







一、背景介绍
Apache Hadoop:Apache Hadoop是一款支持数据密集型分布式应用并以Apache 2.0许可协议发布的开源软件框架。它支持在商品硬件构建的大型集群上运行的应用程序。Hadoop是根据Google公司发表的MapReduce和Google档案系统的论文自行制作而成。称为社区版Hadoop。
第三方发行版Hadoop:Hadoop遵从Apache开源协议,用户可以免费地任意使用和修改Hadoop,也正因此,市面上出现了很多Hadoop版本。其中有很多厂家在Apache Hadoop的基础上开发自己的Hadoop产品,比如Cloudera的CDH,Hortonworks的HDP,MapR的MapR产品等。
二、社区版本与第三方发行版本的比较
Apache社区版本
优点:
- 完全开源免费。
- 社区活跃
- 文档、资料详实
缺点:
- 复杂的版本管理。版本管理比较混乱的,各种版本层出不穷,让很多使用者不知所措。
- 复杂的集群部署、安装、配置。通常按照集群需要编写大量的配置文件,分发到每一台节点上,容易出错,效率低下。
- 复杂的集群运维。对集群的监控,运维,需要安装第三方的其他软件,如ganglia,nagois等,运维难度较大。
- 复杂的生态环境。在Hadoop生态圈中,组件的选择、使用,比如Hive,Mahout,Sqoop,Flume,Spark,Oozie等等,需要大量考虑兼容性的问题,版本是否兼容,组件是否有冲突,编译是否能通过等。经常会浪费大量的时间去编译组件,解决版本冲突问题。
第三方发行版本(如CDH,HDP,MapR等)
优点:
- 基于Apache协议,100%开源。
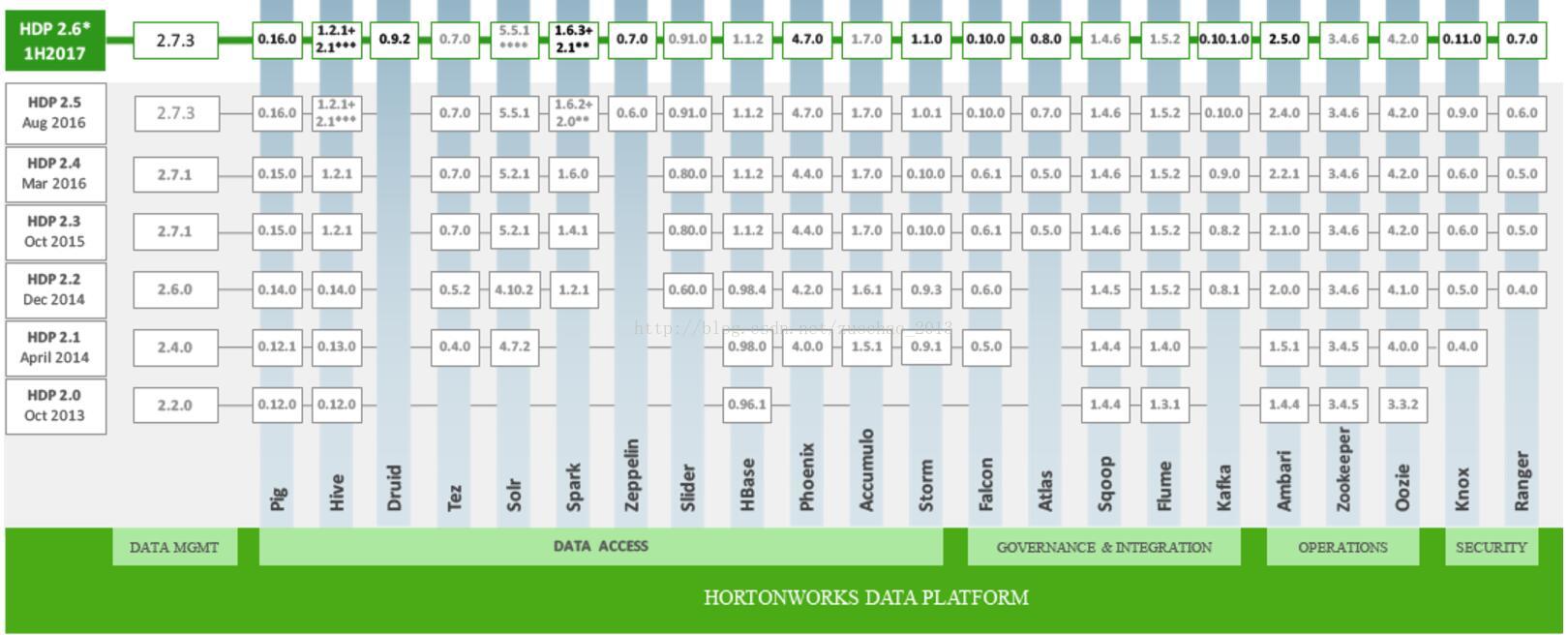
- 版本管理清晰。比如Cloudera,CDH1,CDH2,CDH3,CDH4等,后面加上补丁版本,如CDH4.1.0 patch level 923.142,表示在原生态Apache Hadoop 0.20.2基础上添加了1065个patch。
- 比Apache Hadoop在兼容性、安全性、稳定性上有增强。第三方发行版通常都经过了大量的测试验证,有众多部署实例,大量的运行到各种生产环境。
- 版本更新快。通常情况,比如CDH每个季度会有一个update,每一年会有一个release。
- 基于稳定版本Apache Hadoop,并应用了最新Bug修复或Feature的patch
- 提供了部署、安装、配置工具,大大提高了集群部署的效率,可以在几个小时内部署好集群。
- 运维简单。提供了管理、监控、诊断、配置修改的工具,管理配置方便,定位问题快速、准确,使运维工作简单,有效。
缺点:
- 涉及到厂商锁定的问题。(可以通过技术解决)
三、第三方发行版本的比较
Cloudera:最成型的发行版本,拥有最多的部署案例。提供强大的部署、管理和监控工具。Cloudera开发并贡献了可实时处理大数据的Impala项目。
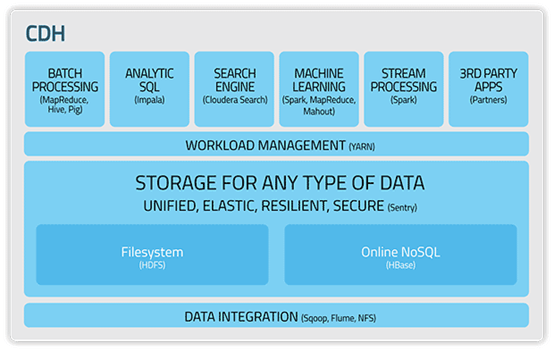
