









![常规的神经网络:
神经网络有一个输入,这个输入通常是一个向量,通过一系列的隐层转换为输出。这里的每个隐层都有一系列的神经元-neurons组成,每个neurons都与前一层所有的neurons相连接,而且这些神经元之间是独立的,并不共享连接。最后一层的全连接层称之为输出层,这个输出层代表了类别的得分。例如在cifar-10中,图像是32*32*3的格式,也就是图像宽高为32,32,3通道;这样一幅小小的图像在常规的全连接神经网络中将产生32*32*3=3072个权重,可是如果是200*200*3的图像哪,甚至更大,这样的情况下参数更多,可见 全连接是非常wasteful的,这么多的参数也会导致过拟合。]
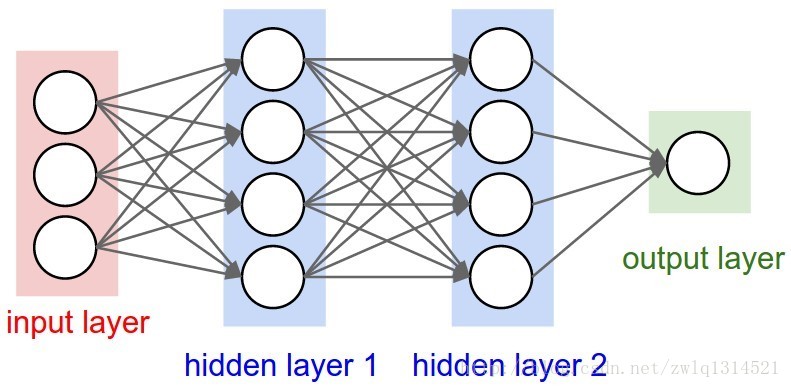
常规的神经网络:神经网络有一个输入,这个输入通常是一个向量,通过一系列的隐层转换为输出。这里的每个隐层都有一系列的神经元-neurons组成,每个neurons都与前一层所有的neurons相连接,而且这些神经元之间是独立的,并不共享连接。最后一层的全连接层称之为输出层,这个输出层代表了类别的得分。例如在cifar-10中,图像是32*32*3的格式,也就是图像宽高为32,32,3通道;这样一幅小小的图像在常规的全连接神经网络中将产生32*32*3=3072个权重,可是如果是200*200*3的图像哪,甚至更大,这样的情况下参数更多,可见 全连接是非常wasteful的,这么多的参数也会导致过拟合。
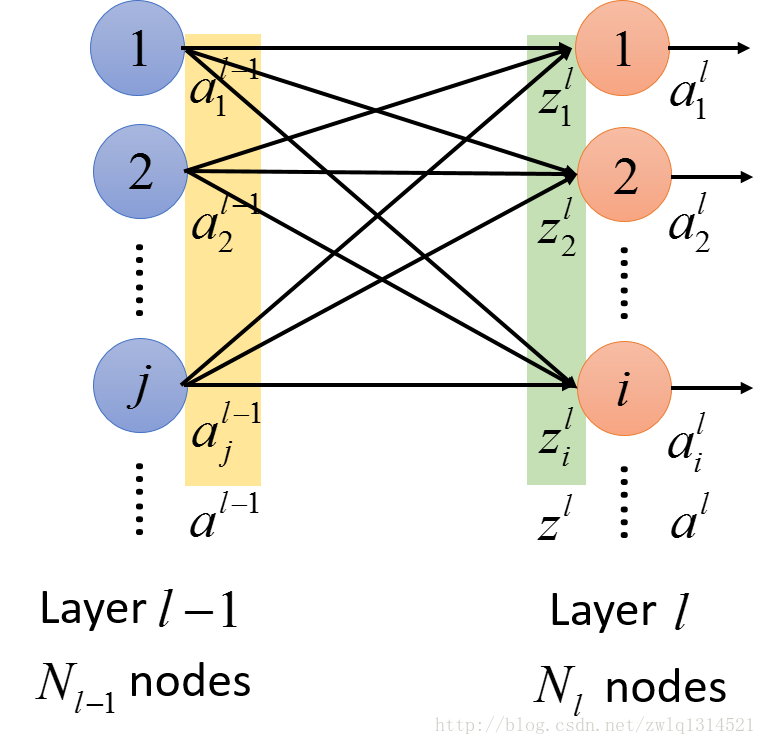
看图2
ali
表示第l层的第i个神经元的输出值;
wlij
表示从l-1层到l层连接过程中,l-1层的j神经元到l层的i神经元的权重。
zli
表示l层的第i个神经元的激活函数的输入
zl
表示l层的所有神经元的集合函数的输入
得到
zli=wli1∗al−11+wli2∗al−22...+bli
考虑整个网络,再回头看看图2,可以得到
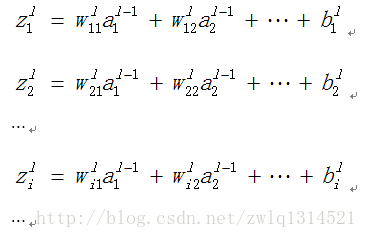
把上面这些式子写成矩阵的形式,可以得到
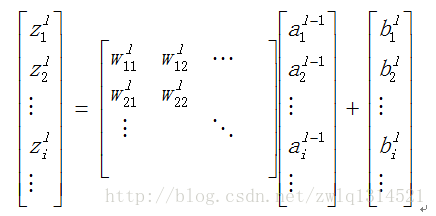
