







本讲内容:
a. ReceiverBlockTracker容错安全性
b. DStreamGraph和JobGenerator容错安全性
注:本讲内容基于Spark 1.6.1版本(在2016年5月来说是Spark最新版本)讲解。
上节回顾
上一讲中,我们从安全角度来讲解Spark Streaming,由于Spark Streaming会不断的接收数据、不断的产生job、不断的提交job。所以数据的安全性至关重要。
首先我们来谈谈,对于数据安全性的考虑:
a. Spark Streaming是基于Spark Core之上的,如果能够确保数据安全可好的话,在Spark Streaming生成Job的时候里面是基于RDD,即使运行的时候出现问题,那么Spark Streaming也可以借助Spark Core的容错机制自动容错
b. 对于executor的安全容错主要是数据的安全容错。Executor计算时候的安全容错是借助Spark core的RDD的,所以天然是安全的
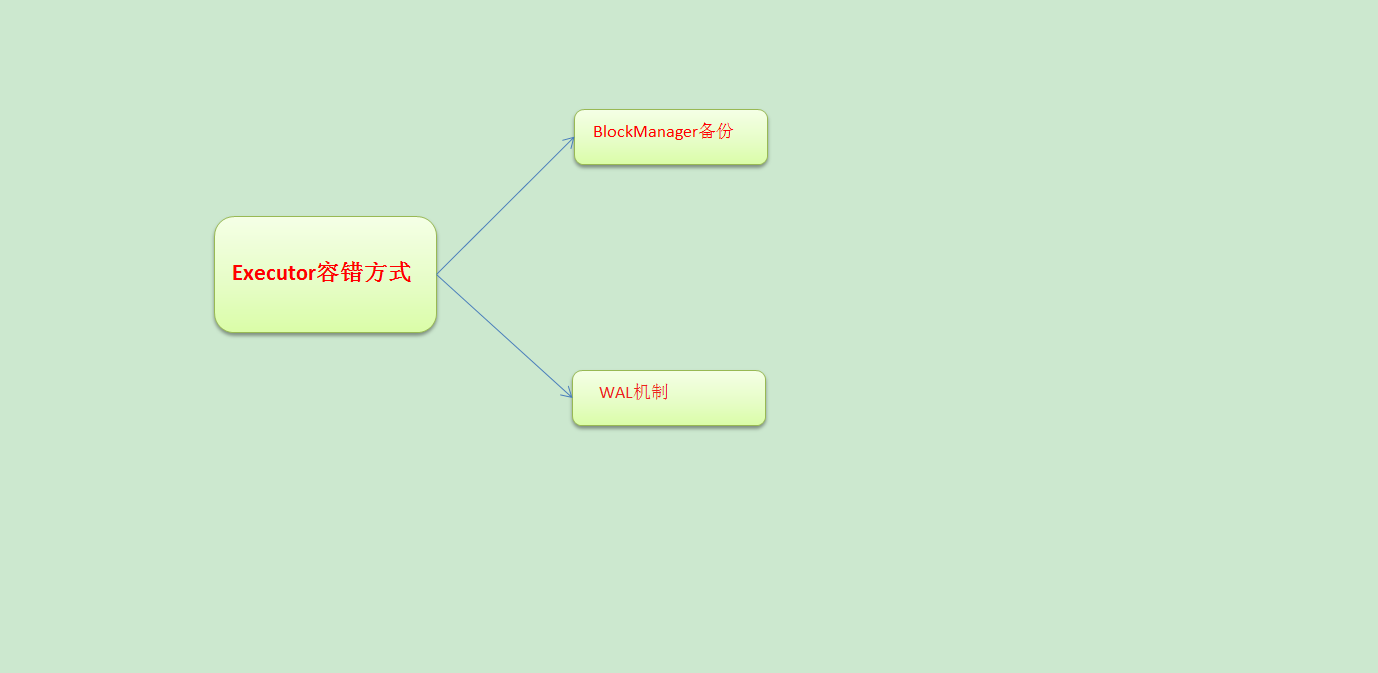
那么Executor容错方式是什么呢?
a. 最简单的容错是副本方式,基于底层BlockManager副本容错,也是默认的容错方式
b. 接收到数据之后不做副本,支持数据重放,所谓重放就是支持反复读取数据
开讲
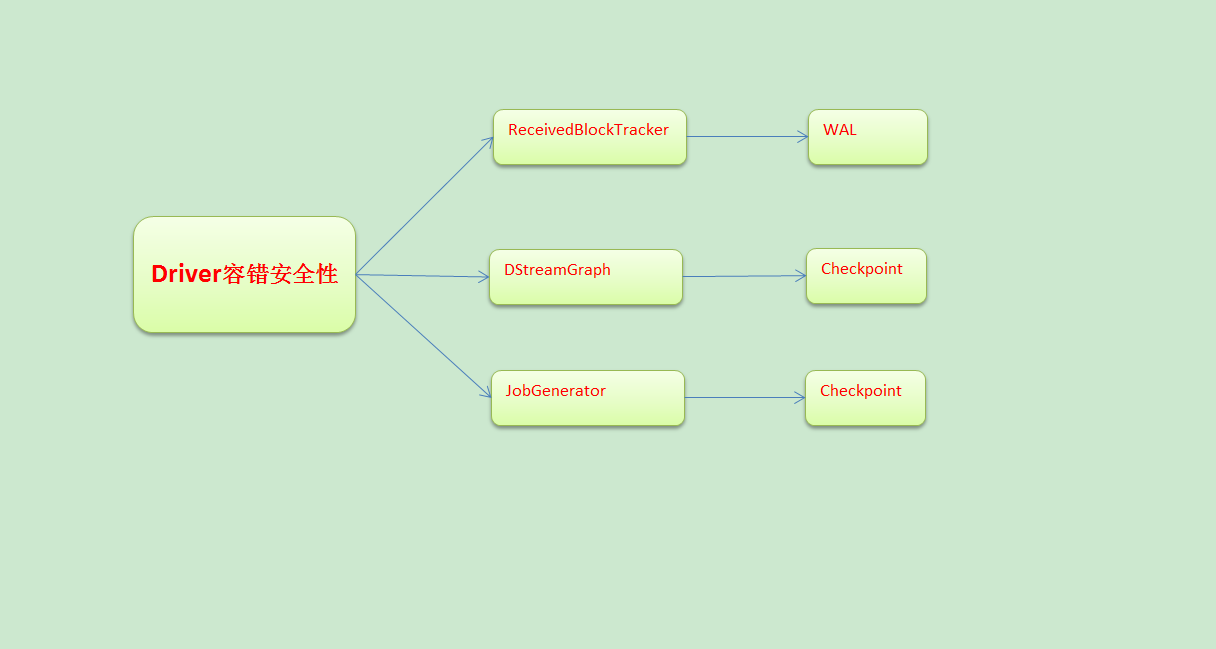
本讲我们从Spark Streaming源码解读Driver容错安全性:那么什么是Driver容错安全性呢?
