







相机校准和3D重建
本节中的功能使用所谓的针孔相机模型。在此模型中,通过使用透视变换将3D点投影到图像平面中形成场景视图。
![s \; m'= A [R | t] M'](https://docs.opencv.org/2.4/_images/math/363c6d531e851a1eb934e7d6f875d593e2dc6f37.png)
要么
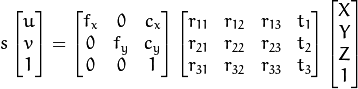
哪里:
是世界坐标空间中3D点的坐标
是以像素为单位的投影点的坐标
是一个相机矩阵,或一个内在参数的矩阵
是通常在形象中心的一个主要观点
是以像素单位表示的焦距。
因此,如果来自摄像机的图像按比例缩放,则所有这些参数都应该按相同的因子缩放(分别乘以/除)。内在参数的矩阵不依赖于所观看的场景。所以,一旦估计,只要焦距固定(在变焦镜头的情况下),它可以重新使用。联合旋转 - 平移矩阵 ![[R | T]](https://docs.opencv.org/2.4/_images/math/fad27ce6ccd005e429215a332c9d7a3a93c8246b.png) 称为外部参数矩阵。它用于描述静态场景周围的相机运动,反之亦然,静止相机前面的物体的刚性运动。也就是说, 将点的坐标转换 成相对于相机固定的坐标系。上面的转换等价于下面的(when
称为外部参数矩阵。它用于描述静态场景周围的相机运动,反之亦然,静止相机前面的物体的刚性运动。也就是说, 将点的坐标转换 成相对于相机固定的坐标系。上面的转换等价于下面的(when 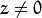 ):
):
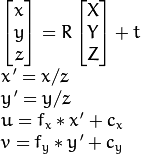
下图说明了针孔摄像机的型号。
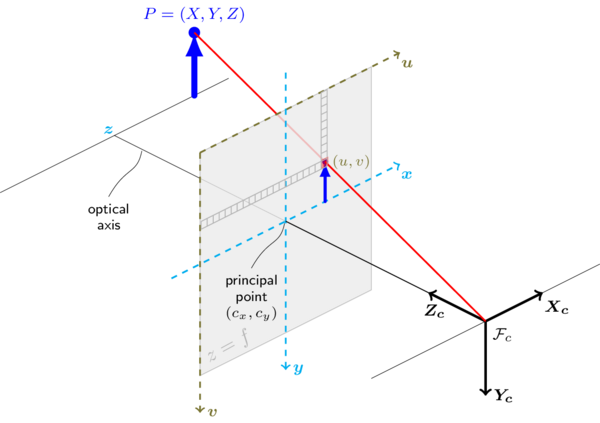
真实的镜头通常会有一些失真,主要是径向失真和轻微的切向失真。所以,上面的模型被扩展为:
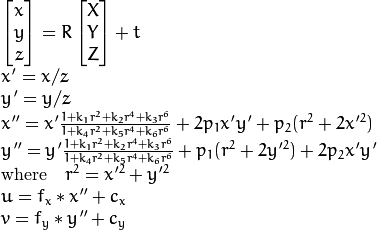
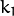 ,
, 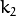 ,
,  ,
, 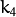 ,
, 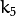 ,和
,和 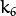 是径向失真系数。
是径向失真系数。 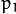 并且
并且 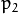 是切向失真系数。在OpenCV中不考虑高阶系数。
是切向失真系数。在OpenCV中不考虑高阶系数。
下图显示了两种常见类型的径向失真:桶形失真(典型的是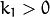 枕形失真(典型
枕形失真(典型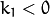 ))。
))。

在下面的函数中,系数被传递或返回
![(k_1,k_2,p_1,p_2 [,k_3 [,k_4,k_5,k_6]])](https://docs.opencv.org/2.4/_images/math/c4c47b9554bab572f9e3ea8d7b0be7eeb8b7c6e5.png)
向量。也就是说,如果矢量包含四个元素,则意味着 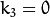 。失真系数不取决于观看的场景。因此,它们也属于内在摄像机参数。不管拍摄的图像分辨率如何,它们都保持不变。如果,例如,一个摄像机被校准上的图像 的分辨率,绝对相同的失真系数可以被用于从相同的摄影机的图像的同时, , ,和 需要被适当地缩放。
。失真系数不取决于观看的场景。因此,它们也属于内在摄像机参数。不管拍摄的图像分辨率如何,它们都保持不变。如果,例如,一个摄像机被校准上的图像 的分辨率,绝对相同的失真系数可以被用于从相同的摄影机的图像的同时, , ,和 需要被适当地缩放。320 x 240640 x 480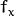
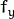
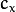
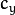
以下功能使用上述模型来执行以下操作:
- 项目3D指向给定内在和外在参数的图像平面。
- 计算给定内部参数的外部参数,几个3D点和它们的投影。
- 根据已知校准图案的几个视图估计内部和外部摄像机参数(每个视图由几个3D-2D点对应描述)。
- 估计立体相机“头部”的相对位置和方向,并计算使相机光轴平行的整流变换。
注意
- 可以在opencv_source_code / samples / cpp / 3calibration.cpp中找到3个水平位置摄像机的校准样本
- 基于一系列图像的校准样本可以在opencv_source_code / samples / cpp / calibration.cpp中找到
- 可以在opencv_source_code / samples / cpp / build3dmodel.cpp中找到校准样本以进行三维重建
- 人工生成的相机和棋盘图案的校准样本可以在opencv_source_code / samples / cpp / calibration_artificial.cpp处找到
- 立体校准的校准示例可以在opencv_source_code / samples / cpp / stereo_calib.cpp中找到
- 在opencv_source_code / samples / cpp / stereo_match.cpp上可以找到有关立体匹配的校准示例
- (Python)相机校准示例可以在opencv_source_code / samples / python2 / calibrate.py中找到
calibrateCamera
从校准模式的几个视图中查找相机的内在和外在参数。
-
C ++:
double
calibrateCamera
(
InputArrayOfArrays
objectPoints
,InputArrayOfArrays
imagePoints
,Size
imageSize
,InputOutputArray
cameraMatrix
,InputOutputArray
distCoeffs
,OutputArrayOfArrays
rvecs
,OutputArrayOfArrays
tvecs
,int
flags
= 0,TermCriteria
criteria
= TermCriteria(TermCriteria :: COUNT + TermCriteria :: EPS,30,DBL_EPSILON)
)
-
的Python:
cv2.
calibrateCamera
(
objectPoints,imagePoints,IMAGESIZE
[
,cameraMatrix
[
,distCoeffs
[
,rvecs
[
,tvecs
[
,旗帜
[
,标准
]
]
]
]
]
]
)
→RETVAL,cameraMatrix,distCoeffs,rvecs,tvecs
-
C:
double
cvCalibrateCamera2
(
const CvMat *
object_points
,const CvMat *
image_points
,const CvMat *
point_counts
,CvSize
image_size
,CvMat *
camera_matrix
,CvMat *
distortion_coeffs
,CvMat *
rotation_vectors
= NULL,CvMat *
translation_vectors
= NULL,int
flags
= 0,CvTermCriteria
term_crit
= cvTermCriteria(CV_TERMCRIT_ITER + CV_TERMCRIT_EPS,30,DBL_EPSILON)
)
-
的Python:
-
参数: - objectPoints -
在新界面中,它是校准模式坐标空间中校准模式点向量的向量(例如std :: vector <std :: vector <cv :: Vec3f >>)。外部向量包含与模式视图数量一样多的元素。如果在每个视图中显示相同的校准图案并且它是完全可见的,则所有矢量将是相同的。尽管可以使用部分遮挡的图案,甚至在不同的视图中使用不同的图案。那么,矢量将是不同的。这些点是3D的,但是由于它们是在一个图形坐标系中,所以如果钻机是平面的,将模型放在XY坐标平面上以使每个输入对象点的Z坐标为0是有意义的。
在旧界面中,所有来自不同视图的对象点的矢量被连接在一起。
- imagePoints -
在新界面中,它是校准模式点投影向量的向量(例如std :: vector <std :: vector <cv :: Vec2f >>)。
imagePoints.size()和objectPoints.size()和imagePoints[i].size()必须等于objectPoints[i].size()每个i。在旧界面中,所有来自不同视图的对象点的矢量被连接在一起。
- point_counts - 在旧界面中,这是一个整数矢量,包含与校准图案的视图数量一样多的元素。每个元素是每个视图中的点数。通常,所有元素都是相同的,并等于校准图案上的特征点的数量。
- imageSize - 仅用于初始化内在摄像机矩阵的图像大小。
- cameraMatrix - 输出3x3浮点相机矩阵
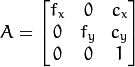 。如果
。如果 CV_CALIB_USE_INTRINSIC_GUESS和/或被CV_CALIB_FIX_ASPECT_RATIO指定,则 在调用该函数之前,必须初始化其中的一些或全部 。fx, fy, cx, cy - distCoeffs -
![(k_1,k_2,p_1,p_2 [,k_3 [,k_4,k_5,k_6]])](https://docs.opencv.org/2.4/_images/math/94288b7709d10a7ddf286e33db0074512bda0411.png) 4,5或8个元素的失真系数的输出向量 。
4,5或8个元素的失真系数的输出向量 。 - rvecs -
Rodrigues()为每个模式视图(例如std :: vector <cv :: Mat >>)估计的旋转矢量的输出矢量(参见 )。也就是说,每个第k个旋转矢量与对应的第k个平移矢量(参见下一个输出参数描述)一起将校准模式从模型坐标空间(其中指定了对象点)带到世界坐标空间,是在第k个图案视图(k = 0 ... M -1)中的校准图案的实际位置。 - tvecs - 为每个模式视图估计的平移向量的输出向量。
- 标志 -
不同的标志可能是零或以下值的组合:
- CV_CALIB_USE_INTRINSIC_GUESS
cameraMatrix包含 进一步优化的有效初始值 。否则, 最初设置为图像中心( 正在使用),焦距以最小二乘方式计算。请注意,如果已知内在参数,则不需要仅使用此函数来估计外部参数。 改为使用 。fx, fy, cx, cy(cx, cy)imageSizesolvePnP() - CV_CALIB_FIX_PRINCIPAL_POINT在全局优化期间,主点不会更改。它也停留在中心或
CV_CALIB_USE_INTRINSIC_GUESS设定的不同位置 。 - CV_CALIB_FIX_ASPECT_RATIO这些函数只考虑
fy作为一个自由参数。该比例fx/fy与输入中保持不变cameraMatrix。当CV_CALIB_USE_INTRINSIC_GUESS没有设置时,实际的输入值fx和fy被忽略,只有它们的比例被计算和使用。 - CV_CALIB_ZERO_TANGENT_DIST切向失真系数
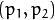 设置为零并保持为零。
设置为零并保持为零。
- CV_CALIB_FIX_K1,...,CV_CALIB_FIX_K6在优化过程中,相应的径向畸变系数不会改变。如果
CV_CALIB_USE_INTRINSIC_GUESS设置,distCoeffs则使用提供的矩阵的系数 。否则,它被设置为0。 - CV_CALIB_RATIONAL_MODEL启用系数k4,k5和k6。为了提供向后兼容性,应该明确指定这个额外的标志,以使校准函数使用有理模型并返回8个系数。如果没有设置标志,则该功能仅计算并返回5个失真系数。
- CV_CALIB_USE_INTRINSIC_GUESS
- 标准 - 迭代优化算法的终止标准。
- term_crit - 与
criteria。
- objectPoints -
cv.
