







搜索算法(篇一)
1. 局部搜索算法简介
局部搜索算法是一类可以有效解决优化问题的通用算法。它的基本原理是在临近解中迭代,使目标函数逐步优化,直至不能再优化为止。
局部搜索算法可以这样描述:假设问题的解空间表示为
S
, 局部搜索算法从一个初始解
局部搜索算法具有以下特点:
- 算法结构通用易实现。只要定义好具体问题相关的邻域,就能有效的求解该问题。
- 算法性能和邻域的定义以及初始状态有关。邻域定义的不同或初始状态选取的不同会对算法的性能产生决定性的影响。
- 算法的局部优化特性。算法容易陷入局部最优解,达到全局最优比较困难。
局部搜索算法主要包含五大要素:
- 目标函数:用来判断解的优劣。
- 邻域的定义:根据不同问题,有着不同的邻域定义。
- 初始解的产生规则
- 新解的产生和接受规则
- 算法终止准则
其中前两个要素的定义和算法要解决的特定问题有关,而且不同的人对同一问题可能有完全不同的定义。后三个要素定义的不同则会产生各种不同的局部搜索算法,而它们的效率和最终解的质量也会有很大的差异。
2.几种经典的局部搜索算法
爬山法
爬山法的主要特点是只接受比当前解好的或相等的解作为当前解,这里所谓解的好或者相等是根据问题的目标函数的值大小来判断的。爬山法解的产生一般是随机的。爬山法新解的产生规则可以是在当前解的邻域内随机选取或者选取最优的,而后者会比较耗时。
爬山法算法的终止准则一般有三种:
- a. 算法总的迭代次数达到一定数目
- b. 最优解没有更新的迭代次数达到一定数目
- c. 当前解的目标函数达到一定的值
爬山法的关键参数包括:
初始解的产生规则
初始解的产生规则一般有两种,一种是取一个随机的解作为初始解,另一种是随机产出一组解,取其中最优的那一个解作为初始解。但是两种方式都不能保证最终解的质量,不过一般来说采用第一种方式产生解的爬山法的运行时间比采用第二种方式长。
新解的产生和接受规则
新解产生的规则一般也有两种,一种是在当前解的邻域内随机产生一个新解,另一种是遍历当前的整个邻域,取邻域中的最优解作为新解。后一种新解产生的规则一般会产生质量较高的最优化解,但是整个算法的运行时间会很长
新解的接受规则一般是只接受比当前解更优的解,也可以只接受不比当前解质量差的解,这就是爬山法极容易陷入局部最优的根本原因
算法的终止准则
算法的终止准则并没有一个严格的限定,根据实际应用需求的不同,可以是以下三种之一:
- 设定一个算法的运行时间,算法在运行了这么长时间后停止
- 设定一个算法的迭代次数,算法迭代搜索了多少次后就停止
- 设定一个算法的最大不改善迭代次数,也就是说如果算法在这么多次的迭代搜索过程中都没有找到更优的解,算法就停止运行
模拟退火法
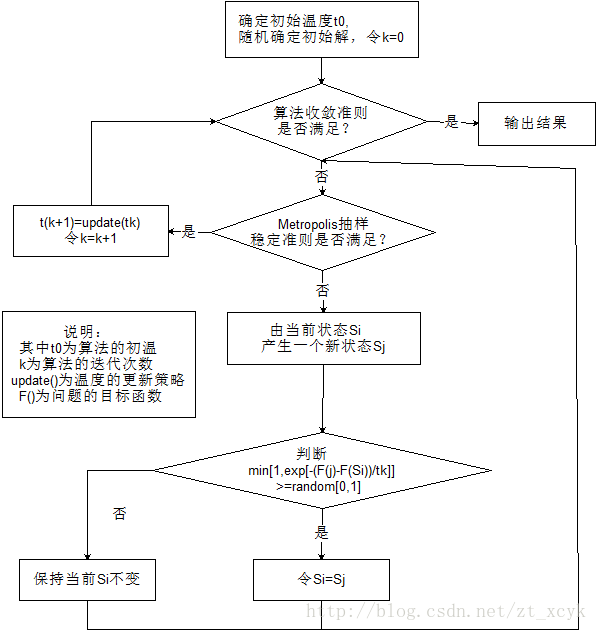
为了克服爬山法极容易陷入局部最优的缺点,所以提出了模拟退火算法的思想。模拟退火法是一个基于概率搜索的局部搜索算法,模拟退火算法从某一初始温度开始,伴随温度的不断下降,结合概率突跳特性在解空间内随机寻找目标函数的全局最优解,既可以从局部最优解中概率性的跳出并趋于全局最优解。
模拟退火算法的初始解也是随机产生,新解的产生规则可以是在当前解的邻域内随机选取。
新解的接受规则
- 如果新解
Sj 优于当前解 Si ,那么新解则成为当前解;- 如果新解 Sj 不如当前解 Si ,则先产生一个 [0,1] 之间的数,如果这个数小于等于 esp[−(f(Sj)−f(Si))/t] ,新解就成为当前解,反之则保持当前解不变。
公式里面的 t 是一个随着迭代过程不断变小的一个数,通常是在一定迭代次数m后,将
t 变小一点exp是以自然常数e为底的指数函数,全称Exponential(指数曲线)
