







转载
文章出自:http://blog.csdn.net/u012373815/article/details/53266301
使用idea构建maven 管理的spark项目 ,默认已经装好了idea 和Scala,mac安装Scala
那么使用idea 新建maven 管理的spark 项目有以下几步:- scala插件的安装
- 全局JDK和Library的设置
- 配置全局的Scala SDK
- 新建maven项目
- 属于你的”Hello World!”
- 导入spark依赖
- 编写sprak代码
- 打包在spark上运行
1.scala插件的安装
首先在欢迎界面点击Configure,选择plugins如下图所示:
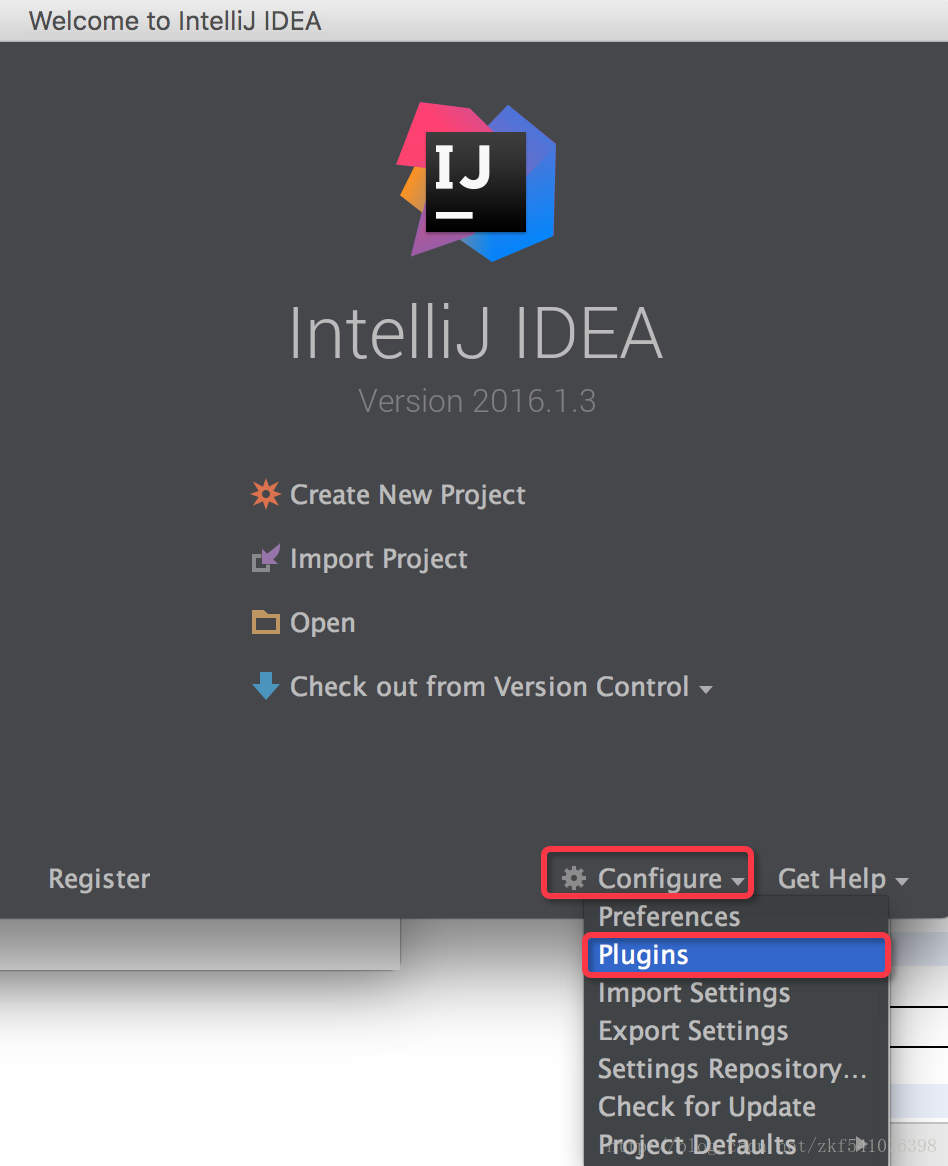
因为的安装过了所以事uninstall 没有安装的话是 install ,安装成功后,点击OK退出。
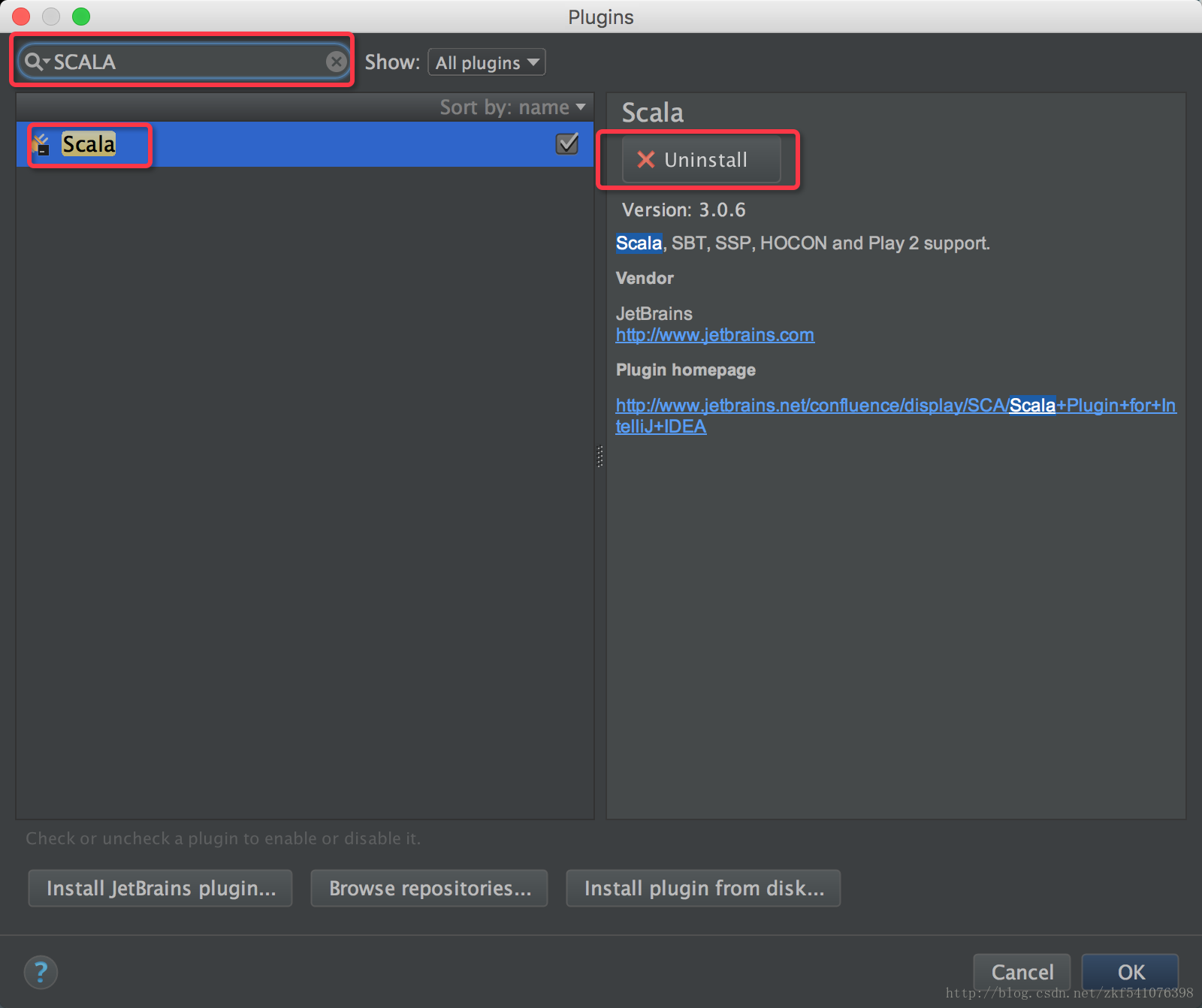
注意:插件安装完了之后,记得重启一下IntelliJ IDEA使得插件能够生效。
2.全局JDK和Library的设置
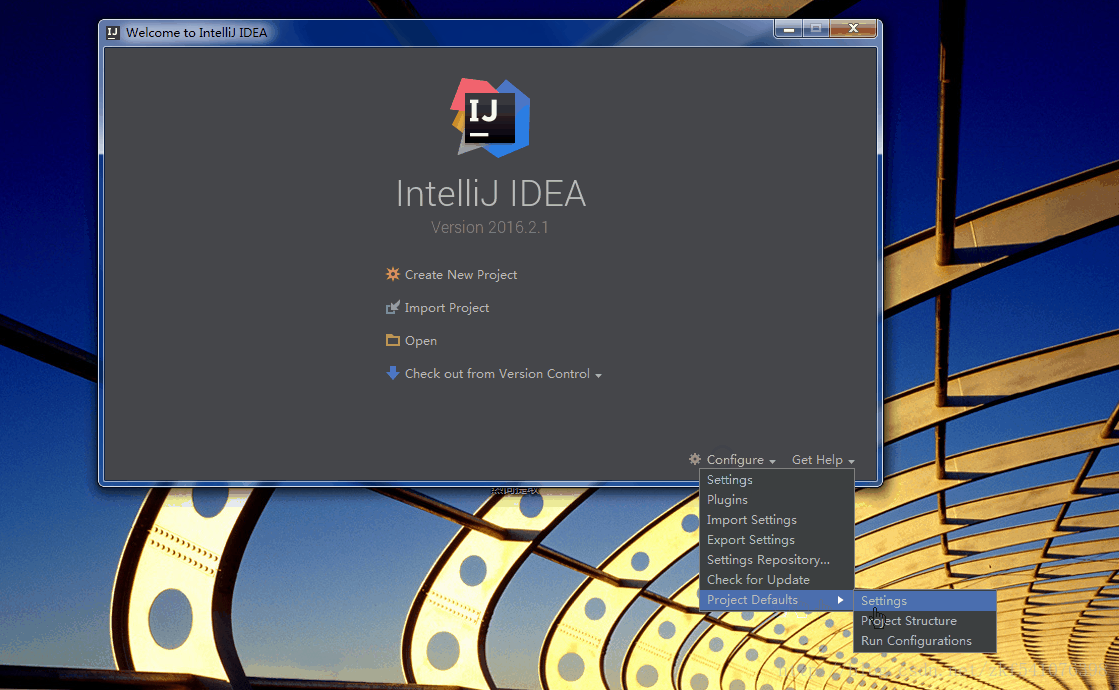