a. 从数据层面:ReceivedBlockTracker为整个Spark Streaming应用程序记录元数据信息
b. 从调度层面:DStreamGraph和JobGenerator是Spark Streaming调度的核心,记录当前调度到哪一进度,和业务有关
c. 从运行角度: 作业生存层面,JobGenerator是Job调度层面
谈Driver容错性我们需要考虑Driver中有那些需要维持状态的运行
a. ReceivedBlockTracker跟踪了数据,因此需要容错。通过WAL方式容错
b. DStreamGraph表达了依赖关系,恢复状态的时候需要根据DStream恢复计算逻辑级别的依赖关系。通过checkpoint方式容错
c. JobGenerator表面是基于ReceiverBlockTracker中的数据,以及DStream构成的依赖关系不断的产生Job的过程。也可以这么理解这个过程中消费了那些数据,并且跟踪进行到了一个怎样的程度
具体分析如下图:
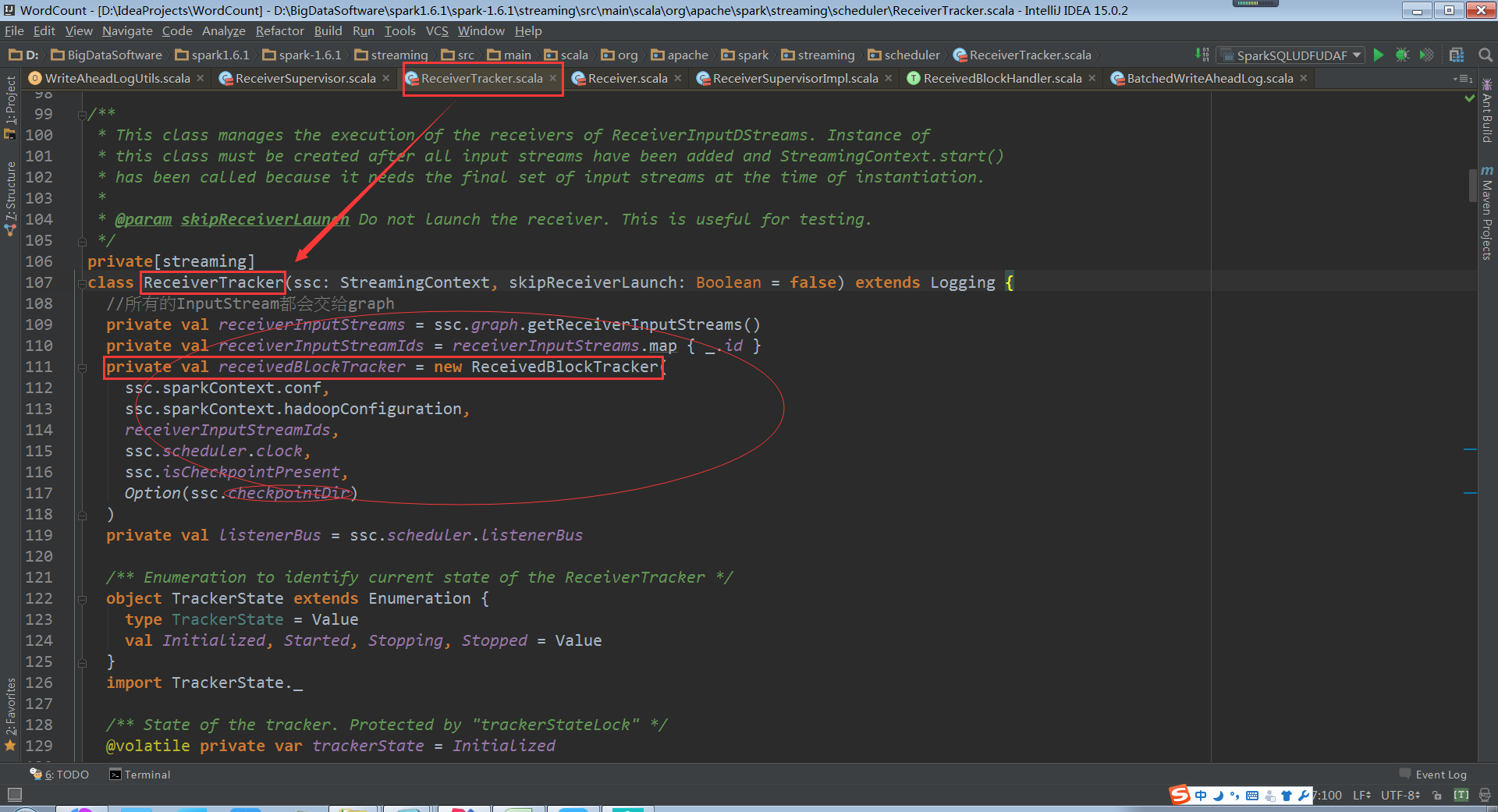
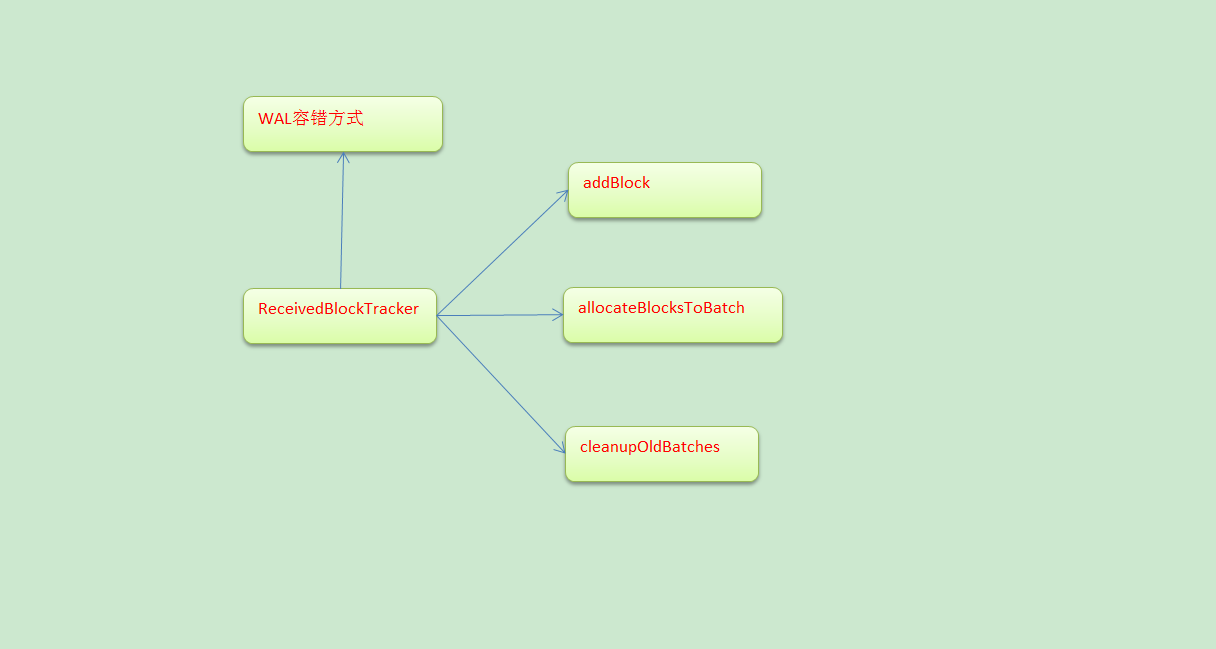
ReceivedBlockTracker
ReceivedBlockTracker会管理Spark Streaming运行过程中所有的数据。并且把数据分配给需要的batches,所有的动作都会被WAL写入到Log中,Driver失败的话,就可以根据历史恢复tracker状态,在ReceivedBlockTracker创建的时候,使用checkpoint保存历史目录
下面我们就走进Receiver,解密在收到数据之后,有事怎么处理的?