CalibrateCamera2
(
objectPoints,imagePoints,pointCounts,IMAGESIZE,cameraMatrix,distCoeffs,rvecs,tvecs,标志= 0
)
→无
该函数估计每个视图的内在摄像机参数和外部参数。该算法基于[Zhang2000]和[BouguetMCT]。必须指定每个视图中3D对象点的坐标和相应的2D投影。这可以通过使用具有已知几何形状和易于检测的特征点的对象来实现。这样的对象称为校准装置或校准模式,而OpenCV已经内置了作为校准装置的棋盘支持(参见参考资料 findChessboardCorners())。目前,内部参数的初始化(当CV_CALIB_USE_INTRINSIC_GUESS未设置时)仅用于平面校准图案(其中对象点的Z坐标必须全部为零)。3D校准钻机也可以使用,只要初始cameraMatrix 被提供。
该算法执行以下步骤:
- 计算初始固有参数(该选项仅适用于平面校准模式)或从输入参数中读取。除非
CV_CALIB_FIX_K?指定了一些,否则最初的失真系数都被设置为零。 - 估计初始摄像机姿态,就好像内部参数已经知道一样。这是使用完成的
solvePnP()。 - 运行全球Levenberg-Marquardt优化算法,以最小化重投影误差,即观察到的特征点
imagePoints与投影(使用相机参数和姿态的当前估计值)对象点之间的平方距离总和objectPoints。见projectPoints()细节。
该函数返回最终的重新投影错误。
注意
如果使用非正方形(=非N×N)网格并 findChessboardCorners()进行校准,并calibrateCamera返回错误的值(零失真系数,图像中心距离很远(w/2-0.5,h/2-0.5),和/或差异较大和(比例为10:1或更大) ),那么你有可能使用patternSize=cvSize(rows,cols)的,而不是用patternSize=cvSize(cols,rows)在findChessboardCorners()。
calibrationMatrixValues
从相机矩阵计算有用的相机特性。
-
C ++:
void
calibrationMatrixValues
(
InputArray
cameraMatrix
,Size
imageSize
,double
apertureWidth
,double
apertureHeight
,double&
fovx
,double&
fovy
,double&
focalLength
,Point2d&
principalPoint
,double&
aspectRatio
)
-
的Python:
-
参数: - cameraMatrix - 输入相机矩阵,可以通过
calibrateCamera()或 估计stereoCalibrate()。 - imageSize - 以像素为单位输入图像大小。
- apertureWidth - 传感器的物理宽度(毫米)。
- apertureHeight - 传感器的物理高度,单位为毫米。
- fovx - 输出沿水平传感器轴的视角(以度为单位)。
- fovy - 沿垂直传感器轴输出视角(以度为单位)。
- focalLength - 以mm为单位的镜头焦距。
- principalPoint - 以毫米为单位的主要点
- aspectRatio -
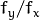
- cameraMatrix - 输入相机矩阵,可以通过
cv2.
calibrationMatrixValues
(
cameraMatrix,IMAGESIZE,apertureWidth,apertureHeight
)
→fovx,fovy,长焦点,principalPoint,的aspectRatio
该功能从先前估计的相机矩阵计算各种有用的相机特性。
注意
请记住统一度“mm”代表棋盘球场所选择的任何度量单位(因此可以是任何值)。
composeRT
结合两个旋转和平移转换。
-
C ++:
void
composeRT
(
InputArray
rvec1
,InputArray
tvec1
,InputArray
rvec2
,InputArray
tvec2
,OutputArray
rvec3
,OutputArray
tvec3
,OutputArray
dr3dr1
= noArray(),OutputArray
dr3dt1
= noArray(),OutputArray
dr3dr2
= noArray(),OutputArray
dr3dt2
= noArray(), OutputArray
dt3dr1
= noArray(),OutputArray
dt3dt1
= noArray(),OutputArray
dt3dr2
= noArray(),OutputArray
dt3dt2
= noArray()
)
-
的Python:
-
参数: - rvec1 - 第一个旋转矢量。
- tvec1 - 第一个翻译矢量。
- rvec2 - 第二个旋转矢量。
- tvec2 - 第二个翻译矢量。
- rvec3 - 叠加的输出旋转向量。
- tvec3 - 输出叠加的平移向量。
- d * d * -的其他输出衍生物
rvec3或tvec3关于rvec1,rvec2,tvec1和tvec2分别。
cv2.
composeRT
(
rvec1,tvec1,rvec2,tvec2
[
,rvec3
[
,tvec3
[
,dr3dr1
[
,dr3dt1
[
,dr3dr2
[
,dr3dt2
[
,dt3dr1
[
,dt3dt1
[
,dt3dr2
[
,dt3dt2
]
]
]
]
]
]
]
]
]
]
)
→rvec3,tvec3,dr3dr1,dr3dt1,dr3dr2,dr3dt2,dt3dr1,dt3dt1,dt3dr2,dt3dt2
函数计算:
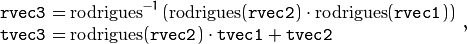
其中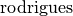 表示对旋转矩阵变换的旋转矢量,并且
表示对旋转矩阵变换的旋转矢量,并且 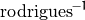 表示逆变换。见
表示逆变换。见Rodrigues()细节。
此外,函数可以计算输出向量相对于输入向量的导数(参见参考资料matMulDeriv())。这些函数在里面使用,stereoCalibrate()但也可以用在你自己的代码中,其中使用Levenberg-Marquardt或其他基于梯度的求解器来优化包含矩阵乘法的函数。
computeCorrespondEpilines
对于立体对的图像中的点,计算另一图像中的对应的线。
-
C ++:
void
computeCorrespondEpilines
(
InputArray
points
,int
whichImage
,InputArray
F
,OutputArray
行
)
-
C:
void
cvComputeCorrespondEpilines
(
const CvMat *
points
,int
which_image
,const CvMat *
fundamental_matrix
,CvMat *
correspondent_lines
)
-
的Python:
-
参数: - 点 - 输入点。
 或
或  类型
类型CV_32FC2或 矩阵vector<Point2f>。 - whichImage - 包含图像的索引(1或2)
points。 - F - 可以使用
findFundamentalMat()或 估计的基本矩阵stereoRectify()。 - 线 - 对应于另一图像中的点的极线的输出向量。每行
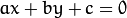 由3个数字编码
由3个数字编码  。
。
- 点 - 输入点。
cv.
ComputeCorrespondEpilines
(
分,whichImage,F,线
)
→无
对于立体对的两个图像之一中的每个点,函数找出另一个图像中对应的极线的方程。
从基本矩阵定义(请参阅 findFundamentalMat()),在第一个图像(当)计算为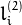 第二个图像中的点 行 :
第二个图像中的点 行 :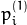
whichImage=1
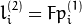
反之亦然,当whichImage=2, 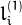 从计算
从计算 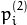 如下:
如下:
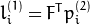
线系数定义为一个比例。他们正常化,所以 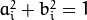 。
。
convertPointsToHomogeneous
将欧几里得的点转换为同质空间。
-
C ++:
void
convertPointsToHomogeneous
(
InputArray
src
,OutputArray
dst
)
-
Python:
-
参数: - src -
N维度点的输入向量。 - dst -
N+1维度点的输出向量。
- src -
cv2.
convertPointsToHomogeneous
(
src
[
,dst
]
)
→
该函数将点从欧几里得转换为齐次空间,方法是将1附加到点坐标元组中。也就是说,每个点都被转换成了。(x1, x2, ..., xn)(x1, x2, ..., xn, 1)
convertPointsFromHomogeneous
将点从齐次转换到欧几里得空间。
-
C ++:
void
convertPointsFromHomogeneous
(
InputArray
src
,OutputArray
dst
)
-
Python:
-
参数: - src -
N维度点的输入向量。 - dst -
N-1维度点的输出向量。
- src -
cv2.
convertPointsFromHomogeneous
(
src
[
,dst
]
)
→
该函数使用透视投影将点均匀地转换成欧几里德空间。也就是说,每个点都被转换成了。当,输出点坐标将是。(x1, x2, ... x(n-1), xn)(x1/xn, x2/xn,..., x(n-1)/xn)xn=0(0,0,0,...)
convertPointsHomogeneous
将点转换为齐次坐标。
-
C ++:
void
convertPointsHomogeneous
(
InputArray
src
,OutputArray
dst
)
-
C:
void
cvConvertPointsHomogeneous
(
const CvMat *
src
,CvMat *
dst
)
-
Python:
-
参数: - src - 输入2D,3D或4D点的数组或向量。
- dst - 2D,3D或4D点的输出向量。
cv.
ConvertPointsHomogeneous
(
src,dst
)
→
该函数通过调用convertPointsToHomogeneous()或来将二维点或三维点转换为齐次坐标convertPointsFromHomogeneous()。
注意
该功能已过时。改用前面两个函数之一。
correctMatches
细化相应点的坐标。
-
C ++:
空隙
correctMatches
(
InputArray
˚F
,InputArray
points1
,InputArray
points2
,OutputArray
newPoints1
,OutputArray
newPoints2
)
-
的Python:
cv2.
correctMatches
(
女,points1,points2
[
,newPoints1
[
,newPoints2
]
]
)
→newPoints1,newPoints2
-
C:
-
参数: - F - 3x3基本矩阵。
- points1 - 1×N个阵列包含第一组点。
- points2 - 1×N个阵列包含第二组点。
- newPoints1 - 优化的points1。
- newPoints2 - 优化的points2。
空隙
cvCorrectMatches
(
与CvMat *
˚F
,*与CvMat
points1
,*与CvMat
points2
,*与CvMat
new_points1
,*与CvMat
new_points2
)
该功能实现了最佳三角剖分法(有关详细信息,请参阅多视图几何图形)。对于每个给定的点对应points1 [I] < - > points2 [i]和一个基本矩阵F,它计算校正后的对应关系newPoints1 [I] < - > newPoints2 [I]最小化的几何误差![d(points1 [i],newPoints1 [i])^ 2 + d(points2 [i],newPoints2 [i])^ 2](https://docs.opencv.org/2.4/_images/math/628211a603e8e7dfff3bbfc475051c9b7b84f935.png) (其中
(其中 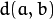 是几何距离在点
是几何距离在点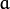 和 之间
和 之间 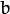 )受到极线约束
)受到极线约束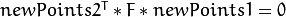 。
。
decomposeProjectionMatrix
将投影矩阵分解为旋转矩阵和相机矩阵。
-
C ++:
空隙
decomposeProjectionMatrix
(
InputArray
projMatrix
,OutputArray
cameraMatrix
,OutputArray
rotMatrix
,OutputArray
transVect
,OutputArray
rotMatrixX
= noArray(),OutputArray
rotMatrixY
= noArray(),OutputArray
rotMatrixZ
= noArray(),OutputArray
为:eulerAngles
= noArray()
)
-
的Python:
cv2.
decomposeProjectionMatrix
(
projMatrix
[
,cameraMatrix
[
,rotMatrix
[
,transVect
[
,rotMatrixX
[
,rotMatrixY
[
,rotMatrixZ
[
,为:eulerAngles
]
]
]
]
]
]
]
)
→cameraMatrix,rotMatrix,transVect,rotMatrixX,rotMatrixY,rotMatrixZ,为:eulerAngles
-
C:
空隙
cvDecomposeProjectionMatrix
(
常量*与CvMat
projMatr
,*与CvMat
calibMatr
,*与CvMat
rotMatr
,*与CvMat
posVect
,*与CvMat
rotMatrX
= NULL,*与CvMat
rotMatrY
= NULL,*与CvMat
rotMatrZ
= NULL,CvPoint3D64f *
为:eulerAngles
= NULL
)
-
的Python:
-
参数: - projMatrix - 3x4输入投影矩阵P.
- cameraMatrix - 输出3x3相机矩阵K.
- rotMatrix - 输出3x3外部旋转矩阵R.
- transVect - 输出4x1平移向量T.
- rotMatrX - 围绕x轴可选的3x3旋转矩阵。
- rotMatrY - 围绕y轴可选的3x3旋转矩阵。
- rotMatrZ - 围绕z轴可选的3x3旋转矩阵。
- eulerAngles - 包含三个以度为单位的欧拉旋转角的可选三元向量。
cv.
DecomposeProjectionMatrix
(
projMatrix,cameraMatrix,rotMatrix,transVect,rotMatrX =无,rotMatrY =无,rotMatrZ =无
)
→为:eulerAngles
该函数计算投影矩阵分解成校准和旋转矩阵以及相机的位置。
它可以选择返回三个旋转矩阵,每个轴一个,以及可以在OpenGL中使用的三个欧拉角。请注意,总是有三个以上的主轴旋转的顺序,导致相同的方向的一个对象,例如。见[Slabaugh]。返回的树旋转矩阵和相应的三个欧拉角仅是可能的解决方案之一。
该功能是基于 RQDecomp3x3()。
drawChessboardCorners
呈现检测到的棋盘角落。
-
C + +:
void
drawChessboardCorners
(
InputOutputArray
图像
,大小
patternSize
,InputArray
角落
,布尔
patternWasFound
)
-
的Python:
cv2.
drawChessboardCorners
(
图像,patternSize,拐角,patternWasFound
)
→无
-
C:
空隙
cvDrawChessboardCorners
(
CvArr *
图像
,CvSize
pattern_size
,CvPoint2D32f *
角
,INT
计数
,INT
pattern_was_found
)
-
的Python:
-
参数: - 图像 - 目的地图像。它必须是一个8位彩色图像。
- patternSize - 每个棋盘行和列的内角的数量。
(patternSize = cv::Size(points_per_row,points_per_column)) - 角落 - 检测到的角落数组,输出
findChessboardCorners。 - patternWasFound - 指示是否找到完整电路板的参数。
findChessboardCorners()应该在这里传递返回值。
cv.