为了不用每次都去配置JDK,这里先进行一次全局配置。首先在欢迎界面点击Configure,然后在Project Defaults的下拉菜单中选择Project Structure,如下图所示:
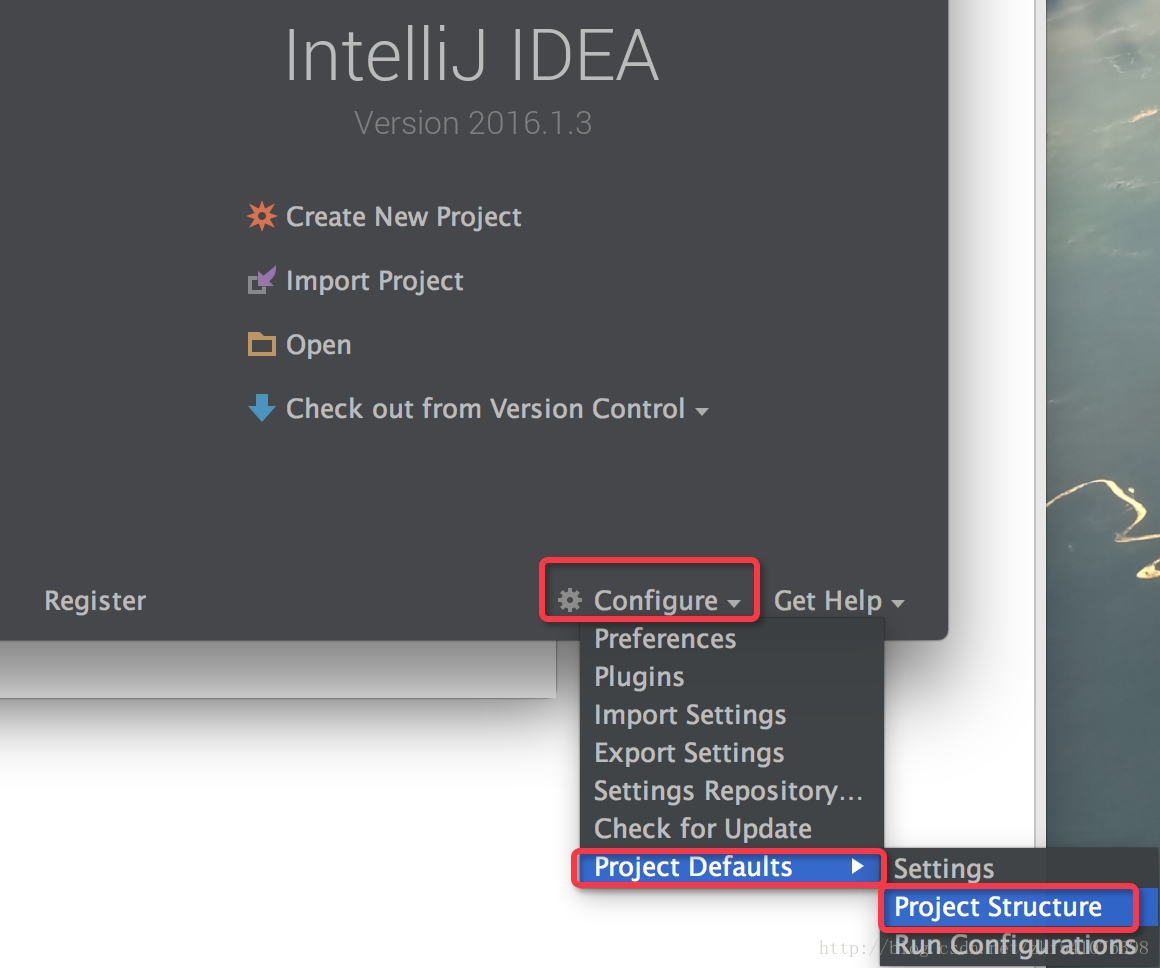
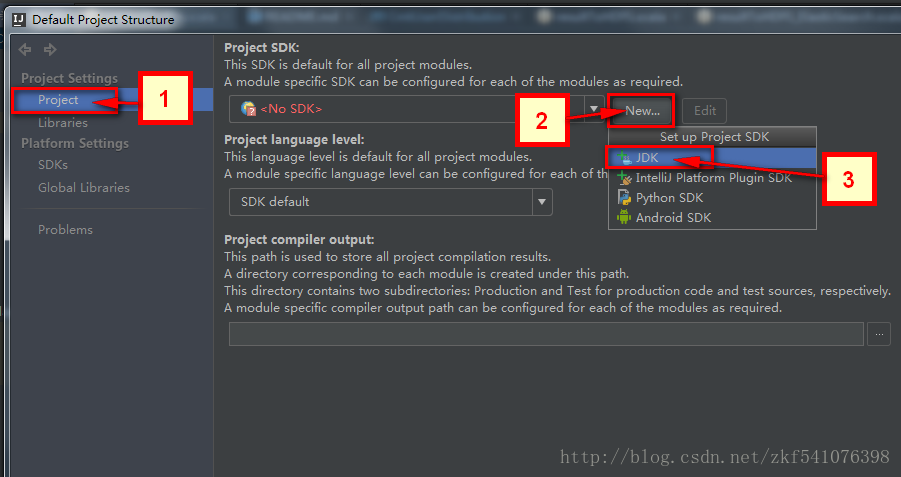
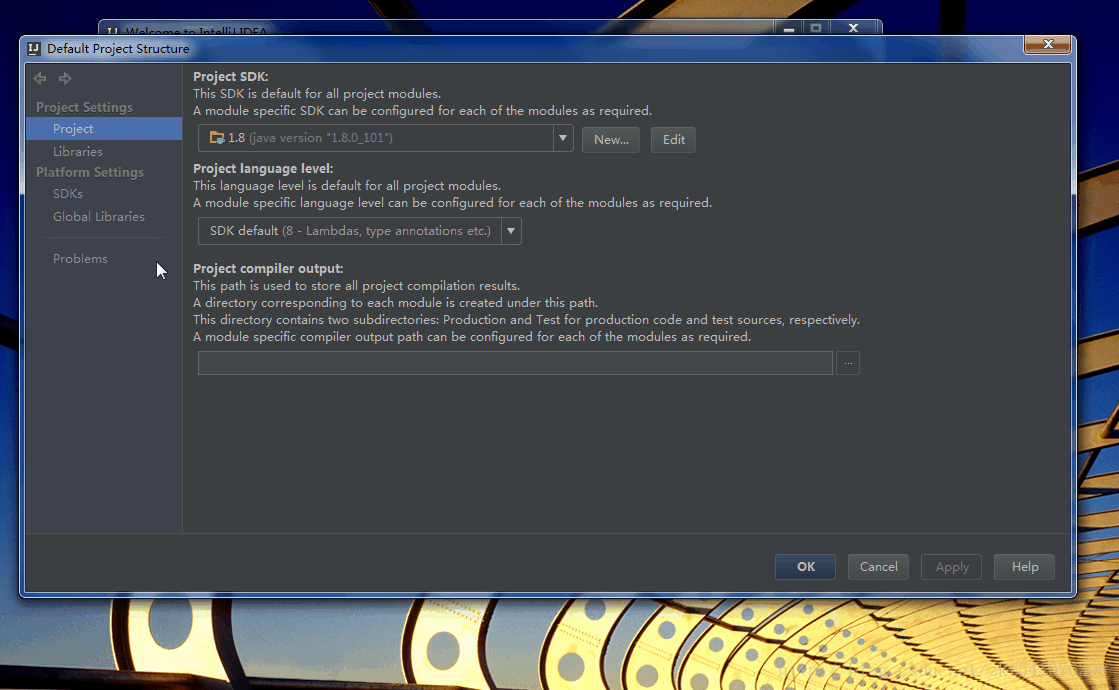
在打开的Default Project Structure界面的左侧边栏选择Project,在右侧打开的页面中创建一个新的JDK选项(一定要本机已经安装过JDK了),如下图所示步骤在下拉菜单中点击JDK后,在打开的对话框中选择你所安装JDK的位置,注意是JDK安装的根目录,就是JAVA_HOME中设置的目录。
3.配置全局的Scala SDK
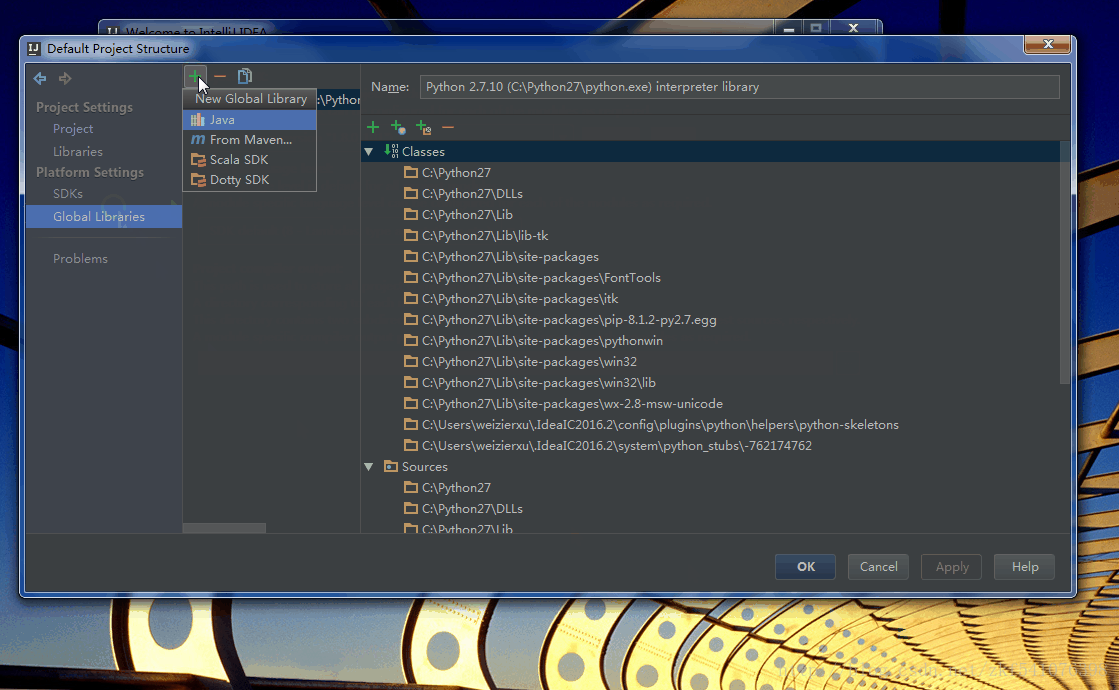
在欢迎页面的右下角点击Configure,然后在Project Defaults的下拉菜单中选择Project Structure,在打开的页面左侧选择Global Libraries,然后在中间一栏中有一个绿色的加号标志 +,点击后在下拉菜单中选择 Scala SDK