Receiver接收到数据,把元数据信息汇报上来,然后通过ReceiverSupervisorImpl就将数据汇报上来,就直接通过WAL进行容错
当Receiver的管理者,ReceiverSupervisorImpl把元数据信息汇报给Driver的时候,正在处理是交给ReceiverBlockTracker. ReceiverBlockTracker将数据写进WAL文件中,然后才会写进内存中,被当前的Spark Streaming程序的调度器使用的,也就是JobGenerator使用的。JobGenerator不可能直接使用WAL。WAL的数据在磁盘中,这里JobGenerator使用的内存中缓存的数据结构
ReceiverBlockTracker.addBlock源码
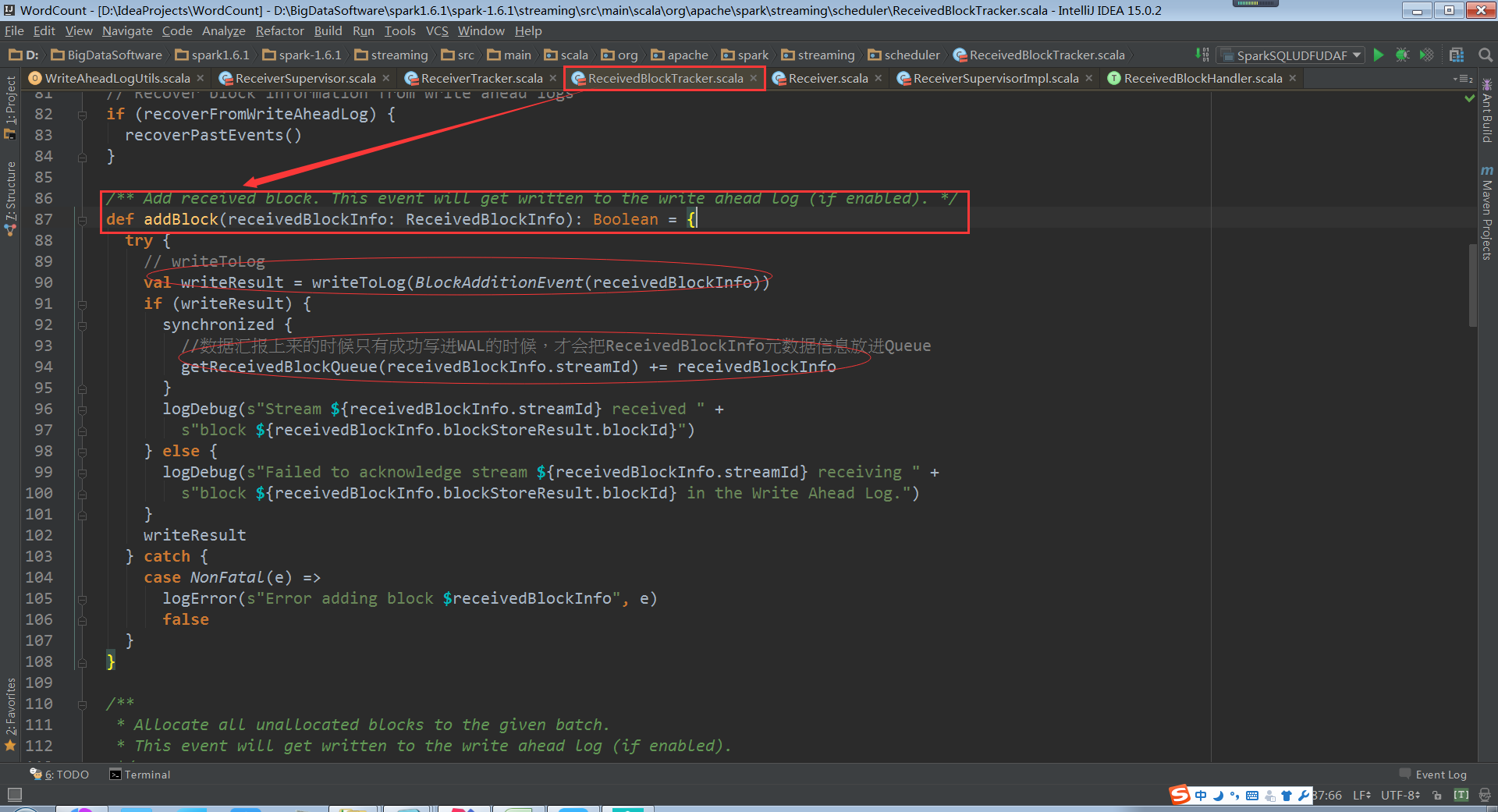
此时的数据结构就是streamIdToUnallocatedBlockQueues,Driver端接收到的数据保存在streamIdToUnallocatedBlockQueues中
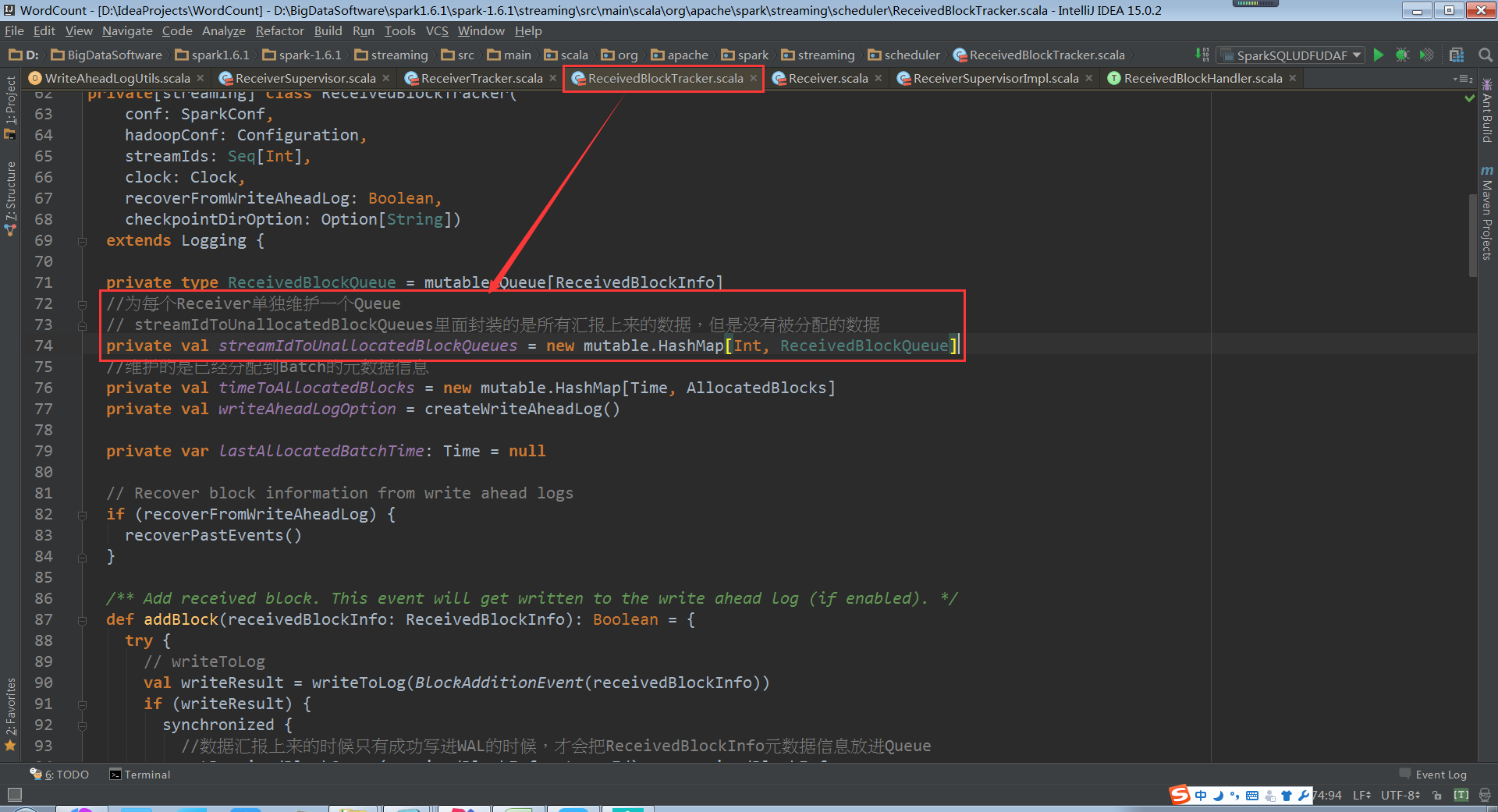
allocateBlocksToBatch把接收到的数据但是没有分配,分配给batch,根据streamId取出Block,由此就知道Spark