







文章目录
简介
什么是文档?
在大多数应用中,多数实体或对象可以被序列化为包含键值对的 JSON 对象。 一个 键 可以是一个字段或字段的名称,一个 值 可以是一个字符串,一个数字,一个布尔值, 另一个对象,一些数组值,或一些其它特殊类型诸如表示日期的字符串,或代表一个地理位置的对象:
在 Elasticsearch 中,术语 **文档 **有着特定的含义。它是指最顶层或者根对象, 这个根对象被序列化成 JSON 并存储到 Elasticsearch 中,指定了唯一 ID。
ES核心概念
1)Cluster:集群。
ES可以作为一个独立的单个搜索服务器。不过,为了处理大型数据集,实现容错和高可用性,ES可以运行在许多互相合作的服务器上。这些服务器的集合称为集群。
2)Node:节点。
形成集群的每个服务器称为节点。
3)Shard:分片。
当有大量的文档时,由于内存的限制、磁盘处理能力不足、无法足够快的响应客户端的请求等,一个节点可能不够。这种情况下,数据可以分为较小的分片。每个分片放到不同的服务器上。
当你查询的索引分布在多个分片上时,ES会把查询发送给每个相关的分片,并将结果组合在一起,而应用程序并不知道分片的存在。即:这个过程对用户来说是透明的。
4)Replia:副本。
为提高查询吞吐量或实现高可用性,可以使用分片副本。
副本是一个分片的精确复制,每个分片可以有零个或多个副本。ES中可以有许多相同的分片,其中之一被选择更改索引操作,这种特殊的分片称为主分片。
当主分片丢失时,如:该分片所在的数据不可用时,集群将副本提升为新的主分片。
5)全文检索。
全文检索就是对一篇文章进行索引,可以根据关键字搜索,类似于mysql里的like语句。
全文索引就是把内容根据词的意义进行分词,然后分别创建索引,例如”你们的激情是因为什么事情来的” 可能会被分词成:“你们“,”激情“,“什么事情“,”来“ 等token,这样当你搜索“你们” 或者 “激情” 都会把这句搜出来。
名词术语
- NRT(准实时): Elasticsearch是一个接近实时的搜索平台。这意味着,从索引一个文档直到这 个文档能够被搜索到有一个轻微的延迟(通常是1秒)。
- Node(节点):单个的装有ElasticSearch服务并且提供故障转移和扩展的服务器
- Cluster(集群):一个集群就是由一个或多个Node组织在一起共同工作,共同分享整个数据具有负载均衡功能的集群,集群名称是唯一标识,因为一个节点只能通过指定某个集群的名字,来加入这个集群
数据组织
- Document(文档):可以被索引的基本数据单位
- Index(索引):含有相同属性文档的集合
- Type(类型):索引可以定义一个或者多个类型,文档必须属于一个类型
- Field(列):Field是ElasticSearch中最小单位,相当于数据的某一列
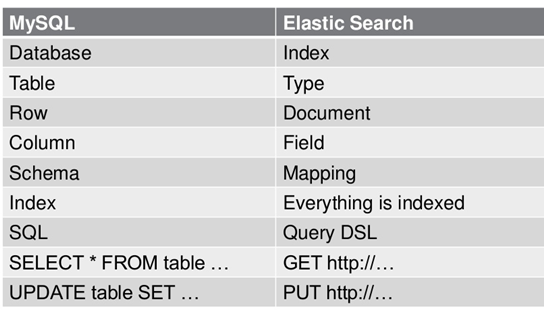
ES数据架构的主要概念(与关系数据库Mysql对比)
(1)Index:关系型数据库中的数据库(DataBase),等价于ES中的索引(Index)
(2)Type:一个数据库下面有N张表(Table),等价于1个索引Index下面有N多类型(Type), 类似于数据库的表概念,但是这个目前已经弃用,在8.x被正式移除
(3)Document:一个数据库表(Table)下的数据由多行(ROW)多列(column,属性)组成,等价于1个Type由多个文档(Document)组成, 每个文档有多个Field
(4)Mapping:在一个关系型数据库里面,schema定义了表、每个表的字段,还有表和字段之间的关系。 与之对应的,在ES中:Mapping定义索引下的Type的字段处理规则,即索引如何建立、索引类型、是否保存原始索引JSON文档、是否压缩原始JSON文档、是否需要分词处理、如何进行分词处理等。
(5)RESTAPI:在数据库中的增insert、删delete、改update、查search操作等价于ES中的增PUT/POST、删Delete、改_update、查GET.
