




 博客详细介绍了Solr的SearchHandler在SolrCloud环境下的工作流程,包括主节点与从节点的交互、分布式执行引擎ShardHandler、请求分步处理等关键步骤,揭示了SolrCloud搜索的分步异步机制。
博客详细介绍了Solr的SearchHandler在SolrCloud环境下的工作流程,包括主节点与从节点的交互、分布式执行引擎ShardHandler、请求分步处理等关键步骤,揭示了SolrCloud搜索的分步异步机制。
由于SearchHandler过程比较复杂,基本每次用到都需要重新看一眼才能记忆,而且还比较容易记错。因此索引把写博文一来方便自己,二来方便别人。
当然,对Solr来讲SearchHandler并不复杂,而且十分简洁和清晰。不过,在SolrCloud下由于需要节点的协助,所以变得有些复杂。同时SolrCloud下的设计非常巧妙,非常值得细读和参考。
先看一眼Solr下SearchHandler流程。
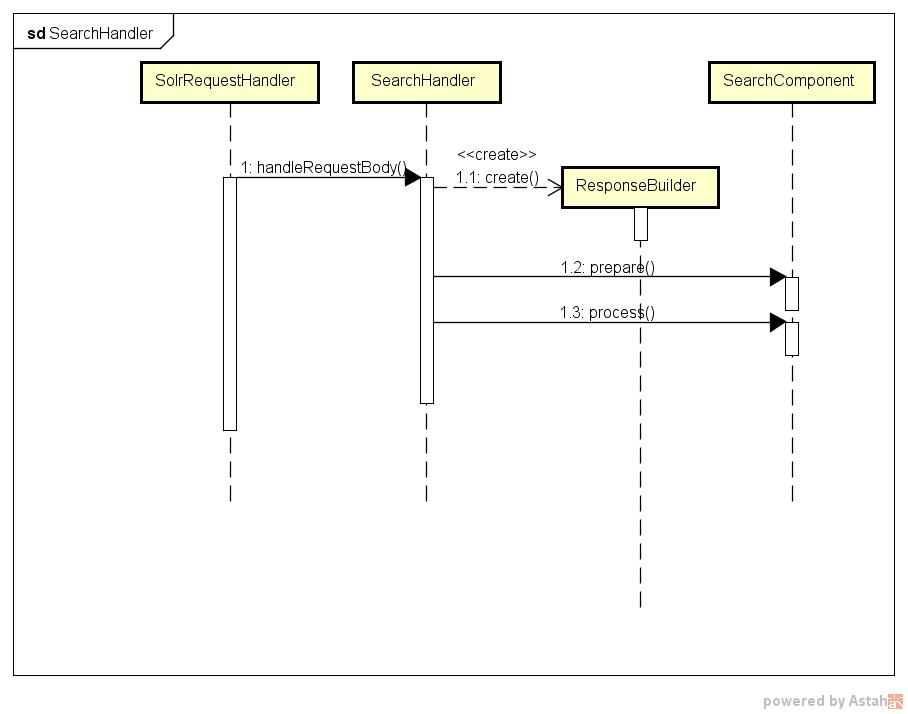
主干流程就是这样,比较清晰简单。当然后细节依然比较复杂,主要原因Solr在组织代码的时候并没有单机与分布式的逻辑分开来。也就是单机与分布式的代码是堆一起的,这只是其一;其次是因为处理搜索的处理器QueryComponent逻辑也非常复杂。对了解SearchHandler而言,我觉得上面的流程就可以。对于查询语法的解析,搜索逻辑以及搜索过程都出现QueryComponent中,另找机会介绍这一块,本文不详述这块内容。
SearchHandler#inform(SolrCore core) {
Object declaredComponents = initArgs.get(INIT_COMPONENTS);
List<String> first = (List<String>) initArgs.get(INIT_FIRST_COMPONEMTS);
List<String> last = (List<String>) initArgs.get(INIT_LAST_COMPONENTS);
// TODO 不堆代码了,主要目的是根据 Handler 的配置,构建 **components** 链。
// 顺序是 first - 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6520
6520

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