Streaming处理数据的时候可以有不同的batchTime(batchTime是上一个Job分配完数据之后,开始再接收到的数据的时间)

timeToAllocatedBlocks可以有很多的时间窗口的Blocks,也就是Batch Duractions的Blocks。这里面就维护了很多Batch Duractions分配的数据
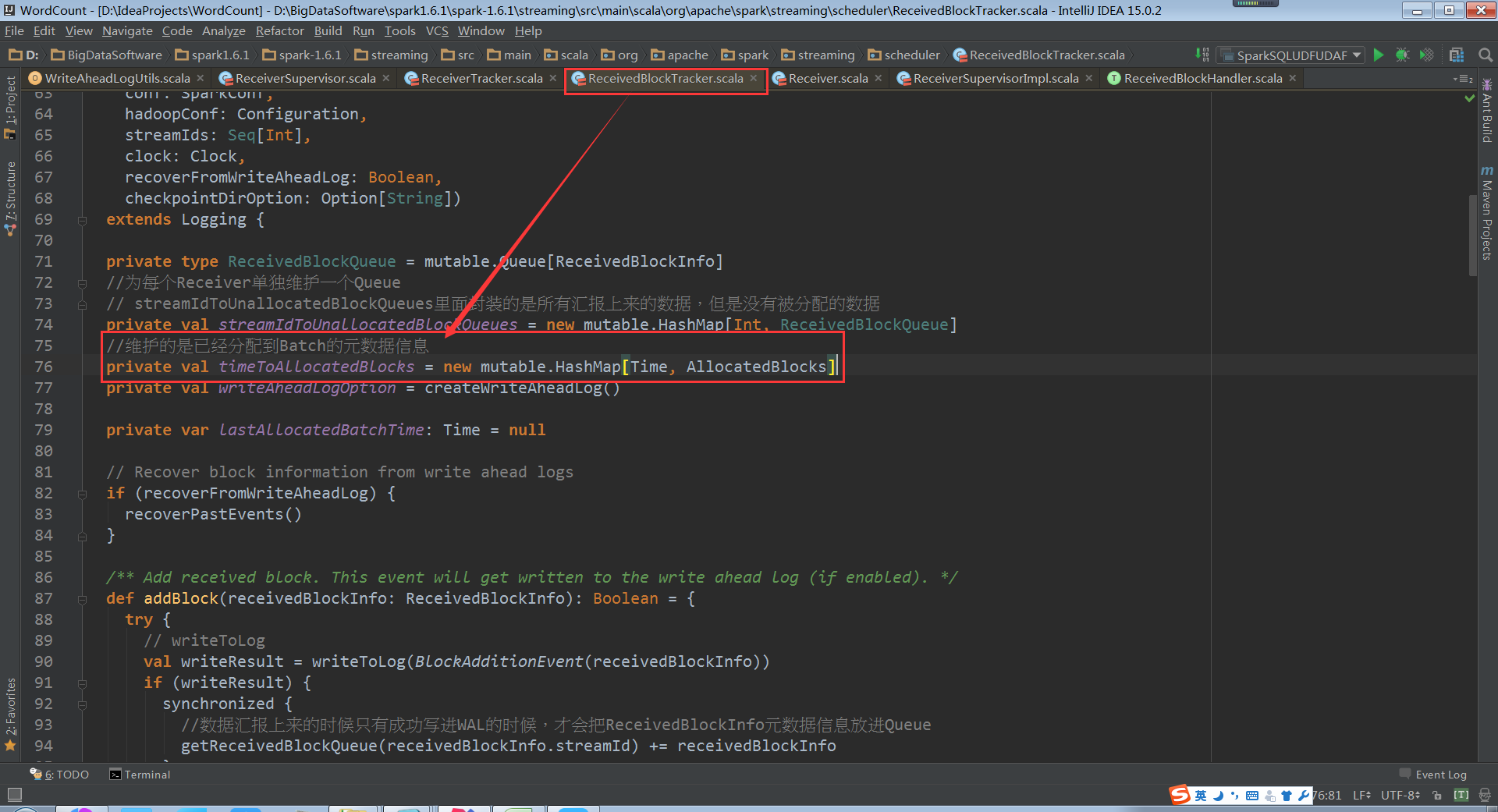
根据streamId获取Block信息
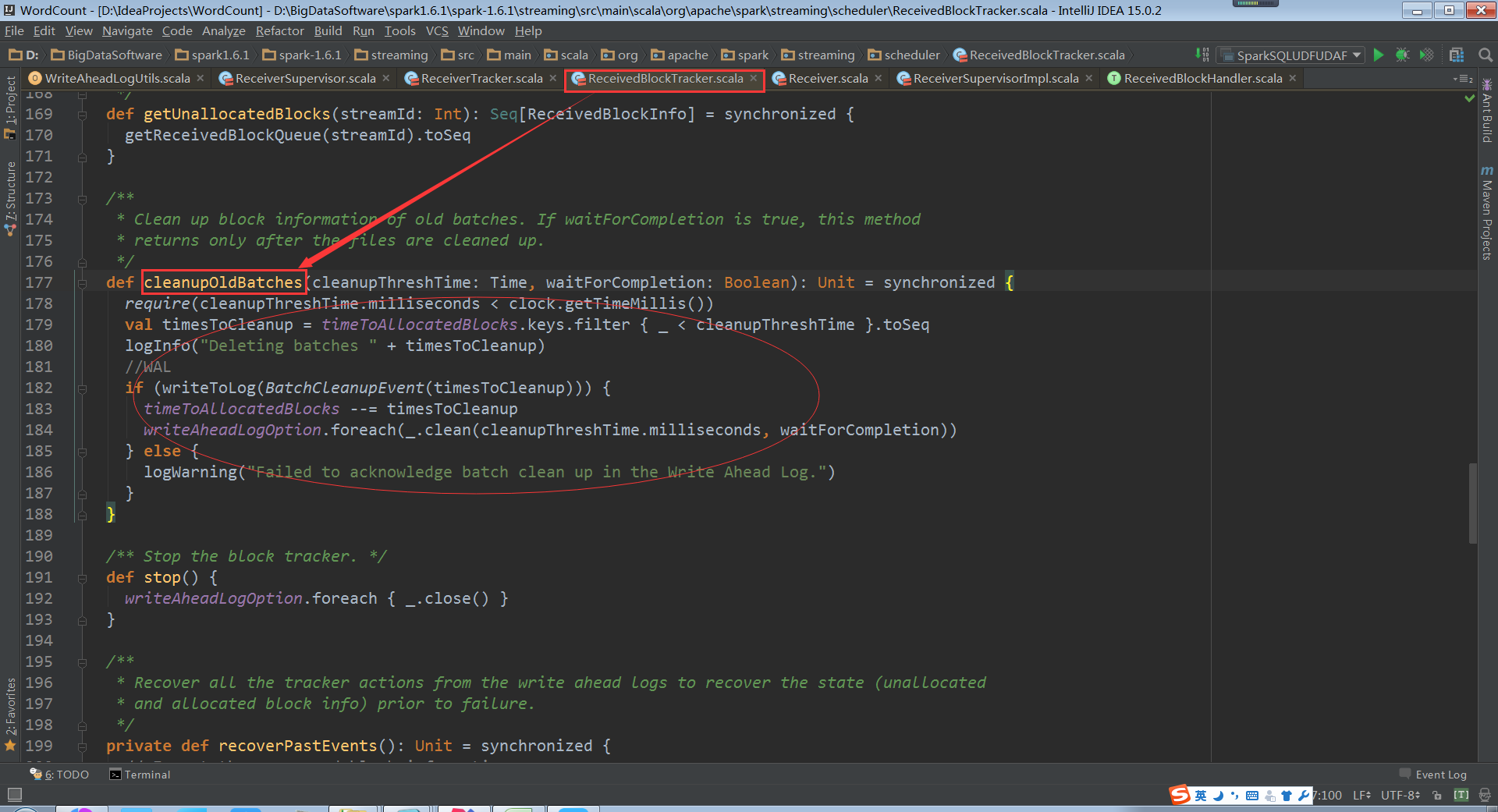