索引webshop的映射信息为例
http://localhost:9200/webshop
{
"mappings": { //mapping映射定义
"book":{ //定义的type是book类型
"properties":{ //该类型所有的属性定义集合
"id":{
"type":"long",//属性类型long
"index":true,//释放需要索引
"store":true//是否需要存储
},
"title":{
"type":"text",//text类型会进行分词
"analyzer":"ik_max_word"//分词器类型
},
"images": {
"type": "keyword",//整体作为关键词
"index": "false"
},
"price": {
"type": "float"
}
}
}
}
}
webshop:为web商店,相当于一个数据库名为webshop
mappings:定义一个索引里面的所有类型type,每个type相当于一个表名,但是6.x只能有一个type(根据规划,Elastic 6.x 版只允许每个 Index 包含一个 Type,8.x 版将会彻底移除 Type)
book:定义了一个book类型的type=book表
properties:定义了type类型所属的所有属性名=表中的列明定义
属性的字段类型:
文档元数据结构-三个必须元数据
一个文档不仅仅包含它的数据 ,也包含 元数据 —— 有关 文档的信息。
三个必须的元数据元素如下:
- _index 文档在哪存放
- _type 文档表示的对象类别
- _id 文档唯一标识
_index 索引
一个 索引 应该是因共同的特性被分组到一起的文档集合。
例如,你可能存储所有的产品在索引 products 中,
存储所有销售的交易到索引 sales 中。
虽然也允许存储不相关的数据到一个索引中,但这通常看作是一个反模式的做法。
一个索引名,这个名字必须小写,不能以下划线开头,不能包含逗号
提示
实际上,在 Elasticsearch 中,我们的数据是被存储和索引在 分片 中,而一个索引仅仅是逻辑上的命名空间,
这个命名空间由一个或者多个分片组合在一起。 然而,这是一个内部细节,我们的应用程序根本不应该关心分片,对于应用程序而言,只需知道文档位于一个
索引 内。 Elasticsearch 会处理所有的细节。
_type类型
相当于数据库中的表,把一个相同的数据结构归为一个类型,这个结构也可以对应Java的类。
数据可能在索引中只是松散的组合在一起,但是通常明确定义一些数据中的子分区是很有用的。 例如,所有的产品都放在一个索引中,但是你有许多不同的产品类别,比如 “electronics” 、 “kitchen” 和 “lawn-care”。
这些文档共享一种相同的(或非常相似)的模式:他们有一个标题、描述、产品代码和价格。他们只是正好属于“产品”下的一些子类。
Elasticsearch 公开了一个称为 types (类型)的特性,它允许您在索引中对数据进行逻辑分区。不同 types 的文档可能有不同的字段,但最好能够非常相似。 我们将在 类型和映射 中更多的讨论关于 types 的一些应用和限制。
一个 _type 命名可以是大写或者小写,但是不能以下划线或者句号开头,不应该包含逗号, 并且长度限制为256个字符. 我们使用 blog 作为类型名举例。
根据规划,Elastic 6.x 版只允许每个 Index 包含一个 Type,7.x 版将会彻底移除 Type。
_id
相当于数据库中表的主键ID,但是在ES中_id是必须的,标识着文档数据的唯一性,而且只有一个主id.
ID 是一个字符串, 当它和 _index 以及 _type 组合就可以唯一确定 Elasticsearch 中的一个文档。 当你创建一个新的文档,要么提供自己的 _id ,要么让 Elasticsearch 帮你生成(如果不自己提供那么ES会自己在数据生成时自动生成一个ID)。
其他元数据
还有一些其他的元数据元素,他们在 类型和映射 进行了介绍。通过前面已经列出的元数据元素, 我们已经能存储文档到 Elasticsearch 中并通过 ID 检索它–换句话说,使用 Elasticsearch 作为文档的存储介质。
_mapping索引映射
Mapping是ES中的一个很重要的内容,它类似于传统关系型数据中table的schema,用于定义一个索引(index)的某个类型(type)的数据的结构。
在传统关系型数据库,我们必须首先创建table并同时定义其schema,如下面的SQL语句。下面代码中小括号内的代码的作用就是定义person_info的schema(模式)。
create table person_info
(
name varchar(20),
age tinyint
)
在ES中,我们无需手动创建type(相当于table)和mapping(相关与schema)。在默认配置下,ES可以根据插入的数据自动地创建type及其mapping。在下面的API介绍部分中,会做相关的试验。当然,在实际使用过程中我们可能就想硬性规定mapping,可以通过配置文件关闭ES的自动创建mapping功能,一般都使用自动创建模式。
mapping中主要包括字段名、字段数据类型和字段索引类型这3个方面的定义。
-
字段名:这就不用说了,与传统数据库字段名作用一样,就是给字段起个唯一的名字,好让系统和用户能识别。
-
字段数据类型:定义该字段保存的数据的类型,不符合数据类型定义的数据不能保存到ES中。下表列出的是ES中所支持的数据类型。(大类是对所有类型的一种归类,小类是实际使用的类型。)
mapping和java中的类定义非常相似,这也是它数据存储和搜索的基本,毕竟我们不肯能像前面的篇章那样一直使用id作为搜索的内容吧。而如果要使用字段搜索则必须进行映射,特别是中文搜索不然分词处理可能就不是很理想或者完全无法搜索到结果。
说明:6.0.0版本中已经没有string类型了而是以text取代,这是在看其他老版本的教程中发现的问题,最后在官网提供的文档中给出了一下基本类型
| 大类 | 包含的小类 |
|---|---|
| string类型 | (text,and,keyword:6.0.0版本)/(string:6.0.0版本之前) |
| Numeric datatypes数字类型 | long, integer, short, byte, double, float, half_float, scaled_float |