公式的作用是一种概率分布,也就是是否选取该解的一个概率,随着算法个进行,概率也会变化
算法的终止准则
算法总的迭代次数达到一定数目
当前温度小于一定的值
当前解的目标函数达到一定的值
模拟退火算法的流程图如下:
从算法的结构可以看出,新状态的产生函数,新状态的接受函数,退温函数,抽样稳定准则和退火结束准则以及初始温度是直接影响算法优化结果和执行时间的主要环节。
模拟退火算法的优点是:由于它允许概率地接受恶化解,所以它不容易陷入局部最优,另外它的初值依赖性不强。但是,为了寻求最优解,算法通常要求较高的初温,较慢的降温速率,较低的终止温度以及各温度下足够多次的采样,因而模拟退火算法往往优化过程较长,这也是模拟退火算法的主要缺点。
模拟退火算法的关键参数:
新状态产生函数
设计状态产生函数的出发点应该是尽可能的保证产生的候选解遍布全部解空间。通常状态产生函数由两部分组成:产生新状态的方式和新状态产生的概率分布。前者决定当前状态产生候选状态的方式,和具体问题相关;后者决定当前状态产生的不同的新状态的概率。
新状态的接受函数
状态接受函数一般以概率地方式给出,不同接受函数的差别主要在于接受概率地形式不同。设计状态接受概率,应该遵循以下原则:
- 在固定温度下,接受优化解的概率大于接受恶劣解的概率
- 随温度的下降,接受恶劣解的概率要下降
- 当温度趋于零的时候,只能接受优化解
退温函数
即温度下降的方式,用于在每次抽样稳定准则后降温。一般最常用的温度更新函数为指数退温,即
tk+1=λtk, 其中 0<λ<1 且其大小可以不断变化抽样稳定准则
该准则用于决定在各温度下产生候选解的数目。常用的抽样稳定准则包括:
- 检验目标函数的均值是否稳定
- 连续若干步的目标值不变
- 按一定的步数抽样
退火结束准则
用于决定算法何时结束。设置温度终止 t <script type="math/tex" id="MathJax-Element-60">t</script>是一种简单的退火结束准则。通常退火结束准则包括:
- 设置终止温度的阈值
- 设置退温的次数
- 算法搜索到最优值若干步保持不变
禁忌搜索算法
禁忌搜索算法是通过一个灵活的存储结构和相应的禁忌准则来避免迂回搜索,并通过藐视准则来赦免一些被禁忌的优良状态,进而保证多样化的有效搜索以最终实现全局优化。
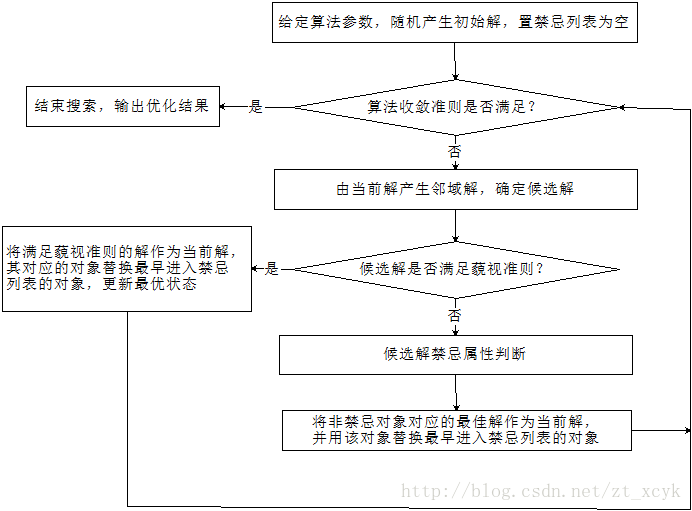
简单TS算法(禁忌搜索算法)的基本思想是:
- 给定一个初始解和一种邻域,然后在当前解的邻域中确定若干候选解
- 若最佳候选解对应的目标值优于迄今为止的最佳状态,则忽略其禁忌特性,用其替代当前解和迄今为止的最佳状态,并将其相应的对象加入禁忌列表,同时修改禁忌表中各对象的任期
- 若不存在上述候选解,则选择在候选解中非禁忌的最佳状态为新的当前解,而无视它与当前解的优劣,同时将相应的对象加入禁忌列表,并修改禁忌列表中各个对象的任期
如此反复上述迭代搜索过程,直至满足停止准则
- 上述算法可用如下流程框图更直观地描述
禁忌搜索是人工智能的一种体现,是一种结合了人工智能的局部搜索算法。禁忌搜索最重要的思想是标记对应已搜索到的局部最优解的一些对象,并在进一步的迭代搜索中尽量避开这些对象,从而保证对不同的有效搜索途径的搜索。禁忌搜索涉及到邻域(neighborhood),禁忌列表(tabu list),禁忌长度(tabu length),候选解(candidate),藐视准则(aspiration criterion)等关键概念。其中,邻域来自局部搜索的思想,用于搜索问题的解空间;禁忌列表的设置,体现了算法避免迂回搜索的特点;藐视准则,这是对优良状态的奖励,它是对禁忌策略的一种放松。 由于禁忌搜索算法具有灵活的记忆功能和藐视准则,并且在搜索过程中可以接受劣质解,所以具有较强的爬山能力,搜索时能够跳出局部最优解,转向解空间的其他区域,从而增强获得更好的全局最优解的概率,所以禁忌算法是一种局部搜索能力很强的全局迭代寻优算法。但是,禁忌搜索也有明显的不足,即对初始解有较强的依赖性,好的初始解可使禁忌搜索算法在解空间中搜索到好的解,而较差的初始解会降低禁忌搜索算法的收敛速度和最终解的质量。
