







一摞烙饼问题其实是一个很有意思的问题,它的描述是让一摞随机顺序的烙饼通过单手翻转的方式进行排序,以达到这摞烙饼由小到大顺序放置在盘子上的目 的,其特点是每次翻转都会导致第一个烙饼到所要反转的那个烙饼之间的顺序变为逆序。我们的目的是求出次数最少的翻转方案以及翻转次数,很显然这是一个最优 化问题,我们本能想到的是动态规划、贪心以及分支限界三种方法。
书中给出的递归算法或称之为分支限界法(即遍历+剪枝=分支限界)秉承了递归算法传统的简单、明了,但效率偏低的特点。这个问题的实质,我们在每一次反转 之前其实是需要做出一种选择,这种选择必须能够导致全局最优解。递归算法就是递归的构建所有解(实际是一颗搜索树),并在遍历过程中不断刷新 LowerBound和UpperBound,以及当前的最优解(剪枝),并最终找到一个最整体优解。在这种策略下,提高算法的效率只能寄希望于剪枝方法 的改进。但是这种方法显然不是多项式时间的,有没有多项式时间的算法呢?
书中P22页提到动态规划,但最后却给出了解决最优化问题普遍适用但效率可能是最差的递归方法。这不禁让人疑惑:这也不美啊!?如果我们能证明该问题满足 动态规划或贪心算法的使用条件,解决问题的时间复杂度将会降到多项式时间甚至N^2。但书中提到动态规划却最终没有使用,又没有讲明原因,我觉得是一种疏 失(应该不算错误)。那我们就来想一下为什么没有动态规划或贪心算法的原因。
我们知道动态规划方法是一种自底向上的获取问题最优解的方法,它采用子问题的最优解来构造全局最优解。利用动态规划求解的问题需要满足两个条件:即(1) 最优子结构(2)子结构具有重叠性。条件(1)使我们可以利用子问题的最优解来构造全局最优解,而条件(2)是我们在计算过程中可以利用子结构的重叠性来 减少运算次数。此外,《算法导论》上还以有向图的无权最短路径和无权最长路径为例提出条件(3)子问题必须独立。
首先我们假定烙饼问题存在优化子结构。假如我们有N个烙饼,把他们以其半径由小到大进行编号。优化子结构告诉我们对于i个烙饼,我们只需要先排列前(i- 1)个,然后再将第i个归位;或先排列第2到i个,最后将第一个归位;又或是找到一个位置k[i<=k<j]像矩阵乘法加括号那样,使得我们 先排列前k个,再排列后j-k个,最后再将二者合并,以找到一个最佳翻转策略等等...
根据动态规划算法的计算过程,我们需要一个N*N矩阵M,其中M[i][j]表示将编号i至编号j的烙饼排序所需要的翻转次数。但我们真的能从M[0] [0..j-1]和M[1][j+1],或与M[i][j]同行同列的值来计算M[i][j]吗?如果能,我们就能获得多项式时间的算法。
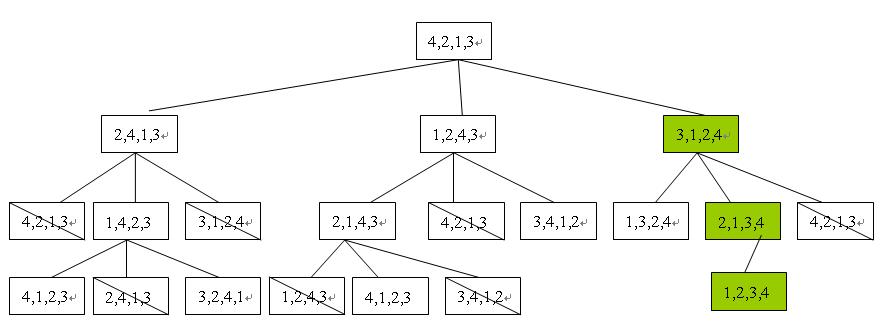
我们来看书中给出的例子:(顶端)3,2,1,6,5,4,9,8,7,0(底端),我们最终的目标是计算M[0][9]。
这里我们以计算M[0][4]为例,计算的矩阵我已经在下面给出:
0 1 2 3 4 5 6 7 8 9
------------------------
0|0 1 (1){1}[?]
1| 0 1 (1){1}
2| 0 1 (1)
3| 0 0
4| 0
------------------
实际上如果我们要向将0-4号烙饼(注意:烙饼编号也等同于其半径)排为正序(中间有其他烙饼也没关系),按照程序给出的结果, 我们需要进行3次翻转,分别为[2,5,9](即分别翻转队列中第二(从零开始)、五、九个烙饼,这里的数字不是烙饼的编号):
[1] [2] [3] 6 5 [4] 9 8 7 [0]
[4] 5 6 [3] [2] [1] 9 8 7 [0]
[0] 7 8 9 [1] [2] [3] 6 5 [4]
我们知道,该矩阵中每一个数的背后都隐含着一个烙饼的排列,例如M[0][4]就应该对应0,7,8,9,1,2,3,6,5,4
所以,每一个M[i][j]的选取都蕴含着其子排列的顺序的变化。
在计算M[i][j]的时候,我们需要计算i-j号饼的全部划分(不包括全部为1的划分)所能构成的翻转结构,并取其翻转 次数最少的哪一个最为M[i][j]的最终值。例如,我们在计算M[0][4]的时候,需要查看:
/**先将0和1-4号分别排序,最后将二者合并为有序所需要的翻转次数*/
M[0][0],M[1][4]
/** 同上 */
M[0][1],M[2][4]
/** 同上 */
M[0][2],M[3][4]
/** 同上 */
M[0][3],M[4][4]
/* 先将0、1、2、3-4号分别排序,最后将4者合并为有序所需要的翻转次数.
* 注意这里又包含将4个分组再次进行划分的问题!
*/
M[0][0],M[1][1],M[2][2],M[3][4]
.....//中间略
M[0][3],M[4][4]
如果再加上运算过程中我们可以淘汰超过最大反转次数的方案(剪枝?),我们完成全部的运算,所经历的运算过程的时间复杂度已经不是多项式时间的,而是和先前所说的递归方法已没什么两样。
造成这种现象的原因是:某个子问题的最优解不一定是整体的最优解,所以我们在处理整个问题的时候,需要遍历所有可能的子问题,并计算它到整体问题所消耗的代价,才能最终作出有利于整体问题的选择。
所以我们一开始的假设,即烙饼问题有优化子结构的假设是错误的。因此我们不能用动态规划,同理也不能用贪心算法。
但说到每一步的“选择”问题,我记得算法导论上有一个叫做“A*”的算法,它的思想是在进行每一步选择的时候都“推算”最终可能需要的代价,并选择当前代价最小的分支进行遍历。这个“推算”的结果可能不会是最终的代价,而只是作为分支选择的依据。
我 们已经知道,关于一摞烙饼的排序问题我们可以采用递归的方式来完成。其间我们要做的是尽量调整UpperBound和LowerBound,已减少运算次 数。对于这种方法,在算法课中我们应该称之为:Tree Searching Strategy。即整个解空间为一棵搜索树,我们按照一定的策略遍历解空间,并寻找最优解。一旦找到比当前最优解更好的解,就用它替换当前最优解,并用 它来进行“剪枝”操作来加速求解过程。














 612
612











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