DrawChessboardCorners
(
图像,patternSize,拐角,patternWasFound
)
→无
该功能将单独的棋盘角落绘制为红色圆圈(如果没有找到该板),或者如果找到该板,则将其作为彩色拐角与线连接。
findChessboardCorners
查找棋盘内角的位置。
-
C ++:
bool
findChessboardCorners
(
InputArray
图像
,大小
patternSize
,OutputArray
角
,int
标志
= CALIB_CB_ADAPTIVE_THRESH + CALIB_CB_NORMALIZE_IMAGE
)
-
的Python:
cv2.
findChessboardCorners
(
图像,patternSize
[
,角
[
,旗帜
]
]
)
→RETVAL,拐角
-
C:
INT
cvFindChessboardCorners
(
const的无效*
图像
,CvSize
pattern_size
,CvPoint2D32f *
角
,INT *
corner_count
= NULL,整数
标志
= CV_CALIB_CB_ADAPTIVE_THRESH + CV_CALIB_CB_NORMALIZE_IMAGE
)
-
的Python:
-
参数: - 图像 - 源棋盘视图。它必须是8位灰度或彩色图像。
- patternSize - 每个棋盘行和列的内角的数量。
( patternSize = cvSize(points_per_row,points_per_colum) = cvSize(columns,rows) ) - 角落 - 检测到的角落的输出阵列。
- 标志 -
各种操作标志可以是零或以下值的组合:
- CALIB_CB_ADAPTIVE_THRESH使用自适应阈值将图像转换为黑白,而不是固定的阈值(从平均图像亮度计算)。
- CALIB_CB_NORMALIZE_IMAGE
equalizeHist()在应用固定或自适应阈值之前,对图像伽玛进行标准化 。 - CALIB_CB_FILTER_QUADS使用其他标准(如轮廓区域,周长,方形形状)来过滤在轮廓检索阶段提取的假四边形。
- CALIB_CB_FAST_CHECK对查找棋盘角的图像运行快速检查,如果没有找到,则快速调用该电话。当没有观察到棋盘时,这可以极大地加速在恶化状态下的呼叫。
cv.
FindChessboardCorners
(
图像,patternSize,旗帜= CV_CALIB_CB_ADAPTIVE_THRESH
)
→拐角
该函数试图确定输入图像是否是棋盘图案的视图并定位内部棋盘角。如果找到了所有的角点并且它们按照一定的顺序(在每一行中从左到右逐行)被放置,则该函数返回一个非零值。否则,如果函数找不到所有的角或重新排序,则返回0.例如,一个规则的棋盘有8×8的方块和7×7的内角,也就是黑方块相互接触的点。检测到的坐标是近似的,并且更准确地确定它们的位置,函数调用cornerSubPix()。cornerSubPix()如果返回的坐标不够准确,也可以使用不同参数的函数。
检测和绘制棋盘角的示例用法:
注意
该功能需要白板(如方形厚的边框,越宽越好)围绕电路板,使检测更加强大的各种环境。否则,如果没有边界且背景是黑暗的,则外部黑色方块不能被正确分割,因此方形分组和排序算法失败。
findCirclesGrid
在圈子网格中查找中心。
-
C ++:
布尔
findCirclesGrid
(
InputArray
图像
,尺寸
patternSize
,OutputArray
中心
,整数
标志
= CALIB_CB_SYMMETRIC_GRID,常量PTR <FeatureDetector>&
blobDetector
=新SimpleBlobDetector()
)
-
Python:
-
参数: - 输入圆的图像 - 网格视图; 它必须是一个8位灰度或彩色图像。
- patternSize - 每行和每列的圈数。
( patternSize = Size(points_per_row, points_per_colum) ) - 中心 - 检测中心的输出阵列。
- 标志 -
各种操作标志可以是下列值之一:
- CALIB_CB_SYMMETRIC_GRID使用圆形的对称图案。
- CALIB_CB_ASYMMETRIC_GRID使用不对称的圆形图案。
- CALIB_CB_CLUSTERING使用特殊的算法进行网格检测。透视扭曲更强健,但对背景混乱更敏感。
- blobDetector - 在浅色背景上发现像黑眼圈的斑点的特征检测器。
cv2.
findCirclesGridDefault
(
image,patternSize
[
,centers
[
,flags
]
]
)
→retval,居中
该函数尝试确定输入图像是否包含圆形网格。如果是,则该函数定位圆的中心。如果找到了所有的中心,并且它们按照特定的顺序(在每一行中从左到右逐行排列)放置,则该函数返回一个非零值。否则,如果函数找不到所有的角或者重新排序,它将返回0。
检测和绘制圆心的示例用法:
注意
该功能需要白板(如方形厚的边框,越宽越好)围绕电路板,使检测更加强大的各种环境。
solvePnP
从3D-2D点对应中查找对象姿势。
-
C ++:
bool
solvePnP
(
InputArray
objectPoints
,InputArray
imagePoints
,InputArray
cameraMatrix
,InputArray
distCoeffs
,OutputArray
rvec
,OutputArray
tvec
,bool
useExtrinsicGuess
= false,int
flags
= ITERATIVE
)
-
的Python:
cv2.
solvePnP
(
objectPoints,imagePoints,cameraMatrix,distCoeffs
[
,RVEC
[
,tvec
[
,useExtrinsicGuess
[
,旗帜
]
]
]
]
)
→RETVAL,RVEC,tvec
-
C:
空隙
cvFindExtrinsicCameraParams2
(
常量*与CvMat
object_points
,常量*与CvMat
image_points
,常量*与CvMat
camera_matrix
,常量*与CvMat
distortion_coeffs
,*与CvMat
rotation_vector
,*与CvMat
translation_vector
,INT
use_extrinsic_guess
= 0
)
-
的Python:
-
参数: - objectPoints - 对象坐标空间中的对象点数组,3xN / Nx3 1通道或1xN / Nx1 3通道,其中N是点数。
vector<Point3f>也可以通过这里。 - imagePoints - 相应图像点的阵列,2xN / Nx2 1通道或1xN / Nx1 2通道,其中N是点数。
vector<Point2f>也可以通过这里。 - cameraMatrix - 输入相机矩阵
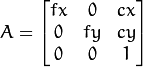 。
。 - distCoeffs - 输入 4,5或8个元素的失真系数向量 。如果矢量为空/空,则假定零失真系数。
- rvec - 输出旋转向量(参见
Rodrigues())tvec,将模型坐标系中的点与摄像机坐标系相关联。 - tvec - 输出转换矢量。
- useExtrinsicGuess - 如果为true(1),则函数使用提供的 值
rvec和tvec值作为旋转矢量和平移矢量的初始近似值,并进一步对其进行优化。 - 标志 -
解决PnP问题的方法:
- CV_ITERATIVE迭代法基于Levenberg-Marquardt优化。在这种情况下,函数找到这样一个姿态,使重投影误差最小化,即观测投影
imagePoints和投影(使用projectPoints())之间的平方距离之和objectPoints。 - CV_P3P 方法基于XS Gao,X.-R.的论文。Hou,J. Tang,H.-F. 张“”透视三点问题的完全解法分类“。在这种情况下,该功能需要正好四个对象和图像点。
- CV.EPNP方法已由F.Moreno-Noguer,V.Lepetit和P.Fua在“EPnP:高效透视n点相机姿态估计”一文中引入。
- CV_ITERATIVE迭代法基于Levenberg-Marquardt优化。在这种情况下,函数找到这样一个姿态,使重投影误差最小化,即观测投影
- objectPoints - 对象坐标空间中的对象点数组,3xN / Nx3 1通道或1xN / Nx1 3通道,其中N是点数。
cv.
FindExtrinsicCameraParams2
(
objectPoints,imagePoints,cameraMatrix,distCoeffs,RVEC,tvec,useExtrinsicGuess = 0
)
→无
该函数在给定一组目标点,它们对应的图像投影以及相机矩阵和失真系数的情况下估计目标姿态。
注意
- 如何在平面增强现实中使用solvePNP的例子可以在opencv_source_code / samples / python2 / plane_ar.py
solvePnPRansac
使用RANSAC方案从3D-2D点对应中查找对象姿态。
-
C ++:
空隙
solvePnPRansac
(
InputArray
objectPoints
,InputArray
imagePoints
,InputArray
cameraMatrix
,InputArray
distCoeffs
,OutputArray
RVEC
,OutputArray
tvec
,布尔
useExtrinsicGuess
=假,INT
iterationsCount
= 100,浮
reprojectionError
= 8.0,INT
minInliersCount
= 100,OutputArray
内围层
= noArray(),INT
flags
= ITERATIVE
)
-
的Python:
-
参数: - objectPoints - 对象坐标空间中的对象点数组,3xN / Nx3 1通道或1xN / Nx1 3通道,其中N是点数。
vector<Point3f>也可以通过这里。 - imagePoints - 相应图像点的阵列,2xN / Nx2 1通道或1xN / Nx1 2通道,其中N是点数。
vector<Point2f>也可以通过这里。 - cameraMatrix - 输入相机矩阵 。
- distCoeffs - 输入 4,5或8个元素的失真系数向量 。如果矢量为空/空,则假定零失真系数。
- rvec - 输出旋转向量(参见
Rodrigues())tvec,将模型坐标系中的点与摄像机坐标系相关联。 - tvec - 输出转换矢量。
- useExtrinsicGuess - 如果为true(1),则函数使用提供的 值
rvec和tvec值作为旋转矢量和平移矢量的初始近似值,并进一步对其进行优化。 - iterationsCount - 迭代次数。
- reprojectionError - RANSAC过程使用的内部阈值。参数值是观察点与投影点投影之间允许的最大距离,将其视为内点。
- minInliersCount - 内部数量。如果某个阶段的算法找到更多的内点
minInliersCount,则结束。 - inliers - 包含in
objectPoints和in中内部索引的输出向量imagePoints。 - 标志 - 解决PnP问题的方法(请参阅参考资料
solvePnP())。
- objectPoints - 对象坐标空间中的对象点数组,3xN / Nx3 1通道或1xN / Nx1 3通道,其中N是点数。
cv2.
solvePnPRansac
(
objectPoints,imagePoints,cameraMatrix,distCoeffs
[
,RVEC
[
,tvec
[
,useExtrinsicGuess
[
,iterationsCount
[
,reprojectionError
[
,minInliersCount
[
,内点
[
,旗帜
]
]
]
]
]
]
]
]
)
→RVEC,tvec,内围层
该函数在给定一组目标点,它们对应的图像投影以及相机矩阵和失真系数的情况下估计目标姿态。这个函数找到了这样一个姿态,使重投影误差最小化,也就是观察到的投影imagePoints与投影(使用 projectPoints())之间的平方和的总和objectPoints。RANSAC的使用使该功能可以抵抗异常值。该功能与TBB库并行。
findFundamentalMat
根据两幅图像中的相应点计算基本矩阵。
-
C ++:
垫
findFundamentalMat
(
InputArray
points1
,InputArray
points2
,INT
方法
= FM_RANSAC,双
参数1
。= 3,双
param2的
= 0.99,OutputArray
掩模
= noArray()
)
-
Python:
cv2.
findFundamentalMat
(
points1,points2
[
,method
[
,param1
[
,param2
[
,mask
]
]
]
]
)
→retval,
-
C:
INT
cvFindFundamentalMat
(
常量*与CvMat
points1
,常量*与CvMat
points2
,*与CvMat
fundamental_matrix
,INT
方法
= CV_FM_RANSAC,双
参数1
。= 3,双
param2的
= 0.99,*与CvMat
状态
= NULL
)
-
的Python:
-
参数: - points1 -
N从第一个图像的 点数组。点坐标应该是浮点(单精度或双精度)。 - points2 - 与第二个图像点大小和格式相同的数组
points1。 - 方法 -
计算基本矩阵的方法。
- CV_FM_7POINT为7点算法。
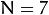
- CV_FM_8POINT为8点算法。
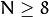
- 用于RANSAC算法的CV_FM_RANSAC。
- CV_FM_LMEDS为LMedS算法。
- CV_FM_7POINT为7点算法。
- param1 - 用于RANSAC的参数。这是从一个点到极线的最大距离(以像素为单位),超过该距离该点被认为是异常值,不用于计算最终的基本矩阵。它可以设置为1-3,取决于点定位精度,图像分辨率和图像噪声。
- param2 - 仅用于RANSAC或LMedS方法的参数。它规定了估计矩阵正确的可信度(概率)。
- 掩码 - N个元素的输出数组,其中每个元素都被设置为0,用于异常值,其他点则被设置为1。该数组仅在RANSAC和LMedS方法中计算。对于其他方法,它被设置为全1。
- points1 -
cv.
