









ScalersTalk 机器学习小组第 21 周学习笔记(深度学习-10)
Scalers点评:机器学习小组是成长会的内部小组,这是成长会机器学习小组第21周学习笔记,也是深度学习第10次的复盘笔记
本周学习情况:
本周(20160725–20160731)的学习主要为理论学习。重点介绍了Numberical stability,机器学习数据集划分,和随机梯度下降算法。本周复盘主持是[S306] Tony
一、Numerical stability:
Numerical stability,即数值稳定性,这个问题在Ng的课程里,对应的处理策略叫做特征缩放,也就是对于一个模型而言,不同feature由于数量级大小的差异,会对学习结果造成影响,这种影响不是因为特征本身而造成的,而是因为特征与特征之间的数值量级上的差异性导致的。
举个例子来说,比如在K近邻算法中,分类器主要是计算两点之间的欧几里得距离,如果一个特征比其它的特征有更大的范围值,那么距离将会被这个特征值所主导。因此每个特征应该被归一化,比如将取值范围处理为0到1之间
一般常用的特征缩放方法主要是这两种:
- (a)调节比例(Rescaling)
这种方法通常是将数据的特征缩放到[0,1]或[-1,1]之间,常用以下公式实现
- 标准化(Standardization)
特征标准化是指示的每个特征具有零均值和单位方差,通常在SVM,Logistic Regression,Neural Network里,常用以下公式实现
二、 数据集划分Training, Validation, Test:
机器学习最终是具有很好的的泛化能力的,所谓的泛化能力,泛,指的就是对于更为广泛的输入数据,是指对于一个训练好的模型,面对先前没有见过的input,可以做出较好的分类或预测。
而在模型的训练过程中如何使模型具有很好的泛化能力呢?
我们通常会采用对数据集进行划分的方法,通过将 数据集划分为训练集(Training),验证集(Validation),测试集(Test)以其能更好的调整参数和选择模型,进而得到具有较好泛化能力的机器学习模型。
- 训练集
Training Set: A set of examples used for learning, which is to fit the parameters[i.e,weights] of the classifier
训练集主要通过学习样本数据,建立一个合适的分类器,主要用来训练模型的。
- 验证集
Validation Set: A set of examples used to tune the parameters[i.e., architecture, not weights] of a classifier, for example to choose the number of hidden units in a neural network.
验证集主要对学习出来的模型进行参数调整,如选择隐藏单元的个数,确定网络结构或者控制模型的复杂程度等一些作用。
- 测试集
Test Set: A set of examples used only to assess the performance [generalization] of a fully specified classifier
测试集主要用来对训练好的模型的准确程度做一个测试。

- 验证集的大小设置
在Udactiy的课程内容设置中,对验证集的大小设置提出了一些方法

一般来说,如果样本的数目在3W以上,当准确率提升0.1%,一般不认为模型的准确率不是因为噪声而提升的。
- 交叉验证(Cross Validation)
交叉验证是在对于数据集不是很大,同时又需要设置验证集的情况下,这个时候可以采用交叉验证集的方法设置验证集,这部分在本课程中没有提及,感兴趣的朋友可以参阅Wiki或者CS231n的课程讲义
交叉验证一般称为K折交叉验证,K是指把TrainingSet分成几个fold,如下图