Hortonworks:不拥有任何私有(非开源)修改地使用了100%开源Apache Hadoop的唯一提供商。Hortonworks是第一家使用了Apache HCatalog的元数据服务特性的提供商。并且,它们的Stinger开创性地极大地优化了Hive项目。Hortonworks为入门提供了一个非常好的,易于使用的沙盒。Hortonworks开发了很多增强特性并提交至核心主干,这使得Apache Hadoop能够在包括Windows Server和Windows Azure在内Microsft Windows平台上本地运行。

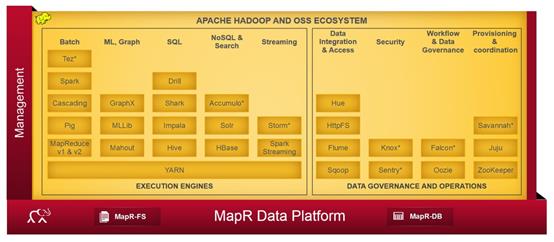
MapR:与竞争者相比,它使用了一些不同的概念,特别是为了获取更好的性能和易用性而支持本地Unix文件系统而不是HDFS(使用非开源的组件)。可以使用本地Unix命令来代替Hadoop命令。除此之外,MapR还凭借诸如快照、镜像或有状态的故障恢复之类的高可用性特性来与其他竞争者相区别。该公司也领导着Apache Drill项目,本项目是Google的Dremel的开源项目的重新实现,目的是在Hadoop数据上执行类似SQL的查询以提供实时处理。
Amazon Elastic Map Reduce(EMR):区别于其他提供商的是,这是一个托管的解决方案,其运行在由Amazon Elastic Compute Cloud(Amazon EC2)和Amzon Simple Strorage Service(Amzon S3)组成的网络规模的基础设施之上。除了Amazon的发行版本之外,你也可以在EMR上使用MapR。临时集群是主要的使用情形。如果你需要一次性的或不常见的大数据处理,EMR可能会为你节省大笔开支。然而,这也存在不利之处。其只包含了Hadoop生态系统中Pig和Hive项目,在默认情况下不包含其他很多项目。并且,EMR是高度优化成与S3中的数据一起工作的,这种方式会有较高的延时并且不会定位位于你的计算节点上的数据。所以处于EMR上的文件IO相比于你自己的Hadoop集群或你的私有EC2集群来说会慢很多,并有更大的延时。
四、选择决定
当我们决定是否采用某个软件用于开源环境时,通常需要考虑以下几个因素:
(1)是否为开源软件,即是否免费。
(2) 是否有稳定版,这个一般软件官方网站会给出说明。
(3) 是否经实践验证,这个可通过检查是否有一些大点的公司已经在生产环境中使用知道。
(4) 是否有强大的社区支持,当出现一个问题时,能够通过社区、论坛等网络资源快速获取解决方法。
综上所述,考虑到大数据平台高效的部署和安装,中心化的配置管理,使用过程中的稳定性、兼容性、扩展性,以及未来较为简单、高效的运维,遇到问题低廉的解决成本。
个人建议使用第三方发行版本。
五、大数据展望
技术篇
2006年项目成立的一开始,“Hadoop”这个单词只代表了两个组件——HDFS和MapReduce。到现在的10个年头,这个单词代表的是“核心”(即Core Hadoop项目)以及与之相关的一个不断成长的生态系统。这个和Linux非常类似,都是由一个核心和一个生态系统组成。
现在Hadoop在一月发布了2.7.2的稳定版, 已经从传统的Hadoop三驾马车HDFS,MapReduce和HBase社区发展为60多个相关组件组成的庞大生态,其中包含在各大发行版中的组件就有25个以上,包括数据存储、执行引擎、编程和数据访问框架等。
