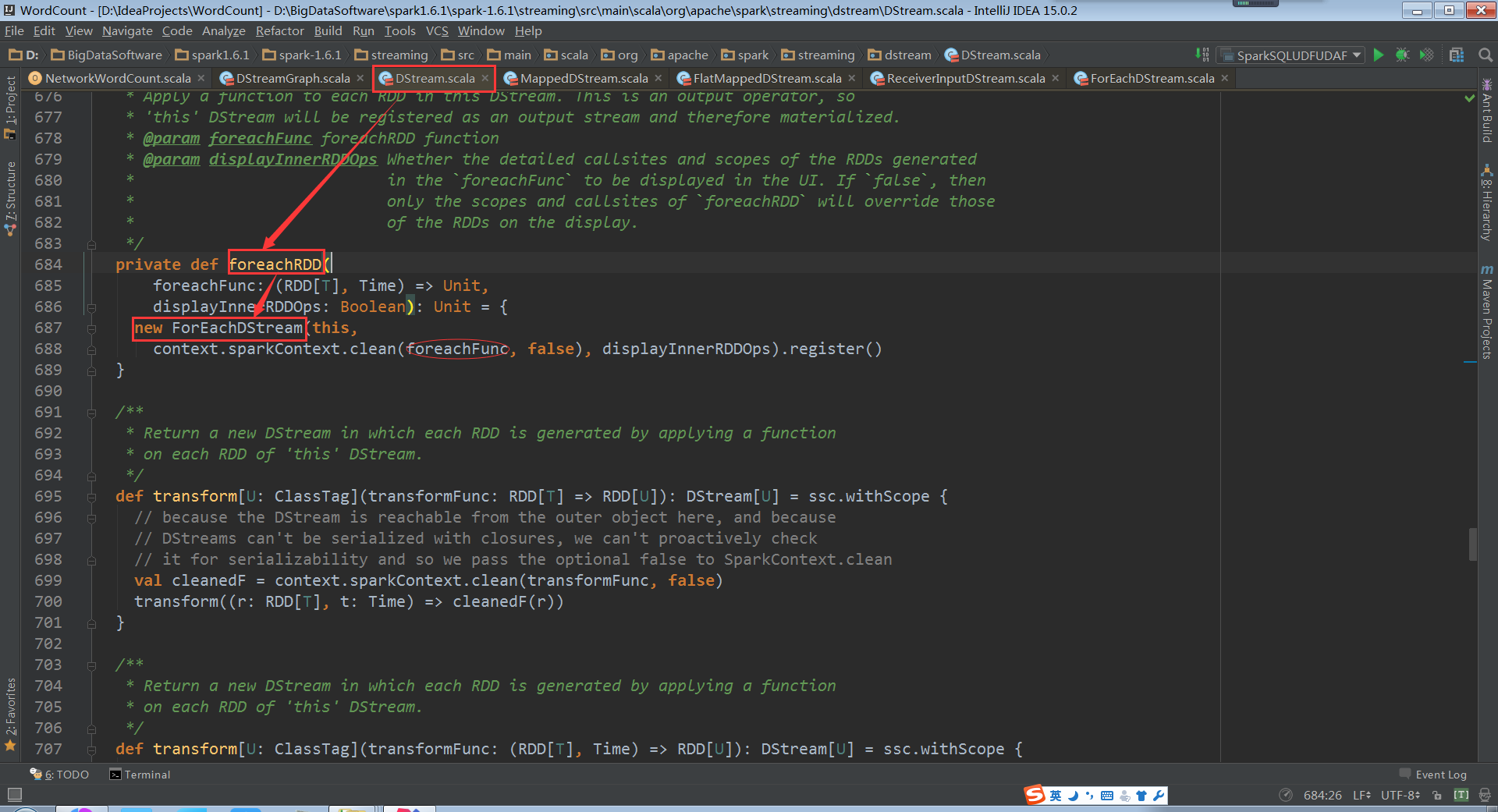
由上面的源码,我们可以这样说:foreachRDD是Spark Streaming的后门,实际上可以任意操作RDD(表面上是DStream离散流数据)
为了弄清楚DStream怎样生成RDD的,我们需要看看DStream的源代码部分注释
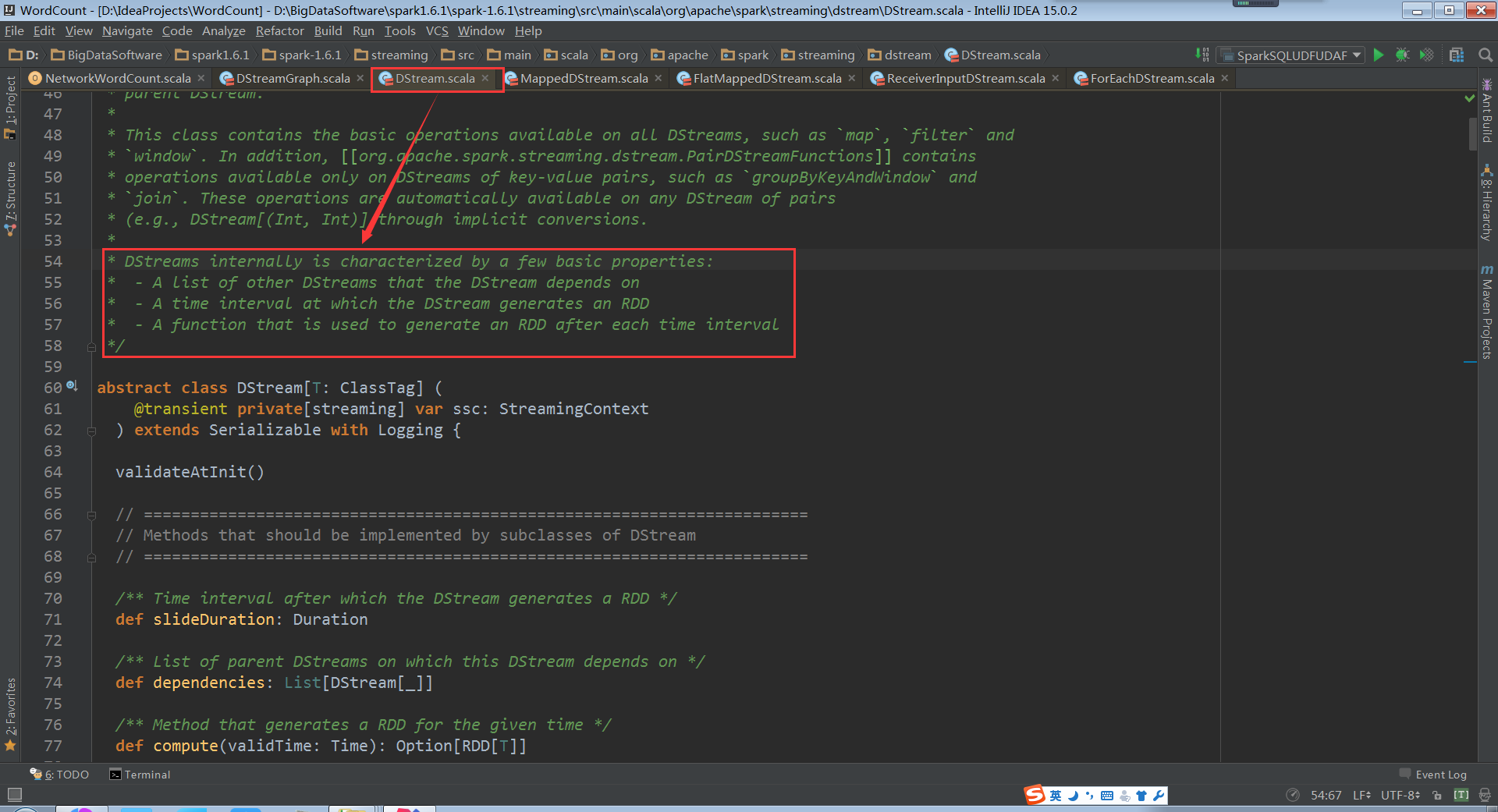
DStream一共有三个关键重点:
a. 除了第一个DStream,后面的DStream都要依赖前一个DStream
