







Kylin是ebay开发的一套OLAP系统,主要是对hive中的数据进行预计算,利用hadoop的mapreduce框架实现。通过设计维度、度量,我们可以构建星型模型或雪花模型,生成数据多维立方体Cube,基于Cube可以做钻取、切片、旋转等多维分析操作。
Apache Kylin核心思想
简单来说,Kylin的核心思想是预计算,用空间换时间,即对多维分析可能用到的度量进行预计算,将计算好的结果保存成Cube,供查询时直接访问。把高复杂度的聚合运算、多表连接等操作转换成对预计算结果的查询,这决定了Kylin能够拥有很好的快速查询和高并发能力。
Apache Kylin架构
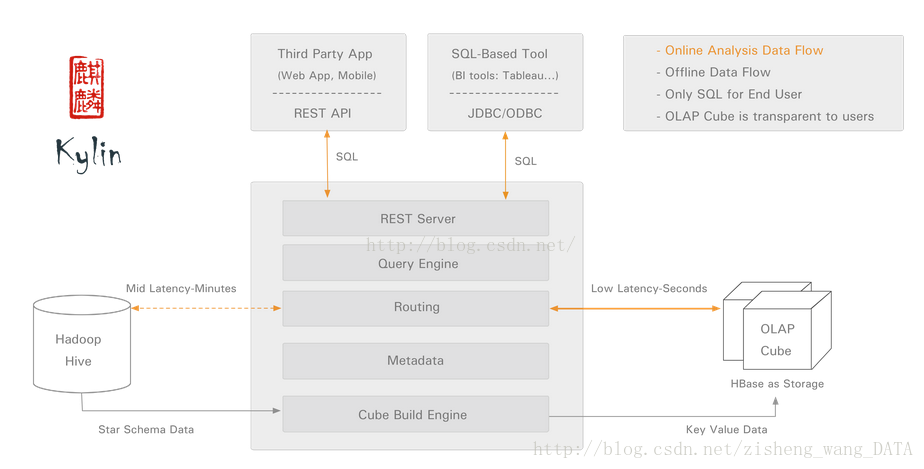
kylin由以下几部分组成:
· REST Server:提供一些restful接口,例如创建cube、构建cube、刷新cube、合并cube等cube的操作,project、table、cube等元数据管理、用户访问权限、系统配置动态修改等。除此之外还可以通过该接口实现SQL的查询,这些接口一方面可以通过第三方程序的调用,另一方也被kylin的web界面使用。
· jdbc/odbc接口:kylin提供了jdbc的驱动,驱动的classname为
org.apache.kylin.jdbc.Driver,使用的url的前缀jdbc:kylin:,使用jdbc接口的查询走的流程和使用RESTFul接口查询走的内部流程是相同的。这类接口也使得kylin很好的兼容tebleau甚至mondrian。
· Query引擎:kylin使用一个开源的Calcite框架实现SQL的解析,相当于SQL引擎层。
· Routing:该模块负责将解析SQL生成的执行计划转换成cube缓存的查询,cube是通过预计算缓存在hbase中,这部分查询是可以再秒级甚至毫秒级完成,而还有一些操作使用过查询原始数据(存储在hadoop上通过hive上查询),这部分查询的延迟比较高。
· Metadata:kylin中有大量的元数据信息,包括cube的定义,星状模型的定义、job的信息、job的输出信息、维度的directory信息等等,元数据和cube都存储在hbase中,存储的格式是json字符串,除此之外,还可以选择将元数据存储在本地文件系统。
· Cube构建引擎:这个模块是所有模块的基础,它负责预计算创建cube,创建的过程是通过hive读取原始数据然后通过一些mapreduce计算生成Htable然后load到hbase中。
Apache Kylin关键流程
在kylin中,最关键的两个流程是cube的预计算过程和SQL查询转换成cube的过程,cube的构造可以分成cube的构建和cube的合并,首先需要创建一个cube的定义,包括设置cube名、cube的星状模型结构,dimension信息、measure信息、设置where条件、根据hive中事实表定义的partition设置增量cube,设置rowkey等
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 239
239











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