,再 进一步~
zl=wl∗al−1+bl
由此 CNN 诞生
CNN基本步骤:

具体说:
• 假设输入一副[32x32x3] 的图像, width 32, height 32, 3通道R,G,B.彩色图
• CONV layer 负责计算输入的一些局部连接的神经元作为下层神经元的输出。each computing a dot product between their weights and a small region they are connected to in the input volume. This may result in volume such as [32x32x12] if we decided to use 12 filters.
• RELU layer 使用激活函数, 例如 (max(0,x)) 。This leaves the size of the volume unchanged ([32x32x12]).
• POOL layer 进行下采样操作。resulting in volume such as [16x16x12].
• FC (i.e. fully-connected) layer 计算类别得分resulting in volume of size [1x1x10], where each of the 10 numbers correspond to a class score, such as among the 10 categories of CIFAR-10.
CNN只考虑局部的部分神经元的连接性 :
稀疏连接或者称局部连接:
每个神经元只与部分前一层的输出相连接,这个概念来源于生物学
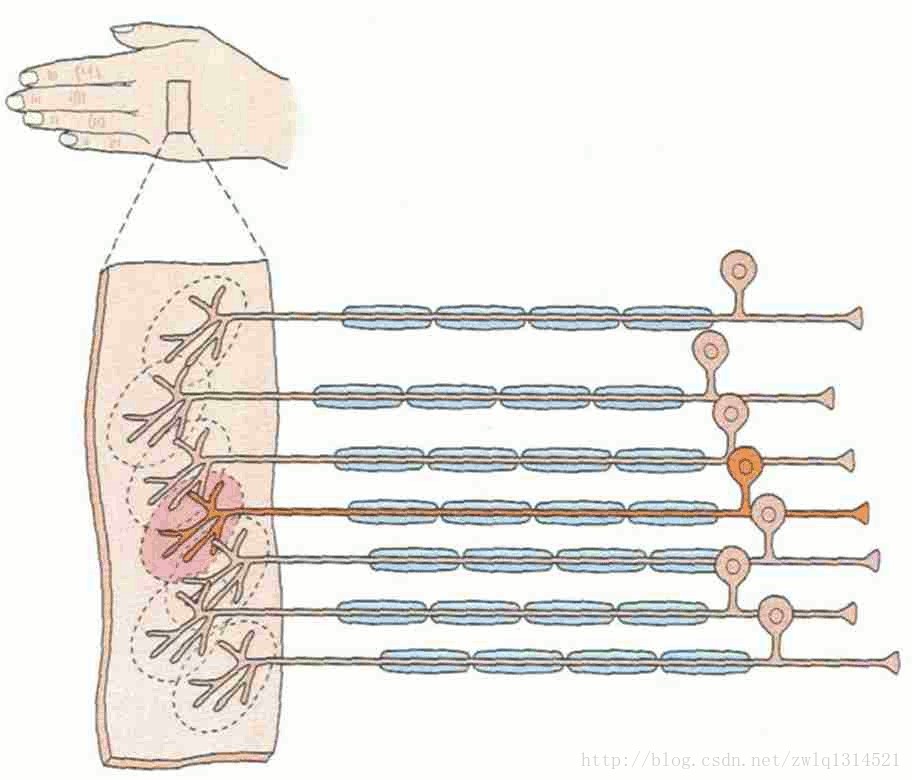
我们看看图4,右边每条神经(长长的)只与附近的几个神经元(虚线小圆圈圈出)相连接。我们的CNN局部连接也是这样
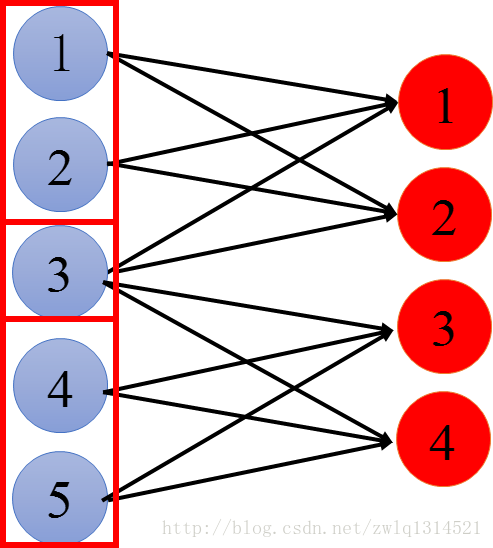
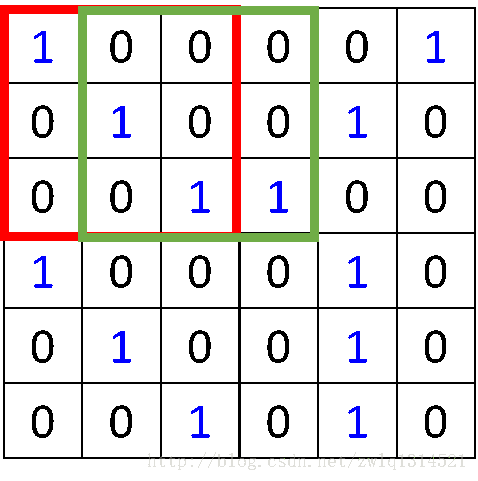
看这个图,输出红圈1与蓝圈123连接,红圈2与蓝圈123连接,红圈3与蓝圈345连接,红圈4与蓝圈345连接。
Cs231n课程这样写道:
Local Connectivity. When dealing with high-dimensional inputs such as images, as we saw above it is impractical to connect neurons to all neurons in the previous volume. Instead, we will connect each neuron to only a local region of the input volume. The spatial extent of this connectivity is a hyperparameter called the receptive field of the neuron (equivalently this is the filter size). The extent of the connectivity along the depth axis is always equal to the depth of the input volume. It is important to emphasize again this asymmetry in how we treat the spatial dimensions (width and height) and the depth dimension: The connections are local in space (along width and height), but always full along the entire depth of the input volume.
从图像识别的角度来讲,在一副图像中我检测到了鸟嘴,我还检测到爪子和尾巴,那么我就可以猜测这可能是一只鸟,而不需要去看到一整副图像。当然这也是有风险的。

参数共享(Parameter Sharing)
不同感受野的神经元可以共用一组权值
Parameter sharing scheme is used in Convolutional Layers to control the number of parameters.