| Boolean datatype布尔类型 | boolean |
| Binary datatype二进制类型 | binary |
| Range datatypes 范围类型 | integer_range, float_range, long_range, double_range, date_range |
当然还有其他复合类型,比如IP类型,email类型具体可以参考官方文档
https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-types.html
字段索引类型:索引是ES中的核心,ES之所以能够实现实时搜索,完全归功于Lucene这个优秀的Java开源索引。在传统数据库中,如果字段上建立索引,我们仍然能够以它作为查询条件进行查询,只不过查询速度慢点。而在ES中,字段如果不建立索引,则就不能以这个字段作为查询条件来搜索。也就是说,不建立索引的字段仅仅能起到数据载体的作用。string类型的数据肯定是日常使用得最多的数据类型,下面介绍mapping中string类型字段可以配置的索引类型。
| 索引类型 | 解释 |
|---|---|
| analyzed | 首先分析这个字符串,然后再建立索引。换言之,以全文形式索引此字 |
| not_analyzed | 索引这个字段,使之可以被搜索,但是索引内容和指定值一样。不分析此字段。 |
| -no | 不索引这个字段。这个字段不能被搜索到。 |
如果索引类型设置为analyzed,在表示ES会先对这个字段进行分析(一般来说,就是自然语言中的分词),ES内置了不少分析器(analyser),如果觉得它们对中文的支持不好,也可以使用第三方分析器。由于笔者在实际项目中仅仅将ES用作普通的数据查询引擎,所以并没有研究过这些分析器。如果将ES当做真正的搜索引擎,那么挑选正确的分析器是至关重要的。
mapping中除了上面介绍的3个主要的内容外,还有其他的定义内容,详见官网文档。
实际操作REST-API
REST-API常见操作说明
| method | URL | remark |
|---|---|---|
| put | localhost:9200/索引名称/类型名称/文档id | 创建文档—指定文档Id |
| POST | localhost:9200/索引名称/类型名称 | 创建文档—随机文档Id |
| POST | localhost:9200/索引名称/类型名称/文档id/_update | 修改文档(部分修改) |
| DELETE | localhost:9200/索引名称/类型名称/文档id | 删除文档 |
| POST | localhost:9200/索引名称/类型名称/_search | 查询所有 |
相关的返回参数:
- took:耗费了几毫秒
- timed_out:是否超时
- _shards:数据拆成了5个分片,所以对于搜索请求,会打到所有的primary shard(或者是它的某个replica shard也可以)
- hits.total:查询结果的数量,3个document
- hits.max_score:score的含义,就是document对于一个search的相关度的匹配分数,越相关,就越匹配,分数也高
- hits.hits:包含了匹配搜索的document的详细数据
query DSL查询特定语言
DSL:Domain Specified Language,特定领域的语言
http request body:请求体,可以用json的格式来构建查询语法,比较方便,可以构建各种复杂的语法,比query string search肯定强大多了
//queryDSL模板
GET /index/type/_search
{
"query" : {},//查询部分匹配类型:match,match-all,match_phrase
"from": 1,//分页查询
"size": 1,//分页查询
"sort": [],//排序部分
"highlight": {},//高亮部分
}
更加适合生产环境的使用,可以构建复杂的查询
例1:查询名称包含suv的商品,同时按照价格降序排序
GET /test/cars/_search
{
"query" : {
"match" : {
"name" : "suv"
}
},
"sort": [
{ "price": "desc" }
]
}
而易见有三台suv,价格从高到低
基础操作
首先要有_index,_type和_mapping之后才能进行文档的query查询操作
环境:centos,curl(windos推荐postman图形化)
创建索引,系统自动创建_mapping
curl -XPUT 'http://192.168.0.91:9200/employee'
查看所有索引
curl '192.168.0.91:9200/_cat/indices?v'
查看一下索引mapping的内容:
curl -XGET "http://192.168.0.91:9200/employee/_mapping?pretty"
{
"employee" : {
"mappings" : { }
}
}
可以看出系统已经自动创建了索引,只是它的内容是空的,我们可以修改索引的mapping,并设置它对应的type,如下面的操作。
下面给employee这个索引加一个type,type name为employee并设置mapping:
curl -H 'Content-Type: application/json' -XPUT 'http://192.168.0.91:9200/employee/employee/_mapping?pretty' -d '
{
"employee": {
"properties": {
"account_number": {
"type": "integer"
},
"firstname": {
"type": "text"
},
"lastname": {
"type": "text"
},
"age": {
"type": "integer"
},
"gender": {
"type": "text"
},
"address": {
"type": "text"
},
"join_time": {
"type": "date",
"format": "yyyy-MM-dd"
}
}
}
}'
大多数情况下,我们想在索引创建的时候就将我们所需的mapping和其他配置确定好。下面的操作就可以在创建索引的同时,创建settings和mapping。