FindFundamentalMat
(
points1,points2,fundamentalMatrix,方法= CV_FM_RANSAC,参数1 = 1,参数2 = 0.99,状态=无。
)
→RETVAL
对极几何由以下等式描述:
![[P_2; 1] ^ TF [p_1; 1] = 0](https://docs.opencv.org/2.4/_images/math/1c83f2262812b017960514fb184fba470c84f0fe.png)
其中 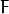 是一个基本矩阵, 和 分别对应于所述第一和第二图像,分。
是一个基本矩阵, 和 分别对应于所述第一和第二图像,分。
该函数使用上面列出的四种方法之一计算基本矩阵,并返回找到的基本矩阵。通常只找到一个矩阵。但是在7点算法的情况下,函数最多可以返回3个解(  矩阵可以存储所有3个矩阵)。
矩阵可以存储所有3个矩阵)。
所计算的基本矩阵可以进一步传递到 computeCorrespondEpilines()找到对应于指定点的极线。也可以通过 stereoRectifyUncalibrated()计算整改转化。
findHomography
找到两架飞机之间的角度转换。
-
C ++:
Mat
findHomography
(
InputArray
srcPoints
,InputArray
dstPoints
,int
方法
= 0,double
ransacReprojThreshold
= 3,OutputArray
mask
= noArray()
)
-
的Python:
cv2.
findHomography
(
srcPoints,dstPoints
[
,方法
[
,ransacReprojThreshold
[
,面罩
]
]
]
)
→RETVAL,掩模
-
C:
int
cvFindHomography
(
const CvMat *
src_points
,const CvMat *
dst_points
,CvMat *
单应性
,int
方法
= 0,double
ransacReprojThreshold
= 3,CvMat *
mask
= 0
)
-
的Python:
-
参数: - srcPoints - 原始平面中点的坐标,类型
CV_32FC2或矩阵的矩阵vector<Point2f>。 - dstPoints - 目标平面中点的坐标,类型
CV_32FC2或a 的矩阵vector<Point2f>。 - 方法 -
用于计算单应性矩阵的方法。以下方法是可能的:
- 0 - 使用所有点的常规方法
- CV_RANSAC - 基于RANSAC的鲁棒方法
- CV_LMEDS - 最小中值鲁棒方法
- ransacReprojThreshold -
最大允许再投影误差将点对视为内点(仅在RANSAC方法中使用)。那就是,如果
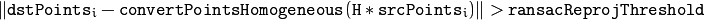
那么这个点就
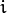 被认为是一个异常点。如果
被认为是一个异常点。如果 srcPoints与dstPoints以像素为单位,它通常是有意义的在范围内的某处设置此参数为1〜10。 - 掩码 - 由可靠方法(
CV_RANSAC或CV_LMEDS)设置的可选输出掩码。请注意,输入掩码值将被忽略。
- srcPoints - 原始平面中点的坐标,类型
cv.
FindHomography
(
srcPoints,dstPoints,H,方法= 0,ransacReprojThreshold = 3.0,状态=无
)
→无
函数查找并返回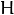 源平面和目标平面之间的透视转换:
源平面和目标平面之间的透视转换:
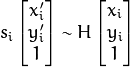
使反投影错误
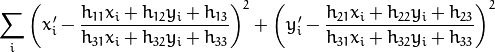
被最小化。如果参数method设置为默认值0,则该函数使用所有的点对以简单的最小二乘方案计算初始单应性估计。
然而,如果不是所有的点对( 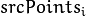 ,
,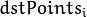 )都符合刚性透视变换(即有一些异常值),那么这个初始估计就会很差。在这种情况下,您可以使用两种健壮的方法之一。这两种方法,
)都符合刚性透视变换(即有一些异常值),那么这个初始估计就会很差。在这种情况下,您可以使用两种健壮的方法之一。这两种方法,RANSAC并且LMeDS,尝试对应点对(的各4对)的许多不同的随机子集,使用这种子集和一个简单的最小二乘法估计的单应矩阵,然后计算所计算的单应性的质量/善(其是RANSAC的内点数或LMeD的中值重投影误差)。然后使用最佳子集来产生单应矩阵的初始估计和内点/外点的掩码。
不管方法是否稳健,计算的单应性矩阵都用Levenberg-Marquardt方法进一步细化(仅在强健方法的情况下使用inlier)以更多地减少再投影误差。
该方法RANSAC几乎可以处理任何异常值的比率,但是需要一个阈值来区分异常值和异常值。该方法LMeDS不需要任何阈值,但只有在超过50%的内部值时才能正确工作。最后,如果没有异常值且噪声相当小,则使用默认方法(method=0)。
该函数用于查找初始内在和外在矩阵。Homography矩阵决定一个规模。因此,这是正常化的 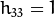 。请注意,无法估计H矩阵时,将返回一个空矩阵。
。请注意,无法估计H矩阵时,将返回一个空矩阵。
也可以看看
getAffineTransform(), getPerspectiveTransform(), estimateRigidTransform(), warpPerspective(), perspectiveTransform()
注意
- 计算图像匹配单应性的示例可以在opencv_source_code / samples / cpp / video_homography.cpp
estimateAffine3D
计算两个三维点集之间的最佳仿射变换。
-
C ++:
int
estimateAffine3D
(
InputArray
src
,InputArray
dst
,OutputArray
out
,OutputArray
inliers
,double
ransacThreshold
= 3,double
confidence
= 0.99
)
-
的Python:
-
参数: - src - 首先输入3D点集。
- dst - 第二个输入3D点集。
- out - 输出3D仿射变换矩阵
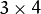 。
。 - 内点 - 指示哪些点是内点的输出向量。
- ransacThreshold - RANSAC算法中的最大重投影误差,将点视为内点。
- 置信度 - 置信水平,介于0和1之间,用于估算转化。0.95到0.99之间的任何东西通常都足够好。数值太接近1会显着减慢估计。低于0.8-0.9的值可能会导致错误的估计转换。
cv2.
estimateAffine3D
(
SRC,DST
[
,出
[
,内点
[
,ransacThreshold
[
,信心
]
]
]
]
)
→RETVAL,指出,内围层
该函数使用RANSAC算法估计两个3D点集之间的最佳3D仿射变换。
filterSpeckles
滤除视差图中的小噪声斑点(斑点)
-
C ++:
void
filterSpeckles
(
InputOutputArray
img
,double
newVal
,int
maxSpeckleSize
,double
maxDiff
,InputOutputArray
buf
= noArray()
)
-
Python:
-
参数: - img - 输入的16位有符号差异图像
- newVal - 用于消除斑点的差异值
- maxSpeckleSize - 最大散斑尺寸,将其视为散斑。较大的斑点不受算法的影响
- maxDiff - 将相邻视差像素之间的最大差异放入同一个斑点。请注意,由于StereoBM,StereoSGBM和其他算法可能会返回一个定点视差图,其中视差值乘以16,因此在指定此参数值时应考虑此比例因子。
- buf - 可选的临时缓冲区,以避免函数内存分配。
cv2.
filterSpeckles
(
img,newVal,maxSpeckleSize,maxDiff
[
,buf
]
)
→无
getOptimalNewCameraMatrix
根据自由缩放参数返回新的相机矩阵。
-
C ++:
Mat
getOptimalNewCameraMatrix
(
InputArray
cameraMatrix
,InputArray
distCoeffs
,Size
imageSize
,double
alpha
,Size
newImgSize
= Size(),Rect *
validPixROI
= 0,bool
centerPrincipalPoint
= false
)
-
的Python:
cv2.
getOptimalNewCameraMatrix
(
cameraMatrix,distCoeffs,IMAGESIZE,α-
[
,newImgSize
[
,centerPrincipalPoint
]
]
)
→RETVAL,validPixROI
-
C:
空隙
cvGetOptimalNewCameraMatrix
(
常量*与CvMat
camera_matrix
,常量*与CvMat
dist_coeffs
,CvSize
IMAGE_SIZE
,双
阿尔法
,*与CvMat
new_camera_matrix
,CvSize
new_imag_size
= cvSize(0,0),CvRect *
valid_pixel_ROI
= 0,INT
center_principal_point
= 0
)
-
的Python:
-
参数: - cameraMatrix - 输入相机矩阵。
- distCoeffs - 输入 4,5或8个元素的失真系数向量 。如果矢量为空/空,则假定零失真系数。
- imageSize - 原始图像大小。
- alpha - 在0(当所有未失真图像中的所有像素均有效)和1(当所有源图像像素保留在未失真图像中时)之间的自由缩放参数。见
stereoRectify()细节。 - new_camera_matrix - 输出新的相机矩阵。
- new_imag_size - 整形后的图像大小。默认情况下,它被设置为
imageSize。 - validPixROI - 可选输出矩形,用于勾勒未失真图像中的所有好像素区域。请参阅中的 说明 。
roi1, roi2stereoRectify() - centerPrincipalPoint - 可选标志,指示在新相机矩阵中主点是否应位于图像中心。默认情况下,主点被选择为最适合源图像的一个子集(由其确定
alpha)到校正的图像。
cv.
GetOptimalNewCameraMatrix
(
cameraMatrix,distCoeffs,IMAGESIZE,α,newCameraMatrix,newImageSize =(0,0),validPixROI = 0,centerPrincipalPoint = 0
)
→无
该功能根据自由缩放参数计算并返回最佳的新相机矩阵。通过改变这个参数,你可以只检索合适的像素alpha=0,如果在角落里有有价值的信息alpha=1,或者在两者之间得到一些东西,就保留所有的原始图像像素。当alpha>0失真结果可能具有对应于所捕获的失真图像之外的“虚拟”像素的一些黑色像素时。原始摄像机矩阵,失真系数,计算出的新摄像机矩阵,并newImageSize应传递 initUndistortRectifyMap()给产生的地图 remap()。
initCameraMatrix2D
从3D-2D点对应中查找初始相机矩阵。
-
C ++:
垫
initCameraMatrix2D
(
InputArrayOfArrays
objectPoints
,InputArrayOfArrays
imagePoints
,尺寸
IMAGESIZE
,双
的aspectRatio
= 1。
)
-
的Python:
cv2.
initCameraMatrix2D
(
objectPoints,imagePoints,IMAGESIZE
[
,的aspectRatio
]
)
→RETVAL
-
C:
空隙
cvInitIntrinsicParams2D
(
常量*与CvMat
object_points
,常量*与CvMat
image_points
,常量*与CvMat
npoints
,CvSize
IMAGE_SIZE
,*与CvMat
camera_matrix
,双
ASPECT_RATIO
= 1。
)
-
的Python:
-
参数: - objectPoints - 校准图案向量矢量指向校准图案坐标空间中的点。在旧的界面中,所有的每个视图矢量被连接在一起。见
calibrateCamera()细节。 - imagePoints - 校准图案点投影向量的向量。在旧的界面中,所有的每个视图矢量被连接在一起。
- npoints - 每个视图的点计数器的整数向量。
- imageSize - 用于初始化主点的图像大小(以像素为单位)。
- 的aspectRatio -如果它是零或负数,既 和 独立评估。否则,
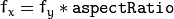 。
。
- objectPoints - 校准图案向量矢量指向校准图案坐标空间中的点。在旧的界面中,所有的每个视图矢量被连接在一起。见
cv.
InitIntrinsicParams2D
(
objectPoints,imagePoints,npoints,IMAGESIZE,cameraMatrix,的aspectRatio = 1。
)
→无
该功能估算并返回相机校准过程的初始相机矩阵。目前,该功能仅支持平面校准图案,这是每个物点具有z坐标= 0的图案。
matMulDeriv
计算每个乘法矩阵的矩阵乘积的偏导数。
-
C ++:
void
matMulDeriv
(
InputArray
A
,InputArray
B
,OutputArray
dABdA
,OutputArray
dABdB
)
-
的Python:
-
参数: - A - 第一个乘法矩阵。
- B - 第二乘法矩阵。
- dABdA -
d(A*B)/dA尺寸的 第一个输出导数矩阵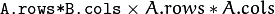 。
。 - dABdB -
d(A*B)/dB尺寸的 第二个输出导数矩阵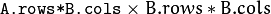 。
。
cv2.
matMulDeriv
(
A,B
[
,dABdA
[
,dABdB
]
]
)
→dABdA,dABdB
该函数 针对两个输入矩阵中的每一个的元素来计算矩阵积的元素的偏导 数。该函数用于计算雅可比矩阵,
针对两个输入矩阵中的每一个的元素来计算矩阵积的元素的偏导 数。该函数用于计算雅可比矩阵, stereoCalibrate() 但也可用于任何其他类似的优化函数。
projectPoints
项目3D指向图像平面。
-
C ++:
void
projectPoints
(
InputArray
objectPoints
,InputArray
rvec
,InputArray
tvec
,InputArray
cameraMatrix
,InputArray
distCoeffs
,OutputArray
imagePoints
,OutputArray
jacobian
= noArray(),double
aspectRatio
= 0
)
-
的Python:
cv2.
projectPoints
(
objectPoints,RVEC,tvec,cameraMatrix,distCoeffs
[
,imagePoints
[
,雅可比
[
,的aspectRatio
]
]
]
)
→imagePoints,雅可比
-
C:
void
cvProjectPoints2
(
const CvMat *
object_points
,const CvMat *
rotation_vector
,const CvMat *
translation_vector
,const CvMat *
camera_matrix
,const CvMat *
distortion_coeffs
,CvMat *
image_points
,CvMat *
dpdrot
= NULL,CvMat *
dpdt
= NULL,CvMat *
dpdf
= NULL ,CvMat *
dpdc
= NULL,CvMat *
dpddist
= NULL,double
aspect_ratio
= 0
)
-
的Python:
-
参数: - objectPoints - 对象点数组,3xN / Nx3 1通道或1xN / Nx1 3通道(或
vector<Point3f>),其中N是视图中的点数。 - rvec - 旋转矢量。见
Rodrigues()细节。 - tvec - 翻译矢量。
- cameraMatrix - 相机矩阵
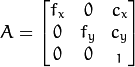 。
。 - distCoeffs - 输入 4,5或8个元素的失真系数向量 。如果矢量为空/空,则假定零失真系数。
- imagePoints -图像点,2×N个/ NX2 1通道或1×N个/ NX1 2通道,或者输出阵列
vector<Point2f>。 - jacobian - 相对于旋转矢量的分量,平移向量,焦距,主点坐标和失真系数,可选择输出2Nx(10+ <numDistCoeffs>)图像点的导数的雅可比矩阵。在旧的界面中,不同的雅可比组分通过不同的输出参数返回。
- aspectRatio - 可选的“固定长宽比”参数。如果参数不为0,则函数假定长宽比(fx / fy)是固定的,并相应地调整雅可比矩阵。
- objectPoints - 对象点数组,3xN / Nx3 1通道或1xN / Nx1 3通道(或
cv.
