







昨天复习了冒泡,选择和插入这三种算法是比较简单的排序算法,今天来学点更加常用的算法。
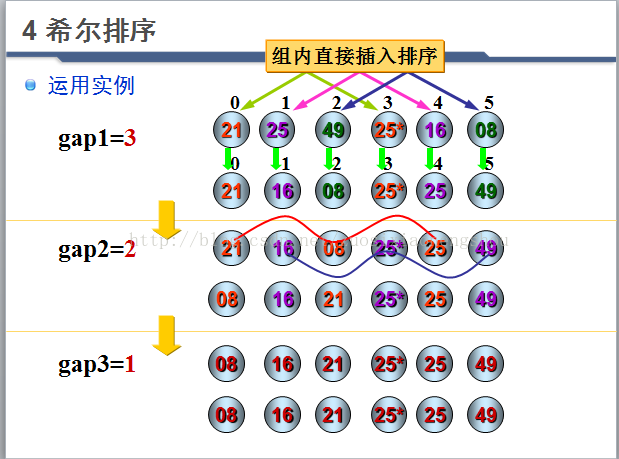
4 希尔排序
希尔排序又称缩小增量排序,是1959年由D.L.Shell提出来的。
算法描述
算法实现:
package cn.hncu.sortAlgorithm;
public class SortMethods2 {
public static void main(String[] args) {
int a[]={5,8,-3,11,7,28,95,-12,8,-55,5};//9个数
//4.希尔排序
shellSort(a);
}
//4 希尔排序---为了便于理解,组内排序算法用冒泡
private static void shellSort(int[] a) {
//分组
for(int gap=(a.length+1)/2;gap>0;){
//组队排序---冒泡
for(int i=0;i<a.length-gap;i++){
for(int j=i;j<a.length-gap;j++){
if(a[j]>a[j+gap]) swap(a,j,j+gap);
}
}
//循环变量的修正
if(gap>1)
gap=(gap+1)/2;
else
break;
}
}算法分析
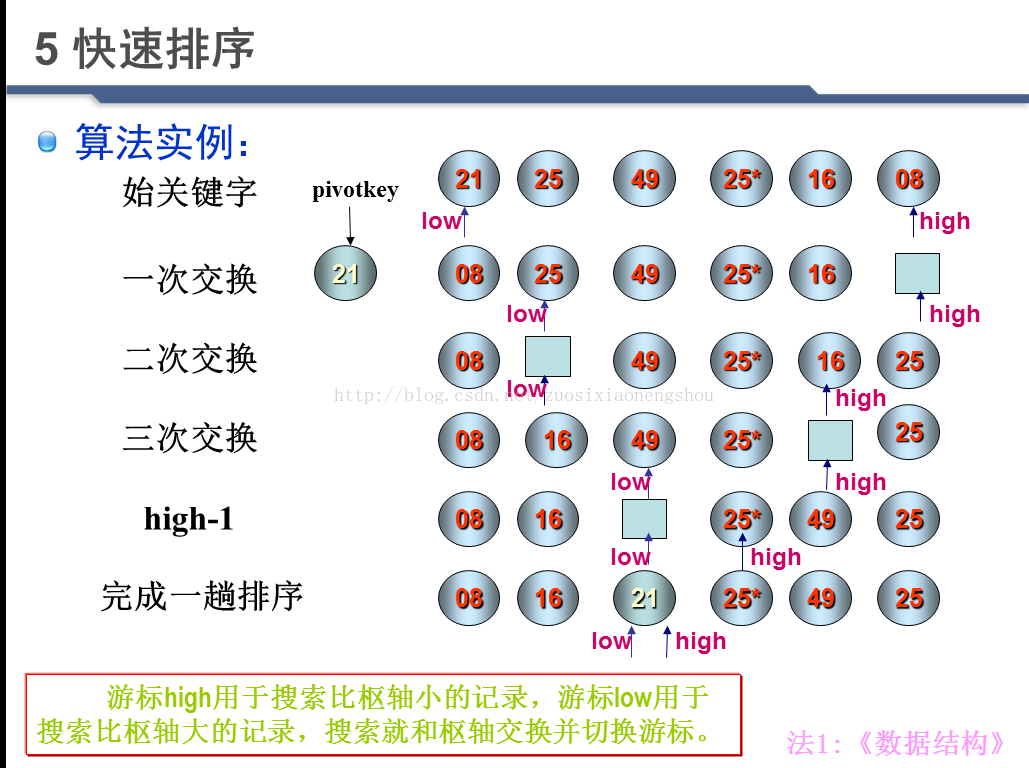
5 快速排序
算法特点:
①一部分: 所有记录的关键字大于等于支点记录的关键字
②另一部分: 所有记录的关键字小于支点记录的关键字
算法描述:
基准记录也称为枢轴(或支点)记录。取序列第一个记录为枢轴记录,其关键字为Pivotkey。指针low指向序列第一个记录位置,指针high指向序列最后一个记录位置。
算法实现
//5. 快速排序
//5.1 普通快速排序
//quickSort(a,0,a.length-1);// 把数组a内0~a.length-1范围内元素 进行排序
private static void quickSort(int[] a, int p, int r) {
if(p<r){
//思路:把数组a划分成两个子数组和一个中间元素q: a[p:q-1], a[q], a[q+1,r]
int q=patition(a,p,r); //经过该函数划分,数组就变成 a[p:q-1], a[q], a[q+1,r]---其中a[q]位置已经排好
quickSort(a,p,q-1);//继续排左区间
quickSort(a,q+1,r);//继续排右区间
}
}
private static int patition(int[] a, int p, int r) {