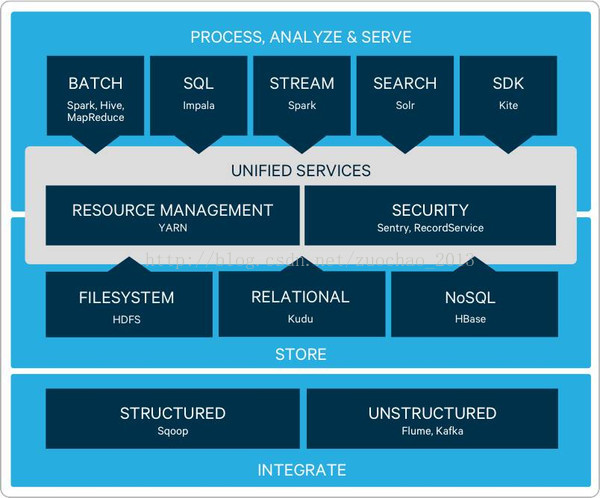
Hadoop在2.0将资源管理从MapReduce中独立出来变成通用框架后,就从1.0的三层结构演变为了现在的四层架构:
底层——存储层,文件系统HDFS
中间层——资源及数据管理层,YARN以及Sentry等
上层——MapReduce、Impala、Spark等计算引擎
顶层——基于MapReduce、Spark等计算引擎的高级封装及工具,如Hive、Pig、Mahout等等
存储层
HDFS已经成为了大数据磁盘存储的事实标准,用于海量日志类大文件的在线存储。经过这些年的发展,HDFS的架构和功能基本固化,像HA、异构存储、本地数据短路访问等重要特性已经实现,在路线图中除了Erasure Code已经没什么让人兴奋的feature。
随着HDFS越来越稳定,社区的活跃度也越来越低,同时HDFS的使用场景也变得成熟和固定,而上层会有越来越多的文件格式封装:列式存储的文件格式,如Parquent,很好的解决了现有BI类数据分析场景;以后还会出现新的存储格式来适应更多的应用场景,如数组存储来服务机器学习类应用等。未来HDFS会继续扩展对于新兴存储介质和服务器架构的支持。
2015年HBase 发布了1.0版本,这也代表着 HBase 走向了稳定。最新HBase新增特性包括:更加清晰的接口定义,多Region 副本以支持高可用读,Family粒度的Flush以及RPC读写队列分离等。未来HBase不会再添加大的新功能,而将会更多的在稳定性和性能方面进化,尤其是大内存支持、内存GC效率等。
Kudu是Cloudera在2015年10月才对外公布的新的分布式存储架构,与HDFS完全独立。其实现参考了2012年Google发表的Spanner论文。鉴于Spanner在Google 内部的巨大成功,Kudu被誉为下一代分析平台的重要组成,用于处理快速数据的查询和分析,填补HDFS和HBase之间的空白。其出现将进一步把Hadoop市场向传统数据仓库市场靠拢。
Apache Arrow项目为列式内存存储的处理和交互提供了规范。目前来自Apache Hadoop社区的开发者们致力于将它制定为大数据系统项目的事实性标准。
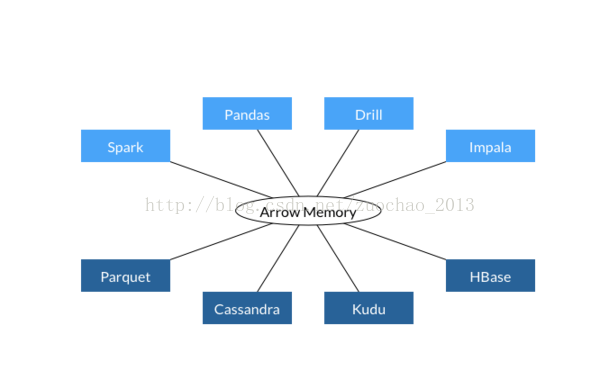
Arrow项目受到了Cloudera、Databricks等多个大数据巨头公司支持,很多committer同时也是其他明星大数据项目(如HBase、Spark、Kudu等)的核心开发人员。再考虑到Tachyon等似乎还没有找到太多实际接地气的应用场景,Arrow的高调出场可能会成为未来新的内存分析文件接口标准。
管控层
管控又分为数据管控和资源管控。
随着Hadoop集群规模的增大以及对外服务的扩展,如何有效可靠的共享利用资源是管控层需要解决的问题。脱胎于MapReduce1.0的YARN成为了Hadoop 2.0通用资源管理平台。由于占据了Hadoop的地利,业界对其在资源管理领域未来的前景非常看好。
传统其他资源管理框架如Mesos,还有现在兴起的Docker等都会对YARN未来的发展产生影响。如何提高YARN性能、如何与容器技术深度融合,如何更好的适应短任务的调度,如何更完整的多租户支持、如何细粒度的资源管控等都是企业实际生产中迫在眉睫的需求,需要YARN解决。要让Hadoop走得更远,未来YARN需要做的工作还很多。