curl -XPUT "192.168.1.101:9200/index_test" -d '
{
"settings": {
"index": {
"number_of_replicas": "1", # 设置复制数
"number_of_shards": "5" # 设置主分片数
}
},
"mappings": { # 创建mapping
"test_type": { # 在index中创建一个新的type(相当于table)
"properties": {
"name": { # 创建一个字段(string类型数据,使用普通索引)
"type": "string",
"index": "not_analyzed"
},
"age": {
"type": "integer"
}
}
}
}
}'
注意这里的’号
删除索引时使用
curl -X DELETE '192.168.0.91:9200/employee'
插入测试数据
curl -H "Content-Type: application/json" -X PUT '192.168.0.91:9200/employee/employee/1' -d '
{"account_number":1,"firstname":"Virginia","lastname":"Ayala","age":39,"gender":"F","address":"171 Putnam Avenue","join_time":"2017-11-10"}'
curl -H "Content-Type: application/json" -X PUT '192.168.0.91:9200/employee/employee/2' -d '
{"account_number":2,"firstname":"Fulton","lastname":"Ayala","age":22,"gender":"M","address":"334 River Street","join_time":"2015-04-10"}'
curl -H "Content-Type: application/json" -X PUT '192.168.0.91:9200/employee/employee/3?pretty' -d '
{"account_number":3,"firstname":"Burton","lastname":"Ayala","age":37,"gender":"F","address":"685 School Lane","join_time":"2017-05-1"}'
curl -H "Content-Type: application/json" -X PUT '192.168.0.91:9200/employee/employee/4?pretty' -d '
{"account_number":4,"firstname":"Josie","lastname":"Ayala","age":42,"gender":"M","address":"27 Bay Parkway","join_time":"2016-12-10"}'
curl -H "Content-Type: application/json" -X PUT '192.168.0.91:9200/employee/employee/5?pretty' -d '
{"account_number":5,"firstname":"Hughes","lastname":"Ayala","age":32,"gender":"F","address":"510 Sedgwick Street","join_time":"2015-12-10"}'
curl -H "Content-Type: application/json" -X PUT '192.168.0.91:9200/employee/employee/6?pretty' -d '
{"account_number":6,"firstname":"Hall","lastname":"Ayala","age":24,"gender":"F","address":"927 Bay Parkway","join_time":"2017-9-10"}'
curl -H "Content-Type: application/json" -X PUT '192.168.0.91:9200/employee/employee/7?pretty' -d '
{"account_number":7,"firstname":"Deidre","lastname":"Ayala","age":35,"gender":"M","address":"685 School Lane","join_time":"2012-12-10"}'
查询所有
curl -H "Content-Type: application/json" -XPOST '192.168.0.91:9200/employee/employee/_search?q=*&pretty' -d '
{
"query": { "match_all": {} },
"size": 100
}'
查询所有"address"含有 "Street"的
curl -H "Content-Type: application/json" -XPOST '192.168.0.91:9200/employee/_search?pretty' -d '
{
"query": { "match": { "address" : "Street" } }
}'
match的变体(match_phrase),它会去匹配短语"Bay Parkway":
curl -H "Content-Type: application/json" -XPOST '192.168.0.91:9200/employee/_search?pretty' -d '
{
"query": { "match_phrase": { "address" : "Bay Parkway" } }
}'
范围查询年龄25<=&<=37
curl -H "Content-Type: application/json" -XPOST '192.168.0.91:9200/employee/_search?pretty' -d '
{
"query": {
"range": {
"age": {
"gte": 25,
"lte": 37