ProjectPoints2
(
objectPoints,RVEC,tvec,cameraMatrix,distCoeffs,imagePoints,dpdrot =无,DPDT =无,dpdf =无,DPDC =无,dpddist =无
)
→无
该功能计算给定固有和非固有摄像机参数的三维点到图像平面的投影。可选地,该函数针对特定参数(内在的和/或外在的)计算图像点坐标的偏导数的雅可比矩阵(作为所有输入参数的函数)。在雅可比在全局优化过程中使用 calibrateCamera(), solvePnP()和 stereoCalibrate()。考虑到当前的内部和外部参数,函数本身也可以用来计算重新投影误差。
注意
通过设置rvec=tvec=(0,0,0) 或设置cameraMatrix为3×3的单位矩阵,或通过零失真系数,可以得到各种有用的功能部分情况。这意味着您可以计算稀疏点集的失真坐标,或者在理想的零失真设置中应用透视变换(并计算导数)。
reprojectImageTo3D
将差异图像重新投影到3D空间。
-
C ++:
void
reprojectImageTo3D
(
InputArray
disparity
,OutputArray
_3dImage
,InputArray
Q
,bool
handleMissingValues
= false,int
ddepth
= -1
)
-
的Python:
cv2.
reprojectImageTo3D
(
视差,Q
[
,_3dImage
[
,handleMissingValues
[
,ddepth
]
]
]
)
→_3dImage
-
C:
空隙
cvReprojectImageTo3D
(
常量CvArr *
disparityImage
,CvArr *
_3dImage
,常量与CvMat *
Q
,INT
handleMissingValues
= 0
)
-
的Python:
-
参数: - 视差 - 输入单通道8位无符号,16位有符号,32位有符号或32位浮点视差图像。
- _3dImage - 输出相同尺寸的3通道浮点图像
disparity。_3dImage(x,y)包含(x,y)从视差图计算出的点的三维坐标的 每个元素 。 - Q -
 透视变换矩阵,可以用
透视变换矩阵,可以用 stereoRectify()。 - handleMissingValues - 表示函数是否应该处理缺失值(即不计算视差的点)。如果
handleMissingValues=true,那么具有与异常值相对应的最小视差的像素(参见StereoBM::operator())被转换为具有非常大的Z值(当前设置为10000)的3D点。 - ddepth - 可选的输出数组深度。如果是
-1,输出图像将CV_32F有深度。ddepth也可以设置为CV_16S,CV_32S或者CV_32F。
cv.
ReprojectImageTo3D
(
视差,_3dImage,Q,handleMissingValues = 0
)
→无
该功能将单通道视差图转换成代表3D表面的3通道图像。也就是说,对于每个像素(x,y)和相应的视差d=disparity(x,y),它计算:
![\ begin {array} {l} [X \; Y \; Z \; W] ^ T = \ text {Q} * [x \ y \; \ texttt {disparity}(x,y)\; (x,y)=(X / W,\; Y / W,\; Z / W)\ end {array}](https://docs.opencv.org/2.4/_images/math/febeb096c7cbbd6472eaad73947edddd8483708a.png)
该矩阵Q可以是任意 矩阵(例如,通过计算的矩阵 stereoRectify())。要将一组稀疏的点{(x,y,d),...}重新映射到三维空间,请使用perspectiveTransform()。
RQDecomp3x3
计算3x3矩阵的RQ分解。
-
C ++:
Vec3d
RQDecomp3x3
(
InputArray
src
,OutputArray
mtxR
,OutputArray
mtxQ
,OutputArray
Qx
= noArray(),OutputArray
Qy
= noArray(),OutputArray
Qz
= noArray()
)
-
的Python:
cv2.
RQDecomp3x3
(
SRC
[
,mtxR
[
,mtxQ
[
,QX
[
,QY
[
,QZ
]
]
]
]
]
)
→RETVAL,mtxR,mtxQ,QX,QY,QZ
-
C:
空隙
cvRQDecomp3x3
(
常量*与CvMat
matrixM
,*与CvMat
matrixR
,*与CvMat
matrixQ
,*与CvMat
matrixQx
= NULL,*与CvMat
matrixQy
= NULL,*与CvMat
matrixQz
= NULL,CvPoint3D64f *
为:eulerAngles
= NULL
)
-
的Python:
-
参数: - src - 3x3输入矩阵。
- mtxR - 输出3x3上三角矩阵。
- mtxQ - 输出3x3正交矩阵。
- Qx - 围绕x轴可选择输出3x3旋转矩阵。
- Qy - 围绕y轴可选输出3x3旋转矩阵。
- Qz - 围绕z轴可选择输出3x3旋转矩阵。
cv.
RQDecomp3x3
(
M,R,Q,QX =无,QY =无,QZ =无
)
→为:eulerAngles
该函数使用给定的旋转计算RQ分解。该函数用于 decomposeProjectionMatrix()将投影矩阵的左侧3x3子矩阵分解为相机和旋转矩阵。
它可以选择返回三个旋转矩阵,每个轴一个,以及可以在OpenGL中使用的以度为单位的三个欧拉角(作为返回值)。请注意,总是有三个以上的主轴旋转的顺序,导致相同的方向的一个对象,例如。见[Slabaugh]。返回的树旋转矩阵和相应的三个欧拉角仅是可能的解决方案之一。
罗德里格斯
将旋转矩阵转换为旋转矢量,反之亦然。
-
C ++:
void
Rodrigues
(
InputArray
src
,OutputArray
dst
,OutputArray
jacobian
= noArray()
)
-
的Python:
cv2.
Rodrigues
(
SRC
[
,DST
[
,雅可比
]
]
)
→DST,雅可比
-
C:
int
cvRodrigues2
(
const CvMat *
src
,CvMat *
dst
,CvMat *
jacobian
= 0
)
-
的Python:
-
参数: - src - 输入旋转矢量(3x1或1x3)或旋转矩阵(3x3)。
- dst - 分别输出旋转矩阵(3x3)或旋转矢量(3x1或1x3)。
- jacobian - 可选输出雅可比矩阵,3x9或9x3,它是输出数组分量相对于输入数组分量的偏导数矩阵。
cv.
Rodrigues2
(
SRC,DST,雅可比= 0
)
→无
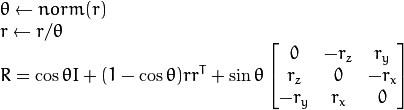
反转换也可以很容易完成,因为
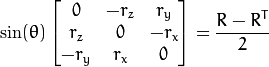
旋转矢量是旋转矩阵的一种方便和最紧凑的表示(因为任何旋转矩阵只有3个自由度)。表现形式为全球3D几何优化程序一样使用calibrateCamera(), stereoCalibrate()或 solvePnP()。
StereoBM
-
类
StereoBM
使用块匹配算法计算立体对应的类。
该类是相关函数的C ++包装器。特别StereoBM::operator()是包装 cvFindStereoCorrespondenceBM()。
StereoBM :: StereoBM
构造函数
-
C ++: (
)
StereoBM::
StereoBM
-
C ++:
StereoBM::
StereoBM
(
INT
预置
,INT
ndisparities
= 0,INT
SADWindowSize
= 21
)
-
Python:
cv2.
StereoBM
(
[
preset
[
,ndisparities
[
,SADWindowSize
]
]
]
)
→<StereoBM object>
-
C:
CvStereoBMState *
cvCreateStereoBMState
(
int
preset
= CV_STEREO_BM_BASIC,int
numberOfDisparities
= 0
)
-
的Python:
-
参数: - 预设 -
指定整套算法参数之一:
- BASIC_PRESET - 适用于一般相机的参数
- FISH_EYE_PRESET - 适用于广角相机的参数
- NARROW_PRESET - 适用于窄角度摄像机的参数
构建完课程后,您可以覆盖预设的任何参数。
- ndisparities - 差异搜索范围。对于每个像素算法,将找到从0(默认最小视差)到的最佳视差
ndisparities。然后可以通过改变最小差异来移动搜索范围。 - SADWindowSize - 算法比较块的线性大小。大小应该是奇数(因为块以当前像素为中心)。较大的块大小意味着更平滑但不太精确的视差图。较小的块大小给出更详细的视差图,但算法找到错误的对应关系的机会较大。
- 预设 -
cv.
CreateStereoBMState
(
预设= CV_STEREO_BM_BASIC,numberOfDisparities = 0
)
→CvStereoBMState
构造函数初始化StereoBM状态。然后可以调用StereoBM::operator()计算特定立体声对的差异。
注意
在C API中,CvStereoBM当不再需要使用状态时,需要释放状态cvReleaseStereoBMState(&stereobm)。
StereoBM :: operator()
使用BM算法计算校正立体声对的差异。
-
C ++:
void
StereoBM::
operator()
(
InputArray
left
,InputArray
right
,OutputArray
disparity
,int
disptype
= CV_16S
)
-
的Python:
cv2.StereoBM.
compute
(
左,右
[
视差
[
,disptype
]
]
)
→视差
-
C:
void
cvFindStereoCorrespondenceBM
(
const CvArr *
left
,const CvArr *
right
,CvArr *
disparity
,CvStereoBMState *
state
)
-
Python的:
-
参数: - 左 - 左8位单通道图像。
- 右 - 右图像的大小和左侧的相同的类型。
- 差距 - 产出差距图。它具有与输入图像相同的尺寸。当
disptype==CV_16S该映射是一个16位有符号的单通道图像时,包含16倍的视差值。为了从这样的定点表示中获得真实的视差值,需要将每个disp元素除以16.如果disptype==CV_32F视差图将已经包含输出的实际差异值。 - disptype - 输出视差图的类型,
CV_16S(默认)或CV_32F。 - 状态 -
CvStereoBMState旧API 的预初始化结构。
cv.