然后在打开的对话框中选择系统本身所安装的Scala(即System对应的版本),点击OK确定,这时候会在中间一栏位置处出现Scala的SDK,在其上右键点击后选择Copy to Project Libraries…,这个操作是为了将Scala SDK添加到项目的默认Library中去。整个流程如下面的动图所示。
4.新建maven项目
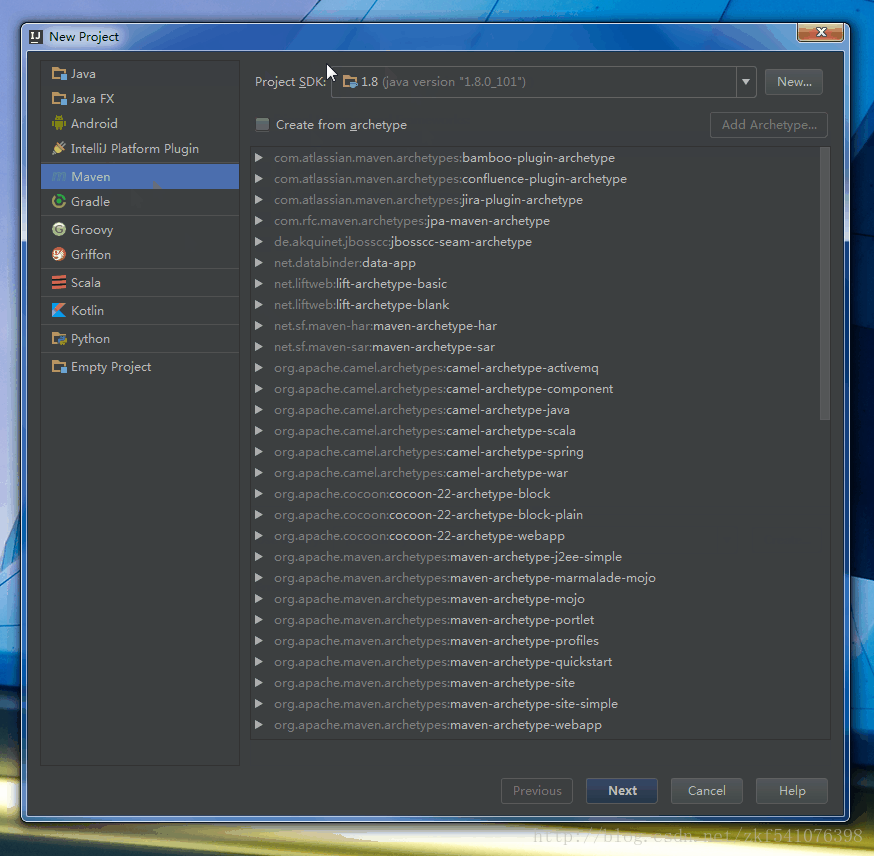
在欢迎界面点击Create New Project,在打开的页面左侧边栏中,选择Maven,然后在右侧的Project SDK一项中,查看是否是正确的JDK配置项正常来说这一栏会自动填充的,因为我们之前在1.3中已经配置过了全局的Project JDK了,如果这里没有正常显示JDK的话,可以点击右侧的New…按钮,然后指定JDK安装路径的根目录即可),然后点击Next,来到Maven项目最重要三个参数的设置页面,这三个参数分别为:GroupId, ArtifactId和Version. 步骤如下图所示:
5.属于你的”Hello World!”
在上一步中,我们已经创建了一个Maven工程