另一方面大数据的安全和隐私越来越多的受到关注。Hadoop依靠且仅依靠Kerberos来实现安全机制,但每一个组件都将进行自己的验证和授权策略。开源社区似乎从来不真正关心安全问题,如果不使用来自Hortonworks的Ranger或来自Cloudera 的Sentry这样的组件,那么大数据平台基本上谈不上安全可靠。
Cloudera刚推出的RecordService组件使得Sentry在安全竞赛中拔得先机。RecordService不仅提供了跨所有组件一致的安全颗粒度,而且提供了基于Record的底层抽象(有点像Spring,代替了原来Kite SDK的作用),让上层的应用和下层存储解耦合的同时、提供了跨组件的可复用数据模型。
计算引擎层
Hadoop生态和其他生态最大的不同之一就是“单一平台多种应用”的理念了。传的数据库底层只有一个引擎,只处理关系型应用,所以是“单一平台单一应用”;而NoSQL市场有上百个NoSQL软件,每一个都针对不同的应用场景且完全独立,因此是“多平台多应用”的模式。而Hadoop在底层共用一份HDFS存储,上层有很多个组件分别服务多种应用场景,如:
-
确定性数据分析:主要是简单的数据统计任务,例如OLAP,关注快速响应,实现组件有Impala等;
-
探索性数据分析:主要是信息关联性发现任务,例如搜索,关注非结构化全量信息收集,实现组件有Search等;
-
预测性数据分析:主要是机器学习类任务,例如逻辑回归等,关注计算模型的先进性和计算能力,实现组件有Spark、MapReduce等;
-
数据处理及转化:主要是ETL类任务,例如数据管道等,关注IO吞吐率和可靠性,实现组件有MapReduce等
-
…
其中,最耀眼的就是Spark了。IBM宣布培养100万名Spark开发人员,Cloudera在One Platform倡议中宣布支持Spark为Hadoop的缺省通用任务执行引擎,加上Hortonworks全力支持Spark,我们相信Spark将会是未来大数据分析的核心。
虽然Spark很快,但现在在生产环境中仍然不尽人意,无论扩展性、稳定性、管理性等方面都需要进一步增强。同时,Spark在流处理领域能力有限,如果要实现亚秒级或大容量的数据获取或处理需要其他流处理产品。Cloudera宣布旨在让Spark流数据技术适用于80%的使用场合,就考虑到了这一缺陷。我们确实看到实时分析(而非简单数据过滤或分发)场景中,很多以前使用S4或Storm等流式处理引擎的实现已经逐渐Kafka+Spark Streaming代替。
Spark的流行将逐渐让MapReduce、Tez走进博物馆。
服务层
服务层是包装底层引擎的编程API细节,对业务人员提供更高抽象的访问模型,如Pig、Hive等。
而其中最炙手可热的就是OLAP的SQL市场了。现在,Spark有70%的访问量来自于SparkSQL!SQL on Hadoop到底哪家强?Hive、Facebook的Pheonix、Presto、SparkSQL、Cloudera推的Impala、MapR推的Drill、IBM的BigSQL、还是Pivital开源的HAWQ?