以5折交叉验证为例,基本的方法大致如下
split the training data into 5 equal folds, use 4 of them for training, and 1 for validation
iterating over different validation sets and averaging the performance across these data
验证集的缺点
在这里谈谈我对于验证集的缺点的一些理解,验证集的设置目的是为了提高最终模型的准确率,一般是我们在训练集上进行训练,在验证集上进行验证,如果发现准确率过低,会对模型进行调整,以其提高准确率,但是在验证的过程中,我们的model会对验证集的数据特性进行记忆,这种记忆会导致模型即使我们并没有验证集训练参数,但最后也有可能导致我们在训练集和验证集出现过拟合。
3. 随机梯度下降(Stochastic Gradient Descent, SGD)
梯度下降是我们训练参数主要使用的方法,梯度下降的具体方法在此就不再赘述,介绍一下随机梯度下降的的思路和一些优化策略
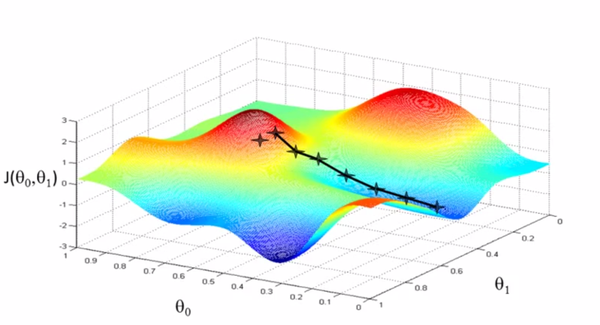
梯度下降的思路是通过假定一个初始状态,然后不断的迭代更新,选择合适的步长和方向,直至目标函数达到最小值。
在传统的梯度下降中,我们通常会有两个问题,一是陷入局部最优,二是收敛速度过慢
为了解决这两个问题,SGD应运而生,在GD中,我们在进行下降过程中计算偏导数,通常是对整个训练集的样本都计算,得到偏导数
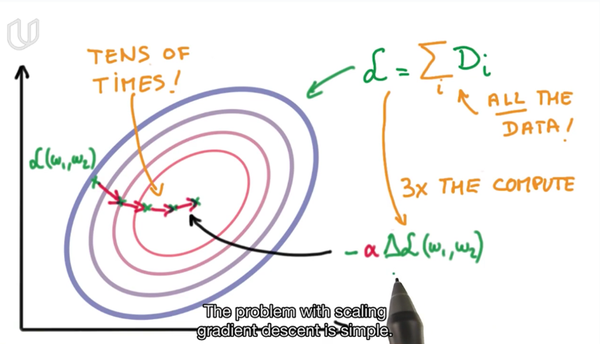
这样会保证下降的方向时正确的,都是朝着损失函数最小的方向去移动,但是计算量巨大,收敛的速度也十分缓慢,尤其当涉及的大数据的情况下的,像动辄几万张图片的训练集,运算速度也是极其缓慢的
如果我们换一种思路,每次不计算全部样本的偏导数,而是以样本集的极其小的一个子集的偏导来做估计,带入迭代过程,每次迭代过程只选择很小的数据量
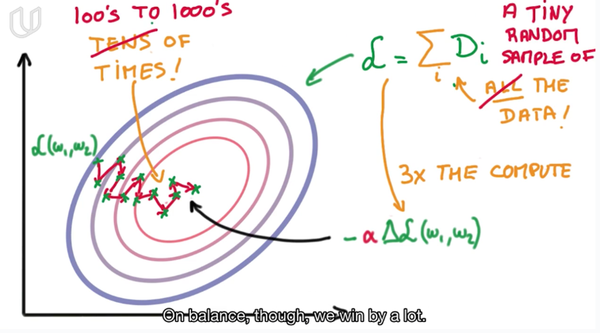
虽然可能由于只选择了很小的一部分训练集进行GD,可能导致下降方向不是最短路径,但是每次的计算量会很小,迭代速度很快,采用小步快跑的策略能很快的到达最优点,同时因为随机的原因,会导致当迭代过程陷入局部最优时,可以有较大的概率再下一次迭代中跳出局部最优,最后到达全局最优点。
在SGD的实际使用也有一些tricks可以帮助我们更好更快的达到收敛状态
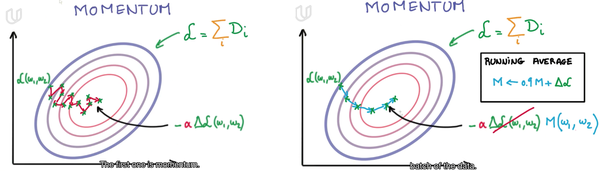
- Momentum动量
在SGD中,通常会因为随机导致下降方向出现噪声,也就是曲折式前进,我们可以借用物理中的思路来对这个问题进行处理,我们都知道物体运动具有惯性,惯性本质的物理原因是物体具有动量。
简单理解就是,如果上一次的Momentum与这一次的负梯度方向相同,那么这一次下降的幅度就会加大进而达到加速收敛的效果
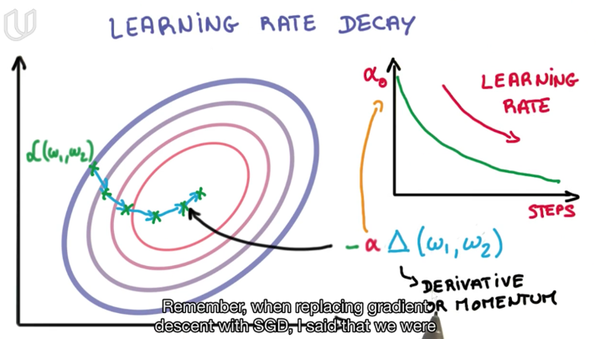
- 学习速率衰减(Learning Rate Decay)
在SGD中,一个是方向问题,另一个是步长问题,也就是学习率问题
具体做法就是每次迭代减小学习速率的大小
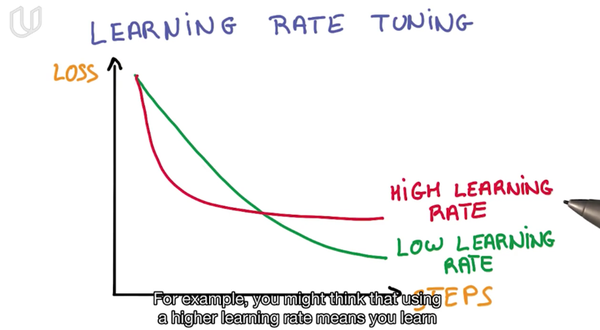
通过设置合适的学习率下降曲线,能够使模型收敛到更好的结果,但是一开始如果学习率过低就会使迭代太慢,所以随着迭代次数的增加再逐步降低,这样可以使得SGD的结果收敛的更好也保证了较快的收敛速度
- Adagrad
当训练达到了微调阶段时,不同的参数需要调整的幅度是不一样的,我们如果能为不同的参数分配不同的学习率,这样学习到的结果也会更优,Adagrad就是这样一种思路,通过自适应的为各个参数分配不同的学习率,实现更快更好的训练。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