b. DStream在每一个interval都会生成一个RDD
c. 这个类里有个function可以在每一个interval后产生一个RDD
这里再次强调一下:DStream是RDD的模板,负责批量产生RDD。那么接下来,我们彻底深入查看具体过程。
额外说明:为什么DStream要像RDD一样回溯,从后往前依赖,构建最后一个DStream?因为DStream要根据batch interval每隔一定时间产生RDD,必须和RDD高度步调一致(其实可以不一致,只不过会有很多问题)。
这样又说明了:DStream是RDD模板,DStream Graph是DAG的模板。
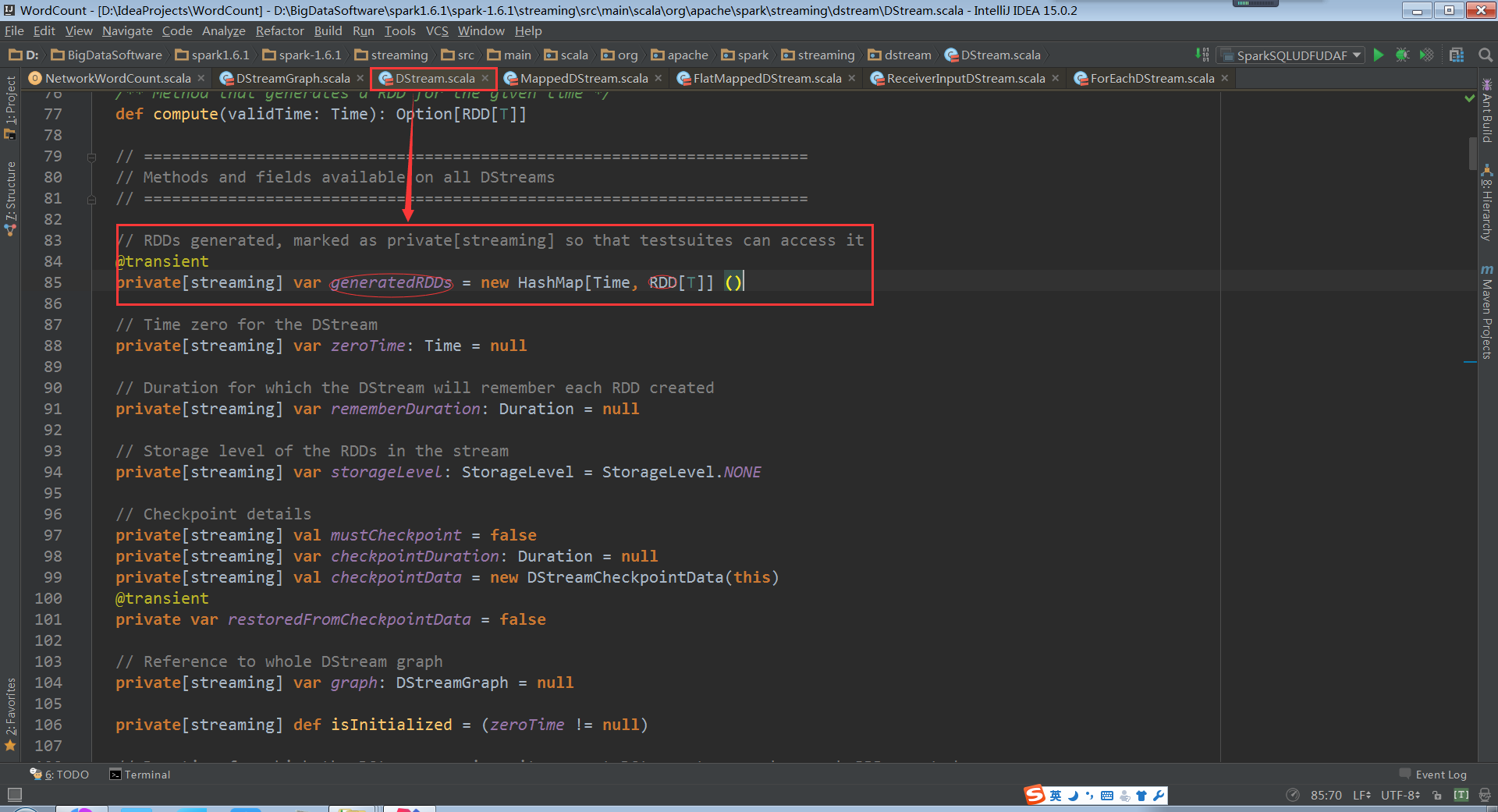
这是基于时间的RDD数据结构。
其中的每一个RDD(实际代表最后一个RDD)意味着会执行一个job。
如果弄清楚GeneratedRDD是怎么实例化的,就可以弄清楚RDD到底是怎么产生的了。
进入到DStream.getOrCompute中:
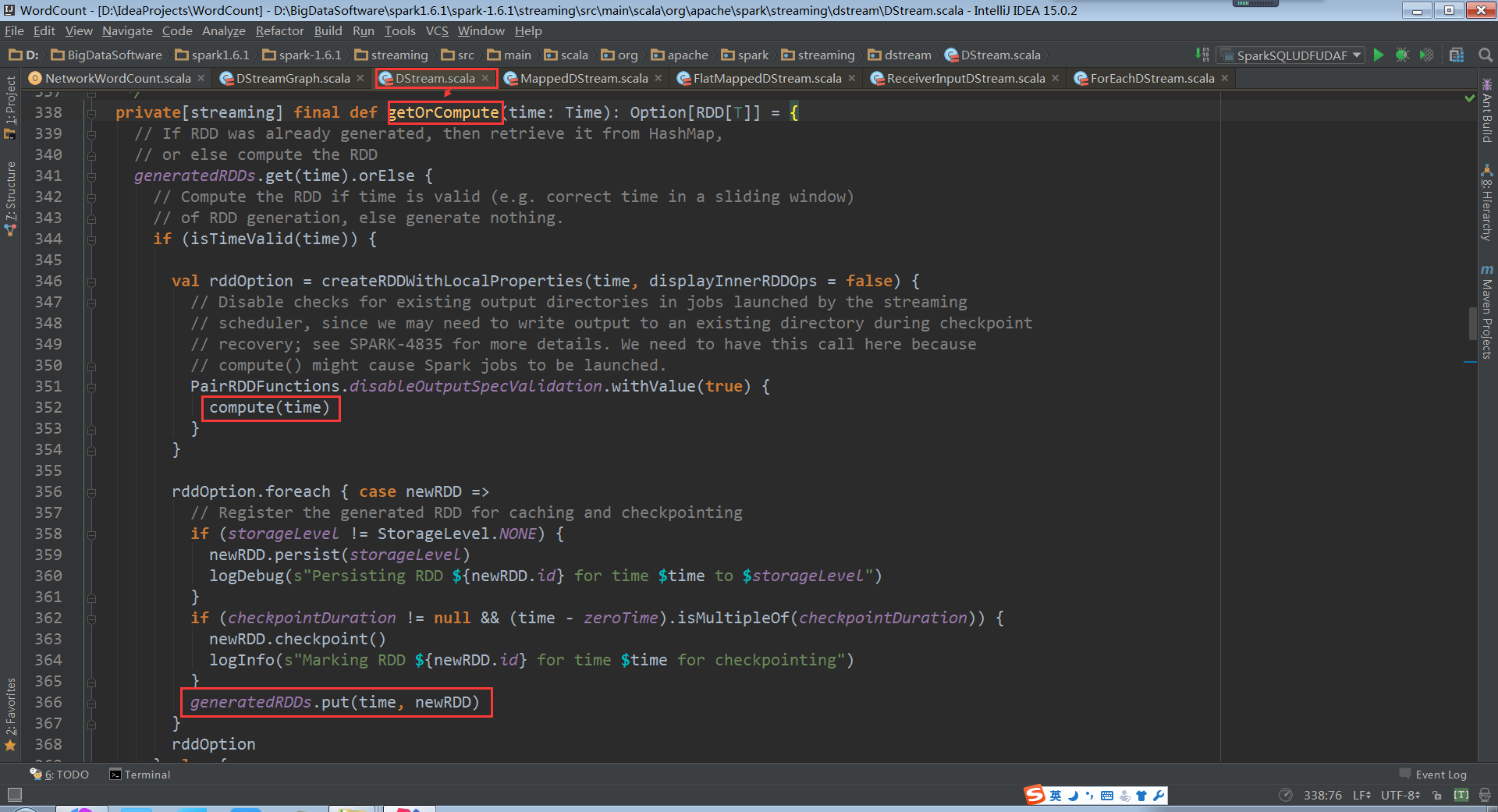
RDD变量生成了,但是并没有执行,只是在逻辑级别进行了代码的框架级别的优化管理。
注意:Spark Streaming实际上在没有输入数据的时候仍然会产生RDD(空的BlockRDD),所以可以在此修改源码,提升性能。
反过来仔细思考一下,spark其实没有所谓实时流处理;实际上就是时间极短的情况下完成的批处理,就是我们之前所说的微批处理。
至此,我们就完成了RDD生成的逻辑级别的解密。加上之前的物理级别的RDD生成过程,我们本节课的内容到此结束。














 4311
4311











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