这也许是碎片化最严重的地方了,从技术上讲几乎每个组件都有特定的应用场景,从生态上讲各个厂家都有自己的宠爱,因此Hadoop上SQL引擎已经不仅仅是技术上的博弈(也因此考虑到本篇中立性,此处不做评论)。可以遇见的是,未来所有的SQL工具都将被整合,有些产品已经在竞争钟逐渐落伍,我们期待市场的选择。
周边的工具更是百花齐放,最重要的莫过于可视化、任务管理和数据管理了。
有很多开源工具都支持基于Hadoop 的查询程序编写以及即时的图形化表示,如HUE、Zeppelin等。用户可以编写一些SQL或Spark代码以及描述代码的一些标记,并指定可视化的模版,执行后保存起来,就可供其他人复用,这钟模式也被叫做“敏捷BI”。这个领域的商业产品更是竞争激烈,如Tableau、Qlik等。
调度类工具的鼻祖Oozie能实现几个MapReduce任务串连运行的场景,后来的Nifi及Kettle等其他工具则提供了更加强大的调度实现,值得一试。
毫无疑问,相对与传统的数据库生态,Hadoop的数据治理相对简单。Atlas是Hortonworks新的数据治理工具,虽然还谈不上完全成熟,不过正取得进展。Cloudera的Navigator是Cloudera商业版本的核心,汇聚了生命周期管理、数据溯源、安全、审计、SQL迁移工具等一系列功能。Cloudera收购Explain.io以后将其产品整合为Navigator Optimizator组件,能帮助用户把传统的SQL应用迁移到Hadoop平台并提供优化建议,可以节省数人月的工作量。
算法及机器学习
实现基于机器学习的自动的智能化数据价值挖掘是大数据和Hadoop最诱人的愿景了,也是很多企业对大数据平台的最终期望。随着可获得的数据越来越多,未来大数据平台的价值更多的取决于其计算人工智能的程度。
现在机器学习正慢慢跨出象牙塔,从一个少部分学术界人士研究的科技课题变成很多企业正在验证使用的数据分析工具,而且已经越来越多的进入我们的日常生活。
机器学习的开源项目除了之前的Mahout、MLlib、Oryx等,今年发生了很多令人瞩目的大事,迎来了数个明星巨头的重磅加入:
2015年1月,Facebook开源前沿深度学习工具“Torch”。
2015年4月,亚马逊启动其机器学习平台Amazon Machine Learning,这是一项全面的托管服务,让开发者能够轻松使用历史数据开发并部署预测模型。
2015年11月,谷歌开源其机器学习平台TensorFlow。
同一月,IBM开源SystemML并成为Apache官方孵化项目。
同时,微软亚洲研究院将分布式机器学习工具DMTK通过Github开源。DMTK由一个服务于分布式机器学习的框架和一组分布式机器学习算法组成,可将机器学习算法应用到大数据中。
2015年12月,Facebook开源针对神经网络研究的服务器“Big Sur”,配有高性能图形处理单元(GPUs),转为深度学习方向设计的芯片。
产业篇
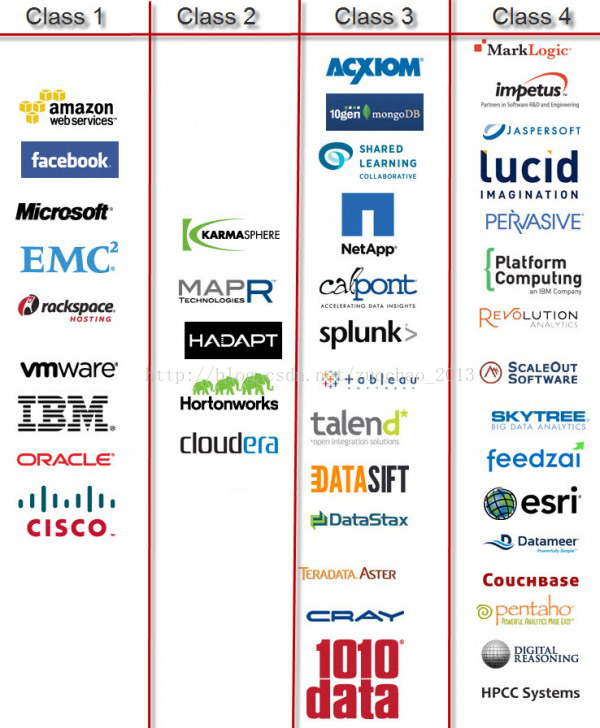
现在使用Hadoop的企业以及靠Hadoop赚钱的企业已经成千上万。几乎大的企业或多或少的已经使用或者计划尝试使用Hadoop技术。就对Hadoop定位和使用不同,可以将Hadoop业界公司划分为四类:
第一梯队:这类公司已经将Hadoop当作大数据战略武器。
第二梯队:这类公司将Hadoop 产品化。
第三梯队:这类公司创造对Hadoop整体生态系统产生附加价值的产品。
第四梯队:这类公司消费Hadoop,并给规模比第一类和第二类小的公司提供基于Hadoop的服务。
时至今日,Hadoop虽然在技术上已经得到验证、认可甚至已经到了成熟期。其中最能代表Hadoop发展轨迹的莫过于商业公司推出的Hadoop发行版了。自从2008年Cloudera成为第一个Hadoop商业化公司,并在2009年推出第一个Hadoop发行版后,很多大公司也加入了做Hadoop产品化的行列。