}
}
}
}'
基础信息REST-API
我们需要借助能够发送HTTP请求的工具调用这些API,工具是可以任意的,包括网页浏览器。这里利用Linux上的curl命令来发送HTTP请求。基本的命令结构为:
curl <-Xaction> url -d 'body'
# 这里的action表示HTTP协议中的各种动作,包括GET、POST、PUT、DELETE等。
注意。文中的示例代码里面包含了用户注释的文字,就是 # 号后面的文字。运行代码时,请注意删除这些注释。
查看集群(Cluster)信息相关API
(1)查看集群健康信息。
curl -XGET "192.168.1.101:9200/_cat/heath?v"
返回结果为:
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks
1440206633 18:23:53 elasticsearch green 1 1 0 0 0 0 0 0
返回结果的主要字段意义:
- cluster:集群名,是在ES的配置文件中配置的cluster.name的值。
- status:集群状态。集群共有green、yellow或red中的三种状态。green代表一切正常(集群功能齐全),yellow意味着所有的数据都是可用的,但是某些复制没有被分配(集群功能齐全),red则代表因为某些原因,某些数据不可用。如果是red状态,则要引起高度注意,数据很有可能已经丢失。
- node.total:集群中的节点数。
- node.data:集群中的数据节点数。
- shards:集群中总的分片数量。
- pri:主分片数量,英文全称为private。
- relo:复制分片总数。
- unassign:未指定的分片数量,是应有分片数和现有的分片数的差值(包括主分片和复制分片)。
我们也可以在请求中添加help参数来查看每个操作返回结果字段的意义。
curl -XGET "192.168.1.101:9200/_cat/heath?help"
返回结果如下:
epoch | t,time | seconds since 1970-01-01 00:00:00
timestamp | ts,hms,hhmmss | time in HH:MM:SS
cluster | cl | cluster name
status | st | health status
node.total | nt,nodeTotal | total number of nodes
node.data | nd,nodeData | number of nodes that can store data
shards | t,sh,shards.total,shardsTotal | total number of shards
pri | p,shards.primary,shardsPrimary | number of primary shards
relo | r,shards.relocating,shardsRelocating | number of relocating nodes
init | i,shards.initializing,shardsInitializing | number of initializing nodes
unassign | u,shards.unassigned,shardsUnassigned | number of unassigned shards
pending_tasks | pt,pendingTasks | number of pending tasks
中文分词mapping创建和搜索
curl -XPUT http://192.168.0.91:9200/ikindex //创建索引
//创建mapping,只有一个字段content,使用ik作为分词器"analyzer": “ik_smart”
curl -H "Content-Type: application/json" -XPOST http://192.168.0.91:9200/ikindex/chinese/_mapping?pretty -d'
{
"chinese": {
"_all": {
"analyzer": "ik_max_word",
"store": "false"
},
"properties": {
"content": {
"type": "text",
"store": "false",
"analyzer": "ik_max_word"
}
}
}
}'
插入测试数据
curl -H "Content-Type: application/json" -X PUT '192.168.0.91:9200/ikindex/chinese/1?pretty' -d '
{"content":"如花的年轻生命嘎然而止了,而周周妹儿的精神在世间永存,愿周周妹一路走好,周周妹儿家人们节哀"}'
查询测试
curl -H "Content-Type: application/json" -XPOST '192.168.0.91:9200/ikindex/_search?pretty' -d '
{
"query": { "match": { "content" : "嘎然而止" } }
}'
ES使用场景
通常我们面临问题有两个:
1)新系统开发尝试使用ES作为存储和检索服务器;
2)现有系统升级需要支持全文检索服务,需要使用ES。
以上两种架构的使用,以下链接进行详细阐述。
http://blog.csdn.net/laoyang360/article/details/52227541
一线公司ES使用场景:
1)新浪ES 如何分析处理32亿条实时日志 http://dockone.io/article/505
2)阿里ES 构建挖财自己的日志采集和分析体系 http://afoo.me/columns/tec/logging-platform-spec.html
3)有赞ES 业务日志处理 http://tech.youzan.com/you-zan-tong-ri-zhi-ping-tai-chu-tan/
4)ES实现站内搜索 http://www.wtoutiao.com/p/13bkqiZ.html














 1259
1259











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