FindStereoCorrespondenceBM
(
左,右,差距,状态
)
→无
该方法在整流立体声对上执行BM算法。请参阅stereo_match.cppOpenCV示例以了解如何准备映像并调用该方法。请注意,该方法是不恒定的,因此你不应该StereoBM在不同的线程同时使用同一个实例。该功能与TBB库并行。
StereoSGBM
-
类
StereoSGBM
使用半全局块匹配算法计算立体对应的类。
该类实现了修改后的H. Hirschmuller算法[HH08],与以前的算法不同,如下所示:
- 默认情况下,算法是单通道,这意味着您只考虑5个方向而不是8个。设置
fullDP=true为运行算法的完整变体,但要注意可能会消耗大量内存。- 该算法匹配块,而不是单个像素。虽然,设置
SADWindowSize=1减少块为单个像素。- 互信息成本函数没有实现。相反,使用[BT98]中更简单的Birchfield-Tomasi子像素度量。虽然,彩色图像也支持。
StereoBM::operator()包括K. Konolige算法的一些预处理和后处理步骤,例如:预滤波(CV_STEREO_BM_XSOBEL类型)和后滤波(唯一性检查,二次插值和斑点滤波)。
注意
- (Python)可以在opencv_source_code / samples / python2 / stereo_match.py中找到说明使用StereoSGBM匹配算法的示例
StereoSGBM :: StereoSGBM
-
C ++: (
)
StereoSGBM::
StereoSGBM
-
C ++:
StereoSGBM::
StereoSGBM
(
INT
minDisparity
,INT
numDisparities
,INT
SADWindowSize
,INT
P1
= 0,INT
P2
= 0,INT
disp12MaxDiff
= 0,INT
preFilterCap
= 0,INT
uniquenessRatio
= 0,INT
speckleWindowSize
= 0,INT
speckleRange
= 0,布尔
fullDP
=假
)
-
的Python:
-
初始化
StereoSGBM并将参数设置为自定义值。参数: - minDisparity - 最小可能的差异值。通常情况下,它是零,但有时整流算法可以移动图像,所以这个参数需要作相应的调整。
- numDisparities - 最大差异减去最小差异。该值总是大于零。在当前的实现中,这个参数必须被16整除。
- SADWindowSize - 匹配的块大小。它必须是一个奇数
>=1。通常情况下,它应该在3..11范围内的某个地方。 - P1 - 控制视差平滑度的第一个参数。见下文。
- P2 - 控制视差平滑度的第二个参数。数值越大,差距越平滑。
P1是相邻像素之间的视差变化加减1的惩罚。P2是相邻像素之间的视差变化超过1的处罚。该算法需要 。见 样品,其中一些合理的良好 和 值显示(像 和 分别)。P2 >P1stereo_match.cppP1P28*number_of_image_channels*SADWindowSize*SADWindowSize32*number_of_image_channels*SADWindowSize*SADWindowSize - disp12MaxDiff - 左右视差检查中允许的最大差异(以整数像素为单位)。将其设置为非正值以禁用检查。
- preFilterCap - 预滤波图像像素的截断值。该算法首先计算每个像素的x导数,并按 时间间隔剪切其值 。结果值被传递给Birchfield-Tomasi像素成本函数。
[-preFilterCap, preFilterCap] - 唯一性比率 - 以最佳(最小)计算的成本函数值应该“赢”第二最佳值的百分比来保证找到的匹配是正确的。通常情况下,5-15范围内的值是足够好的。
- speckleWindowSize - 平滑视差区域的最大尺寸,以考虑其噪声斑点和无效。将其设置为0可禁用斑点过滤。否则,将其设置在50-200的范围内。
- speckleRange - 每个连接组件内的最大视差变化。如果你做斑点过滤,将参数设置为正值,它将被隐式乘以16.通常,1或2是足够好的。
- fullDP - 将其设置
true为运行全尺寸双通道动态编程算法。它会消耗O(W * H * numDisparities)字节,这对于640x480立体声很大,对于HD尺寸的图片很大。默认情况下,它被设置为false。
cv2.
StereoSGBM
(
[
minDisparity,numDisparities,SADWindowSize
[
,P1
[
,P2
[
,disp12MaxDiff
[
,preFilterCap
[
,uniquenessRatio
[
,speckleWindowSize
[
,speckleRange
[
,fullDP
]
]
]
]
]
]
]
]
]
)
→<StereoSGBM对象>
第一个构造函数StereoSGBM使用所有的默认参数进行初始化。所以,你只需要设置StereoSGBM::numberOfDisparities最低限度。第二个构造函数使您可以将每个参数设置为一个自定义值。
StereoSGBM :: operator()
-
C ++:
void
StereoSGBM::
operator()
(
InputArray
left
,InputArray
right
,OutputArray
disp
)
-
的Python:
-
使用SGBM算法计算整幅立体对的差异。
参数: - 左 - 左8位单通道或3通道图像。
- 右 - 右图像的大小和左侧的相同的类型。
- 显示 - 输出视差图。它是与输入图像大小相同的16位有符号单通道图像。它包含16位的视差值。因此,要获得浮点视差图,需要将每个
disp元素除以16。
cv2.StereoSGBM.
compute
(
左,右
[
,DISP
]
)
→DISP
该方法在整流的立体声对上执行SGBM算法。有关stereo_match.cpp如何准备图像并调用方法,请参阅OpenCV示例。
注意
该方法不是一成不变的,所以你不应该StereoSGBM从不同的线程同时使用同一个实例。
stereoCalibrate
校准立体相机。
-
C ++:
双
stereoCalibrate
(
InputArrayOfArrays
objectPoints
,InputArrayOfArrays
imagePoints1
,InputArrayOfArrays
imagePoints2
,InputOutputArray
cameraMatrix1
,InputOutputArray
distCoeffs1
,InputOutputArray
cameraMatrix2
,InputOutputArray
distCoeffs2
,尺寸
IMAGESIZE
,OutputArray
- [R
,OutputArray
Ť
,OutputArray
ê
,OutputArray
˚F
,TermCriteria
标准
= TermCriteria(TermCriteria :: COUNT + TermCriteria :: EPS,30,1e-6),int
flags
= CALIB_FIX_INTRINSIC
)
-
Python:
cv2.
stereoCalibrate
(
objectPoints,imagePoints1,imagePoints2,imageSize
[
,cameraMatrix1
[
,distCoeffs1
[
,cameraMatrix2
[
,distCoeffs2
[
,R
[
,T
[
,E
[
,F
[
,criteria
[
,flags
]
]
]
]
]
]
]
]
]
]]
)
→RETVAL,cameraMatrix1,distCoeffs1,cameraMatrix2,distCoeffs2,R,T,E,F
-
C:
double
cvStereoCalibrate
(
const CvMat *
object_points
,const CvMat *
image_points1
,const CvMat *
image_points2
,const CvMat *
npoints
,CvMat *
camera_matrix1
,CvMat *
dist_coeffs1
,CvMat *
camera_matrix2
,CvMat *
dist_coeffs2
,CvSize
image_size
,CvMat *
R
,CvMat *
T
,与CvMat *
ë
= 0,*与CvMat
˚F
= 0,CvTermCriteria
term_crit
= cvTermCriteria(CV_TERMCRIT_ITER + CV_TERMCRIT_EPS,30,1e-6),整数
标志
= CV_CALIB_FIX_INTRINSIC
)
-
Python:
-
参数: - objectPoints - 校准图案点向量的向量。
- imagePoints1 - 由第一台摄像机观察到的校准图案点投影向量的向量。
- imagePoints2 - 由第二台摄像机观察到的校准图案点投影向量的向量。
- cameraMatrix1 - 输入/输出第一个摄像头矩阵:
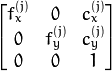 ,
,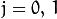 。如果有任何的
。如果有任何的 CV_CALIB_USE_INTRINSIC_GUESS,CV_CALIB_FIX_ASPECT_RATIO,CV_CALIB_FIX_INTRINSIC,或CV_CALIB_FIX_FOCAL_LENGTH指定,部分或全部基质成分必须初始化。详细信息请参阅标志说明。 - distCoeffs1 - 4,5或8个元素的失真系数的输入/输出向量 。输出向量长度取决于标志。
- cameraMatrix2 - 输入/输出第二个摄像头矩阵。该参数类似于
cameraMatrix1。 - distCoeffs2 - 第二台摄像机的输入/输出镜头失真系数。该参数类似于
distCoeffs1。 - imageSize - 仅用于初始化内在摄像机矩阵的图像大小。
- R - 第一个和第二个摄像头坐标系之间的输出旋转矩阵。
- T - 摄像机坐标系之间的输出平移矢量。
- 电子输出基本矩阵。
- F - 输出基本矩阵。
- term_crit - 迭代优化算法的终止条件。
- 标志 -
不同的标志可能是零或以下值的组合:
- CV_CALIB_FIX_INTRINSIC修复
cameraMatrix?并distCoeffs?因此只有 和 矩阵估计。R, T, EF - CV_CALIB_USE_INTRINSIC_GUESS根据指定的标志优化部分或全部内部参数。初始值由用户提供。
- CV_CALIB_FIX_PRINCIPAL_POINT在优化期间修正主要点。
- CV_CALIB_FIX_FOCAL_LENGTH修复
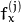 和
和 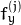 。
。 - CV_CALIB_FIX_ASPECT_RATIO优化。修正比例
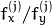 。
。 - CV_CALIB_SAME_FOCAL_LENGTH强制
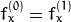 和
和 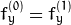 。
。 - CV_CALIB_ZERO_TANGENT_DIST设置每个摄像机的切向失真系数为零,并在那里修复。
- CV_CALIB_FIX_K1,...,CV_CALIB_FIX_K6在优化过程中不要改变相应的径向畸变系数。如果
CV_CALIB_USE_INTRINSIC_GUESS设置,distCoeffs则使用提供的矩阵的系数 。否则,它被设置为0。 - CV_CALIB_RATIONAL_MODEL启用系数k4,k5和k6。为了提供向后兼容性,应该明确指定这个额外的标志,以使校准函数使用有理模型并返回8个系数。如果没有设置标志,则该功能仅计算并返回5个失真系数。
- CV_CALIB_FIX_INTRINSIC修复
cv.
StereoCalibrate
(
objectPoints,imagePoints1,imagePoints2,pointCounts,cameraMatrix1,distCoeffs1,cameraMatrix2,distCoeffs2,imageSize,R,T,E = None,F = None,term_crit =(CV_TERMCRIT_ITER + CV_TERMCRIT_EPS,30,1e-6),flags = CV_CALIB_FIX_INTRINSIC
)
→无
该功能估计两个摄像机之间的转换成立体声对。如果您有一台立体相机,其中两台相机的相对位置和方向是固定的,并且如果您计算了一个物体相对于第一台相机和第二台相机的姿势(R1,T1)和(R2,T2) (这可以完成 solvePnP()),那么这些姿势肯定是相互关联的。这意味着,给定(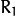 ,:数学:T_1),应该可以计算(
,:数学:T_1),应该可以计算( 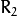 ,:数学:T_2)。您只需要知道第二台摄像机相对于第一台摄像机的位置和方向。这是所描述的功能所做的。它计算(
,:数学:T_2)。您只需要知道第二台摄像机相对于第一台摄像机的位置和方向。这是所描述的功能所做的。它计算( 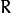 ,:数学:T),以便:
,:数学:T),以便:
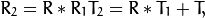
可选地,它计算基本矩阵E:
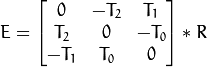
这里 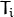 是平移矢量的分量
是平移矢量的分量 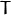 :
: ![T = [T_0,T_1,T_2] ^ T](https://docs.opencv.org/2.4/_images/math/9ab068430870cda7cb8b114c4876a69b0ef7a89a.png) 。该函数还可以计算基本矩阵F:
。该函数还可以计算基本矩阵F:
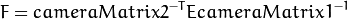
除了立体声相关信息之外,该功能还可以对两台摄像机进行全面校准。但是,由于输入数据中的参数空间和噪声的高维度,函数可能偏离正确的解决方案。如果可以为每个摄像机单独(例如,使用calibrateCamera())高精度地估计内部参数 ,则建议您这样做,然后将CV_CALIB_FIX_INTRINSIC标志与所计算的内部参数一起传递给函数。否则,如果所有的参数都是一次估计的,那么限制一些参数是合理的,例如pass CV_CALIB_SAME_FOCAL_LENGTH和CV_CALIB_ZERO_TANGENT_DISTflags,这通常是一个合理的假设。
类似地calibrateCamera(),该功能使来自两个相机的所有可用视图中的所有点的总的重新投影误差最小化。该函数返回重新投影错误的最终值。
stereoRectify
计算校准立体相机的每个头部的校正变换。
-
C ++:
空隙
stereoRectify
(
InputArray
cameraMatrix1
,InputArray
distCoeffs1
,InputArray
cameraMatrix2
,InputArray
distCoeffs2
,尺寸
IMAGESIZE
,InputArray
- [R
,InputArray
Ť
,OutputArray
R1
,OutputArray
R2
,OutputArray
P1
,OutputArray
P2
,OutputArray
Q
,整数
标志
= CALIB_ZERO_DISPARITY,双
阿尔法
= -1 ,大小
newImageSize
= Size(),Rect *
validPixROI1
= 0,Rect *
validPixROI2
= 0
)
-
C:
void
cvStereoRectify
(
const CvMat *
camera_matrix1
,const CvMat *
camera_matrix2
,const CvMat *
dist_coeffs1
,const CvMat *
dist_coeffs2
,CvSize
image_size
,const CvMat *
R
,const CvMat *
T
,CvMat *
R1
,CvMat *
R2
,CvMat *
P1
,CvMat *
P2
,CvMat *
Q
= 0,int
flags
= CV_CALIB_ZERO_DISPARITY,double
alpha
= -1,CvSize
new_image_size
= cvSize(0,0),CvRect *
valid_pix_ROI1
= 0,CvRect *
valid_pix_ROI2
= 0
)
-
的Python:
-
参数: - cameraMatrix1 - 第一个摄像头矩阵。
- cameraMatrix2 - 第二个摄像头矩阵。
- distCoeffs1 - 第一个摄像头失真参数。
- distCoeffs2 - 第二个摄像头失真参数。
- imageSize - 用于立体校准的图像大小。
- R - 第一台和第二台相机坐标系之间的旋转矩阵。
- T - 相机坐标系之间的平移矢量。
- R1 - 为第一台摄像机输出3x3整流变换(旋转矩阵)。
- R2 - 为第二台摄像机输出3x3整流变换(旋转矩阵)。
- P1 - 在第一台相机的新(校正)坐标系中输出3x4投影矩阵。
- P2 - 在第二个摄像机的新(校正)坐标系中输出3x4投影矩阵。
- Q - 输出 视差 - 深度映射矩阵(参见
reprojectImageTo3D())。 - 标志 - 操作标志可能是零或
CV_CALIB_ZERO_DISPARITY。如果该标志被设置,则该功能使得每个摄像机的主点在经整流的视图中具有相同的像素坐标。如果没有设置标志,该功能仍然可以将图像在水平或垂直方向上移动(取决于极线的方向)以最大化有用的图像区域。 - alpha - 自由缩放参数。如果它是-1或不存在,则该函数执行默认缩放。否则,参数应该在0和1之间。
alpha=0意味着校正的图像被放大并移动,使得只有有效的像素可见(在整流之后没有黑色区域)。alpha=1意味着校正的图像被抽取和移位,使得来自相机的原始图像的所有像素都保留在整流图像中(没有源图像像素丢失)。显然,任何中间值都会在这两个极端情况之间产生中间结果。 - newImageSize - 更正后的新图像分辨率。应该传递相同的大小
initUndistortRectifyMap()(参见stereo_calib.cppOpenCV示例目录中的 示例)。当(0,0)通过时(默认),它被设置为原始imageSize。将其设置为较大的值可以帮助您保留原始图像中的细节,特别是在存在较大径向失真的情况下。 - validPixROI1 - 所有像素有效的校正图像内的可选输出矩形。如果
alpha=0,投资回报率覆盖整个图像。否则,他们可能会变小(见下图)。 - validPixROI2 - 在所有像素都有效的校正图像内的可选输出矩形。如果
alpha=0,投资回报率覆盖整个图像。否则,他们可能会变小(见下图)。
cv.