“发行版”这个词是开源文化特有的符号,看起来任何一个公司只要将开源代码打个包,再多多少少加个佐料就能有一个“发行版”,然而背后是对海量生态系统组件的价值筛选、兼容和集成保证以及支撑服务。
2012年以前的发行版基本为对Hadoop打补丁为主,出现了好几个私有化Hadoop版本,所折射的是Hadoop产品在质量上的缺陷。同期HDFS、HBase等社区的超高活跃度印证了这个事实。
而之后的公司更多是工具、集成、管理,所提供的不是“更好的Hadoop”而是如何更好的用好“现有”的Hadoop。
2014年以后,随着Spark和其他OLAP产品的兴起,折射出来是Hadoop善长的离线场景等已经能够很好的解决,希望通过扩大生态来适应新的硬件和拓展新的市场。
Cloudera提出了Hybrid Open Source的架构:核心组件名称叫CDH(Cloudera's Distribution including Apache Hadoop),开源免费并与Apache社区同步,用户无限制使用,保证Hadoop基本功能持续可用,不会被厂家绑定;数据治理和系统管理组件闭源且需要商业许可,支持客户可以更好更方便的使用Hadoop技术,如部署安全策略等。Cloudera也在商业组件部分提供在企业生产环境中运行Hadoop所必需的运维功能,而这些功能并不被开源社区所覆盖,如无宕机滚动升级、异步灾备等。
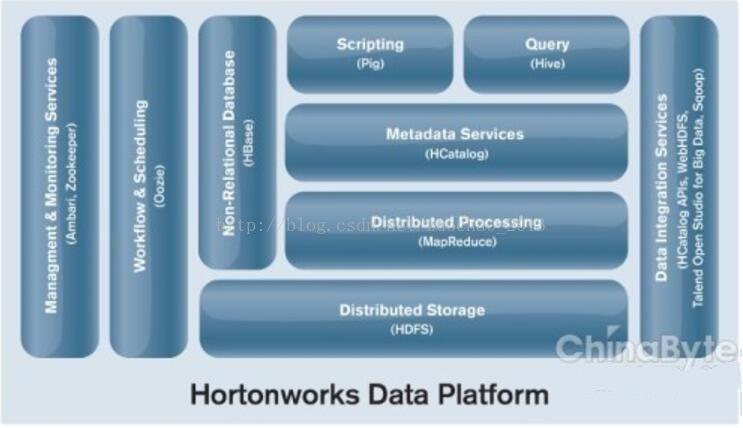
Hortonworks采用了100%完全开源策略,产品名称为HDP(Hortonworks Data Platform)。所有软件产品开源,用户免费使用,Hortonworks提供商业的技术支持服务。与CDH相比,管理软件使用开源Ambari,数据治理使用Atlas,安全组件使用Ranger而非Sentry,SQL继续紧抱Hive大腿。
MapR采用了传统软件厂商的模式,使用私有化的实现。用户购买软件许可后才能使用。其OLAP产品主推Drill,又不排斥Impala。
现在主流的公有云如AWS、Azure等都已经在原有提供虚拟机的IaaS服务之外,提供基于Hadoop的PaaS云计算服务。未来这块市场的发展将超过私有Hadoop部署。
应用篇
Hadoop平台释放了前所未有的计算能力,同时大大降低了计算成本。底层核心基础架构生产力的发展,必然带来的是大数据应用层的迅速建立。
对于Hadoop上的应用大致可以分为这两类:
IT优化
将已经实现的应用和业务搬迁到Hadoop平台,以获得更多的数据、更好的性能或更低的成本。通过提高产出比、降低生产和维护成本等方式为企业带来好处。
这几年Hadoop在数个此类应用场景中已经被证明是非常适合的解决方案,包括:
历史日志数据在线查询:传统的解决方案将数据存放在昂贵的关系型数据库中,不仅成本高、效率低,而且无法满足在线服务时高并发的访问量。以HBase为底层存储和查询引擎的架构非常适合有固定场景(非ad hoc)的查询需求,如航班查询、个人交易记录查询等等。现在已经成为在线查询应用的标准方案,中国移动在企业技术指导意见中明确指明使用HBase技术来实现所有分公司的清账单查询业务。
ETL任务:不少厂商已经提供了非常优秀的ETL产品和解决方案,并在市场中得到了广泛的应用。然而在大数据的场景中,传统ETL遇到了性能和QoS保证上的严重挑战。多数ETL任务是轻计算重IO类型的,而传统的IT硬件方案,如承载数据库的小型计算机,都是为计算类任务设计的,即使使用了最新的网络技术,IO也顶多到达几十GB。
采用分布式架构的Hadoop提供了完美的解决方案,不仅使用share-nothing的scale-out架构提供了能线性扩展的无限IO,保证了ETL任务的效率,同时框架已经提供负载均衡、自动FailOver等特性保证了任务执行的可靠性和可用性。