1. 为了让你的首次体验Scala更清爽一些,将一些暂时无关的文件和文件夹都勇敢的删除掉吧,主要有 main\java, main\resources 和 test 这三个;
2. 将Scala的框架添加到这个项目中,方法是在左侧栏中的项目名称上右键菜单中点击Add Framework Support…,然后在打开的对话框左侧边栏中,勾选Scala前面的复选框,然后点击确定即可(前提是上文中所述步骤都已正确走通,否则你很有可能看不到Scala这个选项的);
3. 在main文件夹中建立一个名为 scala 的文件夹,并右键点击 scala 文件夹,选择 Make Directory as,然后选择Sources Root ,这里主要意思是将 scala 文件夹标记为一个源文件的根目录,然后在其内的所有代码中的 package ,其路径就从这个根目录下开始算起。
4. 在已经标记好为源文件根目录的 scala 文件夹 上,右键选择 New,然后选择 Scala Class,随后设置好程序的名称,并且记得将其设置为一个 Object(类似于Java中含有静态成员的静态类),正常的话,将会打开这个 Object 代码界面,并且可以看到IntelliJ IDEA自动添加了一些最基本的信息;
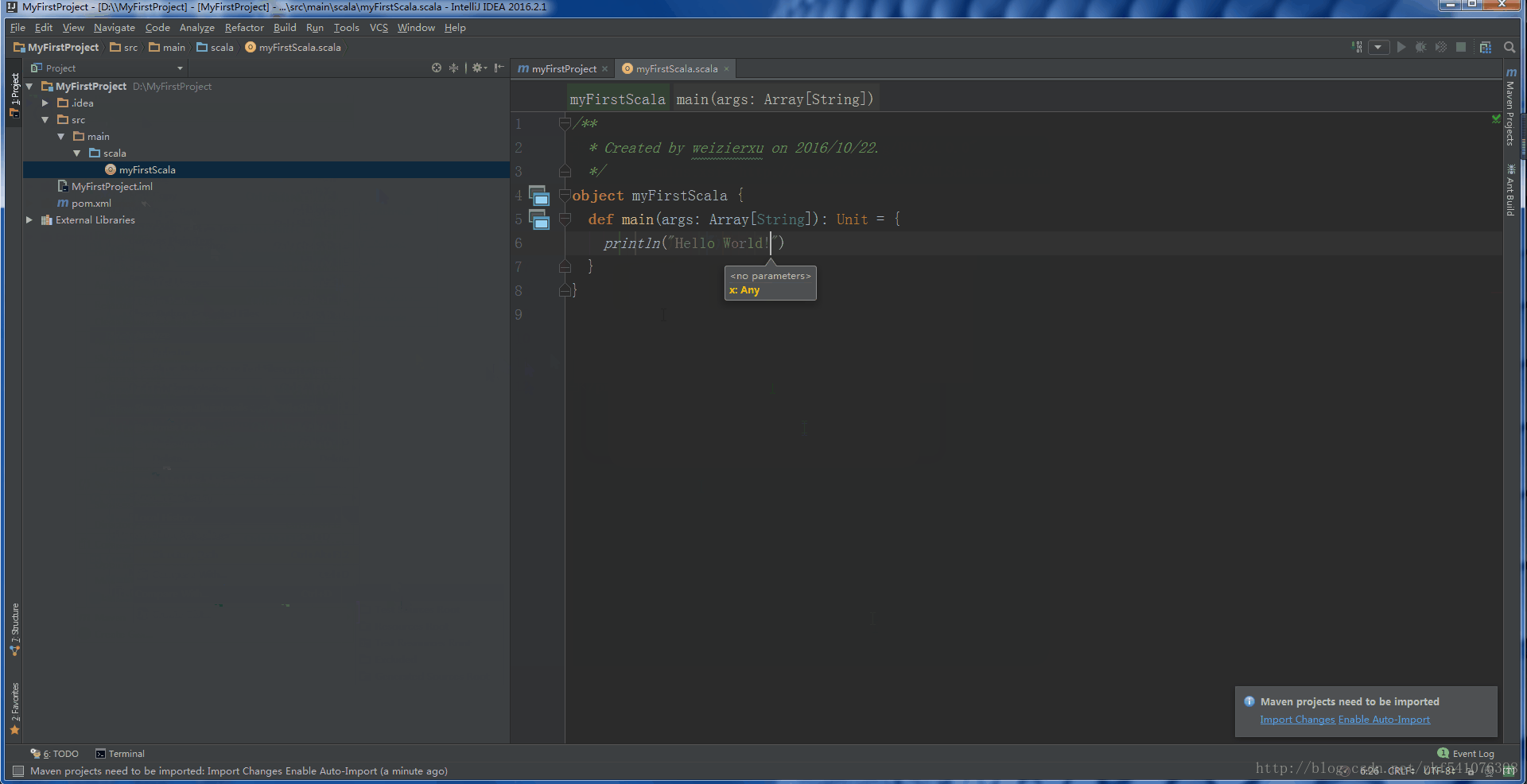
