










文章链接:https://arxiv.org/pdf/1608.07242.pdf
文章是2016年8月放到arvix上的,看格式应该是投到CVPR2017了,Korea的POSTECH这个团队做的,之前比较有名的还有MDNet和CNN-SVM,相信大家应该不陌生哈。
这篇文章的简称是TCNN(树结构的CNN),是VOT2016的冠军,效果很棒,想法也蛮有新意,下面听我一一道来。
1. Motivations
这篇文章最重要的出发点是Model的可靠性问题(reliability),大部分现有的trackers默认Model是可靠的,就是说模型一直随着目标的变化而稳定变化,这样就有一个问题,当目标被遮挡,或者说在跟丢了情况下,再更新的模型其实已经被污染了,可靠性很低,其实是不能用这样的模型进行后续的跟踪的。
TCNN用了很多个CNN的模型,并构建成一棵树的结构,如图1所示,红色的框越粗说明对应的CNN模型的可靠性(reliability)越高。连接的红色的线越粗,说明两个CNN之间的相关性越高(affinity)。黑色的箭头越粗表示对应的CNN模型对目标估计的权重越高。TCNN还对每一个CNN模型进行了可靠性评估。下面来看看具体是怎么做的。
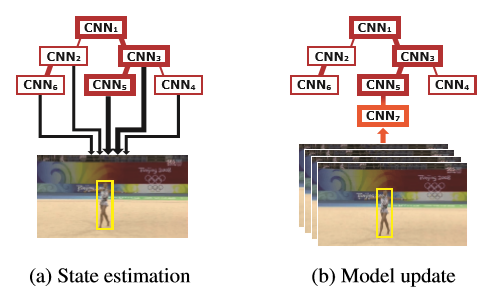
图1:树形结构示意
2. TCNN Algorithm
2.1 CNN网络结构
每个CNN的网络结构是一样的,前面的卷积层的参数共享,是来自于事先用imageNet训练好的VGG-M网络,后面的全连接层是作者自己设计加上的,在第一帧的时候随机初始化并进行迭代训练,后面每次更新的时候都只更新全连接层的参数。图2是网络结构示意图。
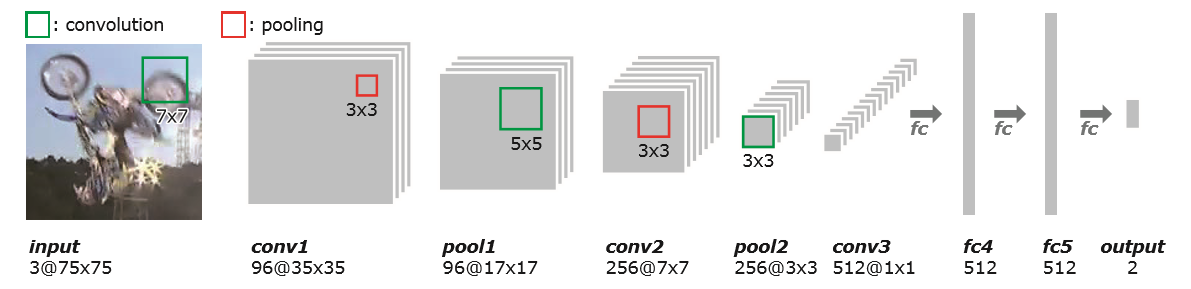
图2:网络结构示意图
由于一棵树里每次的active set(定义为最近更新的10个网络)有很多个CNN,那么怎样让计算过程或者说特征提取过程简化一些?每次在detection的时候采样好几百个candidates,每个candidate都要提取特征,这个计算量可想而知。
这里作者是这样做的,对每一个candidate,在用一个CNN提取特征时,前面的卷积层的特征conv3是共享的,每个节点上的CNN其实只需要保存全连接层即可,也即conv3的特征的提取只需要进行一次,所有的CNN都用同样的conv3的特征,不同的是他们的全连接层。
另外,在确定了目标之后,需要将这个目标保存为训练样本,也只需要保存这个conv3特征即可,不需要再重复计算一次。
网络的训练:第一帧以0.001的学习率迭代50次,之后每次更新以学习率0.003迭代10次,用标准的随机梯度下降(SGD)和softmax交叉熵损失。
2.2 树的结构
树用表示。其中V是顶点集,后者是边的集合。
每个顶点v:包含的信息有对应的CNNv,和帧集Fv。
每条边edge:用这个分数来衡量边。
2.3 目标查找(target state estimation)
目标候选框生成:以上一帧的位置为中心,在(x,y,s)空间由多变量正态分布生成256个候选框,s是尺度scale。
对这些candidates:,计算他们是否为目标的得分:
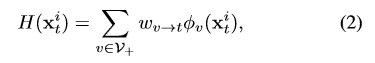
那么目标就确定为:
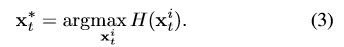
现在需要确定(2)式中的权重系数,就是图一中黑色箭头所代表的量。这个权重从两个量来定义,第一个是:
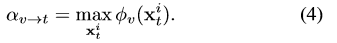
表示的是CNNv和目标的相关性(affinity),用CNNv对所有的candidates的最大分类得分来衡量。第二个是:
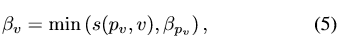
表示的是CNNv这个网络模型自身的可靠性(reliability)。取得是当前的CNNv与他的父节点相连的边的得分与父节点的reliability中小的那一个。最后的CNNv对于t时刻的candidate的权重是这样定义的:
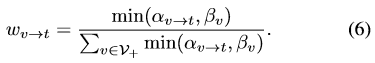
这里(3)式确定的位置还要做一次bounding box regression之后才得到这一帧最终的位置。
2.4 整体模型更新(model update)
采用的策略是每做10次的tracking,创建一个新的CNNn节点。选择这个新的节点的父节点的方式:
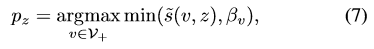
即选择能够使新节点的可靠性最高的节点作为其父节点。这过去的10帧就是新节点对应的帧集Fn。以选择的父节点CNNpv为起点,用其自己的帧集Fn和它的父节点的帧集Fpv对CNNpv的全连接层进行fine-tuning,最后得到的就是CNNn。
每次做tracking的时候保持一个active set,里面是10个最新更新的CNN模型,用这个active set来做跟踪。
3. Experiment
速度是1.5FPS。
首先在OTB50上做了自己的对比实验:
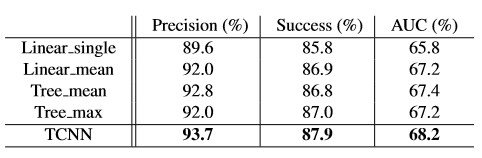
可以看到是使用树的结构,并用加权检测而不是简单平均或者用最大权重的来做检测,都对结果是有贡献的。
OTB50:
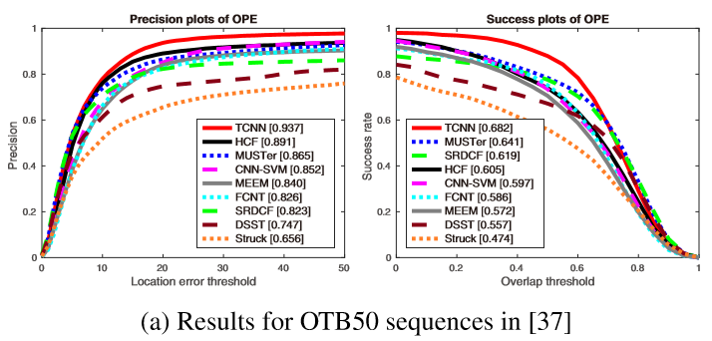
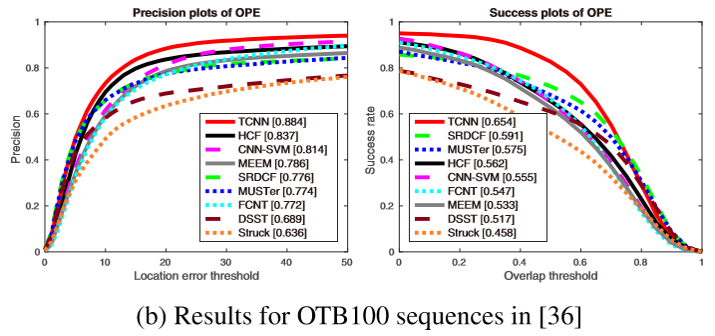
OTB100:
VOT2015:
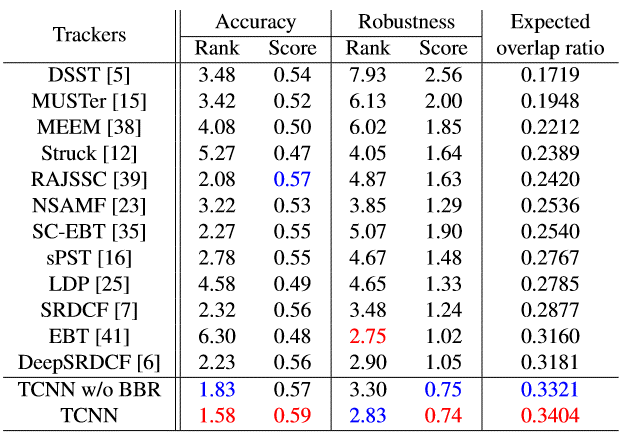
从上面三个实验可以看到效果是非常好的。不过这个方法是在ECO之前的,所以没有与ECO进行比较,ECO的效果比其更好哈,可以看我的上一篇博客。
总结一下效果好的原因:
(1) 使用了多个CNN模型进行检测(10个)
(2) 使用了树的结构来组织CNN模型,避免它们只对最近的帧过拟合
(3) CNN会一直有新的模型加进来,并且是经过fine-tuning的
(4)在确定最终的位置时还做了Bounding Box Regression,进一步提高定位准确性
微信公众号同步更新,欢迎关注:















 8077
8077











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