数据仓库offload:传统数据仓库中有很多离线的批量数据处理业务,如日报表、月报表等,占用了大量的硬件资源。而这些任务通常又是Hadoop所善长的
经常被问到的一个问题就是,Hadoop是否可以代替数据仓库,或者说企业是否可以使用免费的Hadoop来避免采购昂贵的数据仓库产品。数据库界的泰斗Mike Stonebroker在一次技术交流中说:数据仓库和Hadoop所针对的场景重合型非常高,未来这两个市场一定会合并。
我们相信在数据仓库市场Hadoop会迟早替代到现在的产品,只不过,那时候的Hadoop已经又不是现在的样子了。就现在来讲,Hadoop还只是数据仓库产品的一个补充,和数据仓库一起构建混搭架构为上层应用联合提供服务。
业务优化
在Hadoop上实现原来尚未实现的算法、应用,从原有的生产线中孵化出新的产品和业务,创造新的价值。通过新业务为企业带来新的市场和客户,从而增加企业收入。
Hadoop提供了强大的计算能力,专业大数据应用已经在几乎任何垂直领域都很出色,从银行业(反欺诈、征信等)、医疗保健(特别是在基因组学和药物研究),到零售业、服务业(个性化服务、智能服务,如UBer的自动派车功能等)。
在企业内部,各种工具已经出现,以帮助企业用户操作核心功能。例如,大数据通过大量的内部和外部的数据,实时更新数据,可以帮助销售和市场营销弄清楚哪些客户最有可能购买。客户服务应用可以帮助个性化服务; HR应用程序可帮助找出如何吸引和留住最优秀的员工等。
为什么Hadoop如此成功?这个问题似乎是个马后炮,但当我们今天惊叹于Hadoop在短短10年时间取得如此统治性地位的时候,确实会自然而然地思考为什么这一切会发生。基于与同期其他项目的比较,我们认为有很多因素的综合作用造就了这一奇迹:
技术架构:Hadoop推崇的本地化计算理念,其实现在可扩展性、可靠性上的优势,以及有弹性的多层级架构等都是领先其他产品而获得成功的内在因素。没有其他任何一个这样复杂的系统能快速的满足不断变化的用户需求。
硬件发展:摩尔定律为代表的scale up架构遇到了技术瓶颈,不断增加的计算需求迫使软件技术不得不转到分布式方向寻找解决方案。同时,PC服务器技术的发展使得像Hadoop这样使用廉价节点组群的技术变为可行,同时还具有很诱人的性价比优势。
工程验证:Google发表GFS和MapReduce论文时已经在内部有了可观的部署和实际的应用,而Hadoop在推向业界之前已经在Yahoo等互联网公司验证了工程上的可靠性和可用性,极大的增加了业界信心,从而迅速被接纳流行。而大量的部署实例又促进了Hadoop的发展喝成熟。
社区推动:Hadoop生态一直坚持开源开放,友好的Apache许可基本消除了厂商和用户的进入门槛,从而构建了有史以来最大最多样化最活跃的开发者社区,持续地推动着技术发展,让Hadoop超越了很多以前和同期的项目。
关注底层:Hadoop 的根基是打造一个分布式计算框架,让应用程序开发人员更容易的工作。业界持续推动的重点一直在不断夯实底层,并在诸如资源管理和安全领域等领域不断开花结果,为企业生产环境部署不断扫清障碍。
下一代分析平台
过去的十年中Apache Hadoop社区以疯狂的速度发展,现在俨然已经是事实上的大数据平台标准。但仍有更多的工作要做!大数据应用未来的价值在于预测,而预测的核心是分析。下一代的分析平台会是什么样呢?它必定会面临、同时也必须要解决以下的问题:
更多更快的数据。
更新的硬件特性及架构。
更高级的分析。
更安全。
因此,未来的几年,我们会继续见证“后Hadoop时代”的下一代企业大数据平台:
内存计算时代的来临。随着高级分析和实时应用的增长,对处理能力提出了更高的要求,数据处理重点从IO重新回到CPU。以内存计算为核心的Spark将代替以IO吞吐为核心的MapReduce成为分布式大数据处理的缺省通用引擎。做为既支持批处理有支持准实时流处理的通用引擎,Spark将能满足80%以上的应用场景。