StereoRectify
(
cameraMatrix1,cameraMatrix2,distCoeffs1,distCoeffs2,IMAGESIZE,R,T,R1,R2,P1,P2,Q =无,标志= CV_CALIB_ZERO_DISPARITY,α-= -1,newImageSize =(0,0)) - >(ROI1 ,roi2
)
该功能计算每个摄像机的旋转矩阵(虚拟)使两个摄像机图像平面在同一平面上。因此,这使得所有的核线平行,从而简化了密集的立体对应问题。该函数将stereoCalibrate()输入的矩阵计算出来 。作为输出,它在新坐标中提供了两个旋转矩阵和两个投影矩阵。该功能区分以下两种情况:
-
水平立体声:第一个和第二个摄像机视图主要沿x轴相对移动(可能有小的垂直位移)。在校正的图像中,左侧和右侧相机中对应的极线是水平的并且具有相同的y坐标。P1和P2看起来像:
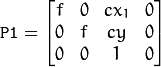
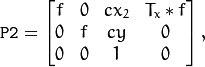
哪里
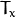 是相机之间的水平移动,
是相机之间的水平移动, 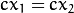 如果
如果CV_CALIB_ZERO_DISPARITY设置。 -
垂直立体声:第一和第二摄像机视图主要在垂直方向上彼此相对移动(也可能在水平方向上稍微移动一点)。校正图像中的核线是垂直的并具有相同的x坐标。P1和P2看起来像:
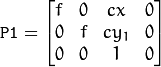
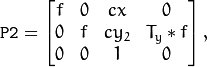
其中
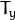 在摄影机间和垂直移位
在摄影机间和垂直移位 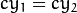 如果
如果CALIB_ZERO_DISPARITY被设置。
正如你所看到的,前三列P1和P2将有效地成为新的“纠正”相机矩阵。然后可以将这些矩阵与R1和一起R2传递 initUndistortRectifyMap()给初始化每个摄像机的校正图。
从stereo_calib.cpp示例中看下面的截图。一些红色的水平线穿过相应的图像区域。这意味着图像很好地纠正了,这是大多数立体声对应算法所依赖的。绿色的矩形是roi1和roi2。你看到他们的内部都是有效的像素。

stereoRectifyUncalibrated
计算未校准的立体相机的校正变换。
-
C ++:
布尔
stereoRectifyUncalibrated
(
InputArray
points1
,InputArray
points2
,InputArray
˚F
,尺寸
imgSize
,OutputArray
H1
,OutputArray
H2
,双
阈值
= 5
)
-
的Python:
cv2.
stereoRectifyUncalibrated
(
points1,points2,F,imgSize
[
,H1
[
,H2
[
,阈
]
]
]
)
→RETVAL,H1,H2
-
C:
INT
cvStereoRectifyUncalibrated
(
常量*与CvMat
points1
,常量*与CvMat
points2
,常量与CvMat *
˚F
,CvSize
img_size
,*与CvMat
H1
,与CvMat *
H2
,双
阈值
= 5
)
-
Python:
-
参数: - points1 - 第一个图像中的特征点数组。
- points2 - 第二个图像中的对应点。与
findFundamentalMat()支持的格式相同 。 - F - 输入基本矩阵。它可以使用相同的一组点对进行计算
findFundamentalMat()。 - imgSize - 图像的大小。
- H1 - 第一图像的输出校正单应性矩阵。
- H2 - 第二图像的输出校正单应性矩阵。
- 阈值 - 用于过滤异常值的可选阈值。如果参数大于零,
![| \ texttt {points2 [I]} ^ T * \ texttt {F} * \ texttt {points1 [I]} |> \ texttt {阈}](https://docs.opencv.org/2.4/_images/math/b4be51fed0f7cc700726e152a48af4056b9599c9.png) 则在计算单应性之前,所有不符合极线几何(即,其点)的点对都将 被拒绝。否则,所有的点被认为是内点。
则在计算单应性之前,所有不符合极线几何(即,其点)的点对都将 被拒绝。否则,所有的点被认为是内点。
cv.
StereoRectifyUncalibrated
(
points1,points2,F,imageSize,H1,H2,threshold = 5
)
→
该功能在不知道相机的内在参数及其在空间中的相对位置的情况下计算整流变换,这解释了后缀“未校准”。另一个与之不同的地方 stereoRectify()在于,函数不是输出对象(3D)空间中的整形变换,而是输出单应矩阵H1和平面的平面透视变换H2。该函数实现了算法 [Hartley99]。
注意
虽然该算法不需要知道摄像机的内部参数,但它极大地依赖于极线几何。因此,如果摄像机镜头有明显的失真,在计算基本矩阵和调用这个函数之前,最好纠正它。例如,可以通过使用分别为立体相机的每个头部估计失真系数calibrateCamera()。然后,图像可以使用校正undistort(),或只是点坐标可以纠正undistortPoints()。
triangulatePoints
通过三角测量重建点。
-
C ++:
void
triangulatePoints
(
InputArray
projMatr1
,InputArray
projMatr2
,InputArray
projPoints1
,InputArray
projPoints2
,OutputArray
points4D
)
-
的Python:
cv2.
triangulatePoints
(
projMatr1,projMatr2,projPoints1,projPoints2
[
,points4D
]
)
→points4D
-
C:
-
参数: - projMatr1 - 第一台相机的3x4投影矩阵。
- projMatr2 - 第二台相机的3x4投影矩阵。
- projPoints1 - 第一个图像中的2xN个特征点阵列。在c ++版本的情况下,它也可以是大小为1xN或Nx1的特征点或双通道矩阵的向量。
- projPoints2 - 第二个图像中相应点的2xN数组。在c ++版本的情况下,它也可以是大小为1xN或Nx1的特征点或双通道矩阵的向量。
- 点4D - 在齐次坐标中的4 ×N重建点阵列。
void
cvTriangulatePoints
(
CvMat *
projMatr1
,CvMat *
projMatr2
,CvMat *
projPoints1
,CvMat *
projPoints2
,CvMat *
points4D
)
该函数通过使用立体相机的观察来重建三维点(在齐次坐标中)。投影矩阵可以从中获得stereoRectify()。
注意
请记住,所有的输入数据都应该是浮点型的,以便这个函数能够工作。
也可以看看
鱼眼
这个命名空间中的方法使用所谓的鱼眼相机模型。
定义:设P是世界坐标系X(存储在矩阵X中)中坐标X的三维点。相机坐标系中P的坐标向量为:
-
类
center
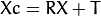
其中R是与旋转向量om对应的旋转矩阵:R = rodrigues(om); 调用x,y和z Xc的3个坐标:
-
类
center
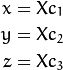
P的松孔投影坐标是[a; b]在哪里
-
类
center
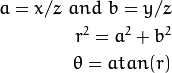
鱼眼畸变:
-
类
center
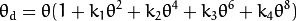
失真的点坐标是[x'; y']在哪里
..class :: center ..数学:
最后,转换成像素坐标:最后的像素坐标矢量[u; v]其中:
-
类
center
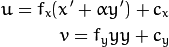
鱼眼:: projectPoints
项目要点使用鱼眼模型
-
C ++:
void
fisheye::
projectPoints
(
InputArray
objectPoints
,OutputArray
imagePoints
,const Affine3d&
affine
,InputArray
K
,InputArray
D
,double
alpha
= 0,OutputArray
jacobian
= noArray()
)
-
C ++:
-
参数: - objectPoints - 对象点数组,1xN / Nx1 3通道(或
vector<Point3f>),其中N是视图中的点数。 - rvec - 旋转矢量。见
Rodrigues()细节。 - tvec - 翻译矢量。
- K - 相机矩阵
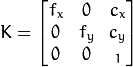 。
。 - D - 失真系数的输入向量
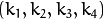 。
。 - alpha - 歪斜系数。
- imagePoints -图像点,2×N个/ NX2 1通道或1×N个/ NX1 2通道,或者输出阵列
vector<Point2f>。 - jacobian - 相对于焦距分量,主点坐标,失真系数,旋转矢量,平移矢量和偏斜,可选择输出图像点的导数2Nx15的雅可比矩阵。在旧的界面中,不同的雅可比组分通过不同的输出参数返回。
- objectPoints - 对象点数组,1xN / Nx1 3通道(或
void
fisheye::
projectPoints
(
InputArray
objectPoints
,OutputArray
imagePoints
,InputArray
rvec
,InputArray
tvec
,InputArray
K
,InputArray
D
,double
alpha
= 0,OutputArray
jacobian
= noArray()
)
该功能计算给定固有和非固有摄像机参数的三维点到图像平面的投影。可选地,该函数针对特定参数(内在的和/或外在的)计算图像点坐标的偏导数的雅可比矩阵(作为所有输入参数的函数)。
鱼眼:: distortPoints
使用鱼眼模型扭曲2D点。
-
C ++:
-
参数: - unsistorted - 对象点数组,1xN / Nx1 2通道(或
vector<Point2f>),其中N是视图中的点数。 - K - 相机矩阵 。
- D - 失真系数的输入向量 。
- alpha - 歪斜系数。
- 失真 - 图像点的输出数组,1xN / Nx1 2通道,或
vector<Point2f>。
- unsistorted - 对象点数组,1xN / Nx1 2通道(或
空隙
fisheye::
distortPoints
(
InputArray
不失真
,OutputArray
扭曲
,InputArray
ķ
,InputArray
d
,双
阿尔法
= 0
)
鱼眼:: undistortPoints
使用鱼眼模型来防止2D点
-
C ++:
-
参数: - 扭曲 - 对象点数组,1xN / Nx1 2通道(或
vector<Point2f>),其中N是视图中的点数。 - K - 相机矩阵 。
- D - 失真系数的输入向量 。
- R - 对象空间中的整流转换:3x3 1通道或矢量:3x1 / 1x3 1通道或1x1 3通道
- P - 新的相机矩阵(3x3)或新的投影矩阵(3x4)
- 未失真 - 图像点的输出阵列,1xN / Nx1 2通道,或
vector<Point2f>。
- 扭曲 - 对象点数组,1xN / Nx1 2通道(或
空隙
fisheye::
undistortPoints
(
InputArray
扭曲
,OutputArray
不失真
,InputArray
ķ
,InputArray
d
,InputArray
- [R
= noArray(),InputArray
P
= noArray()
)
鱼眼:: initUndistortRectifyMap
通过cv :: remap()计算图像变形的失真和校正图。如果D是空的,则使用零失真,如果R或P为空,则使用单位矩阵。
-
C ++:
-
参数: - K - 相机矩阵 。
- D - 失真系数的输入向量 。
- R - 对象空间中的整流转换:3x3 1通道或矢量:3x1 / 1x3 1通道或1x1 3通道
- P - 新的相机矩阵(3x3)或新的投影矩阵(3x4)
- 大小 - 未失真的图像大小。
- m1type - 第一个输出映射的类型,可以是CV_32FC1或CV_16SC2。有关详细信息,请参阅convertMaps()。
- map1 - 第一个输出地图。
- map2 - 第二个输出映射。
- K - 相机矩阵
void
fisheye::
initUndistortRectifyMap
(
InputArray
K
,InputArray
D
,InputArray
R
,InputArray
P
,const cv :: Size&
size
,int
m1type
,OutputArray
map1
,OutputArray
map2
)
鱼眼:: undistortImage
转换图像以补偿鱼眼镜头失真。
-
C ++:
-
参数: - 扭曲 - 与鱼眼镜头失真的图像。
- K - 相机矩阵 。
- D - 失真系数的输入向量 。
- Knew - 失真图像的相机矩阵。默认情况下,它是单位矩阵,但是您可以通过使用不同的矩阵来额外缩放和移位结果。
- 不失真 - 输出图像与补偿鱼眼镜头失真。
空隙
fisheye::
undistortImage
(
InputArray
扭曲
,OutputArray
不失真
,InputArray
ķ
,InputArray
d
,InputArray
自知
= CV :: noArray(),常量大小和
new_size