参数共享基于这样一个合理的假设:That if one feature is useful to compute at some spatial position (x,y), then it should also be useful to compute at a different position (x2,y2)
以不同颜色来区分。输出1和3连接箭头均是红,黄,浅黄,表示输出1和3享用同一组参数,输出2和4连接箭头颜色分别是青绿蓝,表示输出2和4享用同一组参数
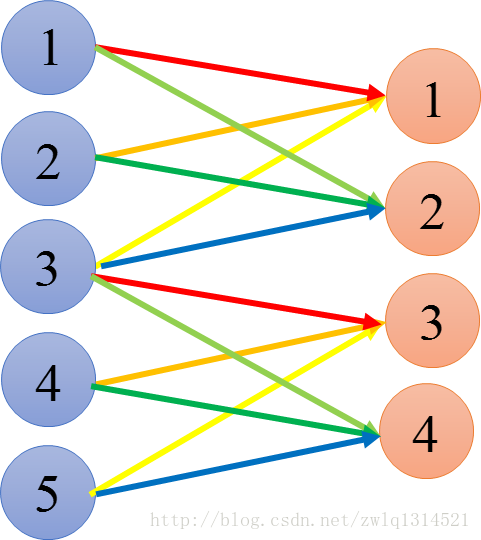
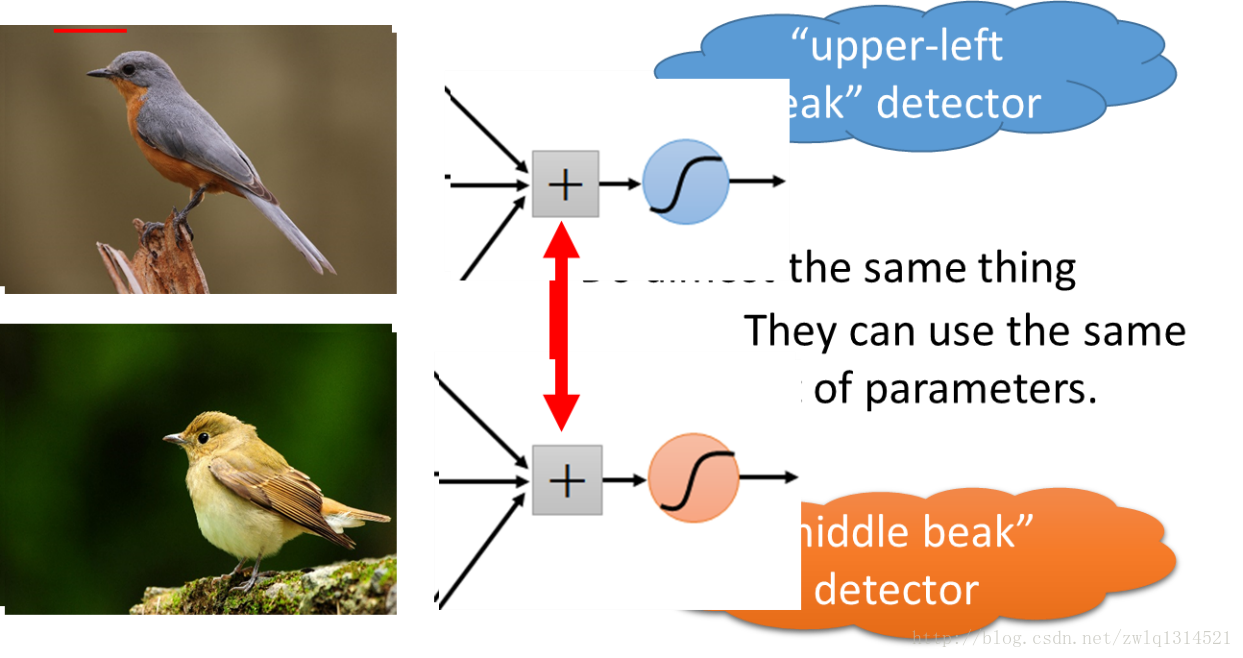
引到图像识别上:在两张图片中我都检测到鸟嘴,那么对于鸟嘴这种特征,我不需要利用不同的特征表示来描述,我可以用一种特征形式,也就是同一组特征参数形式来表示。这就是参数共享,说明CNN的参数共享是可行的,合理的。
学到这里,我会不由自主想起卷积操作,因为它也是局部和共享。以一副小二值图像的卷积操作为例,会更形象的表述:
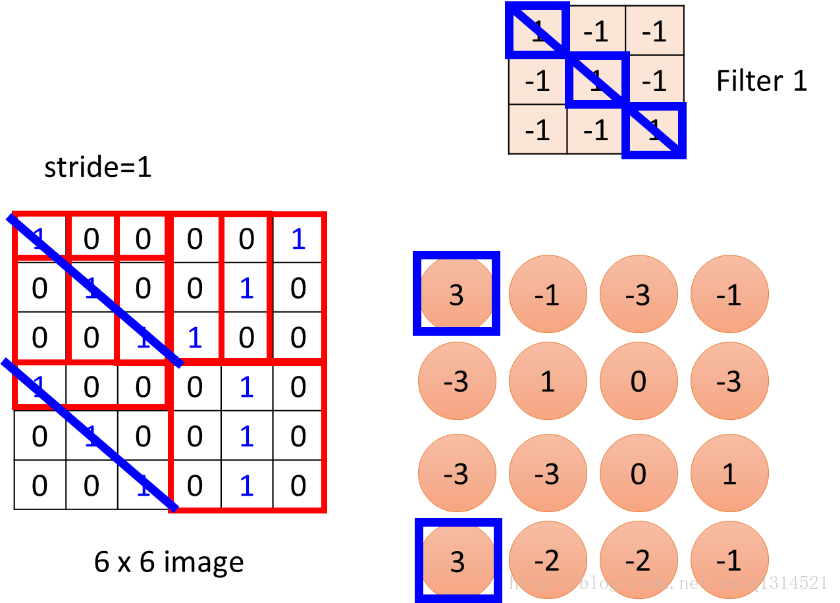
图5是一副6*6的图像,我想对这个图像进行3*3的滤波操作,就是拿一个3*3的九宫格模板一步一步的遍历这幅图像