int i=p;
int j=r+1;
int x=a[p];//枢轴保存在变量x中
while(true){
while(a[++i]<x&&i<r);//这个循环之后,a[i]就是左区中一个大于x的元素
while(a[--j]>x); //这个循环之后,a[j]就是右区中一个小于x的元素
if(i>=j) break;
swap(a,i,j); //把a[i]和a[j]交换一下
}
//把枢轴(目前在第p的位置)交换到 j 的位置
swap(a,p,j);
return j;
}
实现方式2
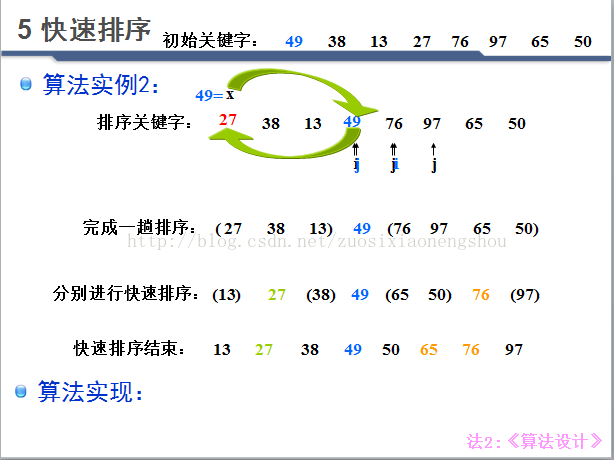
算法分析:
最好情况(每次总是选到中间值作枢轴)T(n)=O(nlogn)
最坏情况(每次总是选到最小或最大元素作枢轴)T(n)=O(n²)
最坏情况:S(n)=O(n)
一般情况:S(n)=O(logn)
5 快速排序 优化
可以证明,快速排序算法在平均情况下的时间复杂性和最好情况下一样,也是O(nlogn),这在基于比较的算法类中算是快速的,快速排序也因此而得名。
快速排序算法的性能取决于划分的对称性。因此通过修改partition( )方法,可以设计出采用随机选择策略的快速排序算法,从而使期望划分更对称,更低概率出现最坏情况。
算法实现:
//5.2 优化后的快速排序
quickSort2(a,0,a.length-1);
private static void quickSort2(int[] a, int p, int r) {
if(p<r){
int q=patition2(a,p,r); //经过该函数划分,数组就变成 a[p:q-1], a[q], a[q+1,r]---其中a[q]位置已经排好
quickSort2(a,p,q-1);//继续排左区间
quickSort2(a,q+1,r);//继续排右区间
}
}
private static int patition2(int[] a, int p, int r) {
//优化:采用随机选取策略确定枢轴
int rand=p+(int)(Math.random()*(r-p));
if(rand!=p) swap(a,p,rand);// 把rand位置的元素换到p位置,然后把p位置当做枢轴
int i=p;
int j=r+1;
int x=a[p];
while(true){
while(a[++i]<x&& i<r);
while(a[--j]>x);
if(i>=j) break;
swap(a,i,j);
}
swap(a,p,j);
return j;
}6 归并排序
算法描述
归并:将两个或两个以上的有序表组合成一个新的有序表。
2-路归并排序