=尺寸()
)
该功能转换图像以补偿径向和切向镜头失真。
该函数只是 fisheye::initUndistortRectifyMap()(具有统一性R)和 remap()(具有双线性内插)的组合。有关正在执行的转换的详细信息,请参阅前一个函数。
-
看下面的结果undistortImage。
-
- a)
undistort()透视相机模型的结果(在校准下优化所有可能的失真系数(k_1,k_2,k_3,k_4,k_5,k_6) - b)
fisheye::undistortImage()鱼眼相机模型的结果(在校准下优化鱼眼失真的所有可能的系数(k_1,k_2,k_3,k_4) - c)用鱼眼镜头拍摄原始图像
- a)
图片a)和b)几乎一样。但是如果我们考虑远离图像中心的图像点,我们可以注意到在图像a)上这些点是失真的。

鱼眼:: estimateNewCameraMatrixForUndistortRectify
估算新的相机矩阵的失真或纠正。
-
C ++:
-
参数: - K - 相机矩阵 。
- D - 失真系数的输入向量 。
- R - 对象空间中的整流转换:3x3 1通道或矢量:3x1 / 1x3 1通道或1x1 3通道
- P - 新的相机矩阵(3x3)或新的投影矩阵(3x4)
- 平衡 - 在最小焦距和最大焦距之间的范围内设置新的焦距。平衡在[0,1]的范围内。
- fov_scale - 新焦距的除数。
- K - 相机矩阵
void
fisheye::
estimateNewCameraMatrixForUndistortRectify
(
InputArray
K
,InputArray
D
,const Size&
image_size
,InputArray
R
,OutputArray
P
,double
balance
= 0.0,const Size&
new_size
= Size(),double
fov_scale
= 1.0
)
鱼眼:: stereoRectify
鱼眼相机模型的立体校正
-
C ++:
-
参数: - K1 - 第一个相机矩阵。
- K2 - 第二个相机矩阵。
- D1 - 第一个摄像头失真参数。
- D2 - 第二个摄像机失真参数。
- imageSize - 用于立体校准的图像大小。
- 旋转 - 第一台和第二台摄像机坐标系之间的旋转矩阵。
- tvec - 相机坐标系之间的平移矢量。
- R1 - 为第一台摄像机输出3x3整流变换(旋转矩阵)。
- R2 - 为第二台摄像机输出3x3整流变换(旋转矩阵)。
- P1 - 在第一台相机的新(校正)坐标系中输出3x4投影矩阵。
- P2 - 在第二个摄像机的新(校正)坐标系中输出3x4投影矩阵。
- Q - 输出 视差 - 深度映射矩阵(参见
reprojectImageTo3D())。 - 标志 - 操作标志可能是零或
CV_CALIB_ZERO_DISPARITY。如果该标志被设置,则该功能使得每个摄像机的主点在经整流的视图中具有相同的像素坐标。如果没有设置标志,该功能仍然可以将图像在水平或垂直方向上移动(取决于极线的方向)以最大化有用的图像区域。 - alpha - 自由缩放参数。如果它是-1或不存在,则该函数执行默认缩放。否则,参数应该在0和1之间。
alpha=0意味着校正的图像被放大并移动,使得只有有效的像素可见(在整流之后没有黑色区域)。alpha=1意味着校正的图像被抽取和移位,使得来自相机的原始图像的所有像素都保留在整流图像中(没有源图像像素丢失)。显然,任何中间值都会在这两个极端情况之间产生中间结果。 - newImageSize - 更正后的新图像分辨率。应该传递相同的大小
initUndistortRectifyMap()(参见stereo_calib.cppOpenCV示例目录中的 示例)。当(0,0)通过时(默认),它被设置为原始imageSize。将其设置为较大的值可以帮助您保留原始图像中的细节,特别是在存在较大径向失真的情况下。 - roi1 - 校正图像内所有像素都有效的可选输出矩形。如果
alpha=0,投资回报率覆盖整个图像。否则,他们可能会变小(见下图)。 - roi2 - 校正图像内所有像素均有效的可选输出矩形。如果
alpha=0,投资回报率覆盖整个图像。否则,他们可能会变小(见下图)。 - 平衡 - 在最小焦距和最大焦距之间的范围内设置新的焦距。平衡在[0,1]的范围内。
- fov_scale - 新焦距的除数。
void
fisheye::
stereoRectify
(
InputArray
K1
,InputArray
D1
,InputArray
K2
,InputArray
D2
,const Size&
imageSize
,InputArray
R
,InputArray
tvec
,OutputArray
R1
,OutputArray
R2
,OutputArray
P1
,OutputArray
P2
,OutputArray
Q
,int
flags
,const Size&
newImageSize
= Size ),double
balance
= 0.0,double
fov_scale
= 1.0
)
鱼眼::校准
执行相机校准
-
C ++:
-
参数: - objectPoints - 校准图案矢量矢量指向校准图案坐标空间中的点。
- imagePoints - 校准图案点投影向量的向量。
imagePoints.size()和objectPoints.size()和imagePoints[i].size()必须等于objectPoints[i].size()每个i。 - image_size - 仅用于初始化内置相机矩阵的图像大小。
- K - 输出3x3浮点相机矩阵 。如果
fisheye::CALIB_USE_INTRINSIC_GUESS/被指定,则 在调用该函数之前,必须初始化其中的一些或全部 。fx, fy, cx, cy - D - 失真系数的输出矢量 。
- rvecs -
Rodrigues()为每个模式视图估计的旋转矢量的输出矢量(请参阅 )。也就是说,每个第k个旋转矢量与对应的第k个平移矢量(参见下一个输出参数描述)一起将校准模式从模型坐标空间(其中指定了对象点)带到世界坐标空间,是在第k个图案视图(k = 0 ... M -1)中的校准图案的实际位置。 - tvecs - 为每个模式视图估计的平移向量的输出向量。
- 标志 -
不同的标志可能是零或以下值的组合:
- 鱼眼:: CALIB_USE_INTRINSIC_GUESS
cameraMatrix包含的有效初始值 被进一步优化。否则, 最初设置为图像中心( 正在使用),焦距以最小二乘方式计算。fx, fy, cx, cy(cx, cy)imageSize - 鱼眼:: CALIB_RECOMPUTE_EXTRINSIC在每次迭代内部优化之后,将重新计算Extrinsic。
- 鱼眼:: CALIB_CHECK_COND这些功能将检查条件编号的有效性。
- 鱼眼:: CALIB_FIX_SKEW偏斜系数(alpha)设为零并保持为零。
- 鱼眼:: CALIB_FIX_K1..4所选的失真系数被设置为零并保持为零。
- 鱼眼:: CALIB_USE_INTRINSIC_GUESS
- 标准 - 迭代优化算法的终止标准。
double
fisheye::
calibrate
(
InputArrayOfArrays
objectPoints
,InputArrayOfArrays
imagePoints
,const Size&
image_size
,InputOutputArray
K
,InputOutputArray
D
,OutputArrayOfArrays
rvecs
,OutputArrayOfArrays
tvecs
,int
flags
= 0,TermCriteria
criteria
= TermCriteria(TermCriteria :: COUNT + TermCriteria :: EPS,100,DBL_EPSILON)
)
鱼眼:: stereoCalibrate
执行立体声校准
-
C ++:
-
参数: - objectPoints - 校准图案点向量的向量。
- imagePoints1 - 由第一台摄像机观察到的校准图案点投影向量的向量。
- imagePoints2 - 由第二台摄像机观察到的校准图案点投影向量的向量。
- K1 - 输入/输出第一个相机矩阵: ,。如果指定了其中的任何一个
fisheye::CALIB_USE_INTRINSIC_GUESS,fisheye::CV_CALIB_FIX_INTRINSIC则必须初始化一些或所有矩阵组件。 - D1 - 4个元素的失真系数的输入/输出向量 。
- K2 - 输入/输出第二个摄像头矩阵。该参数类似于
K1。 - D2 - 第二台摄像机的输入/输出镜头失真系数。该参数类似于
D1。 - imageSize - 仅用于初始化内在摄像机矩阵的图像大小。
- R - 第一个和第二个摄像头坐标系之间的输出旋转矩阵。
- T - 摄像机坐标系之间的输出平移矢量。
- 标志 -
不同的标志可能是零或以下值的组合:
- 鱼眼:: CV_CALIB_FIX_INTRINSIC修复,以便只估计矩阵。
K1, K2?D1, D2?R, T - 鱼眼:: CALIB_USE_INTRINSIC_GUESS 包含的有效初始值被进一步优化。否则,最初设置为图像中心(正在使用),焦距以最小二乘方式计算。
K1, K2fx, fy, cx, cy(cx, cy)imageSize - 鱼眼:: CALIB_RECOMPUTE_EXTRINSIC在每次迭代内部优化之后,将重新计算Extrinsic。
- 鱼眼:: CALIB_CHECK_COND这些功能将检查条件编号的有效性。
- 鱼眼:: CALIB_FIX_SKEW偏斜系数(alpha)设为零并保持为零。
- 鱼眼:: CALIB_FIX_K1..4所选的失真系数被设置为零并保持为零。
- 鱼眼:: CV_CALIB_FIX_INTRINSIC修复,以便只估计矩阵。
- 标准 - 迭代优化算法的终止标准。
双
fisheye::
stereoCalibrate
(
InputArrayOfArrays
objectPoints
,InputArrayOfArrays
imagePoints1
,InputArrayOfArrays
imagePoints2
,InputOutputArray
K1
,InputOutputArray
D1
,InputOutputArray
K2
,InputOutputArray
D2
,尺寸
IMAGESIZE
,OutputArray
- [R
,OutputArray
Ť
,整数
标志
= CALIB_FIX_INTRINSIC,TermCriteria
标准
= TermCriteria(TermCriteria :: COUNT + TermCriteria :: EPS,100,DBL_EPSILON)
)
| [BT98] | Birchfield,S.和Tomasi,C。对图像采样不敏感的像素相异度量。IEEE模式分析与机器智能汇刊。1998年。 |
| [BouguetMCT] | JYBouguet。MATLAB校准工具。http://www.vision.caltech.edu/bouguetj/calib_doc/ |
| [Hartley99] | Hartley,RI,“投射矫正的理论与实践”。IJCV 35 2,pp 115-127(1999) |
| [HH08] | Hirschmuller,H.Stereo Processing by Semiglobal Matching and Mutual Information,PAMI(30),第2期,2008年2月,第328-341页。 |
| [Slabaugh] | (1,2) Slabaugh,GG计算欧拉从旋转矩阵角。http://www.soi.city.ac.uk/~sbbh653/publications/euler.pdf(已核实:2013-04-15) |
| [Zhang2000] |
|
![]()
目录
- 相机校准和3D重建
- calibrateCamera
- calibrationMatrixValues
- composeRT
- computeCorrespondEpilines
- convertPointsToHomogeneous
- convertPointsFromHomogeneous
- convertPointsHomogeneous
- correctMatches
- decomposeProjectionMatrix
- drawChessboardCorners
- findChessboardCorners
- findCirclesGrid
- solvePnP
- solvePnPRansac
- findFundamentalMat
- findHomography
- estimateAffine3D
- filterSpeckles
- getOptimalNewCameraMatrix
- initCameraMatrix2D
- matMulDeriv
- projectPoints
- reprojectImageTo3D
- RQDecomp3x3
- 罗德里格斯
- StereoBM
- StereoBM :: StereoBM
- StereoBM ::运算符()
- StereoSGBM
- StereoSGBM :: StereoSGBM
- StereoSGBM :: operator()
- stereoCalibrate
- stereoRectify
- stereoRectifyUncalibrated
- triangulatePoints
- 鱼眼镜头
- 鱼眼:: projectPoints
- 鱼眼:: distortPoints
- 鱼眼:: undistortPoints
- 鱼眼:: initUndistortRectifyMap
- 鱼眼:: undistortImage
- 鱼眼:: estimateNewCameraMatrixForUndistortRectify
- 鱼眼:: stereoRectify
- 鱼眼::校准
- 鱼眼:: stereoCalibrate














 5402
5402











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