然而,Spark毕竟核心还是批处理,擅长迭代式的计算,但并不能满足所有的应用场景。其他为特殊应用场景设计的工具会对其补充,包括:
a) OLAP。OLAP,尤其是聚合类的在线统计分析应用,对于数据的存储、组织和处理都和单纯离线批处理应用有很大不同。
b) 知识发现。与传统应用解决已知问题不同,大数据的价值在于发现并解决未知问题。因此,要最大限度地发挥分析人员的智能,将数据检索变为数据探索。
统一数据访问管理。现在的数据访问由于数据存储的格式不同、位置不同,用户需要使用不同的接口、模型甚至语言。同时,不同的数据存储粒度都带来了在安全控制、管理治理上的诸多挑战。未来的趋势是将底层部署运维细节和上层业务开发进行隔离,因此,平台需要系统如下的功能保证:
a) 安全。能够大数据平台上实现和传统数据管理系统中相同口径的数据管理安全策略,包括跨组件和工具的一体化的用户权利管理、细粒度访问控制、加解密和审计。
b) 统一数据模型。通过抽象定义的数据描述,不仅可以统一管理数据模型、复用数据解析代码,还可以对于上层处理屏蔽底层存储的细节,从而实现开发/处理与运维/部署的解偶。
简化实时应用。现在用户不仅关心如何实时的收集数据,而且关心同时尽快的实现数据可见和分析结果上线。无论是以前的delta架构还是现在lambda架构等,都希望能够有一种解决快速数据的方案。Cloudera最新公开的Kudu虽然还没有进入产品发布,但却是现在解决这个问题可能的最佳方案:采用了使用单一平台简化了快速数据的“存取用”实现,是未来日志类数据分析的新的解决方案。
翘首展望,下一个十年
10年以后的Hadoop应该只是一个生态和标准的“代名词”了,下层的存储层不只是HDFS、HBase和Kudu等现有的存储架构,上层的处理组件更会像app store里的应用一样多,任何第三方都可以根据Hadoop的数据访问和计算通信协议开发出自己的组件,用户在市场中根据自己数据的使用特性和计算需求选择相应的组件自动部署。
当然,有一些明显的趋势必然影响着Hadoop的前进:
-
云计算
现在50%的大数据任务已经运行在云端,在3年以后这个比例可能会上升到80%。Hadoop在公有云的发展要求更加有保障的本地化支持。
-
硬件
快速硬件的进步会迫使社区重新审视Hadoop的根基,Hadoop社区绝不会袖手旁观。
-
物联网
物联网的发展会带来海量的、分布的和分散的数据源。Hadoop将适应这种发展。
以后的十年会发生什么?以下是笔者的一些猜想:
SQL和NoSQL市场会合并,NewSQL和Hadoop技术相互借鉴而最终走向统一,Hadoop市场和数据仓库市场会合并,然而产品碎片化会继续存在。
Hadoop与其他资源管理技术和云平台集成,融合docker和unikernal等技术统一资源调度管理,提供完整多租户和QoS能力,企业数据分析中心合并为单一架构。
企业大数据产品场景化。以后直接提供产品和技术的公司趋于成熟并且转向服务。越来越多的新公司提供的是行业化、场景化的解决方案,如个人网络征信套件以及服务。
大数据平台的场景“分裂”。与现在谈及大数据言必称Hadoop以及某某框架不同,未来的数据平台将根据不同量级的数据(从几十TB到ZB)、不同的应用场景(各种专属应用集群)出现细分的阶梯型的解决方案和产品,甚至出现定制化一体化产品。
大数据的明天是美好的,未来Hadoop一定是企业软件的必备技能,希望我们能一起见证。
转载出处 http://blog.csdn.net/shifenglov/article/details/40376105














 142
142











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