禁忌搜索算法的关键参数:
适配值函数
一般可以用目标函数直接作为适配值函数,也可以用目标函数的一些变形作为适配值函数。若目标函数的计算比较困难或耗时较多,可采用反映问题目标的某些特征值作为适配值,从而改善算法的时间性能
禁忌对象
所谓禁忌对象就是被置入禁忌表中的那些变化元素,而禁忌的目的则是为了尽量避免迂回搜索而多搜寻一些有效的搜索路径。归纳而言,禁忌对象通常可选取状态本身或状态分量或适配值的变化等。一般而言,以状态本身为禁忌对象比状态分量或适配值为禁忌对象的禁忌范围要小,从而给予的搜索范围要大,容易造成计算时间的增加。然而,在禁忌长度和候选解集大小相同且较小的情况下,后两者也会因为禁忌范围过大而使搜索陷入局部最小。
禁忌长度
禁忌长度即禁忌对象在不考虑藐视准则的情况下不允许被选取的最大次数,对象只有在其任期为0的时候才能被解禁。禁忌长度的选取与问题特性,研究者的经验有关,它决定了算法的计算复杂度。一般禁忌长度的设定有两种方式:一种是静态的禁忌长度,也就是禁忌长度t是定长不变的,如将禁忌长度固定为某个数或者固定为与问题规模相关的一个量。另一种是禁忌长度动态变化,如根据搜索性能和问题特性设定禁忌长度的变化区间,而禁忌长度则 可按某种原则或公式在其区间中变化。当然,禁忌长度的区间大小也可随搜索性能的变化而动态变化。总体而言,禁忌长度的动态设置方式比静态方式具有更好的性能和鲁棒性。
候选解
候选解通常在当前状态的邻域中择优选取,但选取过多将造成较大的计算量,而选取过少则容易造成过早收敛。要做到在这个邻域中的择优往往需要大量的计算,因此可以确定性或随机性地在部分邻域中选取候选解,具体数据大小则可视问题特性和对算法的要求而定。
藐视准则
在禁忌搜索算法中,可能会出现候选解全部被禁忌,或者存在一个优于历史最优解的状态的禁忌候选解,此时藐视准则将使某些状态解禁,以实现更高效的性能优化。
下面列出藐视准则的常见方式:
基于适配值的准则:
全局形式: 若某个禁忌候选解的适配值优于历史最优状态,则解禁此候选解为当前状态和新的历史最优解状态;
区域形式: 将搜索空间分为若干子区域,若某个禁忌候选解的适配值优于它所在区域的历史最优状态,则解禁此候选解为当前状态和相应区域的历史最优状态;
基于搜索方向的准则:
若禁忌对象上次被禁忌时使得适配值有所改善,并且目前该禁忌对象对应的候选解的适配值优于当前解,则对该禁忌对象解禁;
基于最小错误的准则:
若所有的候选解均被禁忌,且不存在一个优于历史最优解的候选解,则对候选解中最佳的候选解进行解禁,以继续搜索过程;
终止准则:
和爬山法、模拟退火法一样,禁忌搜索算法也需要一个终止准则来结束算法的搜索过程,而严格实现理论上的收敛条件,即在禁忌长度充分大的条件下实现状态空间的遍历。着显然是不切合实际的。因此设计算法的时候通常采用近似的收敛准则。
常用方法如下:
- 给定最大迭代步数
- 设定某个对象的最大禁忌频率
- 设定适配值的偏离幅度
可变邻域搜索
- 如果新解















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