cleanupOldBatches:因为时间的推移会不断的生成RDD,RDD会不断的处理数据,
因此不可能一直保存历史数据
writeToLog源码
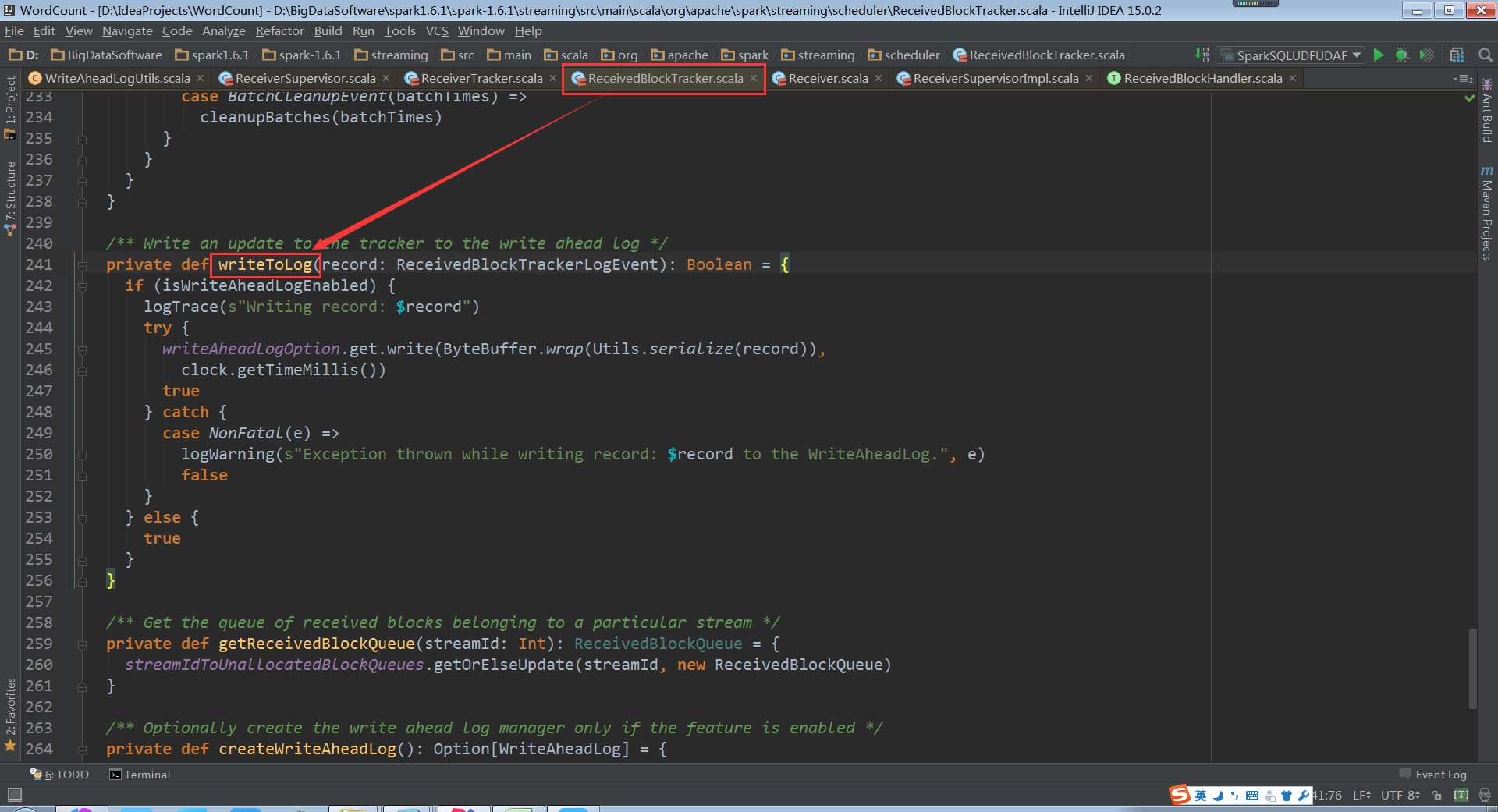
总结:
WAL对数据的管理包括数据的生成,数据的销毁和消费。上述在操作之后都要先写入到WAL的文件中
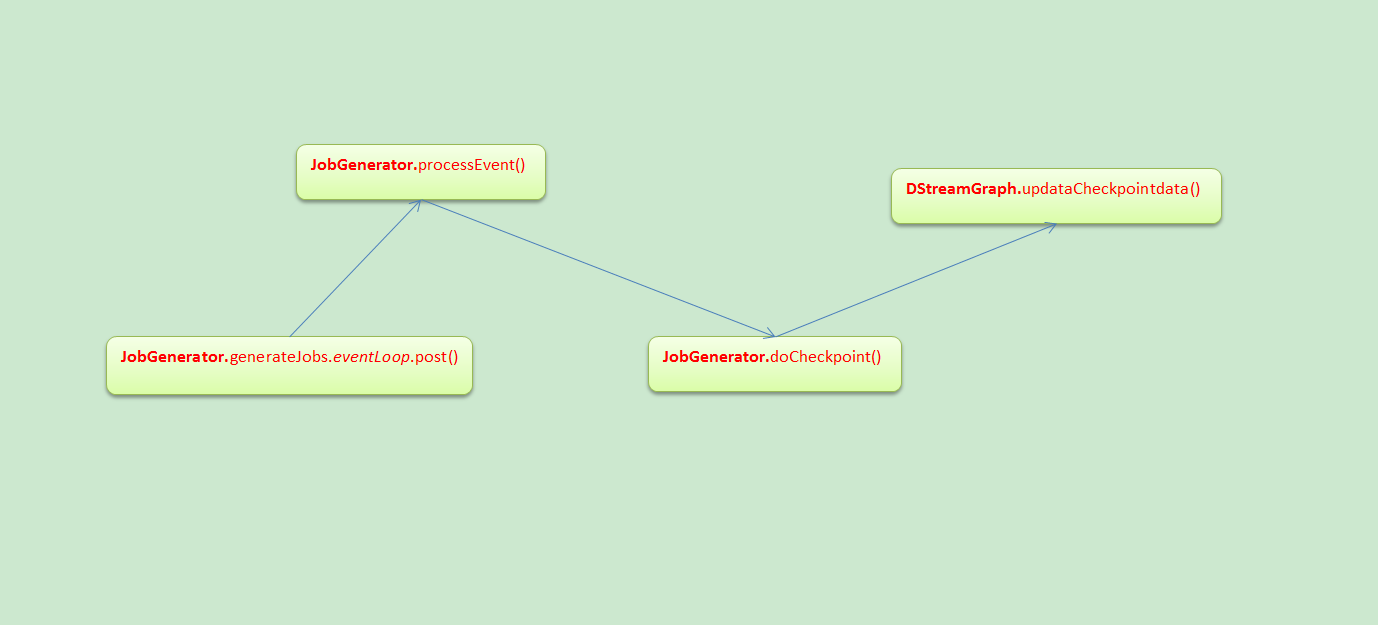
JobGenerator
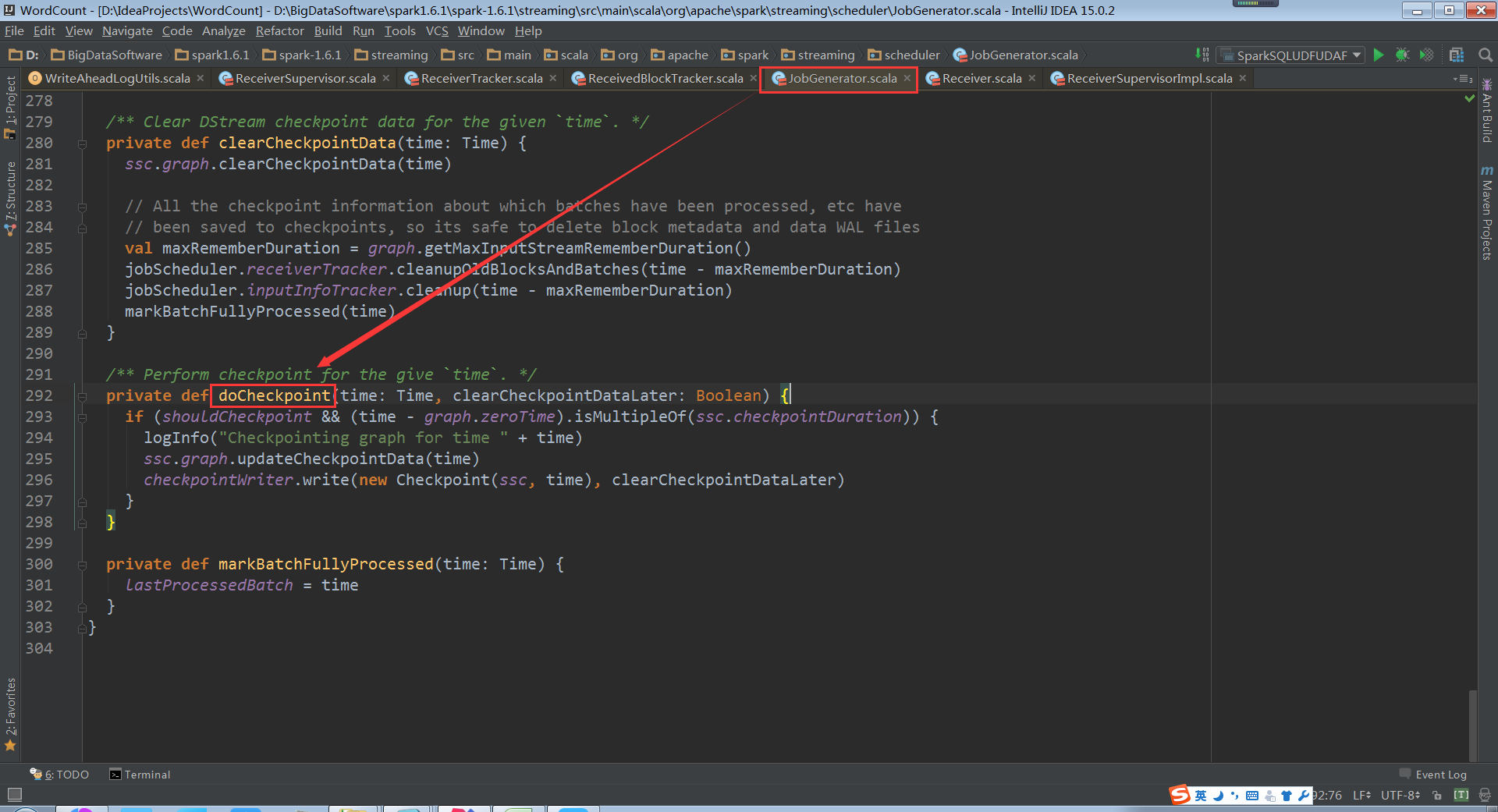
