







package spark.xgb.test
import ml.dmlc.xgboost4j.scala.Booster
import ml.dmlc.xgboost4j.scala.spark.XGBoost
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
/**
* Created by zhaijianwei on 2017/12/7.
*/
object sparkWithDataFrame {
def main(args: Array[String]) {
if(args.length != 4){
println(
"usage: program num_of_rounds num_workers training_path test_path")
sys.exit(1)
}
val numRound = args(0).toInt
val num_workers = args(1).toInt
val inputTrainPath = args(2)
val inputTestPath = args(3)
// 使用kyro序列化,需要对序列化的类进行注册
val sparkConf = new SparkConf().setAppName("sparkWithDataFrame")
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
sparkConf.registerKryoClasses(Array(classOf[Booster]))
val sparkSession = SparkSession.builder().config(sparkConf).getOrCreate()
val trainDF = sparkSession.sqlContext.read.format("libsvm").load(inputTrainPath)
val testDF = sparkSession.sqlContext.read.format("libsvm").load(inputTestPath)
val params = List(
"eta" -> 0.1f,
"max_depth" -> 2,
"objective" -> "binary:logistic"
).toMap
val xgbModel = XGBoost.trainWithDataFrame(trainDF, params, numRound, num_workers, useExternalMemory = true)
xgbModel.transform(testDF).show()
}
}
提交spark的shell程序:
numRound=100
num_workers=10
inputTrainPath="/tmp/zjw/agaricus.txt.train" //存放训练数据的hdfs路径
inputValidPath="/tmp/zjw/agaricus.txt.test" //存放测试数据的hdfs路径
spark-submit --class spark.xgb.test.sparkWithDataFrame \
--num-executors 60 \
--executor-memory 16g \
--driver-memory 16g \
--executor-cores 4 \
--queue root.bdp_jdw_up \
--jars ./jar/xgboost4j-0.7.jar,./jar/xgboost4j-spark-0.7.jar \
./jar/spark_prac-1.0-SNAPSHOT.jar $numRound $num_workers $inputTrainPath $inputValidPath运行结果:
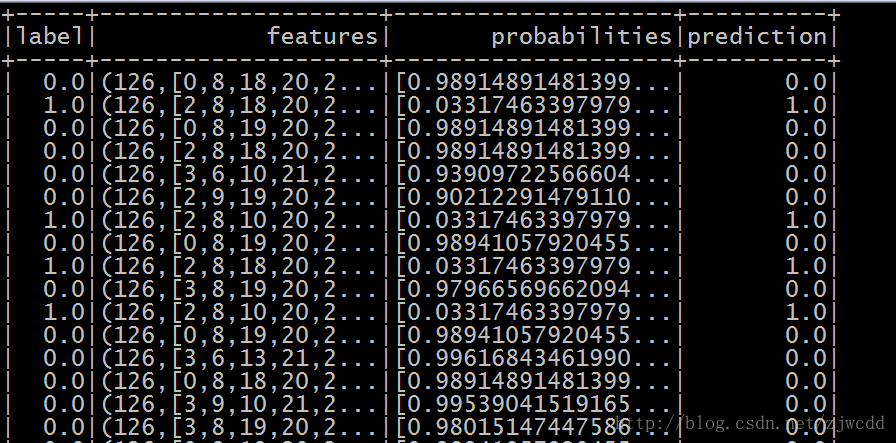














 7297
7297











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