为什么说卷积是可以提取特征的呐?看下面这张图,我以右上角的3*3模板去遍历左下角的6*6的图像,获得右下角4*4的结果,,在这个4*4的结果图中看到两个值为3的点,这两个点对应左边图两个对角线为1,1,1的3*3小领域图像块,这里,通过卷积提取的特征就是对角为1,1,1的图像特征,这就是一种特征提取,这就是卷积来提取特征的意义。
池化:
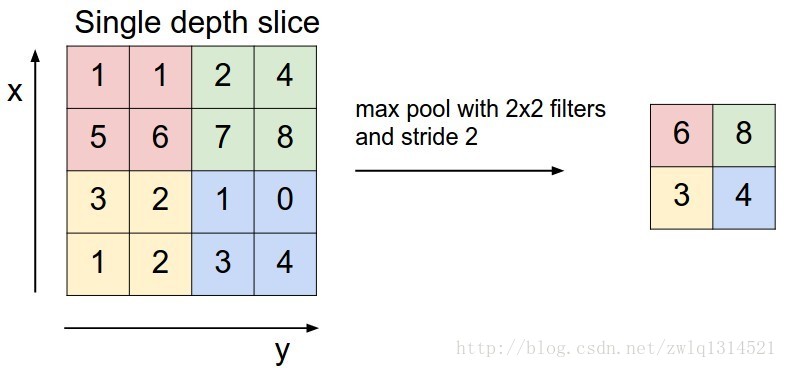
池化有最大值池化和均值池化,还有L2-norm池化,实践中最大值池化效果好些。
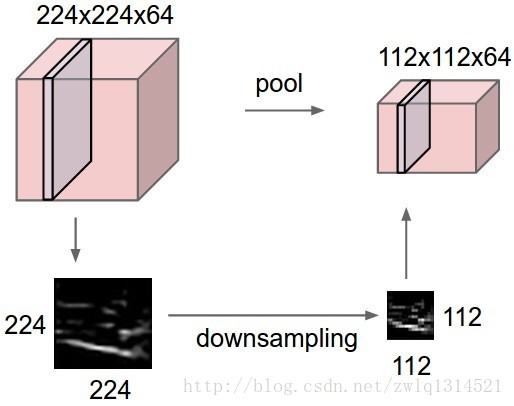
池化层会进行下采样操作,左边一副224*224*64的图像,经下采样后变为112*112*64,注意,深度(64)是保留的。下边的图示为最大值池化,经过2*2的滤波器,步长为2,每一步的滤波将4个参数变为一个最大值。
![这里写图片描述]
![这里写图片描述]
从图像识别的角度来说,下采样像素并不会改变物体,但是却让神经网络的参数变少了。计算复杂度降低了。















 3006
3006











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