Checkpoint会有时间间隔Batch Duractions,Batch执行前和执行后都会进行checkpoint
doCheckpoint被调用的前后流程
generateJobs源码
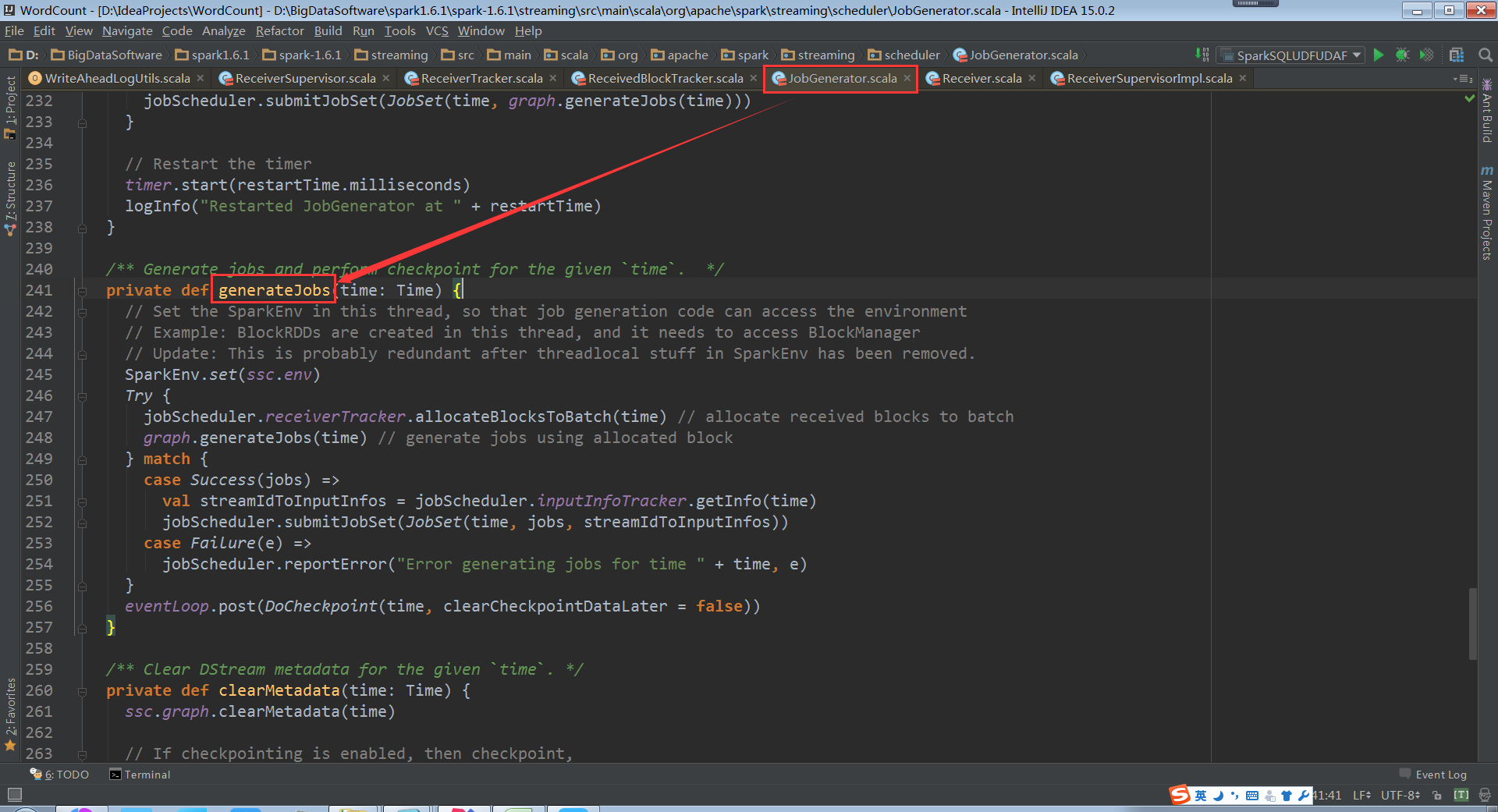
processEvent接收到消息
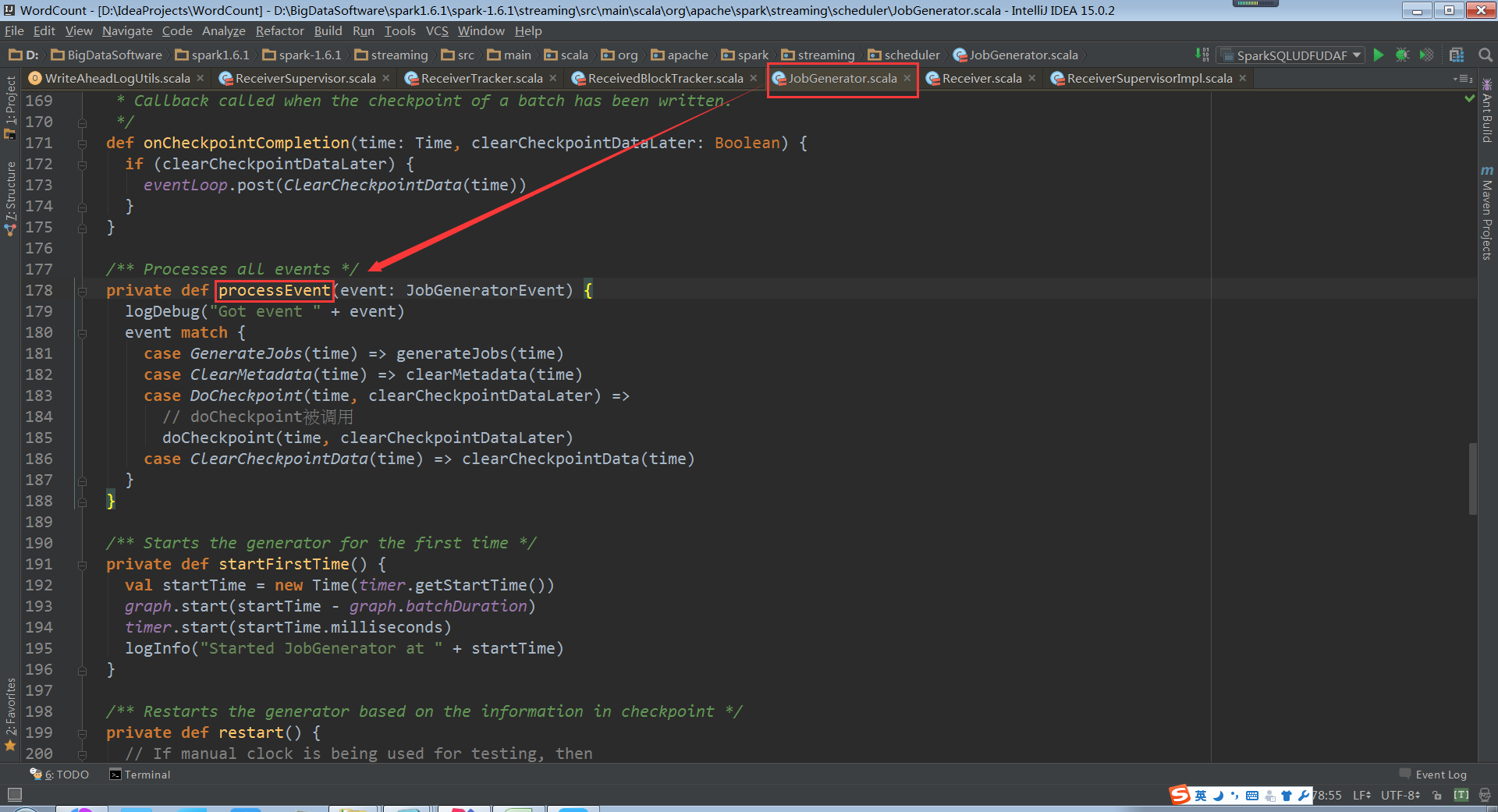
对当前的状态进行Checkpoint
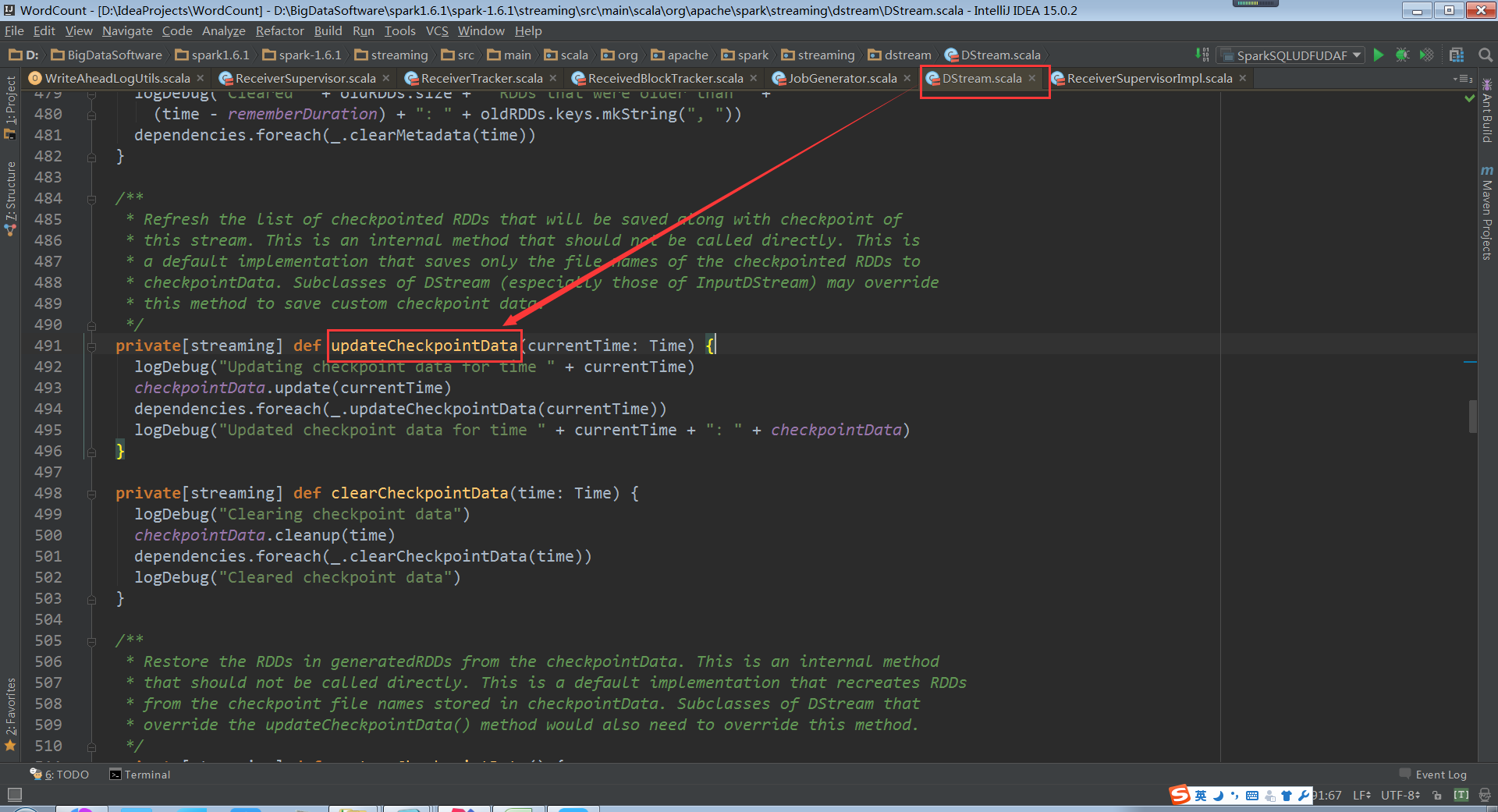
DStream中的updateCheckpointData源码(最终导致RDD的Checkpoint)