5. 在创建的 Object 中输入如下语句:
def main(args: Array[String]):Unit = {println("Hello World!")}
在程序界面的任意位置,右键单击后选择 Run '你的程序名称',静待程序的编译和运行,然后在下方自动打开的窗口中,你就可以看到振奋人心的 Hello World!了。
流程动图如下:
6. 导入spark依赖
此时你已经可以成功的运行一个Scala 项目了。想要运行在spark 上则还需要导入相关依赖。打开pom.xml文件添加如下依赖。
注意:是添加如下依赖;spark 和Scala的版本是对应的。
<properties><spark.version>2.0.2</spark.version>
<scala.version>2.11</scala.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.19</version>
<configuration>
<skip>true</skip>
</configuration>
</plugin>
</plugins>
</build>
导入依赖以后记得点击,这个引入jar 包哦
7. 编写sprak代码
依赖添加成功后,新建scala 的object 文件然后填写如下代码
//本案例是新建一个int 型的List数组,对数组中的每个元素乘以3 ,再过滤出来数组中大于10 的元素,然后对数组求和。
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by yangyibo on 16/11/21.
*/
object MySpark {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("mySpark")
//setMaster("local") 本机的spark就用local,远端的就写ip
//如果是打成jar包运行则需要去掉 setMaster("local")因为在参数中会指定。
conf.setMaster("local")
val sc =new SparkContext(conf)
val rdd =sc.parallelize(List(1,2,3,4,5,6)).map(_*3)
val mappedRDD=rdd.filter(_>10).collect()
//对集合求和
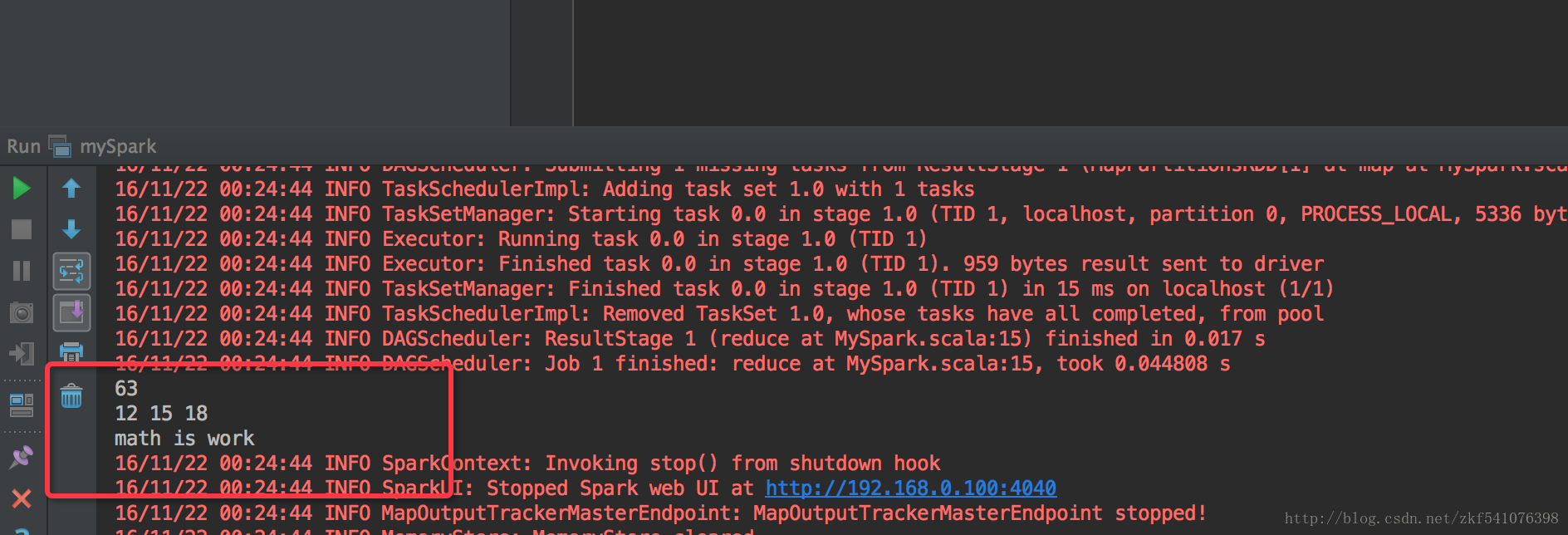
println(rdd.reduce(_+_))
