







Linear Regression
在学习李航《统计学习方法》的逻辑斯特回归时,正好coursera上相应的线性回归和逻辑斯特回归都学习完成,在此就一起进行总结,其中图片多来自coursera课程上。
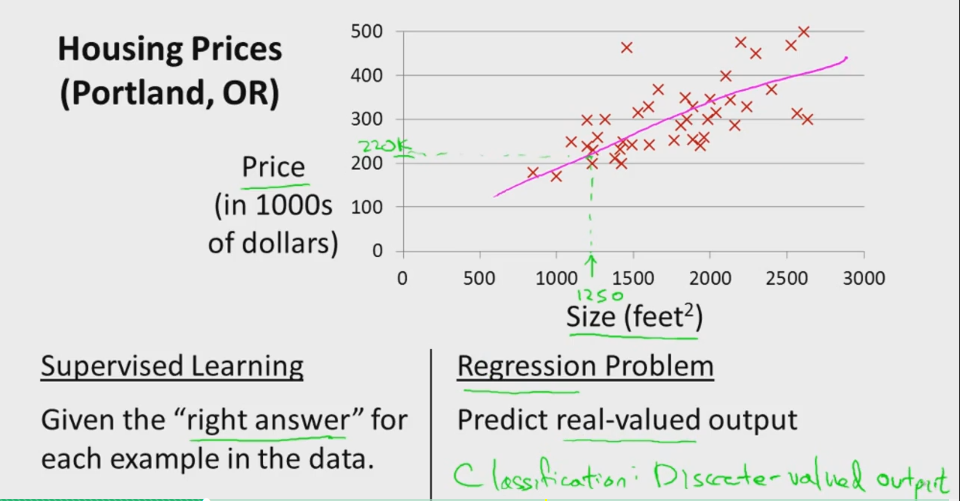
线性回归是机器学习中很好理解的一种算法。我们以常见的房屋销售为例来进行简单分析:
假设我们统计的一个房屋销售的数据如下:

在此,我们从单一变量谈起,直观上比较容易理解。训练集定义为 {
(x(1),y(1)),(x(2),y(2)),…,(x(m),y(m))} ,其中 x 是输入特征,
假设空间
实际线性回归假设能够拟合各种不同的曲线,实际的房子价格可能与房间面积、房间厅室、房间朝向等多个变量有关,我们可以定义特征
h(x)=hθ(x)=θ0+θ1x1+θ2x2+…+θixi=θTx
其中 θT=[θ0,θ1,…,θi],xT=[x1,x2,…,xi] ,最后是其向量表达形式。我们可以看出,每一组 θ 值对应一个拟合函数,为了选出其中最好的 θ ,我们定义一个评价标准,即损失函数(loss function)或代价函数(cost function)。
代价函数
在线性回归中,我们定义代价函数为:
J(θ)=1m∑i=1m12(hθ(x(i))−y(i))2
minθJθ
其中,系数 12 是为了求导方便, 1m 在不同的讲义中可能会有所不同,我们以斯坦福的讲义为标准。
从表达式我们可以看出,学习的最终目的就是优化代价函数,使代价函数变小了,预测值和真值的差异就越小,训练出来的模型就越好。如何求解 J(θ) 有很多种办法,常见的有梯度下降法和最小二乘法。
梯度下降法
梯度下降法是求解无约束最优化问题的一种最常见的方法,其实现简单,易于理解。如下图所述带有二元参数的目标函数 J(θ0,θ1) ,求解其最小值。我们可以初始化一个参数值 (θ0,θ1) ,然后求 J(θ0,θ1) 在各个方向的偏导,通过一个学习步长来改变参数,并最终求得 J(θ0,θ1) 的最小值。具体算法流程为:
- Algorithm 6.1
- initialize θ , θ={ 0,0,…,0}
- for k = 1 : NumIter do
- θj=θj−α∂∂θjJ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