doCheckpoint中的shouldCheckpoint是状态变量
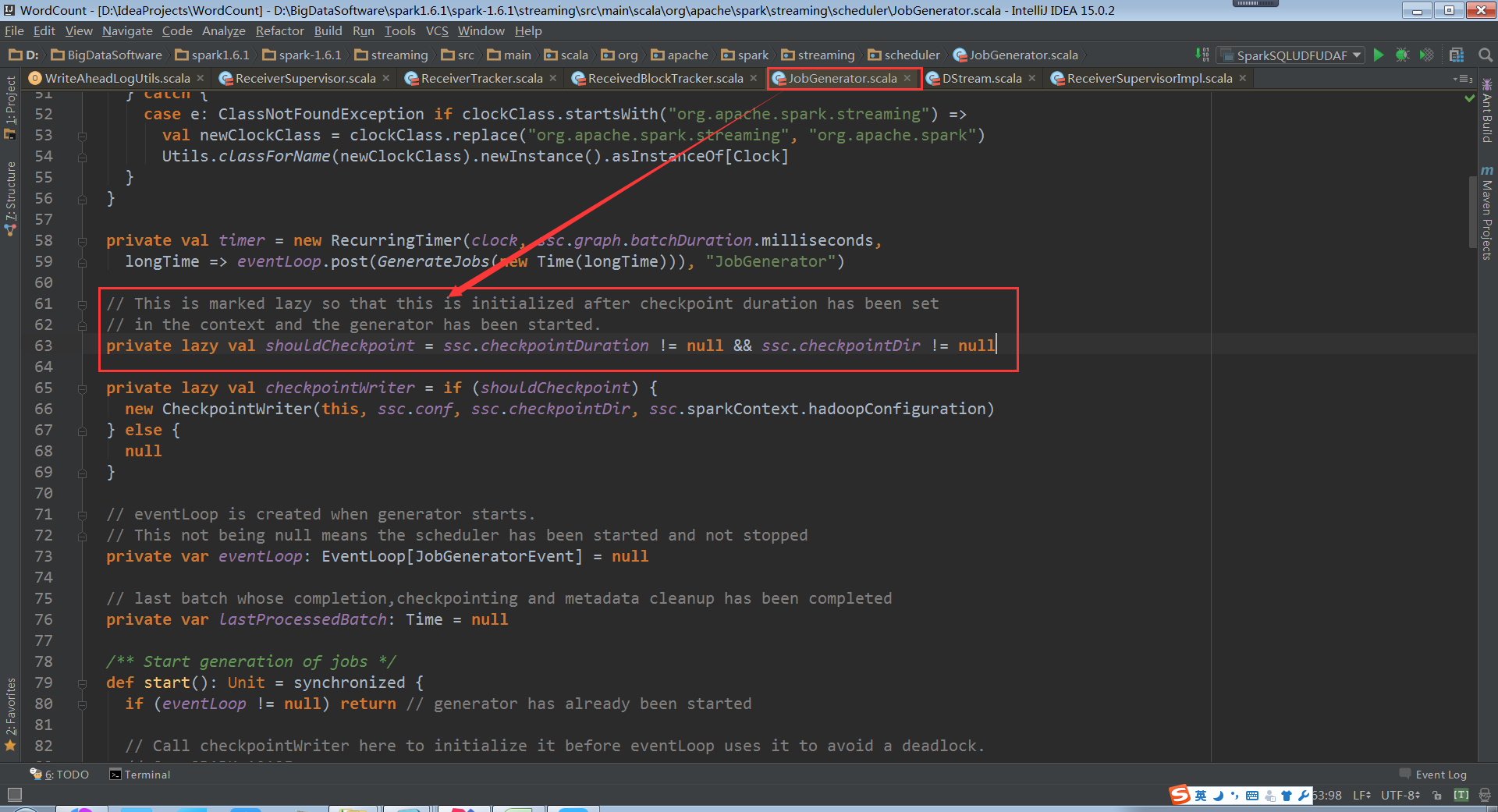
JobGenerator容错安全性
总结
a. ReceivedBlockTracker是通过WAL方式来进行数据容错的。
b. DStreamGraph和JobGenerator是通过checkpoint方式来进行数据容错的。















 1161
1161

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