//输出大于10的元素
for(arg <- mappedRDD)
print(arg+" ")
println()
println("math is work")
}
}
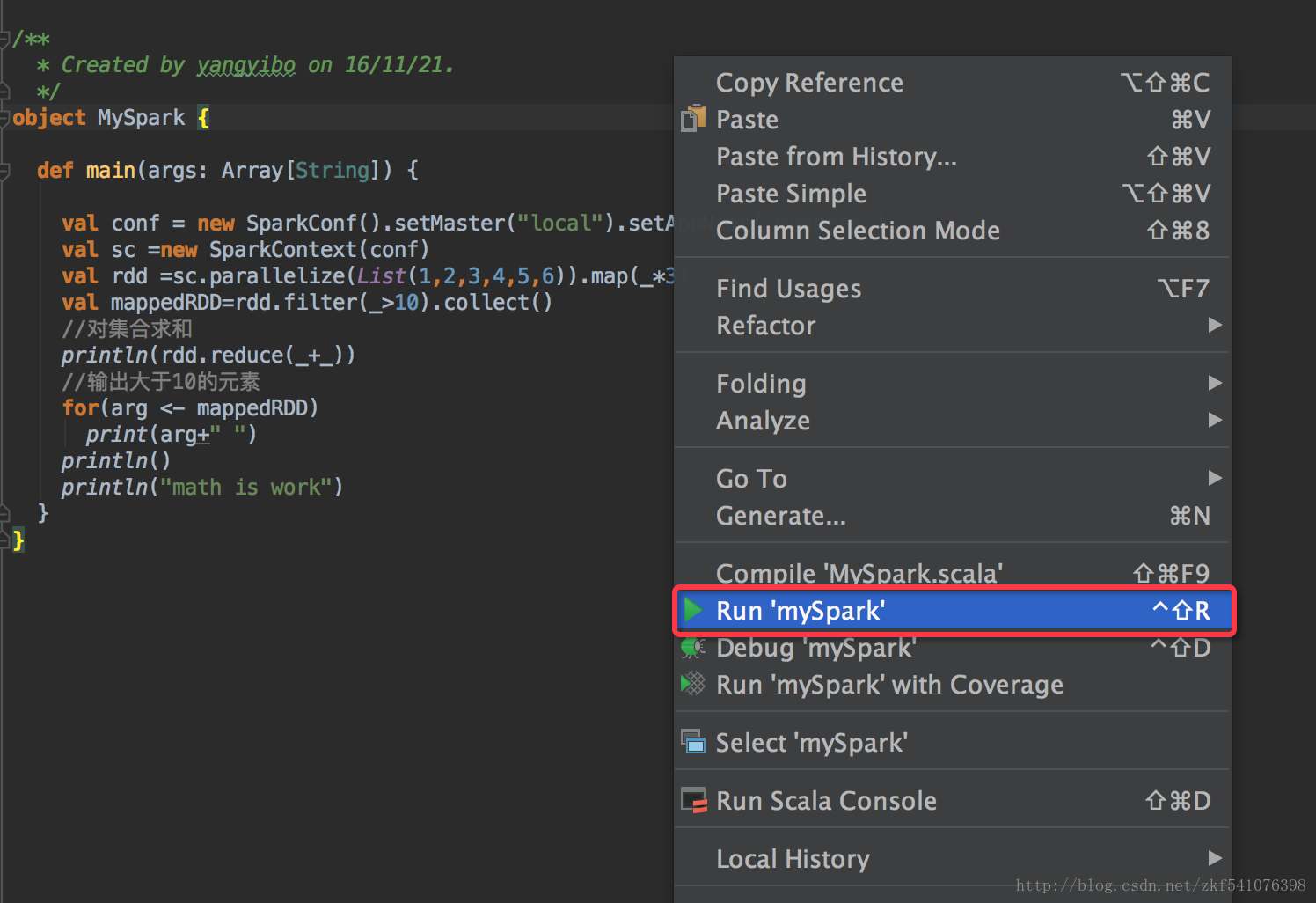
代码编写好以后,右键 run ‘mySpark’ 运行。
执行结果如下:
8. 打包运行
运行成功后,可以讲代码打包成jar 包发送到远端或者本地的spark 集群上运行。打包有以下步骤
点击“File“然后选择“project Structure“
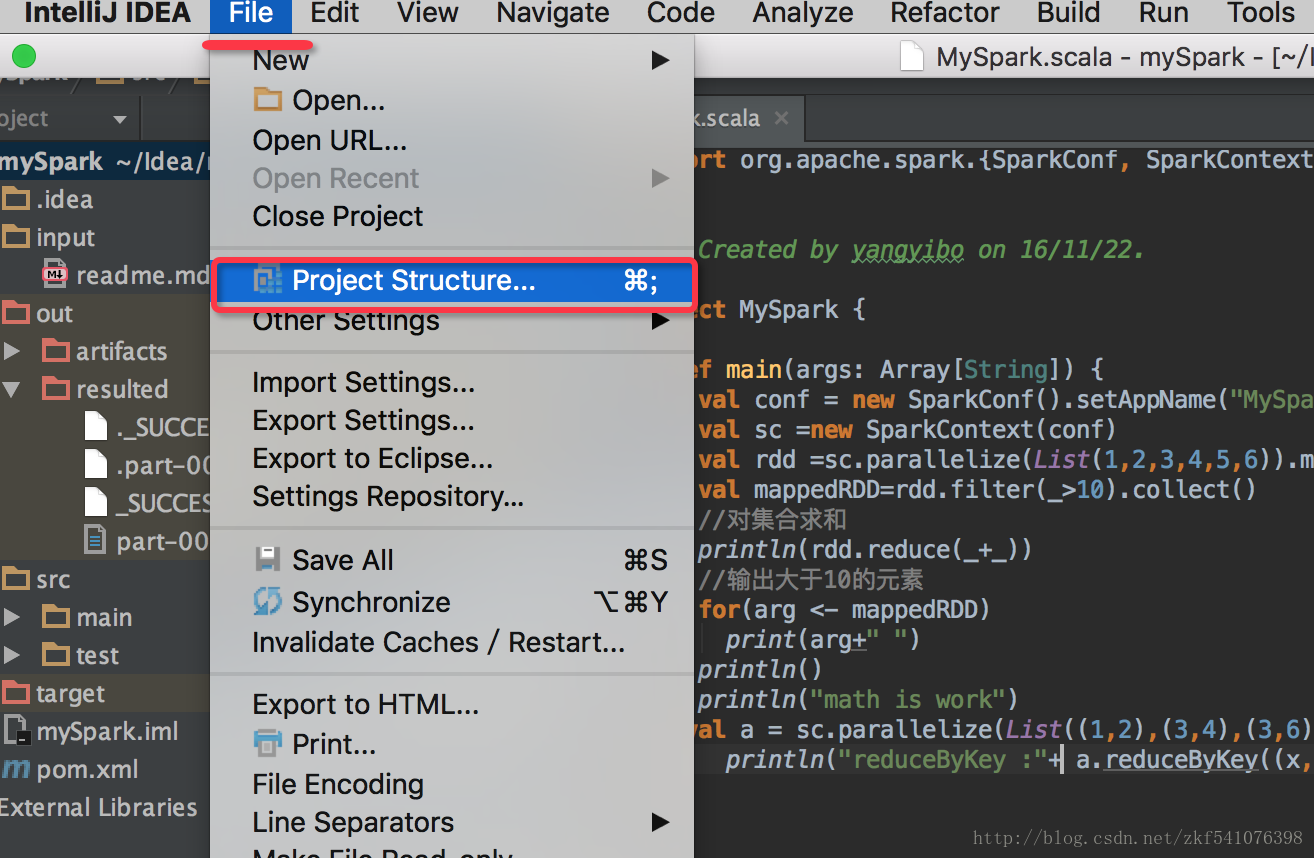
然后如图所示进行如下操作
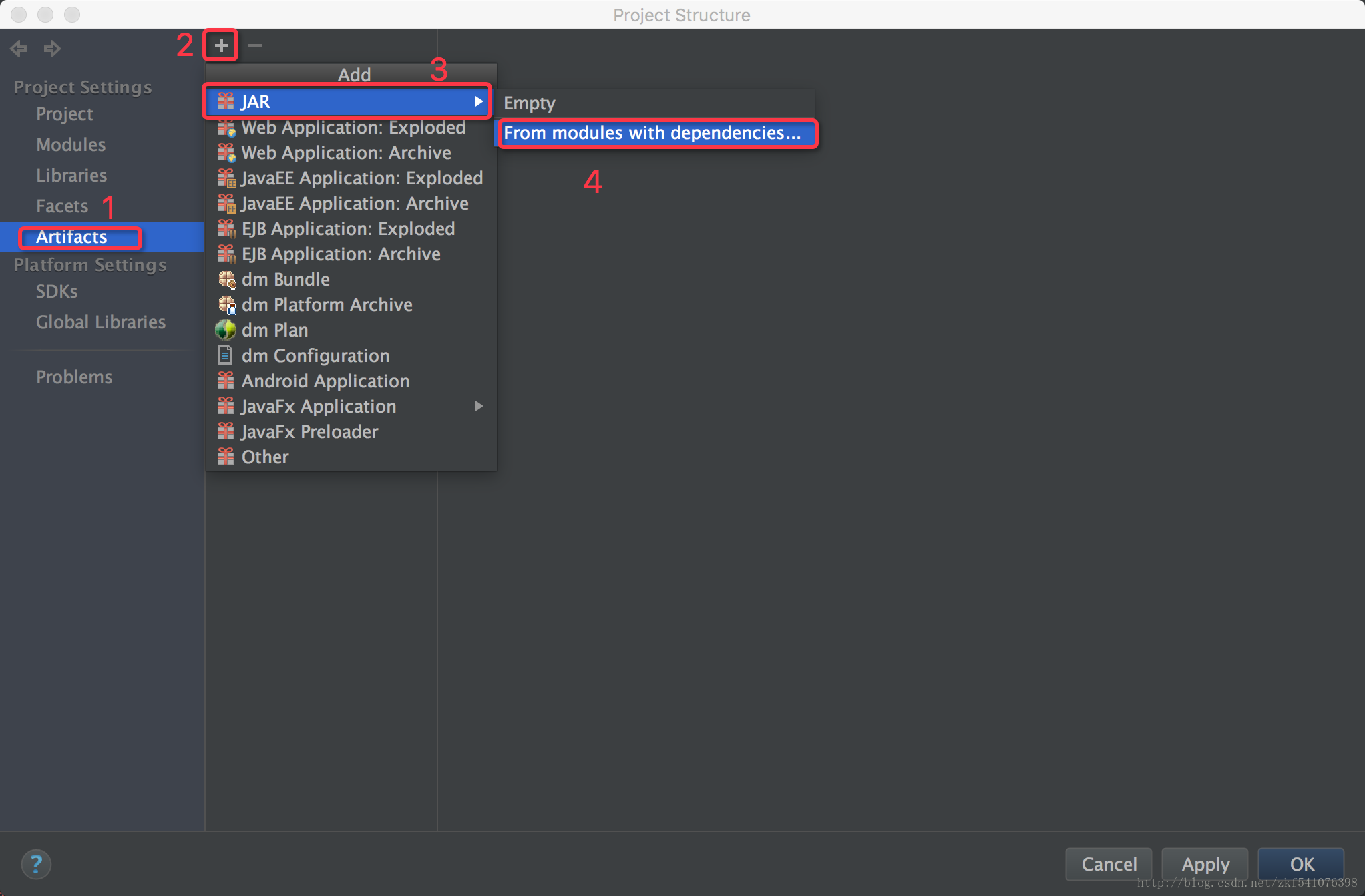
在弹出的对话框中点击按钮,选择主类进行如下4步操作。
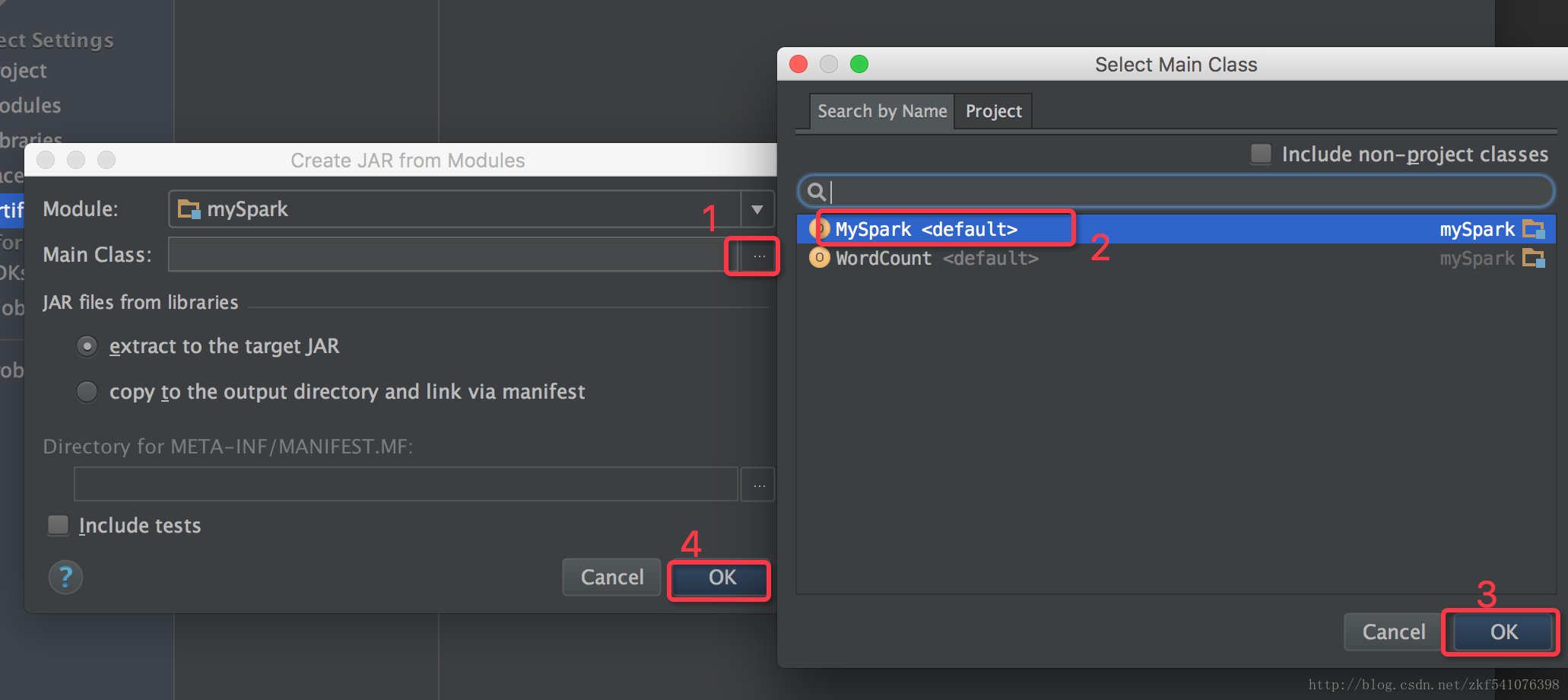
由于我们的jar包实在spark 上运行的,所可以删除其他不需要的依赖包,如下图所示,删除其他不需要的包,只留下红色矩形中的两个。
注意:output directory 的路径。此处是你导出 jar 的路径。
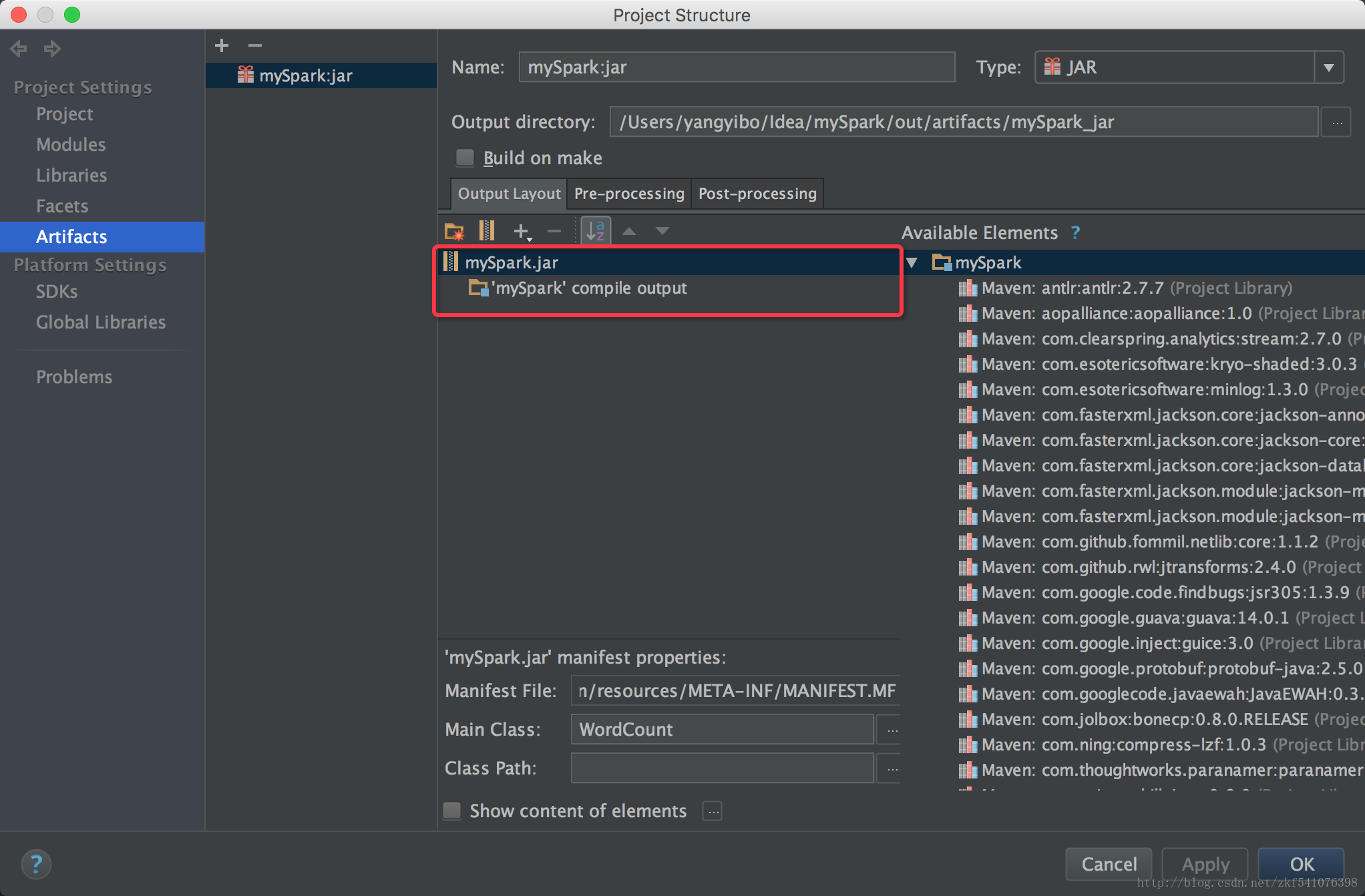
执行 bulid 构建你的jar
jar 包导出以后就可以在spark上运行了。
此时进入终端,进入到spark安装包的 bin 目录下。执行如下命令
MySpark :是启动类的名字,如果有包命,要加包名,(例如 com.edu.MySpark)
spark1:7077 : 是你远端的spark 的地址 ,(可以是 //192.168.200.66:7077) 写spark1 是因为我在/etc/hosts 中配置了环境参数,至于hosts 怎么配,请自行百度。
/Users/yangyibo/Idea/mySpark/out/artifacts/mySpark_jar/mySpark.jar: 是你jar 包的路径。
./bin/spark-submit --class MySpark --master spark://spark1:7077 /Users/yangyibo/Idea/mySpark/out/artifacts/mySpark_jar/mySpark.jar














 3742
3742











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