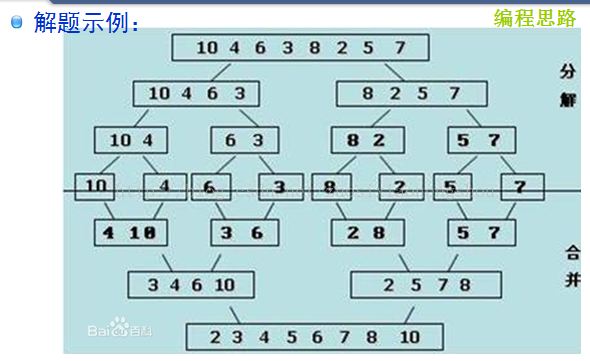
算法实现
//6. 归并排序
mergeSort(a,0,a.length-1);
private static void mergeSort(int[] a, int left, int right) {
if(left<right){ //至少要有两个元素才会分解,----如果没有这句,会出现栈溢出错误: StackOverflowError
//先分解
int mid=(left+right)/2;//二分
mergeSort(a,left,mid);
mergeSort(a,mid+1,right);
//再合并
int[] b=new int[a.length];
merge(a,b,left,mid,right);// 把当前分解层次的两个子序列合并到数组b对应的位置
copyArray(a,b,left,right); //把辅助序列b中的数据拷回a中
}
}
private static void copyArray(int[] a, int[] b, int left, int right) {
for(int i=left;i<=right;i++){
a[i]=b[i];
}
}
//归并:把两个子序列合并成一个
private static void merge(int[] a, int[] b, int left, int mid, int right) {
//合并a[left,mid]和a[mid+1,right] 到 b[left,right]中
int p=left; //遍历子序列a[left,mid]的游标
int r=mid+1; //遍历子序列a[mid+1,right]的游标
int k=left; //合并结果b[left,right]的游标
while(p<=mid && r<=right){
if(a[p]<a[r])
b[k++]=a[p++];
else
b[k++]=a[r++];
}
//经过上面的循环,至少其中一个序列已经排完,那么另外一个子序列剩下的元素直接搬到b中即可
if(p>mid) //左序列排完,照搬右序列
for(int i=r;i<=right;i++)
b[k++]=a[r++];
else //右序列排完,照搬左序列
for(int i=p;i<=mid;i++)
b[k++]=a[p++];
// while(true) {
// if(r>right) break;
// b[k++]=a[r++];
// }
// while(true) {
// if(p>mid) break;
// b[k++]=a[p++];
// }
}算法分析:
合并排序法主要是将两笔已排序的资料合并和进行排序。
如果所读入的资料尚未排序,可以先利用其它的排序方式来处理这两笔资料,然后再将排序好的这两笔资料合并。
T(n)=O(nlogn)
S(n)=O(n)
当然了这些算法也是亲测可用的啦。

排序算法小结

总体而言,排序方式之间没有绝对的好坏,视具体的解题场景而定。如,数据量很小时,用快排不如冒泡效率高。当序列中的大部分数据已经有序时,用插入排序方式也会优于快排。
另外,如果数据分别存储在不同的序列且各子序列本身是有序的,则可以直接利用归并排序中的merge()就可合成有序的完整序列。
总算是给把排序算法复习完了,这三种算法确实有点难理解。!!!∑(゚Д゚ノ)ノ 为了弄懂不知道死了多少脑细胞和多少个日日夜夜。haha














 260
260











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









